Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Many Mini Topics
Mark Stamp
Many Mini Topics
1
Brief Topics
Much
more to machine learning than
HMM, PHMM, PCA, SVM, clustering
Here, briefly cover several topics…
o k-Nearest Neighbors (k-NN), Neural
Networks, Boosting (AdaBoost), Random
Forests, Linear Discriminant Analysis
(LDA), Vector Quantization, Naïve Bayes,
Regression Analysis, Conditional Random
Fields (CRF)
Many Mini Topics
2
Brief Topics
Some
topics are here because they
are short and simple
o Not worth an entire chapter
o K-Nearest Neighbors, for example
Ironically,
some topics are here
because they are too big
o Would require an entire book to cover
o Neural Networks, for example
Many Mini Topics
3
One Not-So-Brief Topic
Linear
Discriminant Analysis (LDA)
We spend more time on this one
o Not chapter-length, but more than others
LDA
is interesting and useful
And also has connections to several
other techniques that we studied
o SVM, PCA, and to a lesser extent,
clustering
Many Mini Topics
4
k-Nearest Neighbor
Many Mini Topics
5
k-Nearest Neighbor
In
k-NN, given a labeled training set
And, given a point we want to classify
o That is, a point not in training set
We’ll
let training data “vote”
Who gets to vote?
o That is, which data points in the training
set get to vote?
And
how to count (weight) the votes?
Many Mini Topics
6
k-NN
Which
data points get to vote?
o If it’s a “national” election, and majority
rules, most numerous class always wins
o That’s not very informative, so not going
to have universal suffrage in k-NN
But
what about “local” elections?
o That is, only the training data nearby
gets to vote
o This might be useful…
Many Mini Topics
7
k-Nearest Neighbors
Given
a set of labeled training data…
And given a point to classify
Classify based on k nearest neighbors
o Where neighbors are in training set
o Value of k specified in advance
The
simplest ML method known to man
o And not to mention, woman
o Simple, at least wrt training
Many Mini Topics
8
k-NN Example
Red circles and blue
squares are training data
Note that we assume
labeled training data
Suppose we want to
classify green diamond…
And we want to keep it
as simple as possible
Many Mini Topics
9
1-NN Example
1-NN
o Or more simply,
nearest neighbor
Since
blue square b
is nearest…
Classify green
diamond x as “blue”
Many Mini Topics
10
3-NN Example
3-Nearest
Neighbors
Classify based on 3
nearest points
3 nearest to x are…
o 2 red points, r1, r2,
and 1 blue point, b
Using
3-NN, we
classify x as “red”
Many Mini Topics
11
k-NN Variations
We
could also weight by distance
o E.g., use 1/d(x,b) for each blue b nearest
neighbor, and 1/d(x,r) for red r
o Sum these by color, biggest sum wins…
We
might weight by class frequency
o Suppose training set has B blue and R
red, with R > B
o Weight each red as 1, each blue as R/B
Might
Many Mini Topics
also consider a fixed radius
12
k-NN
Weighted by
Distance
Suppose
use 1/d(x,y)
For this weight, 3-NN
classifies x as “blue”…
o Assuming
1/d(x,b) > 1/d(x,r1) + 1/d(x,r2)
Many Mini Topics
13
k-NN Weighted by Frequency
Suppose
we weight
by frequency
Then each red is 1
And each blue is 2.5
In this case, 3-NN
classifies x as blue
o Blue “score” is 2.5
o Red “score” is 2.0
Many Mini Topics
14
k-NN Advantages
k-NN
is “lazy learning” algorithm
o No (none, nada, zippo) training required
o All computation deferred to scoring phase
In
limit, k-NN tends to (near) optimal
o As size of training set grows
o Although optimal k also grows
o Optimal in sense of “Bayes error rate”
Works
for multi-classification
o I.e., not restricted to binary classification
Many Mini Topics
15
k-NN Disadvantages
Scoring
is not so straightforward
o In naïve approach, distances to all points
needed for each score computation
o Can use fast neighbor search algorithms
(e.g., Knuth’s “post office problem”)…
o …but then lose some of the simplicity
Very
sensitive to local structure
o Random variations in local structure of
training set can have undesirable impact
Many Mini Topics
16
Bottom Line
k-NN
is as simple as it gets
o And simple is good, if it works
Training
is non-existent
Scoring is somewhat more involved
Lots of variations on the theme
Can be combined with other techniques
o E.g., k-NN used in scoring phase of PCA
Many Mini Topics
17
Neural Networks
Many Mini Topics
18
Neural Networks
Aka
“Artificial Neural Networks”
o When a 3 letter acronym is required…
Class
of ML algorithms that model
interconnected neurons of brain
Several types of Neural Networks
o We only consider 1 type (MLP)
o And only from a very high level
Why
not more about Neural Networks?
