Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
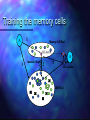
Artificial Immune Systems: a new classifier Andrew Watkins & Lois Boggess Department of Computer Science Mississippi State University Metaphors from nature Neural networks Genetic algorithms Biological immune systems Pathogen Leucocytes T cells (thymus) B cells (bone marrow) Immune response Pathogen Antigen presenting cells T cell (helper cell) and B cell B cell begins cloning and mutating Memory cells T cells B cells can’t “match” an antigen unless a T cell does also Protection against self-destruction: As T cells mature, those that match against self are destroyed. Surviving T cells do not match self Artificial Immune Systems Some based on T cell analogy (e.g., Dasgupta, University of Memphis,Forrest at U.New Mexico) Information Security Example: data security Data chopped into small segments Lots of small random sequences from the alphabet of the data The ones that match are eliminated. Rest recognize patterns not originally in the data Can calculate how many needed on basis of alphabet and acceptable risk of overlooking changes to data Models based on B cells Measure affinity of B cells to a presenting antigen The stronger the affinity, the more likely the B cell is to change state and produce clones, some of which are mutated B cells that are not excited by antigens eventually die B cells “network” with similar B cells Clusters visible in the results (e.g. Timmis et al. and the Iris data) Early work at MSU (Andrew Watkins) Used the B cell models Tried to modify to create a classifier Problem: B cells proliferated until a system is swamped Problem: method for training the classifier elusive Resource limited AIS Timmis’ group also had B cells swamping the available computing resources Replace large numbers of identical B cells with single representative (ARB) having a resource number indicating “how many” Limit the total, and introduce competition MSU contribution Add class consciousness Reward B cells which have strong affinity to a presenting antigen of the same class At some point, also reward B cells which have low affinity to antigens of different class Take resources away from B cells which respond inappropriately - eventually they die Training the memory cells 1 A Memory Cell Pool MCmatch 3 Mutated Offspring 2 4 A 5 MC candidate ARB Pool Effects of number of seed cells Top two are accuracy on training Bottom two are accuracy on test data Slight trend toward better accuracy with more seed cells Very different from radial basis classifiers Training algorithm 1. A training antigen is presented to all of the memory cells of the same class as itself to find the memory cell MCmatch 2. MCmatch is added to the ARB pool along with its mutated offspring; the number of offspring it is allowed to create depends on the strength of the match 3. The training antigen is presented to the entire ARB pool. It is at this point that we go through the stages of competing for resources, culling the weakest ARBs, and producing mutated offspring. This stage continues until the stimulation threshold is met. 4. The strongest ARB of the same class as the training antigen is chosen as the candidate memory cell. The strength of the reaction of MCcandidate is compared with the strength of the reaction of MCmatch to the training antigen. Algorithm (cont.) 5. If MCcandidate’s reaction is stronger than MCmatch’s reaction then add MCcandidate to the Memory Cell Pool. If, in addition to having this stronger reaction, MCcandidate is closer to MCmatch than the product of the Affinity Threshold and the Affinity Threshold Scalar, then replace MCmatch with MCcandidate in the Memory Cell Pool. Cleveland heart disease Iris IncNet 28-NN, stand, E uclid, 7 features Fisher discrim inant analysis LDA 90.0 85.1 0.5 84.2 Grobian (rough) SSV 100% 98.0% 3-NN + simplex 3-NN 98.7% 96.7% Logdisc IncNet 77.7% 77.6% TAP MFT Bayesian Na•ve MFT Bayesian 92.3% 90.4% C-MLP2LN 98.0% IB3 96.7% DIPOL92 77.6% SVM 90.4% 84.5 PVM 2 rules 98.0% MLP + BP 96.0% 840.6 84.0 PVM 1 rule AIRS AIRS C4.5 94.9% 94.9% Best 2-lay er MLP + BP, 12 hidden MLP+BP, 12 hidden MLP+BP, 24 hidden 7 8 82.5-83.4 83.165 FuNe-I NEFCLASS 97.3% 96.7 % 96.7% 96.7% 77.5%77.2% 76.8% 76.8% 90.4% 16-NN, stand, E uclid FSM, 82.4-84% on test only Na•ve Bayes AIRS RIAC SVM 94.6% 93.2% 76.6% 76.5% 1-NN, Manhatten AIRS 84.2% 84.0% 9 SNB 83.1 CART 96.0% 92.0% 76.4% MLP+BP, 6 hidden 83.5% 10 11 LVQ kNN, k=27, M anh FUNN 95.7% 92.8% 92.1% LVQ LFC 75.8% 75.8% FSM - m ethodology? 1-NN Euclidean 83.6% 82.2% 12 13 GTO DT (5xCV) kNN, k=19, E uclidean 82.9 82.8 0.6 82.5 82.10.8 Non-linear perceptron FSM + rotation 1-NN Linear Discr. Anal. SMART GTO DT (5xCV) ASI Fischer discr. anal MLP+BP DB-CART Linear perceptron 91.3% 90.7% RBF NB DB-CART, 10xCV CART, 10xCV 81.8% 67.9% 14 LDA (all vectors, 85% on train) SVM (5xCV) kNN (k=1?) 81.8 OC1 DT 89.5% 75.7% 75.573.8% 75.5% 81.5 81.5 CART GTO DT 88.9% 86.0% kNN, k=22, Manh MML 75.5% SNB 75.4% ... AIRS 74.1% C4.5 73.0% 11 others reported with lower scores, including Bayes, Kohonen, kNN , ID3 Ι 1 2 3 4 5 6 15 16 Ι 22 23 others below 16th rank include MLP with Backprop, CART, RBF, Gaussian EM, ASR, C4.5, and a number of WEKA tools, a mong others Ionosphere Diabetes Sonar 84.7% 84.5% We have only just begun Lots of ideas for exploring the paradigm Andrew Watkins original ideas for modifications Don Goodman - exploring what happens when there are lots of classes Gaurov Marwah - uniform probability assumed for cloning and mutation - what if we introduce prob. distributions? L. Boggess - nature doesn’t use pure mutation during cloning process - what if we use some ideas from sequence alignment to determine good mutation sites?