Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
French grammar wikipedia , lookup
Spanish grammar wikipedia , lookup
Compound (linguistics) wikipedia , lookup
Preposition and postposition wikipedia , lookup
Scottish Gaelic grammar wikipedia , lookup
Esperanto grammar wikipedia , lookup
Polish grammar wikipedia , lookup
Indeterminacy (philosophy) wikipedia , lookup
Ancient Greek grammar wikipedia , lookup
Latin syntax wikipedia , lookup
Yiddish grammar wikipedia , lookup
Dependency grammar wikipedia , lookup
Morphology (linguistics) wikipedia , lookup
Untranslatability wikipedia , lookup
Cognitive semantics wikipedia , lookup
Malay grammar wikipedia , lookup
Lexical semantics wikipedia , lookup
Word-sense disambiguation wikipedia , lookup
Ontology Learning from Text
Methods & Tools
Polyxeni Katsiouli
Pervasive Computing Research Group
Communication Networks Laboratory
Department of Informatics and Telecommunications
University of Athens – Greece
18/5/2007
Definition of Ontology
‘A formal, explicit specification of a shared conceptualization’
must be
machine
understandable
not private to some individual,
but accepted by a group
types of concepts and
constraints must be clearly
defined
an abstract model of some
phenomenon in the world formed
by identifying the relevant
concepts of that phenomenon
Main elements of an ontology
wasWrittenBy
domain
range
Object property
(relation)
hasTitle
xsd:string
domain
Hierarchy of concepts
(is-a relations)
datatype property
(attribute)
range
Definition of Ontology Learning
The application of a set of methods and
techniques used for building an ontology from
scratch
Uses distributed and heterogeneous
knowledge and information sources
Allows a reduction in the time and effort
needed in the ontology development process
Ontology Learning methods from…
Unstructured sources
•
Semi-structured source
•
Involves NLP techniques, morphological and syntactic
analysis, etc.
elicit an ontology from sources that have some predefined
structure, such as XML Schema
Structured data
•
Extracting concepts and relations from knowledge contained
in structured data, such as databases
Ontology Learning ‘Layer Cake’
x, y (sufferFrom(x, y) ill(x))
Axioms & Rules
Relations
cure (domain:Doctor, range:Disease)
is_a (Doctor, Person)
Disease:=<I, E, L>
Taxonomy (Concept hierarchies)
Concepts
{disease, illness}
Synonyms
disease, illness, hospital
Terms
Part 1 Terms Extraction
Axioms & Rules
Relations
Taxonomy (Concept hierarchies)
Concepts
Synonyms
disease, illness, hospital
Terms
Terms
Linguistic realizations of domain-specific concepts
Are the basis of the ontology learning process
Term extraction implies:
•
Linguistic processing part-of-speech tagging,
morphological analysis, etc.
•
Statistical processing compares the distribution of
terms between corpora
Terms Extraction: Process
Run a Part-Of-Speech (POS) tagger over the domain
corpus
Identify possible terms by constructing patterns, such
as: Adj-Noun, Noun-noun, Adj-Noun-Noun,…
Ignore Names
Identify only the relevant to the text terms by applying
statistical metrics
Linguistic Analysis: an example
Discourse
Analysis
[[It SUBJ:X1] [was PRED] still available…]
Dependency Structure
[[He SUBJ] [booked PRED] [[this] [table HEAD] NP:DOBJ]S]
(S)
Dependency Structure
[[the SPEC] [large MOD] [table HEAD] NP]
(Phrases)
[[He SUBJ] [booked PRED] [[this] [table HEAD]NP:DOBJ:X1]…]…
[[the] [large] [table] NP] [[in] [the] [corner] PP]
[work~ing V]
[table N:ARTIFACT] [table N:furniture]
[table] [2005-06-01] [John Smith]
Phrase Recognition
Morphological Analysis (stemming)
Part of Speech & Semantic Tagging
Tokenization (incl. Named-Entity Rec.)
