Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
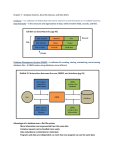
Module Reading Material and Resources Core Texts: Connolly, T.M., and Begg, C.E., Database Systems: A Practical Approach to Design, Implementation and Management, Addison-Wesley, 4th Edition, ISBN: 0321210255 Additional Texts: Bertino, E., Catania, B and Zarri, G, Intelligent Database Systems, Addison-Wesley, ACM Press, 2001 ISBN: 0-201-87736-8 Adelman, S., Moss, L and Abai, M., Data Strategy, Addison Wesley, 2005, ISBN: 0-321-24099-5 Eaglestone, B and Ridly, M., Web Database System, Mc. Graw-Hill, 2001, ISBN 0-07-709600-2 Thraisingham, B., XML Database and Semantic Web, 2002, CRC Press, ISBN: 0849310318 Ponniah, P., Data Warehousing Fundamentals, 2001, Wiley-Interscience, ISBN: 0471412546 Berson, A and Smith, S.J., Data Warehousing, Data Mining and OLAP, 1997, McGraw Hill Companies, ISBN: 0-070-06272-2 Nemati, H and Barko, C., Organisational Data Mining: Leveraging Enterprise Data Resource for Optimal Performance, 2003, Ideal Group Inc. ISBN: 1591402220 Learning Outcomes Having successfully completed this unit you should be able to: Explain the concepts of data, databases, and database management systems. Identify major components of the DBMS environment. Describe the important role of databases in developing dynamic Web sites. Identify the components of distributed database environment. Required Study Time You should expect to spend approximately 9 hours studying this unit. You may find it convenient to break up your study as follows: Preparation (Introduction and On-line Planning): Disk-based Content: Application: Set textbook Content: Reflection (On-line discussions, review questions): Tutorial Work: Related Coursework: Extension Work: ½ hour 3 1 2 1 hours hours hour hour 1 hour ¼ hour ¼ hour Equipment/Software Required A Web browser – for browsing Web sites and Web-based database applications. Internet Explorer 5.0 is recommended. A text editor – for the editing and writing of HTML. Window’s Notepad is sufficient for editing and writing programs. Internet Information Server (IIS) or Personal Web Server (PWB). Learning Journal You will be expected to keep a learning journal throughout this module. It will help, if you keep a record of new/difficult programming, unusual rules and lessons learnt from the activities. You can refer to your Learning Journal at any point. Reading Materials Connolly, T.M., and Begg, C.E., Database Systems: A Practical Approach to Design, Implementation and Management, Addison-Wesley, 4th Edition, ISBN: 0321210255 Content 1.1 Data and its Importance By data, we mean known facts that can be recorded and can be interpreted to provide information. Data alone has no significance, but once interpreted and suitably correlated, it provides information that allows us to improve our knowledge of the world. For example, the string ‘John Smith’, and the number 2254, written on a piece of paper, are two pieces of data that are meaningless by themselves. If the sheet is sent in response to the question ‘Who is the head of the department and what is his telephone extension?’, then it is possible to interpret the data and use it to enrich our knowledge with the information that John Smith is the head of the department and that his extension is 2254. In many applications, data is intrinsically much more stable than the procedures that operate upon it. Let’s consider the data relating to bank applications. Queries about the availability of funds on credit cards can be asked through simple devices located in shops, hotels, or companies which allow purchases made anywhere in the world to be charged to the credit card owners. The data involved in these applications has a structure that has remained virtually unchanged for decades, while the procedures that act upon it vary continually, as every customer can readily verify. Furthermore, when one procedure is substituted for another, the new procedure ‘inherits’ the data of the old one, with appropriate changes. This characteristic of stability leads us to state that data constitutes a resource for the organisation that manages it, a significant heritage to exploit and protect. 1.2 File-based Data Management The conventional approach to data management is to use files to store data permanently. A file allows for the storage and searching of data, but provides only simple mechanisms for access and sharing. With this file-based approach, the procedures written in a programming language are completely autonomous; each one defines and uses one or more ‘private’ files. Data of possible interest to more than one program is replicated as many times as there are programs that use it, with obvious redundancy and possibility of inconsistency. Consider a typical business scenario, where a number of different application programs may be employed to deal with purchase orders, invoices, sales and marketing, suppliers, customers, employees, and so on. We can imagine that some of these applications might use the same data. If the data is kept in different files, there could be problems when an item of data needs updating, as it will need to be updated in all the relevant files. If this is not done, the data will be inconsistent, and this could lead to errors. The problem could be made even worse if different items of data are changed in different departments, for instance, the invoice application uses a different address from the sales mailing list program for the same customer. Applications Customer Orders Files Customer File Stock File Order File Customer Invoice Customer