Many Mini Topics
19
Neural Networks
Why
model the brain?
Human brain has the ability to learn
o Computers (and politicians), not so much
Neurons
are highly interconnected
Massive parallelism in brain
Some ability to self-organize
High fault-tolerance
Able to generalize from experience
Many Mini Topics
20
Multilayer Perceptron
MLP
is a popular type of NN
o MLP is a supervised learner
o An input layer, an output layer, and 1 or
more hidden layers in between
o Each layer is fully connected to preceding
o Any number of nodes in a layer
o Nonlinear functions connect layers
Why
nonlinear functions?
Many Mini Topics
21
MLP
with
Two
Hidden
Layers
f1, f2,
g
functions
Edges are
weights
Many Mini Topics
22
MLP
The
functions are specified
o Typically, sigmoid functions (i.e., smooth
approximation to step function)
o For example, f(x) = tanh(x)
Training
to determine weights (edges)
How to train?
Method is known as back-propagation
Many Mini Topics
23
Back-Propagation
Make
small modifications to weights
so that error decreases
Usually, lots of weights, so random
modifications not going to work
Want error reduction to be large
o Ideally, maximum possible at each step
o Sounds like a job for calculus….
We
omit the details here
Many Mini Topics
24
Plusses of Neural Network
Lots
of recent interest in NNs
o So, it is definitely a hot topic
“Deep
Learning” seems to be
synonymous with Neural Networks
o Otherwise a fairly vacuous term
Some
good results on hard problems
Other?
Many Mini Topics
25
Minuses of Neural Networks
Mysterious
models may not tell us much
o A concern, especially in research mode
Computationally
intensive (training)
Conceptually, how different are NNs?
o “Hidden” intermediate layer is typical of
machine learning techniques
o E.g., HMM, PHMM, SVM, EM clustering, …
o Has been shown that MLP related to SVM
Many Mini Topics
26
Neural Networks
NNs
have long (if rocky) history
Lots of hype surrounding NNs
A rose by any other name?
o Modeling the brain sounds good (AI)
But,
biologically-inspired models not
always ideal for engineering!!!
o Modern aircraft do not fly like birds
o Airplanes do not (intentionally) flap wings
Many Mini Topics
27
Bottom Line
Neural
Networks powerful and useful
But, NNs have plusses and minuses
compared to other ML techniques
Not a good idea to treat NNs as the
ML equivalent of a universal solvent
o Better to view as just as another tool
o Do not get too obsessed with the name
Many Mini Topics
28
Boosting
Many Mini Topics
29
Boosting
Suppose
that we have a (large) set of
binary classifiers
o All of which apply to the same problem
Goal
is to combine these to make one
classifier that’s as strong as possible
We’ve already seen that SVM can be
used to generate such a “meta-score”
o But boosting is ideal for weak classifiers
Many Mini Topics
30
Boosting
Intuitively,
stronger classifiers will
yield a better meta-score
o This is almost certainly true when
combining scores using SVM, for example
Boosting
is somewhat counter-intuitive
Boosting produces a strong classifier
from many (very) weak classifiers
o An arbitrarily strong classifier, provided
we’ve got enough (weak) classifiers
Many Mini Topics
31
Boosting Your Football Team
Suppose
you are a HS football coach
A lot of players tryout for your team,
but almost all of them are mediocre
o In fact, your best players are only
marginally better than playing nobody
Can
you field a good team?
What strategy might you use to build
a strong team from your players?
Many Mini Topics
32
Boosting Your Team
Suppose
you simply choose the best
player at each position
But, your best quarterback is terrible
o So your receivers will never catch a pass
o Best receiver would be wasted at receiver!
So,
it might be better to play your best
receiver elsewhere (e.g., defense)
o And put someone else at receiver
Many Mini Topics
33
“Boosting” Your Team
1.
2.
3.
4.
5.
