Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
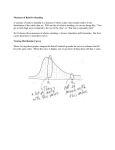
1.1 HOMEWORK TOPIC 1&2. Due Thursday January 15 at the beginning of the lab class. Indicate clearly the procedures used in each exercise. Question 1 ANSWER [15 points] 1.1. The statistics for the data set are as follows Sample Mean St Dev CV 2 SE 1 18 29 10 14 16 12 19 21 19 15 17.3 5.33 30.8 1.687 28.46 2 17 12 27 22 20 11 20 24 16 17 18.6 5.04 27.1 1.593 25.38 3 18 23 19 17 34 14 23 20 21 14 20.3 5.77 28.4 1.826 33.34 4 16 23 14 20 14 11 23 15 17 17 17.0 3.94 23.2 1.247 15.56 18.3 5.02 27.4 1.588 25.683 Plus 20 38 49 30 34 36 32 39 41 39 35 37.3 5.33 14.3 1.687 37 32 47 42 40 31 40 44 36 37 38.6 5.04 13.1 1.593 38 43 39 37 54 34 43 40 41 34 40.3 5.77 14.3 1.826 36 43 34 40 34 31 43 35 37 37 37.0 3.94 10.7 1.247 38.3 5.02 13.1 1.588 Mean S2-S1 S4-S3 -1 -2 -17 0 17 -5 8 3 4 -20 -1 -3 1 0 3 -5 -3 -4 St Dev 2 SE 2 1.3 8.60 2.720 74.01 3 -3.3 6.57 2.077 43.12 -1 7.58 2.39854 58.57 Theoretical 18 Mean 5 25 SE 1.581 1.1. Total average 40 numbers: 18.30 Average of Std. Dev: 5.02 Average Std. dev. of means: 1.588 similar to the theoretical SE of the means 1.581 (5/SQRT(10)). 1.2. The addition of 20 to each value results in an increase of 20 in the means but no change in the standard deviations or standard error of the means. The CV's decrease due to the increase in the means (recall CV = Standard Dev./Mean) 1.3. Average of averages: 18.30 -> Same as the average of 40 samples. Average of the four Standard Errors: 1.588 (close to theoretical one). 1 1.2 and Standard deviation of the 4 means = 1.503 (close to theoretical one). Both are close to the theoretical SE = 5/SQRT(10)=1.581 1.4. By taking random samples of size 10 and finding the sample means, one offsets the variability of the observations against one another. The effect of exceptionally large or small values is “diluted”. Therefore, a set of sample means deviates less from μ (have less dispersion about μ) than a set of individual variates. We see this here, where the standard deviation of the four means (1.503) is much less than the average of the standard deviations of the four samples (5.02). In fact, these two values are related to one another through the formula, 5.02/SQRT(10)=1.588 1.5. Using n=40 and all the samples combined Distribution of sample means for sample size n =40 per mean Y ( n 40) Zi Yi Y ( n 40) n 5 40 0.79057 . 18.3 18.00 0.379473 0.79057 P (Z0.38) = 0.3520 Conclusion: this is not an unusual sample for a population with a mean = 18 and a variance of 25, similar or larger values happen ~35% of the times 1.6. The average is -1, close to the expected value of 0 The average standard deviation is 7.58 (and the average 2= 58.57). This is close to the expected values of 2= 50. (Remember that the variance of A – B = 2A+2B ; even though you are subtracting the samples, the errors accumulate) Mean St Dev SE Var S2-S1 -1 -17 17 8 4 -1 1 3 -3 2 1.3 8.60 2.720 74.01 S4-S3 -2 0 -5 3 -20 -3 0 -5 -4 3 -3.3 6.57 2.077 43.12 -1.0 7.58 2.399 58.57 Question 2 ANSWER [15 points] 2.1. Given a Normal distribution Y with Mean = 1.00 and 2 = 4.00. Find 2.1.1. P (Y≤ 3.44) = P (Z≤ (3.44-1.00)/2= P (Z≤ (1.22) = 1-0.1112= 0.8888 2.1.2. P(0.0≤ Y≤ 2.66)= P(-0.5≤ Z≤ 0.83)= P(Z≤ 0.83)- P(Z ≤ -0.5) –= P(Z≤ 0.83) = 0.7967 P(Z ≤-0.5) = P(Z ≥0.5) =0.3085 = 0.7967-0.3085 = 0.4882 2.1.3. P(Y≤ Yo)= 0.6026 P(Y≥Yo)= 0.3974 In the Z Table= P(Z≥0.26) = 0.3974 If Zo = (Yo-)/ Yo= Zo*+ P(Y ≥(0.26*+))= P(Y ≥(0.26*2+1))= 0.3974 2 1.3 P(Y≥1.52)= 0.3974 Yo= 1.52 Checking P(Y≤ 1.52)=1- P(Y≥1.52)=1- P(Z≥(1.52-1)/2)=1- P(Z≥0.26)=1-0.3974=0.6026 2.1.4. Remember