File Stock File Order File Purchase Orders Stock File Order File Stock Control Stock File Order File Figure 1.1 File-based system. Figure 1.1 shows how different applications will each have their own copy of the files they need in order to carry out the activities for which they are responsible. Shared File Approach One approach to solve the problems of redundancy and inconsistency is to share files among different applications. This will alleviate the problem of inconsistent data among different applications. This is illustrated in figure 1.2. Applications Customer Orders Customer Invoice Purchase Orders Stock Control Figure 1.2 Shared file system. Files Customer File Stock File Order File Supplier File The shared file approach solves the problem of data inconsistency, but other problems may emerge as indicated below: When each department had its own version of a file for processing, each department could ensure that the structure of the file suited their specific application. If departments have to share files, the file structure that suits one department might not suit another. For example, data might need to be sorted in a different sequence for different applications. (Customer details could be stored in alphabetical order, or numerical order – ascending or descending – of customer number.). Some applications may require access to more data than others, but the file will still need to contain the additional information to support all applications that require it. If the structure of the data file needs to be changed in some way, this alteration will need to be reflected in all application programs that use that data file. This problem is known as physical data dependency. While a data file is being processed by one application, the file will not be available for other applications or for ad hoc queries. 1.3 Databases and Database Management Systems Environment A database is a collection of related data managed by a Database Management System (DBMS). A DBMS is a software system designed to manage collections of data that are large, shared, and persistent. The database approach is an improvement on the shared file solution as the use of a DBMS provides facilities for efficient and effective querying, data security and integrity, and simultaneous accessing of data. We will detail the significant characteristics of the database and DBMS in this section. Database Characteristics Large – Databases can be large, in the sense that they can contain thousands of billions of bytes and are, in general, certainly larger than the main memory available. As a result, a DBMS must manage data in secondary memory (i.e., on disks). Small databases can exist, but the systems must be able to manage data without being limited by dimensions, apart from the physical ones of the devices at hand. Shared – Databases are shared, in the sense that various applications and users must be able to gain access to data of common interest. In this way, the redundancy of data is reduced, since repetitions are avoided, and consequently, the possibility of inconsistencies is reduced. In addition, in order to guarantee shared access to data by many users operating simultaneously, the DBMS makes use of a special mechanism called concurrency control. Persistent – Databases are persistent, in the sense that they have a lifespan that is not limited to single executions of the programs that use them. Conversely, data managed by a program in main memory has a life that begins and ends with the execution of the program; therefore, such data is not persistent. Reliability – DBMSs ensure reliability, in the sense that they have the capacity to preserve the contents of the database (or at least to allow its reconstruction) in case of hardware or software failure. To fulfil this requirement, DBMSs provide specific functions for backup and recovery. Privacy – DBMSs ensure data privacy. Each user, who is recognised by a user name that is specific to that user’s access to the DBMS, is qualified to carry out only certain operations on the data, through the mechanisms of authorisation. Efficiency – DBMSs are concerned with efficiency, which is the capacity to carry out operations using appropriate amounts of resources (time and space) for each user. This characteristic relies on the techniques used in the implementation of the DBMS, and how well the product has been designed. Effectiveness – DBMSs increase effectiveness by providing various functions and services to different users to make the activities of the users productive. Connolly, T.M., and Begg, C.E., Database Systems: A Practical Approach to Design, Implementation and Management, AddisonWesley, 4th Edition, ISBN: 0321210255 Chapter 1: Section 1.2 and 1.3 Make notes in learning journal. Now carry out Activity 1.1 – Looking up Glossary Entries Learning Outcome: Explain the concepts Data, Database and Database Management Systems Keep notes in your learning journal of your learning process before you proceed to the next section. Now do Review Question 1.1 Now do Review Question 1.2 Now do Review Question 1.3 Now do Review Question 1.4 Components of a DBMS DBMSs are highly complex and sophisticated software packages that aim to provide various services to database applications. In the main content of this unit, we introduced the concept of a DBMS and discussed their main characteristics. Here we briefly introduce the different components of a DBMS. A DBMS is normally partitioned into several software components (modules), each of which is assigned a specific operation. The major software components in