Here is one “adaptive” strategy/algorithm…
Select the best player and decide what
role(s) he can best play on your team
Determine the biggest weakness remaining
From unselected players, choose one that
can best improve weakness identified in 2
Decide exactly what role(s) the newlyselected player will fill
Goto 2 (until you have a team)
Many Mini Topics
34
Boosting Your Team
Will
strategy on previous slide give you
the best possible team?
o Not necessarily, as “best possible” would
probably require an exhaustive search
But,
this strategy might produce a
better team than an obvious approach
o E.g., selecting best player at each position
Especially
Many Mini Topics
when players are not so good
35
(Adaptive) Boosting
Boosting
is kind of like building your
football team from mediocre players
At each iteration…
o Identify biggest remaining weakness
o Determine which of available classifiers
will help most wrt that weakness…
o …and compute weight for new classifier
Note
that this is a greedy approach
Many Mini Topics
36
Boosting Strengths
Weak
(nonrandom) classifiers can be
combined into one strong classifier
o Arbitrarily strong!
Easy
and efficient to implement
There are many different boosting
algorithms
We’ll only look at one algorithm
o AdaBoost (Adaptive Boosting)
Many Mini Topics
37
Boosting Weaknesses
Very
sensitive to “noise”, including…
o Mislabeled training data
o Extraneous features
So,
in practice may not get wonderful
results promised by the theory
This issue should become clear as we
present the algorithm
Many Mini Topics
38
AdaBoost
AdaBoost
is the most popular and
best-known method of boosting
Iterative approach
o Make selection based on what has been
selected so far
o This is the sense that it is adaptive
And
we’ll always be greedy
o Get biggest boost possible at each step
Many Mini Topics
39
AdaBoost
Assume
that we have a labeled training
set of the form (Xi,zi), for i = 1,2,…,n
o Where Xi is data point and zi is label
o We’ll assume labels are +1 and -1
We
also have L classifiers (all weak)
o Denoted c1, c2, …, cL
o Each cj assigns a label to each Xi
We
combine cj to yield a classifier C(Xi)
Many Mini Topics
40
AdaBoost
We
construct table where +1 and -1
are classifications provided by ci
Use
this info in AdaBoost algorithm
Many Mini Topics
41
AdaBoost
Iterative
process…
Generate a series of classifiers, call
them C1(Xi), C2(Xi), …, CM(Xi)
o Where C(Xi) = CM(Xi) is desired classifier
And
Cm(Xi) is of the following form
o Cm(Xi) = α1k1(Xi) + α2k2(Xi) +…+ αmkm(Xi)
o And Cm(Xi) = Cm-1(Xi) + αmkm(Xi)
o And each kj is one of the classifiers ci
o And αi are weights
Many Mini Topics
42
AdaBoost
At
iteration j, we need to decide…
o Which unused classifier kj = ci to include
o What weight αj to assign to kj
In
football analogy, at each iteration…
o Select one of the unchosen players
o Determine “role” for that player
How
to do this so that we get the
most improvement (in greedy sense)
Many Mini Topics
43
AdaBoost
We
define exponential “loss function”
o Loss function is like a score, except a
smaller loss is better
o In contrast, a bigger score is better
Loss
We
(or error) function at step m is
need to determine km and αm > 0
Many Mini Topics
44
AdaBoost
Cost
function:
Write
cost as:
Where:
Rewrite
Many Mini Topics
sum as:
45
AdaBoost
We
have:
We
rewrite this as:
This simplifies:
And hence:
o W = W1 + W2 is constant this iteration
Choose
Many Mini Topics
km so that W2 is minimized!
46
AdaBoost
Now,
we have selected km
What about corresponding weight αm ?
Recall:
Since we know km, we know W1 and W2
Calculus:
Set to 0, solve to find:
Where rm = W2/W
Many Mini Topics
47
AdaBoost
Summary
of mth iteration…
Select km so that number of misses
(i.e., W2) is minimized
o Like choosing next player as the one that
does the most good for your team
Once
km is known, compute W2 and W
And choose αm as on previous slide
o I.e., put new player in best role for team
Many Mini Topics
48
AdaBoost
AdaBoost
can be considered a method
to reduce dimensionality
o Algorithm only selects things that will
improve overall classifier
o Irrelevant “features” (classifiers) ignored
Recall,
mislabeled training data is the
Achilles heel of boosting
o AdaBoost also has issues with outliers due
to exponential weighting…
Many Mini Topics
49
Bottom Line
Given
lots of weak classifiers
o May be very weak, just not random
Can
construct arbitrarily strong
classifier
AdaBoost uses greedy approach
o Maximize improvement at each step
o Amazingly simple idea
o But, sensitive to noise…
Many Mini Topics
50
Random Forest
Many Mini Topics
51
Random Forest
Random
Forest (RF) is generalization
of a Decision Tree
Decision Tree is really, really simple
o And very intuitive
So,
why do we need to generalize?