Statistical Analysis
Statistical metrics used in terms extraction:
Term weighting (TFIDF)
N
tfidf ( w) tf log(
)
df ( w)
Chi-square
(obs exp)
exp
Mutual Information
2
P ( x, y )
mi( x, y )
P( x) P( y )
TFIDF
Most popular weighting schema
N
tfidf ( w) tf ( w) log(
)
df ( w)
The word is more popular when it appears
several times in a document
tf(w)
The word is more important if it appears
in less documents
term frequency (number of words occurrences in a document)
df(w) document frequency (number of documents containing the word
N
number of all documents
tfidf(w) relative importance of the word in the document
Part 2 Synonyms
Axioms & Rules
Relations
Taxonomy (Concept hierarchies)
Concepts
{disease, illness}
Synonyms
Terms
Synonyms
Identification of terms that share
semantics, i.e., potentially refer to the
same concept
Methods for extracting synonyms
• Based on WordNet
• Latent Semantic Indexing (LSI)
WordNet
A lexical database for the English language
Nouns, verbs, adjectives & adverbs are grouped into sets of
synonyms (synsets)
Synsets are interlinked by means of conceptual-semantic
and lexical relations
Adapting WordNet to specific domain
Partition the set of synonymy relations defined in WordNet in
three classes:
•
•
•
Relations irrelevant in the specific domain
Relations that are relevant but incorrect in the specific
domain
Relations that are relevant and correct in the specific
domain
Remove relations from the first two classes and include
relations from the third class
Rank the rest sets according to their frequency in corpus
Latent Semantic Indexing (LSI)
LSI is a technique in NLP of analyzing relationships
between a set of documents and the terms they contain
Uses a term-document matrix which describes the
occurrences of terms in documents – Vector Space Model
Example:
doc1
database
X
computer
X
access
doc2
X
X
Part 3 Concepts
Axioms & Rules
Relations
Taxonomy (Concept hierarchies)
Disease:=<I, E, L>
Concepts
Synonyms
Terms
Concepts
Intension, Extension, Lexicon
A term may be indicate a concept if we can define its:
Intension:
(in)formal definition of the set of objects that this concept
describes
Example: a disease is an impairment of health or a condition of abnormal functioning
Extension: a set of objects that the definition of this concept
describes
Example: influenza, cancer, heart disease
Lexical realizations: the term itself and its multilingual synonyms
Example: disease, illness, maladie
Part 4 Taxonomy Induction
Axioms & Rules
Relations
is_a (Doctor, Person)
Taxonomy (Concept hierarchies)
Concepts
Synonyms
Terms
Concept Hierarchy Extraction
Basic methods used for taxonomy extraction:
With the use of WordNet
Lexico-syntactic patterns
Machine Readable Dictionaries
Co-occurrence Analysis
Linguistic-approaches
Taxonomy Extraction with WordNet
Given two terms t1 and t2, check if they stand in a
hypernym relation with regard to WordNet
Normalize the number of hypernym paths by dividing
by the number of senses of t1
isa(t1, t 2) min(
| paths( senses(t1), senses(t 2)) |
,1)
| senses(t1) |
path: a sequence of edges connecting the two synsets
Example: - 4 different hypernym paths between synsets ‘country’ and ‘region’
- ‘country’ has 5 senses
value of isa (country, region) = 0.8
Lexico-syntactic patterns - Hearst
Aim: the acquisition of hyponym lexical relations from text
Uses a set of predefined lexico-syntactic patterns which
•
•
•
occur frequently and in many text genres
indicate the relation of interest
can be recognized with little or no pre-encoded knowledge
Principle idea: match these patterns in texts to retrieve
is_a relations
Precision with respect to WordNet: 55,45%
Lexico-syntactic patterns - Hearst
NPo such as {NP1, NP2,…, (and | or)} NPn
vehicle
‘Vehicles such as cars, trucks and bikes….’