a DBMS environment are depicted in figure 1.6. The diagram also shows how it interfaces with other software components such as user queries and file manager. Application programs User Queries Database Schema DBMS DML Preprocessor Query Processor DDL Compiler Program Object Database Manager Dictionary Manager Code Access Methods System Buffers File Manager Database and System Catalogue Figure 1.3 Major components of a DBMS Query processor – This is a major DBMS component that transforms queries written in a high-level language, typically SQL, into a series of low-level instructions directed to the Database Manager. An important task of a query processor is query optimisation. As there are many equivalent transformations of the same high-level query, the aim of query optimisation is to choose the one that minimises resource usage. Database Manager (DM) – The DM interfaces with the user-submitted application programs and queries. The DM accepts the queries and determines what conceptual records are required to satisfy the request. The DM then places a call to the File Manager to perform the request. File Manager – The file manager manages the underlying storage files as well as the allocation of storage space on the disk. However, it does not manage the physical input and output of data. Rather, it passes the requests onto the appropriate access methods, which read data from or write data into the system buffers. DML Pre-processor – This module accepts an application program and converts it to Data Manipulation Language (DML) statements which are standard function calls in the host language. The DML pre-processor must interact with the query processor in order to generate the appropriate code. DDL Compiler – The Data Definition Language (DDL) compiler converts the DDL statements into a set of tables containing meta-data which describes the database objects. These tables are then stored in the system catalogue while control information is stored in data file headers. Any DBMS module that needs information about database objects must access the catalogue. Catalogue Manager – The catalogue manager manages access to the system catalogue by most DBMS components. Data Models A data model is a combination of constructs used to organise data. Each data model provides structuring mechanisms, similar to the type constructors of programming languages, which allow the definition of new data types based on constructors applied to predefined elementary types. For example, most programming languages allow the construction of types by means of array, record, and file constructors. In other words, array, record and file constructors are predefined data types, and you may simply specify a data variable, say X, as array type of data without defining its properties. X will inherit all the properties of array data type. Relational Data Model The relational data model, which is the most widespread data model, provides the relation constructor, which makes it possible to organise data in a collection of records with a fixed structure. A relation is often represented by means of a table, whose rows show specific records and whose columns correspond to the fields of the record; the order of the rows and columns is irrelevant. A record in a table is simply a row of the table, and a field also known as an attribute, is a column of the table. For example, data relating to university courses and their tutors can be organised by means of two relations COURSE and TUTOR, represented by the tables in figure 1.3. As we can see, a relational database generally involves many relations. COURSE Course Code BIS2020 BIS3020 BIS4020 Course Name Tutor Name Database Systems Adam Smith Advanced Database Henry Alliance Systems Web Database Systems Amera Haque TUTOR Tutor Name Adam Smith Henry Alliance Amera Haque Office M101 G220 Phone 82340098 76803344 G231 10086540 Figure 1.4 Example of a relational database Learning unit 3 will give a detailed discussion on the relational data model. Besides the relational model, three other data models have been defined in the database community. Hierarchical Data Model The hierarchical data model is based on the use of tree structures (and hierarchies, hence the name), defined during the first phase of development of DBMSs in the sixties. It is still used in many systems, mainly for continuity reasons. Network Data Model The network data model is also known as the CODASYL model, after the Conference on Data Systems Languages that gave it a precise definition. It is based on the use of graphs, developed in the early seventies. Object Data Model The object data model was developed in the eighties in order to overcome some limitations of the relational model. It extends the paradigm of object-oriented programming to databases. In object databases, each entity of the real world is represented by an object. In contrast, a real world object is distributed among a number of relations (or tables) in the relational data model. We will discuss object data model in unit 2. The data models listed above are all available in commercial DBMSs; they are called logical data models, to underline the fact that the structures used for these models, although abstract, reflect a particular organisation (tree, graph, table, or object). Other data models known as conceptual data models, have been introduced to describe data in a manner independent of the logical model; but these are not available in commercial DBMSs. Their name comes from the fact that they tend to describe concepts of the real world, rather than the data needed for their