Decision Trees tend to overfit data
Random Forest avoids this problem
o But lose some of the intuitive simplicity
Many Mini Topics
52
Decision Trees
A
decision tree is just what it says…
o Tree that is used to make decisions
o Kind of like a flow chart
Each
node is a test condition
Each branch is outcome of test
represented by corresponding node
Leaf nodes contain the final decision
o Simple, simple, simple
Many Mini Topics
53
Decision Trees
Advantages?
o Can be constructed with little/no data
and can be tested if/when data available
o Easy to understand, easy to use, easy to
combine with other learning methods, …
Disadvantages?
o Constructing optimal tree is NP complete
o Overfit, complex trees, how to prune?, ...
o Some concepts not easy to fit to trees
Many Mini Topics
54
Decision Tree Example
Suppose
that we have labeled training
data for malware and benign samples
o Data consists of file size and entropy
We
see that malware tends to be
smaller in size with higher entropy
o Compared to benign samples
Easy
to make decision trees
o Next slides…
Many Mini Topics
55
Decision
Tree
Example
Large
vs
small, high
vs low
thresholds
based on
data
Many Mini Topics
56
Decision
Tree
Example
Other
order
works
too…
Which is
better?
Many Mini Topics
57
Generating Decision Trees
Generating
optimal decision tree can
be hard, so what to do?
Approximate! But how?
We’ll use a simple greedy approach
o Choose feature that provides most
information gain and split data
o From remaining features, select the one
that provides most information gain
o Continue until gain below some threshold
Many Mini Topics
58
Decision Tree
Why
greedy?
o Want to use best classifiers first, so we
can generate smaller trees
o Want most info gain closer to root (good
if we want to prune tree)
o Fast and efficient to construct, since no
backtracking or other complex algorithm
o Make use of all relevant information in
training data
Many Mini Topics
59
Information Gain
“Gain”
can be measured using entropy
o Recall, entropy measures uncertainty
Information
gain for feature A ?
o Entropy reduction if data is split on A
We
want to maximize information gain
o Compute gain for each remaining feature
o Split on feature with biggest info gain
o Repeat until gain is below some threshold
Many Mini Topics
60
Information Gain
Let
P(xi) be probability of outcome xi
Then entropy of X = (x1,x2,...,xn) is
Suppose
that we have 10 malware and
10 benign samples
Measure file size, entropy, and number
of distinct opcodes for each
Many Mini Topics
61
Training Data
Notation
o S(X) is size
o H(X) entropy
o D(X) opcodes
How
to set
thresholds?
o Midway
between
averages…
Many Mini Topics
62
Entropy Calculation
Then,
for example, we use a threshold
of 115 for file size
From training data
o Tm = {X3,X5,X6,X7,X9,X10,Y4,Y5,Y8,Y9}
classified as malware
o Tb = {X1,X2,X4,X8,Y1,Y2,Y3,Y6,Y7,Y10}
classified as benign
Compute
Many Mini Topics
entropy of Tm and Tb
63
Information Gain
Entropy
computed as
Information
gain ?
o Entropy of parent node minus average
weighted entropy of child nodes
For
size feature, information gain is
o GS = 1.0 – 0.9710 = 0.0290
Many Mini Topics
64
Information Gain
Similarly,
we compute
o GS = 0.0290, GH = 0.1952, GD = 0.5310
Conclusion?
Want
to make first split based on
number of distinct opcodes, D(X)
Then need to recalculate information
gain for remaining features
o To decide which to select for 2nd level
Many Mini Topics
65
Bagging
Decision
Tree is good, maybe too good…
o Tends to overfit data
o Overfitting is bad in ML (why?)
What
to do?
Bagging
o Multiple decision trees on subsets of data
o Then combine results (e.g. majority vote)
o Very easy way to reduce overfitting
Many Mini Topics
66
Bagging Example
Suppose
we have sample U to classify
We measure S(U) = 116 and H(U) = 7
Recall that based on training data
o 5.5 is threshold for entropy H(X)
o 115 is threshold for size S(X)
Suppose
we classify using tree that
splits first on entropy, then size
o Ignoring opcode feature
Many Mini Topics
67
Bagging Example
Then
U is classified
as benign
But this is suspect…
o Why?
Suppose
instead,
use bagging
o As on next slide…
Many Mini Topics
68
Bagging
Suppose
Then
we select subsets
subset A is
Many Mini Topics
69
Bagging
For
subset A …
Threshold for
S(X) is 117 and
H(X) is 5.9
And U classified
as malware!