is-a
is-a
is-a
truck
car
bike
such NP as {NP,} * { (or | and) } NP
fruit
‘Such fruits as oranges, nectarines or apples…’
is-a
is-a
is-a
orange
apple
nectarine
NP {, NP} * { , } { or | and } other NP
‘Swimming, running, or/and other activities…’
activity
is-a
running
is-a
swimming
Lexico-syntactic patterns - Hearst
NP { , } including {NP, } * { or | and } NP
‘Injuries, including broken bones, wounds and bruises…’
injury
is-a
is-a
is-a
broken bone
bruise
wound
NP { , } especially {NP, } * { or | and } NP
‘Publications, especially papers and books…’
publication
is-a
paper
is-a
book
Machine Readable Dictionaries
A method for extracting taxonomies which goes back
to the 80’s
Main idea: exploit the regularity of dictionary entries to
find a suitable hypernym for the defined word
Example:
spring “the season between winter and summer and in which
leaves and flowers appear”
is_a (spring, season)
MRDs: Exceptions
The hypernym can be preceded by an expression such as ‘a kind of’,
‘a sort of’, or ‘a type of’
The problem is solved by keeping an exception list with words such as
‘kind’, ‘sort’, ‘type‘ and taking the head of the NP following the
preposition ‘of’
Example: hornbeam: “a type of tree with a hard wood, sometimes used in hedges”
is_a (hornbeam, tree)
The word can be defined in terms of a part-of or membership relation
Example: republican : “a member of a political party advocating republicanism”
is_a (republican, political party) part_of (republican, political party)
Co-occurrence analysis
A certain term t1 is more special that a term t2, if
t2 also appears in all the documents in which t1
appears.
Document-based subsumption
Term x subsumes term y iff P(x | y) 1, where
n( x, y)
P( x | y )
n( y )
n(x,y) the number of documents in which x and y co-occur
n(y) the number of documents that contain y
Linguistic Approaches
Modifiers typically restrict or narrow
down the meaning of the modified noun
Example:
is_a (international credit card, credit card)
Part 5 Relations
(non-taxonomic)
Axioms & Rules
cure (domain:Doctor, range:Disease)
Relations
Taxonomy (Concept hierarchies)
Concepts
Synonyms
Terms
Extracting relations & attributes
Specific relations
• Part-of
• Qualia (Formal, Constitutive, Telic, Agentive)
General relations
• Exploiting linguistic structure
Attributes
Learning attributes: Introduction
Attributes relations with a datatype as range
Typically expressed in texts using preposition of, the verb have or
genitive constructs, e.g. ‘the color of the car’, ‘the car’s color’, ‘every
car has a color’
Values of attributes are expressed using copula constructs,
adjectives or expressions specific to the attribute in question, e.g.,
•
•
•
‘the car is red’ (copula + value)
‘the red car’ (adjective)
‘the baby weights 3 kgr’ (specific expressions)
Classification of attributes
To systematize the learning process attributes are classified according to their range
An approach to learning attributes
Tokenize & part-of-speech tag the corpus
Apply the following patterns to extract adjective/noun pairs
(\w+{DET})? (\w+{NN}) + is{VBZ} \w + {JJ}
(\w+{DET})? \w + {JJ} (\w+{NN}) +
These pairs are weighted using conditional probability:
f(n,a): joint frequency of adjective a and noun n
f(n): the frequency of noun n
For each of the adjectives we look up the corresponding
attributes in WordNet
JJ: adjective
NN: noun
DET: determiner
VBZ: verb, 3rd person singular present
“meronymy” / “part-of” relations
Given a “seed” word find parts of that word in a large corpus of text
whole NN[-PL] ‘s POS part NN[-PL]
e.g. …building’s basement…
part NN[-PL] of PREP {the|a} DET mods [JJ|NN]* whole NN
e.g. …basement of a building…
55% accuracy
Format type_of_word TAG type_of_word TAG…
NN = Noun
PREP = Preposition
JJ = Adjective
NN-PL = Plural Noun
POS = Possessive
Qualia structures