representation. These models are used in the preliminary phase of the database design process, to analyse the application in the best possible way without implementational contamination. Conceptual data models are mainly used to help specify user requirements formally and unambiguously. They are independent of any particular DBMS, and do not involve any physical or implementational details. However, they provide an effective bridge between the informal user requirements and logical database design and implementation. Learning unit 2, dedicated to the design of databases, will examine in detail a conceptual data model, the Entity-Relationship model and object relationship model. Connolly, T.M., and Begg, C.E., Database Systems: A Practical Approach to Design, Implementation and Management, AddisonWesley, 4th Edition, ISBN: 0321210255 Chapter 1: Section 2.1, 2.3 and 2.5 Make notes in learning journal. Now do Review Question 1.5 Now do Review Question 1.6 Keep notes in your learning journal of your learning process before you proceed to the next section. You may wish to highlight any concept(s) you have found difficult to understand and suggest what you need to do to overcome your difficulties. Database Designers and Users DBMSs are complex systems that in their life cycle involve a variety of people. In this section, we briefly examine the different types of people involved in the DBMS environment. DBA A database administrator (DBA) is the person responsible for the design, control and administration of the database. A DBA has the task of mediating the various requirements, often conflicting, expressed by the user, and ensuring centralised control over the data. In particular, a DBA is responsible for guaranteeing services, ensuring the reliability of the system, and managing the authorisations for access to the data. Application Designers and Programmers The application designers and programmers define and create programs that access the database. They use a data manipulation language (DML) or various support tools for the generation of interfaces for the database. Learning unit 4 introduces SQL as a database query language for implementing database applications. Users The users employ the database for their own activities. They can be categorised into two types: Naïve Users: Naïve users use transactions, that is, programs that carry out frequent and predefined activities, with few exceptions known and taken into account in advance. They are normally unaware of the DBMS, and they may even have no knowledge of the database in use. They interact with the database by entering simple commands or choosing operations from a menu. For example, an airline ticket booking assistant uses a computer terminal to check the availability of a ticket required by a customer, and may carry on to book the ticket. He/she is using an easy-to-use interface to interact with the database which holds the airline tickets information, but does not need to know the application program that searches the ticket booking database and modifies the database records should booking take place. It is not even necessary for the assistant to know anything about the ticket booking database. Sophisticated Users: Sophisticated users, on the other hand, are familiar with the structure of the database and the facilities offered by the DBMS. They may use a high-level query language such as SQL to perform any required operations such as formulating queries of various types. They can be specialists in the language they use and interact frequently with the database. They may even write application programs for their own use. Connolly, T.M., and Begg, C.E., Database Systems: A Practical Approach to Design, Implementation and Management, AddisonWesley, 4th Edition, ISBN: 0321210255 Chapter 1: Section 1.4 Now do Review Question 1.7 Use the online discussion facility and post your comments on the topic for discussion for your group to share in. 1.5 Distributed Database Management System A distributed database works on two or more logically related databases distributed over interconnected computer systems located in different physical sites. In distributed database system data, processing and query functions are distributed among geographical locations. Hence, it is also referred as decentralised database system. Unlike a centralised database management system, the distributed database management system (DDBMS) allows end users to access the data readily stored in local sites in order to respond to immediate business needs. DDBMS is not only distributed in different geographical locations, it also allows multiple database access in order to execute queries according to the requirements of decentralised business units. A DDBMScan be Homogeneous or Heterogeneous. A homogeneous DDBMS employs same DBMS products at all sites, on the other hand, a heterogeneous DDBMS can have different DBMSs and data models at least in two different sites. The following section lists the advantages and disadvantages of DDBMS. Advantages and disadvantages of DDBMS The advantages of DDBMS are: Close proximity to data as fragment of data is distributed to all important sites Immediate and faster access of data The system does not depend on a single database and therefore less vulnerable to failure A new site can be added immediately without affecting others Allows multiple processing at multiple sites Reduced overhead and maintenance costs Several sites are capable to process data at the same time The disadvantages of DDBMS are: More control and coordination over data are required Same data