Many Mini Topics
70
Bagging
Easy
to show that U is classified as…
o Malware based on subset A
o Benign based on subset B
o Malware based on subset C
So,
by majority vote, U is malware
Recall, U was benign based on all data
o But that classification looked suspect
Bagging
Many Mini Topics
better generalizes the data
71
Random Forest
Random
Forest uses bagging in 2 ways
o Bagging of data (as on previous slide)
o And bagging of features
How
to bag features?
Select subset of features and ordering
RF training algorithm use heuristic to
do smart bagging
Many Mini Topics
72
Random Forest and k-NN
Interesting
connection between RF
and k-NN algorithms
As usual, let (Xi,zi), i=1,2,…,n be
training set, and each zi is -1 or +1
Then define weight function
And
define
Many Mini Topics
73
Decision Tree and k-NN
For
a given decision tree, define
And
So
what?
Many Mini Topics
74
Decision Tree and k-NN
Then
k-NN is equivalent to…
o Classify X as type +1 if scorek(X) > 0
o And type -1 otherwise
And
Decision Tree (DT) is same as…
o Classify X as type +1 if scoret(X) > 0
o And type -1 otherwise
DT
and k-NN are neighborhood-based
o But different neighborhood structure
Many Mini Topics
75
Random Forest and k-NN
Random
Forest is collection of DTs
So, same approach as on previous
slides applies to RF
Implies RF also neighborhood-based
o Like decision tree…
o ...but neighborhood structure is more
complex
Somewhat
Many Mini Topics
surprising connection
76
Bottom Line
Decision
tree is very simple idea
Bagging data generalizes decision tree
o Less prone to overfitting
Random
Forest generalizes bagging
o Bag both data and features
Often,
results
Many Mini Topics
Random Forest gives very good
77
LDA
Many Mini Topics
78
LDA and QDA
Linear
Discriminant Analysis and
Quadratic Discriminant Analysis
For both, the concept is simple
Based on labeled data, separate match
from nomatch region
o In LDA, using a (linear) hyperplane
o In QDA, use a quadratic surface
Easy
to visualize in 2-d
Many Mini Topics
79
LDA vs QDA
In
2-d, separate with line vs parabola
Many Mini Topics
80
LDA vs QDA
LDA
is simpler, fewer parameters
o Connections to both SVM and PCA
o But, no kernel trick, and projection of data
is simpler in LDA
QDA
more complex, more parameters
o Can separate some cases that LDA cannot
o In practice, often not much difference
We’ll
only consider LDA here
Many Mini Topics
81
LDA and PCA and SVM
(Oh My!)
LDA
training can be similar to PCA
o Training set consists of m “experiments”
with n “measurements” each
o Form a covariance-like matrix
LDA
training also related to SVM
o We project/separate based on hyperplane
o But, no kernel trick, so LDA is simpler
We’ll
see Lagrange mult. & eigenvectors
Many Mini Topics
82
Big Idea Behind LDA?
Scatter
is closely related to variance
Mean and scatter of training data is
not under our control
o But, have some control in projection space
Project
training data onto hyperplane...
o Making distance between class means
LARGE and the within class scatter
But
small
how?
Many Mini Topics
83
LDA and Clustering
Again,
want projected data to have…
o Between-class means that are far apart
o Within-class scatter is small (both classes)
Recall
that in clustering, we want...
o Distance between clusters to be large
o And each cluster should be compact
o Replace “cluster” with “class” in LDA
So,
LDA is related to clustering too!
Many Mini Topics
84
Projection Examples
Projecting
onto hyperplane
Why is projection (b) better than (a)?
Many Mini Topics
85
LDA Projection
Again,
in LDA we maximize separation
between means and minimize scatter
o In the projection space
But,
why worry about the scatter?
That is, why not just separate means?
o Kind of like the opposite of K-means
o Would be easier to forget about scatter
o What could possibly go wrong?
Many Mini Topics
86
LDA Projection
In
(a), means more widely separated
But in (b), much smaller scatter
Many Mini Topics
87
LDA Training
Want
to account for both within-class
cohesion and between-class separation
o Cohesion based on scatter in proj. space
o Separation based on projected means
LDA
uses a fairly simple approach
o One expression that is a function of both
cohesion and separation
But
first, we need some notation
Many Mini Topics
88
Notation
Let
X1,X2,…,Xm and Y1,Y2,...,Yn be
training vectors of 2 classes
Each vector is of length l
(Scalar)
Where
Many Mini Topics
projection of X is
vector w is to be determined
89
Mean and Scatter
Class
means are
o Note μx and μy are vectors
And
class scatter
o Note sx2 and sy2 are scalars, not vectors
Next,
want to compute projected
means and scatter
Many Mini Topics
90
Projected Mean and Scatter
Mean
of X in projection space
o And similar for projected mean of Y
Scatter
of X in projection space
o And similar for projected scatter of Y
Many Mini Topics
91
Projected Means
Consider
the function
o argmax M(w) is w that has largest
distance between projected means
Consider
the function
o argmin C(w) is w with smallest scatter
o argmax 1/C(w) is same as argmin C(w)
Many Mini Topics
92
Fisher Discriminant
In
general…
o argmax M(w) ≠ argmax 1/C(w)
So,
how (or what) to optimize ?
