Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
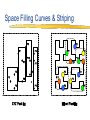
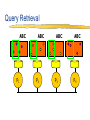
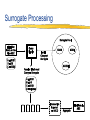
Parallel Multi-Dimensional ROLAP Indexing Andrew Rau-Chaplin Faculty of Computer Science Dalhousie University Joint work with Frank Dehne, Carleton Univ. Todd Eavis, Dalhousie Univ. Data Warehousing for Decision Support Query Reports Analysis Data Mining Front-End Tools Olap Server Output Olap Server Olap Engines Monitoring Administration Data Warehouse Data Storage Meta Data Repository Extract Clean Transform Load Refresh Operational Databases Data Marts External Sources Data Cleaning and Integration Operational data collected into DW DW used to support multidimensional views Views form the basis of OLAP processing Our focus: the OLAP server Multi-dimensional views Collection of feature attributes Aggregate along one or more measure attributes Reduce the granularity by “collapsing” dimensions Points generated by: distributive functions(e.g., sum) algebraic functions (e.g., average) holistic functions(e.g., median) Ford By Make & Year Chevy By Year 1990 1991 1992 1993 By Make Red White Blue By Colour & Year By Make & Colour By Colour Data Cube Generation Proposed by Gray et al in 1995 Can be generated “manually” from a relational DB but this is very inefficient Exploit the relationship between cuboids to compute all 2d cuboids In OLAP environments, we typically pre-compute these views to improve query response time ABC AB A AC C ALL BC B Existing Parallel Results Goil & Choudhary MOLAP solution in-memory structures global partition + d communication rounds distributed views Limitations J. Of Data Mining & Knowledge Discovery 1(4), 1997 Memory for multidimensional arrays expensive communication for larger d Our Approach ROLAP solution ABCD ABC AC AB A ABD ACD AD BC B C All CCGrid’01 + J. Dist. & Parallel Databases 11(2), 2001 BCD BD CD D Construct and cost the data cube lattice Find a “least cost” spanning tree Partition the spanning tree over the processors equally, construct views and distribute Can handle partial cubes Limitations What about indexing????? Parallel Multi-dimensional Indexing Query specifies a range on multiple dimensions Forms a hypercube in the point space General Approach No multidimensional index is universally successful Exploit domain specific information and the features of a particular index OLAP Data is provided up front Updates are batch oriented Design Goals A framework for distributed highperformance indexing of ROLAP cubes Practical to implement Low communication volume Fully adapted to external memory (disks) No shared disk required Incrementally maintainable Efficient for high D spatial searches Scalable in terms of data size, dimensions, processors Challenge How to order and partition data such that Number of records retrieved per node is as balanced as possible Minimize the number of disk seeks required in answering a query ABC P1 P2 P3 P4 Indexing the Data Cube Combine the strengths of a space filling and an r-tree index Use Hilbert curve to load buckets Index buckets with rtree Update indexes with merge/sort Space Filling Curves & Striping Query Retrieval ABC P1 ABC P2 ABC P3 ABC P4 Example Original Space Processor 1 8 points to be reported Reports: 2 consecutive blocks & 4 points Processor 2 Reports: 2 consecutive blocks & 4 points The Parallel Framework A single view is partitioned across p processors Partial Hilbert/r-tree indexes are computed locally Queries are answered concurrently Queries answered individually or “piggybacked” The Virtual Data Cube Problem: Full cube often to large to materialize Solution: Use surrogate views Surrogate Processing Other issues… Dimension ordering Query piggybacking Batch updating Managing Hierarchies of views Experimental Results Machine 17 node cluster Node = 1.8 GHz Xeon, 1 GB RAM, 2 * 40 GB IDE drives, running Linux Interconnect = Intel Fast Ethernet switch Test Data 10 dimensions and 1,000,000 records RCUBE index Construction Output: ~640 million rows, 16 Gigabytes Distributed Query Resolution Test: Random queries returning ~15% of points (10 experiments per point) Disk blocks retrieved vs. Disk Seeks Test: Random queries returning 5-15% of points (15 experiments per point) Distributed Query Resolution in Surrogate Group-bys Thank You Questions?