is replicated in different sites and therefore appropriate update procedures have to be in place to avoid data inconsistency Requires more data storage Since data is available at local sites, it is required to ensure system security Heterogeneity is a major challenge for implementing DDBMS environment. This is because, the sites are located geographically and according to the local demands they have their own preference for software. To meet the demands vendors supply different and, may be, incompatible systems and techniques that make the DDBMS implementation difficult Components of DDBMS A distributed database management systems employ a number of computer workstations at different sites. These workstations are part of a local network system. The workstations contain a set of hardware and software that allow them to be an integral part of this network and the DDBMS must rely on these network components for its data exchange. The workstations are needed to be attached to each other through a communication media that allow the sites to interact and to carry data. Besides the physical hardware requirements, DDBMS implementation involves a number of software components, for example, transaction manager, data manager, distributed query processor, protocols for data communication and catalog manager. The functions of these components are listed below: Transaction manager: the transaction manager resides in the node that receives and manages data requests. Data manager: the data manager resides in thenode that acts as data repository and retrieves data. Distributed query processor: the query processor allows multiple nodes to access data located at multiple sites. The processor also allows transmitting data and queries to the multiple sites. Protocols: it allows nodes to communicate with each other and assists managers to send and receive data for processing. Catalog manager: it manages local and global directories that contain metadata. A distributed database involves many database management systems that run in different remote sites. The database management system at each site manages a fraction of single logical database and it can be homogeneous or heterogeneous in nature, as discussed in previous section. The homogeneous system can be autonomous or nonautonomous depending on its ability to be able to work independently or not. The autonomous homogeneous distributed database can work independently whereas the nonautonomous system acts based on the instructions provided by the central database management system. However, the main objectives of implementing a distributed database management system are to capture local transactions and to provide meaningful information to the managers whenever it is necessary. Providing effective information to the managers for decision making not only invoves just implementation of a distributed database but in addition it requires strategies for integration and consolidation of the distributed data. An integrated database can provide meaningful information to the business mangers and can help in bridging information gaps in order to discover new knowledge. This integrated database which has the ability to provide new information to the managers can be implemented by applying datawarehousing and data mining approaches. Unit 10 and 11 will explore these two techniques in more details. Connolly, T.M., and Begg, C.E., Database Systems: A Practical Approach to Design, Implementation and Management, AddisonWesley, 4th Edition, ISBN: 0321210255 Chapter 22: Distributed DBMSs-Concepts and Design; Section 22.1 and 22.3 Make notes in learning journal. Now carry out Activity 1.3 - Show the Components of DDBMS Learning Outcome: Identify the components of a distributed database environment Now do Review Question 1.8 Keep notes in your learning journal of your learning process before you proceed to the next section. 1.6 Unit Summary This unit serves as an introduction to the entire module. We have introduced some fundamental concepts in the area of database systems including data, databases, and DBMSs bases on which you will be able to explore further issues such as data modelling, relational database design, query and Web-database design and development, data warehousing and data mining. A simple Webdatabase example was also given to illustrate how information stored in a database can be retrieved and displayed through a Web page. The unit further introduced and highlighted the importance of distributed database management system since distributed databases arenow at the core of many industries. The basic components of a DDBMS environment were identified. The usefulness of such distributed source of data was also introduced through the technologies of data warehousing and data mining. These technologies will be examined in greater detail in later units. A lot of questions may rise after studying this unit, for example: How do I create a database and organise the tables within it? How can I query database records? Can I insert, delete and update records? How can I query and update database records from a Web page, for example, from HTML forms? How to configure a Web server to run ASP code? What if I want to run ASP code on my own PC? Are there any other ways to construct Web-database applications besides ASP? How should I decide which method to adopt? The rest of the module is designed to answer these questions and many more. Before you move onto the next unit you must complete the end of unit self assessment. Activity 1.1 – Looking up Glossary Entries In the Basic Concepts of Database and