In LDA, we’ll keep it simple
Then
argmax J(w) is desired solution
Function J(w) is Fisher Discriminant
Many Mini Topics
93
Fisher Discriminant
Why
maximize Fisher Discriminant?
Combines
both large separation and
small scatter in one simple formula
Have we seen anything similar before?
Reminiscent of silhouette coefficient
Many Mini Topics
94
Example
Which
has larger Fisher Discriminant?
Why?
Many Mini Topics
95
Maximizing J(w)
Expanding,
we have
o Note J(w) defined in projection space
Game
plan…
o Write J(w) in matrix form, then maximize
resulting matrix function
o We can easily relate to other methods
Many Mini Topics
96
Matrix Form
Define
within-class scatter matrices
o Essentially, covariance matrices of X and Y
o Total within-class scatter: SW = Sx + Sy
Between-class
scatter:
These matrices all defined in input
space, not in projection space
Many Mini Topics
97
In Projection Space
But
J(w) defined in projection space…
All of matrices on previous slide have
analog in projection space
o As above, use “⌃” for projection space
Define
analog of SB as
Can be shown that
Define
then
Many Mini Topics
98
Matrix Form
In
matrix form,
Let’s maximize!
o Note that if vector w = argmax J(w) then
αw also works, for any scalar α
o So, let’s require w to satisfy wTSWw = 1
The
problem can now be stated as
o Maximize: wTSBw
o Subject to: wTSWw = 1
Many Mini Topics
99
Lagrange Multipliers
The
problem can now be stated as
o Maximize: wTSBw
o Subject to: wTSWw = 1
Lagrangian
is
o L(w,λ) = wTSBw + λ(wTSWw – 1)
How
to solve?
Partial derivatives, set equal to 0…
Many Mini Topics
100
Lagrange Multipliers
Equivalent
version of the problem is
o Minimize: - ½ wTSBw
o Subject to: ½ wTSWw = 1
In
this form, Lagrangian is
o L(w,λ) = - ½ wTSBw + ½ λ(wTSWw – 1)
Take
derivatives wrt w, we find
o - SBw + λSWw = 0
o Or SBw = λSWw
Many Mini Topics
101
Lagrange Multipliers
Solution
w to LDA training problem
satisfies SBw = λSWw
Now, suppose the inverse SW-1 exists,
and define S = SW-1 SB
Then desired solution w satisfies
o Sw = λw
We
see that w is an eigenvector of S
o And Lagrange multiplier λ is its eigenvalue
Many Mini Topics
102
LDA and PCA and SVM
Previous
slide shows a deep connection
between LDA, PCA, and SVM
o That is, Lagrange multipliers (SVM) and
eigenvectors (PCA) arise in LDA training
And
it gets even better…
o Recall, L(w,λ) = -½ wTSBw + ½ λ(wTSWw – 1)
o Dual: max L(λ) = c1 + c2λ where c2 > 0
o Already know that λ is an eigenvalue of S
o So, λ must be largest eigenvalue of S
Many Mini Topics
103
Comparison of LDA and PCA
PCA
determine score based on large
variances
LDA distinguishes between classes
based primarily on means
So, LDA does well if means separated
o LDA will not do so well if means are close,
even if variances are very distinguishing
o Of course, underlying LDA and PCA
problems are different
Many Mini Topics
104
Numerical Example
Given
the labeled
training data…
Want to train LDA
o That is, find
projection vector w
o So that J(w) is max
o We’ll solve based on
Sw = λw
Many Mini Topics
105
Mean and Scatter Matrices
For
given training data, means are
Scatter
Many Mini Topics
matrices
106
Matrices
From
previous slide, we find
And
we find
So that
Many Mini Topics
107
Eigenvectors
We
find
Eigenvectors
and
of S are
o Eigenvalues λ1=0.8256 and λ2=0.0002
Many Mini Topics
108
Solution?