The meaning of a lexical element is described in terms of four roles:
Constitutive
Agentive
Formal
Telic
physical properties of a object (e.g., weight, material, parts)
typically a verb denoting an action which brings the object in existence
normally consists in typing information about the object (e.g., hypernym)
the purpose or function of an object either by a verb or by a nominal
Example:
Qualia structures for knife
Formal: artifact_tool
Constitutive: blade, handle,…
Telic: cut_act
Agentive: make_act
Qualia Structures: Learning Approach
aim: to automatically learn qualia
structures from the WWW
Based on the idea of matching certain
lexico-syntactic patterns conveying a
standard relation
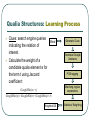
Qualia Structures: Learning Process
Clues: search engine queries
indicating the relation of
interest
Word
Calculate the weight of a
candidate qualia element e for
the term t using Jaccard
coefficient:
GoogleHits(e t )
GoogleHits(e) GoogleHits(t ) GoogleHits(e t )
Weighted QS
Generate Clues
Download Google
Abstracts
POS-tagging
Matching regular
expressions
Statistical Weighting
Qualia Structure: Patterns (1/2)
Formal Role
Telic Role
Qualia Structure: Patterns (2/2)
Constitutive Role
Relations by syntactic analysis
SubjToClass_PredToSlot_DObjToRange
OntoLT
Maps a subject to the domain, the predicate or verb to a slot or
relation and the object to its range.
Example:
‘The player kicked the ball to the net’
relation: kick (domain: player, range: ball)
RelExt
A tool for Relation Extraction
identifies relevant triples (pairs of concepts connected by a
relation) over concepts from an existing ontology
is based on the fact that verbs express a relation between two
classes that specify the domain and range
extracts relevant verbs & their grammatical arguments and
computes corresponding relations through a statistical &
linguistic processing
was developed in the context of SmartWeb project to provide
intelligent information services in the FIFA World Cup 2006
RelExt: Linguistic processing
● Linguistic annotation
the SCHUG system was used
provides a multi-layer XML format for a
given text
dependency structure, lemmatization,
POS
Corpus
Linguistic
annotation
NER &
Concept Tagging
● NER (Name Entity Recognition)
performed to map instances of football
players to existing ontology classes
●Concept tagging
maps synonyms for given terms to the
corresponding ontology concepts
Annotated
corpus
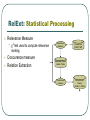
RelExt: Statistical Processing
Relevance Measure
•
χ2
test used to compute relevance
ranking
Coocurence measure
Relation Extraction
Relevance
Measure
Frequencies
In BNC, NZZ
Relevance Scores
Heads, Preds
Cooccurence
measure
Cooccurence
Scores
Heads <> Preds
Part 6 Axioms & Rules
x, y (sufferFrom(x, y) ill(x)
Axioms & Rules
Relations
Taxonomy (Concept hierarchies)
Concepts
Synonyms
Terms
DIRT
Discovery of Inference Rules from Text
an unsupervised method for discovering inference rules
from text, such as
X is author of Y X wrote Y,
X caused Y Y is blamed on X
X manufactures Y X’s Y factory
Is based on the assumption that:
Distributional Hypothesis
Words that occurred in the same contexts tend to be similar
DIRT: Distributional Hypothesis
Distributional Hypothesis is applied to
dependency tress
If two paths tend to link the same sets of
words, their meanings are hypothesized to be
similar
DIRT: Dependency trees
The inference rules
discovered by DIRT are
between paths in
dependency trees
Are generated by Minipar
parser
Minipar represents its
grammar as a network where
nodes represent grammatical
categories and links syntactic
relationships
A subset of the dependency relations in Minipar output
DIRT: Dependency trees
“John found a solution to the problem”
found
subj
obj
Links represent dependency relationships