Database Designers and Users sections of this unit the following phrases have glossary entries: Database DBMS Relational data model (1) In your own words write a short definition for each of these phrases. (2) Look up and make notes of the definition of each phrase in a glossary. (3) Identify (and correct) any important conceptual differences between your definition and the glossary entry. Feedback on Activity 1.1 – Looking up Glossary Entries Such exercises as defining terms in your own words, then comparing your definition with the glossary entry (or perhaps a definition in some other source) can be an effective way of evaluating your understanding of new concepts. It is important to highlight differences between your understanding and sources such as the glossary, since such differences are an indication that you may need to study a topic in more detail to resolve conceptual misunderstandings. You may also wish to extend – i.e. personalise – the glossary (either on paper, or electronically) by modifying or adding new definitions and references for terms or phrases you feel are important. Activity 1.3 - Show the Components of DDBMS Take a pencil and draw a diagram for the following scenario: ABC Company has four branch offices located at different sites. All these four branches have their own fragment of database and they are connected by a communication medium. Now extend the diagram to represent a different scenario where two different network topologies are connected together and not all the sites have their own copy of a database. Feedback on Activity 1.3 - Show the Components of DDBMS This activity requires drawing communication links between nodes located at different branches. Four databases are attached to the nodes. You may identify some other components, for example, topology of networks, Transaction Processing and Data Processing. You may wish to extend the diagram by showing how different networks are connected by a wide area network. This diagram will give you an understanding of the need of basic components that are used to establish a DDBMS environment. Review Questions Review Question 1.1 Explain the following terms: (1) Data (2) Database (3) Database Management System (DBMS). Review Question 1.2 With the assistance of an example, discuss the problems of a file system for data storage and manipulation Review Question 1.3 Discuss the significant characteristics of database systems in comparison with file systems. Review Question 1.4 Discuss the main characteristics of a DBMS. Review Question 1.5 What is meant by data model? Discuss the different approaches adopted by different data models for data representation. Review Question 1.6 Describe the use of a conceptual data model in database design. Review Question 1.7 Explain the main responsibilities of a DBA in database applications. Review Question 1.8 List the differences between homogeneous and heterogeneous DDBMS. Answers to Review Questions Answer to Review Question 1.1 (1) Data is known facts that can be recorded and can be interpreted to provide information. (2) A database is a collection of related data managed by a Database Management System (DBMS). (3) A DBMS is a software system that is designed to manage collections of data that are large, shared, and persistent. Answer to Review Question 1.2 A file system stores data permanently in files. In a file system, each different application has its own files. The main problem with such a file system is data redundancy and inconsistency. Because the same data may be required by different applications, multiple copies of the same data file should then be generated and made available to those applications. If one application makes any change to a common file, the file has to be changed across all applications that use it, otherwise, inconsistency errors occur. One approach to solve the problem is to share files among different applications. This will alleviate the problems of redundant and inconsistent data among different applications, but other problems may emerge as indicated below: If applications have to share files, the file structure that suits one application might not suit another. If the structure of the data file needs to be changed in some way, this alteration will need to be reflected in all application programs that use that data file. This problem is known as physical data dependency. While a data file is being processed by one application, the file will not be available for other applications or for ad hoc queries. (Similar examples of file sharing system as given on page 10 should be used to explain the above points.). Answer to Review Question 1.3 The database approach is an improvement on the shared file solution as the use of a DBMS provides facilities for efficient and effective querying, data security and integrity, and simultaneous accessing of data. The main characteristics of database systems are: Large – Databases can be large, in the sense that they can contain thousands of billions of bytes and are, in general, certainly larger than the main memory available. Shared – Databases are shared, in the sense that various applications and users must be able to gain access to data of common interest. In contrast to file systems, the redundancy of data is reduced, since repetitions are avoided, and consequently, the possibility of inconsistencies is reduced. In addition, in order to guarantee shared access to data by many users operating simultaneously, the DBMS makes use of special mechanism called concurrency control. Persistent – Databases are persistent, in the sense