We
have
Just
for fun, Let’s project training
data onto each of w1 and w2
Slope of w1 is
o m1 = 0.7826/0.6225 = 1.2572
Slope
of w2 is
o m2 = -0.4961/0.8683 = -0.5713
Many Mini Topics
109
Projecting Onto Eigenvectors
Comparing
Many Mini Topics
eigenvectors w1 and w2
110
LDA
Projecting
onto largest eigenvector of
S is best possible result for J(w)
Easy to generalize LDA to more than
2 classes
o Vector w replaced by a matrix, each
column of which determines a hyperplane
o These hyperplanes partition the space
for classification
Many Mini Topics
111
Bottom Line
LDA
is useful in its own right
Also, interesting because of many
connections to other ML techniques
o PCA, SVM, clustering, other?
o We related Lagrangian to eigenvectors
LDA
generalizes to more classes
o QDA also a generalization of LDA
Nice!
Many Mini Topics
112
Vector Quantization
Many Mini Topics
113
Vector Quantization
In
VQ we have codebook vectors
o Not to be confused with codebook cipher!
o These are prototypes for classification
o That is, each vector is associated with one
codebook vector
Does
this sound at all familiar?
Very closely related to K-means…
…And EM clustering
Many Mini Topics
114
VQ Example
Rounding
to nearest integer is ultra
simple 1-d example of VQ
Codebook
elements are integers
All elements in one half-open interval
associated with a specific prototype
Many Mini Topics
115
Linde-Buzo-Gray Algorithm
LBG
algorithm to find VQ clusters
Algorithm is given in book…
o Essentially same as K-means...
o Specify K and initial codebook
o Assign points based on nearest prototype
o Update the codebook (center of mass)
o Compute distortion to decide whether to
do another iteration or not
Many Mini Topics
116
VQ vs K-Means
VQ
can be considered a generalization
of K-means
o K-means uses Euclidean distance to
measure distortion
o In VQ, we can use other measures of
distortion…
Examples
Many Mini Topics
of other measures?
117
Naïve Bayes
Many Mini Topics
118
Naïve Bayes
Why
is Naïve Bayes naïve?
o We make (naïve?) simplifying assumption
o Specifically, we assume independence
o Often, not a good reflection of reality…
o …But makes the problem easier to solve
And
why is it Bayes?
o We’ll use Bayes Formula
Many Mini Topics
119
Declaration of Independence
Why
independence?
Assume we have n vectors
o X1, X2, …, Xn
o Each vector is of length m
o Centered, so mean in each component is 0
Independence
o For all i ≠ j
Then
implies cov(Xi,Xj) = 0
covariance matrix is diagonal
Many Mini Topics
120
Simplify, Simplify, Simplify
But,
we don’t get to choose the data
So, maybe more accurate to say we
approximate by ignoring covariance
What’s the benefit?
o The full covariance matrix is m x m
o Lots of parameters to estimate
By
ignoring covariance, we only have m
variances (and means) to worry about
Many Mini Topics
121
What is “Bayes”?
Denote
conditional probability as
o P(A|B) = probability of A given B
Bayes
Formula: P(A|B) = P(B|A)P(A)/P(B)
Or
Or
Many Mini Topics
122
Bayes Formula Example
We
have a test for some illegal drug
o If use the drug, test positive 98%
o If do not use drug, test negative 99%
Also,
only 5 out of 1000 use the drug
Let
o A = {person uses the drug}
o B = {person tests positive for drug}
Want
Many Mini Topics
to find P(A|B)
123
Example
Have
A={person uses the drug} and
B={person tests positive for drug}
Want P(A|B), but hard to compute
On the other hand, P(B|A) is easy
So,
What
Many Mini Topics
the …. ?
124
So What?
Suppose
we want to find best “state”
for given observation
That is, find X that maximizes P(X|O)
o Where X is state and O is observation
o This should look familiar…
But
P(X|O) may be difficult to compute
while P(O|X) is easy
o If so, use P(X|O) = P(O|X) P(X)/P(O)
Many Mini Topics
125
The Bottom Line
Can
use P(X|O) = P(O|X) P(X)/P(O) to
find best state X
o Since P(O|X) often easier than P(X|O)
o Note P(O) is constant, so not needed
o And P(X) usually easy to compute
For
example, consider HMM Problem 2
o Actually, much deeper connections…
o ...As we will discuss later
Many Mini Topics
126
Regression Analysis
Many Mini Topics
127
Regression vs Classification
Classification
schemes classify
o SVM, for example
But,
regression schemes don’t regress
o Regression provides a score (e.g., HMM)
o A way to reason about relationships
In
this section, we consider…
o Linear regression
o Logistic regression
Many Mini Topics
128
Linear Regression
Find
linear model that best fits data
If relationship tends to be linear,
then linear regression will work well
Consider house size vs price
o House size: x-axis
o House price: y-axis
In
general, larger houses cost more
o Except CA, where everything costs more
Many Mini Topics
129
Linear Regression Example
Linear
least squares algorithm
minimizes sum of error terms
Many Mini Topics
130
Linear Regression vs PCA
Linear
least squares and PCA not same
o PCA based on orthogonality
Many Mini Topics
131
Categorical Data
Linear
regression not good choice here
o Piecewise linear better matches data
Many Mini Topics
132
Logistic Function
Smooth
function
that won’t waste
its time between
categories
o Use this in place
of piecewise
linear on
previous slide
Many Mini Topics
133
Logistic Function
The
logistic function is
o And we have y = F(t)
For
data of form x = (x1,x2,…,xn)
o We let t = b0 + b1x1 + ... + bnxn
Then
How
to determine parameters bi ?
