Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
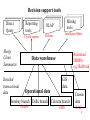
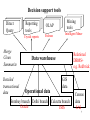
Data warehousing and mining Introduction • Organizations getting larger and amassing ever increasing amounts of data • Historic data encodes useful information about working of an organization. • However, data scattered across multiple sources, in multiple formats. • Data warehousing: process of consolidating data in a centralized location • Data mining: process of analyzing data to find useful patterns and relationships 2 Typical data analysis tasks • Report the per-capita deposits broken down by region and profession. • Are deposits from rural coastal areas increasing over last five years? • What percent of small business loans were cleared? • Why is it less than last year’s? How did similar businesses that did not take loans perform? • What should be the new rules for loan eligibility? 3 Decision support tools Direct Query Merge Clean Summarize Detailed transactional data Reporting tools OLAP Crystal reports Essbase Mining tools Intelligent Miner Relational DBMS+ e.g. Redbrick Data warehouse Operational data Bombay branch Delhi branch Oracle GIS data Calcutta branch IMS Census data SAS 4 Data warehouse construction • Heterogeneous data integration – merge from various sources, fuzzy matches – remove inconsistencies • Data cleaning: – missing data, outliers, clean fields e.g. names/addresses – Data mining techniques • Data loading: summarize, create indices • Products: Prism warehouse manager, Platinum info refiner, info pump, QDB, Vality 5 Warehouse maintenance • Data refresh – when to refresh, what form to send updates? • Materialized view maintenance with batch updates. • Query evaluation using materialized views • Monitoring and reporting tools – HP intelligent warehouse advisor 6 Decision support tools Direct Query Merge Clean Summarize Detailed transactional data Reporting tools OLAP Crystal reports Essbase Mining tools Intelligent Miner Relational DBMS+ e.g. Redbrick Data warehouse Operational data Bombay branch Delhi branch Oracle GIS data Calcutta branch IMS Census data SAS 7 OLAP Fast, interactive answers to large aggregate queries. • Multidimensional model: dimensions with hierarchies – Dim 1: Bank location: • branch-->city-->state – Dim 2: Customer: • sub profession --> profession – Dim 3: Time: • month --> quarter --> year • Measures: loan amount, #transactions, balance 8 OLAP • Navigational operators: Pivot, drill-down, roll-up, select. • Hypothesis driven search: E.g. factors affecting defaulters – view defaulting rate on age aggregated over other dimensions – for particular age segment detail along profession • Need interactive response to aggregate queries.. 9 OLAP products • About 30 OLAP vendors • Dominant ones: – Oracle Express: largest market share: 20% – Arbor Essbase: technology leader – Microsoft Plato: introduced late last year, rapidly taking over... 10 Microsoft OLAP strategy • Plato: OLAP server: powerful, integrating various operational sources • OLE-DB for OLAP: emerging industry standard based on MDX --> extension of SQL for OLAP • Pivot-table services: integrate with Office 2000 – Every desktop will have OLAP capability. • Client side caching and calculations • Partitioned and virtual cube • Hybrid relational and multidimensional storage 11 Data mining • Process of semi-automatically analyzing large databases to find interesting and useful patterns • Overlaps with machine learning, statistics, artificial intelligence and databases but – more scalable in number of features and instances – more automated to handle heterogeneous data 12 Some basic operations • Predictive: – Regression – Classification • Descriptive: – Clustering / similarity matching – Association rules and variants – Deviation detection 13 Classification • Given old data about customers and payments, predict new applicant’s loan eligibility. Previous customers Age Salary Profession Location Customer type Classifier Decision rules Salary > 5 L Prof. = Exec Good/ bad New applicant’s data 14 Classification methods • Nearest neighbor • Regression: (linear or any polynomial) – a*salary + b*age + c = eligibility score. • Decision tree classifier • Probabilistic/generative models • Neural networks 15 Clustering • Unsupervised learning when old data with class labels not available e.g. when introducing a new product. • Group/cluster existing customers based on time series of payment history such that similar customers in same cluster. • Key requirement: Need a good measure of similarity between instances. • Identify micro-markets and develop policies for each 16 Association rules • Given set T of groups of items • Example: set of item sets purchased • Goal: find all rules on itemsets of the form a-->b such that T Milk, cereal Tea, milk Tea, rice, bread – support of a and b > user threshold s – conditional probability (confidence) of b given a > user threshold c • Example: Milk --> bread • Purchase of product A --> service B cereal 17 Mining market • Around 20 to 30 mining tool vendors • Major players: – – – – Clementine, IBM’s Intelligent Miner, SGI’s MineSet, SAS’s Enterprise Miner. • All pretty much the same set of tools • Many embedded products: fraud detection, electronic commerce applications 18 Conclusions • The value of warehousing and mining in effective decision making based on concrete evidence from old data • Challenges of heterogeneity and scale in warehouse construction and maintenance • Grades of data analysis tools: straight querying, reporting tools, multidimensional analysis and mining. 19