that they have a lifespan that is not limited to single executions of the programs that use them. Conversely, data managed by a program in main memory has a life that begins and ends with the execution of the program; therefore, such data is not persistent. Answer to Review Question 1.4 Reliability – DBMSs ensure reliability, in the sense that they have the capacity to preserve the content of the database (or at least to allow its reconstruction) in case of hardware or software failure. To fulfil this requirement, DBMSs provide specific functions for backup and recovery. Privacy – DBMSs ensure data privacy. Each user, who is recognised by a user name that is specific to that user’s access to the DBMS, is qualified to carry out only certain operations on the data, through the mechanisms of authorisation. Efficiency – DBMSs are concerned with efficiency, which is the capacity to carry out operations using appropriate amounts of resources (time and space) for each user. This characteristic relies on the techniques used in the implementation of the DBMS, and how well the product has been designed. Effectiveness – DBMSs increase effectiveness by providing various functions and services to different users to make the activities of the users productive. Answer to Review Question 1.5 A data model is a combination of constructs used to organise data. Each data model provides structuring mechanisms, similar to the type constructors of programming languages, which allow the definition of new data types based on constructors applied to predefined elementary types. The relational data model organises data in a collection of records with a fixed structure. A relation is often represented by means of a table, whose rows show specific records and whose columns correspond to the fields of the record; the order of the rows and columns is irrelevant. The hierarchical data model is based on the use of tree structures (and hierarchies, hence the name), defined during the first phase of development of DBMSs in the sixties. The network data model is also known as the CODASYL model. It is baseed on the use of graphs, developed in the early seventies. The object data model was developed in the eighties in order to overcome some limitations of the relational model. In object databases, each entity of the real world is represented by an object. Answer to Review Question 1.6 Conceptual data models are used in the preliminary phase of the database design process, to analyse the application in the best possible way without implementational contamination. For example, the entity-relationship data model assists in the identification of entities and their relationships in a real world application. Conceptual data models have been introduced to describe data in a manner independent of the logical model. Their name comes from the fact that they tend to describe concepts of the real world, rather than the data needed for their representation. Answer to Review Question 1.7 A DBA is responsible for the design, control and administration of the database. A DBA has the task of mediating the various requirements, often conflicting, expressed by the users, ensuring centralised control over the data. In particular, a DBA is responsible for guaranteeing services, ensuring the reliability of the system, and managing the authorisations for access to the data. Answer to Review Question 1.8 Heterogeneous DDBMS: Different hardware at different sites Different DBMS products at different sites Different data models at different sites Homogeneous DDBMS: Same hardware are used at all sites Same DBMS products at all sites Same data models at all sites Group Discussion Use the WebCT(Oasis) discussion facility to post your comments on the following topic. Discussion topic 1: Compare the following pairs of concepts/techniques: (1) File system vs. database system (3) Naïve user vs. sophisticated user Conceptual vs. logical data model Discussion topic 2: Discuss the advantages and disadvantages of using DBMS for managing data in general, and for managing information on the Web. Keep notes in your learning journal of your learning process before you proceed to the next section. Contribution to Discussion You are expected not only to define the terms but also to reflect and share your experiences on the concepts. You may draw analogies and provide examples to extend the concepts. Learning Journal In your learning Journal write up your experience of your learning on this unit. Say what you thought was good or bad, what you had difficulty understanding, and how you resolved your problems. Log errors and difficulties to assist in future programming learning. Make notes of key points or issues to follow up from the activities. Log issues that are raised during your group discussion. End of Unit Self Assessment Before proceeding to the next unit you should work through the End of Unit SelfAssessment on Web CT. When you have completed the questions you will be able to obtain sample answers for future reference. Your performance with these questions will not affect your grade for the module, but may be monitored so that your tutor can be alerted if you are having difficulty. Please contact your tutor if you feel you have not done as well as you expected. Don’t forget to complete the End of Unit Self-Assessment Extra Content and Activities R. Elmasri and S. B. Navathe, 3rd Edition, 2000, Fundamentals of Database Systems, Addison-Wesley Chapter 2: Database System Concepts and Architecture pp.27 – 36 Data Mining Your Web Site Jesus Mena, 1999, Digital Press, ISBN 1-55558-222-2