Many Mini Topics
134
Logistic Regression
Can
treat F(x) as a probability
o That is, F(x) is probability that x belongs
to the class associated with “1”
o And 1-F(x) is probability of class “0”
To
“train”, must determine the bi
This is done by setting it up as a MLE
o Set derivatives equal to 0, and so on
o Numerical appox. (Newton’s method)
Many Mini Topics
135
Bottom Line
Linear
vs logistic regression?
o For different types of problems
o Linear is easy, logistic is harder
Logistic
regression vs Naïve Bayes?
o Logistic regression gives an approximate
solution to the exact problem
o Naïve Bayes is an exact solution to an
approximate problem
Many Mini Topics
136
Conditional Random Fields
Many Mini Topics
137
Conditional Random Fields
Intuitively
appealing generalization of
Hidden Markov Models (and similar)
CRF algorithms not as nice as HMM
So, CRF may not always be
appropriate
Probably more of a niche topic
o May be good for some specific cases
o May not be good choice in general
Many Mini Topics
138
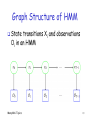
Graph Structure of HMM
State
transitions Xi and observations
Oi in an HMM
Many Mini Topics
139
Graph Structure of HMM
Why
a directed graph?
And why not other interconnections?
Many Mini Topics
140
Pilot Example
Why
worry about these things?
Consider modeling airplane pilot
o Hidden states? Something about pilot
o Observations? Speed, altitude, etc.
Observations
would almost certainly
have an effect on states
o But this is not part of HMM!
o No path from Oi to Xj
Many Mini Topics
141
Linear Chain CRF
Undirected
graph
o For example, Oi can influence state Xi
o Useful for pilot example, for example
Many Mini Topics
142
Big Picture
Ideally,
we want to know joint
probability distribution P(X,O)
o Models all possible interactions
o But, intractable, requires too much data…
So,
we’ll simplify
Makes sense to focus on P(X|O), since
observations assumed known
o Whether training or scoring
Many Mini Topics
143
Generative vs Discriminative
Models
that focus directly on P(X|O)
are said to be discriminative
o No additional simplifying assumptions
o Like logistic regression
Models
that simplify P(X|O) in the
form P(O|X)P(X) are generative
o Simplified by independence assumption
o Like Naïve Bayes
Many Mini Topics
144
Generative vs Discriminative
Discriminative
matter most
focused on things that
o Approximate solution to exact problem
Generative
deals with P(O) to some
extent, which is not itself of interest
o Exact solution to approximate problem
Not
so clear where advantage lies in
theory or practice
Many Mini Topics
145
Generative vs Discriminative
Naïve
Bayes and logistic regression
are a generative-discriminative pair
In HMM, λ is the model, λ = (A,B,π)
Consider HMM forward algorithm…
o We replace P(X,O|λ) with P(O|X,λ)P(X|λ)
What
does this say about HMM?
o HMM is essentially a sequential version
of Naïve Bayes!
Many Mini Topics
146
Generative-Discriminative Pair
Can
show Linear Chain CRF essentially
sequential version of logistic regression
So, HMM and Linear Chain CRF are
another generative-discriminative pair
Are there others?
Yes, we can take this one more level of
generality...
Many Mini Topics
147
Generative-Discriminative Pairs
Many Mini Topics
148
Bottom Line
CRFs
are generalization of HMMs
o Allow for additional interactions
Most
practical is linear chain CRF
Generative-discriminative pairs
o Naïve Bayes-logistic regression
o HMMs-linear chain CRF
Generative
better when data limited?
o Discriminative better when lots of data?
Many Mini Topics
149