Direction: from the head to the modifier
John
solution
Labels represent types of dependency relations
det
mod
Each link between two words represents a direct
semantic relationship
a
to
pcomp
Path between “John” and “problem”
problem
N:subj:V find V:obj:N solution N:to:N
meaning “X finds solution to Y”
det
the
DIRT: Paths in Dependency Trees
Connect the prepositional complement directly to the words
modified by the preposition
transformation rule
Each link between two words represent a direct semantic relationship
A path represents indirect semantic relationships between two content words
Ontology Learning Tools
Text2Onto
•
•
http://ontoware.org/projects/text2onto
OntoLT
•
•
Open source (Java)
Open source (Protégé plug-in, Java)
http://olp.dfki.de/OntoLT/OntoLT.htm
OntoGen
•
•
Open source (C++, .NET)
http://www.textmining.net
Text2Onto: Main Features
Learn primitives independent of a specific KR
language (Probabilistic Ontology Model, POM)
System calculates a confidence for each learned
object for better user interaction
Updates the learned knowledge each time the
corpus is changed and avoid processing it by scratch
Allows for easy
•
•
•
combination of algorithms,
execution of algorithms,
writing new algorithms
Text2Onto: Algorithms used
Concepts
•
Statistical measures, e.g. TFIDF, C-value/NC-value,…
Subclass_of relations
•
•
Exploits hypernym relations from WordNet
Hearst patterns
Mereological relations (part-of)
General relations: extracts the following syntactic frames:
•
•
•
Transitive, e.g., love(subj, obj)
Intransitive + PP-complement, e.g., walk(subj, pp(to))
Transitive + PP-complement, e.g., hit(subj, obj, pp(with))
Instance-of
Equivalence
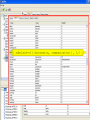
Text2Onto: screenshot
OntoGen : Techniques used
Linear Dimensionality Reduction (a.k.a LSI)
•
•
words related to the same topic co-occur together
more often than words related to different topics
Result: clusters of words each describing one topic
K-means clustering algorithm
•
Partitions the corpus into k clusters so that two
documents within the same cluster are more closely
related than two documents from different clusters
OntoGen: screenshot
Onto-LT
A Protégé plug-in with which classes and
relations can be extracted from a linguistic
annotated text collection
Provides mapping rules that allow for a
mapping between linguistic entities and
class/slots candidates in Protégé
Onto-LT: Mapping rules
HeadNounToClass_ModToSubClass
Maps a head-noun to a class and in combination with its modifier(s)
to one or more sub-class(es)
SubjToClass_PredToSlot_DObjToRange
Maps a linguistic subject to a class, its predicate to a corresponding
slot for this class and the direct object to the “range” of the slot
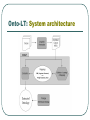
Onto-LT: System architecture
Onto-LT: screenshot
Conclusions
A detailed methodology that guides the ontology
learning process does not exist
Only general guidelines are provided
No complete correspondence between the methods
and the tools
Methods are based mainly on NLP techniques
complemented with statistical measures
Tools give only support to perform some of the steps
proposed in different approaches (except Text2Onto)
Some References…
Cimiano, P. Ontology Learning and Population from Text:
Algorithms, Evaluation and Applications. Springer, 2006
Hearst, M.A., Automatic Acquisition of Hyponyms from Large
Text Corpora. In: Proceedings of the 14th International
Conference on Computational Linguistics, pp. 539-545, 1992
Gómez-Pérez, A., & Manzano-Macho, D., An overview of
methods and tools for ontology learning from text, The
Knowledge Engineering Review, Vol. 19:3, 187-212, 2005.
P. Cimiano, J. Wenderoth, Automatically Learning Qualia
Structures from the Web. In: Proceedings of the ACL
Workshop on Deep Lexical Acquisition, pp. 28-37, 2005