that P(|Z |≤ Zo): Pb that a random Z will be numerically less than Zo, that is, lie within the interval (–Z1, Z1) P(|Z |≥ Zo) : Pb that a random Z will numerically exceed Zo, that is, lie outside the interval (–Z1, Z1) P(|Y|≤ Yo)= 0.975 P(|Y|≥Yo)=1-0.975=0.025 2P(Y≥Yo)=0.025 P(Y≥Yo)= 0.0125 P(Z≥2.2414)= 0.0125 Right border= P(Y≥1+ 2.2414*2)= 0.0125 P(Y≥5.48)= 0.0125 Yo= 5.48 Left border = P(Y≤ 1-2.2414*2)= 0.0125 P(Y≥-3.48)= 0.0125 Yo= -3.48 The numbers are not identical because now the mean is1 instead of 0. The distance between 5.48 and 1= -3.48 and 1= |4.48| If you move all -1 to the left by subtracting 1, then Left border: -3.48-1 = -4.48, mean =1-1= 0, right border: 5.48-1= 4.48 When mean = 0 the values of left and right borders are the same Checking P(|Y|≤ 5.48)= 1- P(|Y|≥ 5.48)= 1- 2P(Y≥ 5.48)= 1- 2P(Z≥ 2.24)=1-2*0.0125=0.975 2.2. Given that Y is normally distributed with mean =10 and variance 25 (= 5) and that a sample of 25 observations is drawn then SE of the mean = 5/SQRT(25)= 1 2.2.1. P( Y ≥ 13) = P(Z≥ (13-10)/1)= P(Z≥ 3)=0.0013 2.2.2. P( 7≤ Y ≤ 13)= P(-3≤ Z≤ 3)= P(|Z|≤ 3)=1- 2P(Z≥ 3) =1-2*0.0013=0.9974 2.2.3. = 24 and 2=12 N=? if P( Y ≥ 26)=0.1587 P( Y ≥ 26)=0.1587 then P(Z ≥ (26-24)/SQRT(12/N)=0.1587 then 2/SQRT(12/N)= 1 then 2= SQRT(12/N) then 4= 12/N then N=12/4= 3. Checking Mean STD DEV=SQRT(12/3)= 2 P( Y ≥ 26)= P(Z≥ (26-24)/2)= P(Z≥ 1)= 0.1587 2.3. Given a χ2 distribution with 12 degrees of freedom. Find 2.3.1. P (χ2≤ 21.0)= 1- P (χ2≥ 21.0)=1-0.05= 0.95 2.3.2. Find χo2 such that P(χ2≥ χo2)=0.10 χo2=18.5 2.4. Given a t distribution. Find 2.4.1. Y = 10 g s2= 4 (population variance unknown). What is the approximate probability that a bag of 16 oysters weights less than 8 g? P( Y ≤ 8)= P(t≤ (8-10)/SQRT(4/16))= P(t≤ (-2/0.5)= P(t≤ (-4)= P(t≥ 4)=0.00058 or 0.0006 3 1.4 2.4.2. Find to such that 80% of the values are within the -to to to interval for 22 d.f. P(|t|≤ to )=0.8 then P(|t|≥ to )=0.20 then to=1.321 Question 3 ANSWER [20 points] data PROBLEM3; input GPC1 $ PROTEIN; cards; No 11.6 No 9.3 No 11.7 No 12.7 No 13.4 No 9.2 No 7.9 No 14.1 No 12.0 No 10.6 No 12.0 No 10.1 No 12.1 Yes 18.1 Yes 15.2 Yes 17.2 Yes 11.9 Yes 14.7 Yes 12.0 Yes 12.9 Yes 12.7 Yes 10.9 Yes 14.5 Yes 12.8 Yes 12.9 Yes 14.9 ; PROC SORT; By GPC1; PROC UNIVARIATE normal plot; by GPC1; PROC TTEST; Class GPC1; Var PROTEIN; proc power; twosamplemeans meandiff = 2.6154 stddev = 1.9521 npergroup = 13 14 15 16 17 power = .; 4 1.5 proc power; twosamplemeans meandiff = 2.6154 stddev = 1.9521 alpha= 0.01 npergroup = . power = 0.85; run; quit; 3.1. Both variables are normal Tests for Normality No GPC Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.965582 Pr < W 0.8366 Tests for Normality Yes GPC Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.932847 Pr < W 0.3711 Q-Q plot The good fit of the Q-Q plots to the expected ~N line correlates well with the high W values and the non-significant differences in the Shaprio-Wilk test. We accept our assumption that the data are normally distributed. 3.2. GPC1 N Mean Std Dev Std Err Minimum Maximum No 13 11.2846 1.7790 0.4934 7.9000 14.1000 5 1.6 GPC1 N Yes 13 13.9000 2.1111 0.5855 -2.6154 1.9521 0.7657 Diff (1-2) Mean Std Dev Std Err Minimum Maximum Method Variances Pooled Equal Satterthwaite Unequal 10.9000 18.1000 DF t Value Pr > |t| 24 -3.42 0.0023 23.33 -3.42 0.0023 Equality of Variances Method Num DF Den DF F Value Pr > F 12 Folded F 12 1.41 0.5624 We reject the null hypothesis that the samples are the same. The samples are significantly different (P= 0.0023). The GPC gene increases protein content of the grain. 3.3. Power Analysis Using SAS Computed Power Index N Per Group Power 1 13 0.906 2 14 0.927 3 15 0.943 4 16 0.956 5 17 0.966 6 1.7 Hand calculation of power Using Section 2.3.2 n=13 2n-2=24 t /2 2*(n-1)= t /2 24 df = 2.064 /2=0.025 Mean No Gpc Gpc 11.2846 13.9000 S 1.78 2.11 Average s2 s2 3.165 4.457 3.811 |1 - 2 |= 2.6154 ((2*s2)/n)= ((2*3.811)/13) = 0.765707 P(t> 2.064-(2.6154/0.765707))= P(t > -1.3517=1-P(t >1.3517) 1-0.10= 0.90 Or using Section 2.4.4. 2 r = 2 (s(pooled) /(t/2, n1+n2-2 + t, n1+n2-2) 2 r = 2 (3.811/6.8402)(2.064+ t, n1+n2-2) 2 r= 1.1143(2.064+ t, n1+n2-2) SQRT(13/1.1143) - 2.064= t, n1+n2-2 t, n1+n2-2= 1.3517 Then < 0.10 and the power= 1-0.10>0.90 3.4. Power of 85% and alpha=0.01 Average 2= 3.811 2 r = 2 (s(pooled) / (t/2, n1+n2-2 + t, n1+n2-2) Approximate with Normal 2 2 r = 2 (3.811/ (2.6154) ) (2.575 + 1.035) =14.5 2 2 Using T with n=16 r = 2 (3.811/ (2.6154) ) (2.75 + 1.055) =16.13 Then at least 17 to have at least 0.85 power. Actual power with 17 based on SAS= 0.87 guesstimate n 16 17 df = 2(n - 1) 30 32 t0.005 2.75 2.7385 t0.15 1.055 1.0535 estimated n 16.1 16.0 It is not possible to have 16.014 replications to achieve a power of at least 0.85 therefore we must round up to 17 replications. The iterations suggest that 17 replications would achieve a power of at least 0.85. Using SAS Computed N Per Group Question 4 ANSWER Actual Power N Per Group 0.870 17 [10 points] 7 1.8 4.1. Since the experiment was aimed to detect an increase in weight, the test is one-tailed. =0.05 (Type I error). Using the Power formula | 2 | | 2 | 70 Power P( z z 1 ) P ( z z 1 ) P( z 1.645 ) Y 1Y 2 2 * 2500 2 2 4 n P( z 0.3349) 1 0.36885 0.63 Also could be done using equation from section 2.4.4 in lecture notes 4.2. Table Z/2= 0.005 =2.575 Z=0.2= 0.8416 2 (Z/2 + Z) = 11.673 2 2 r = 2 ( /) * (Z + Z) Distance ¼ ½ ¾ N 374 94 42 1 24 1¼ 15 1½ 11 Question 5 ANSWER Data Prob5; Input DIFF= Cards; 15.675 17.160 18.480 19.745 19.470 19.855 18.590 18.150 18.975 15.620 ; Proc TTEST; paired C*T; 1¾ 8 2 6 [15 points] C T @@; *paired samples; C-T; 14.135 15.510 15.015 17.050 16.720 19.525 17.160 16.610 17.820 16.390 * assumes paired samples; proc power; onesamplemeans mean = 1.579 ntotal = 10 stddev = 1.223 nullmean= 0 alpha= 0.05 power = .; run; quit; Two sample paired test Mean Diff 95% CL Mean Std Dev 95% CL Std Dev 8 1.9 1.5785 DF t Value 9 4.08 0.7036 2.4534 1.223 0.8412 2.2327 Pr > |t| 0.0028 One sample DIFF Fixed Scenario Elements Normal Distribution Exact Method 0 Null Mean Alpha 0.05 Mean 1.579 Standard Deviation 1.223 Total Sample Size 10 Number of Sides 2 Computed Power Power 0.951 5.1.: there are significant differences between treatment and control (P=0.028) 5.2.: the power of the test is 0.95 5.3. Graphical representation of DIFF 9 1.10 Question 6 ANSWER [15 points] Four locations. Average yield= 7,000 lb/ac, standard deviation= 450 lb/ac. How many locations do we need to estimate the true mean yield with a 95% confidence interval of less than 800 lb/acre? d= 400 lb/ac First estimate using r = z/ 2 /d r= 1.962 * 202500/160000= 4.86 2 2 2 Using r = t2 /2, r-1 s2 / d2, the sample size, is estimated iteratively, initial-n 5 10 7 8 t2.5 %, n-1 2.776 2.262 2.447 2.365 n (2.776)2 (450)2 / 4002 = 9.75 (2.262)2 (450)2 / 4002 = 6.48 (2.447)2 (450)2 / 4002 = 7.57 (2.365)2 (450)2 / 4002 = 7.07 Answer: He should examine at least 8 replications. Question 7 ANSWER [10 points] No standard deviation CV not greater than 10%. Estimate the number of replications required in order to have the total length of a 95% confidence interval about the true mean yield be less than the standard deviation? Using the equation: r= z2/ 2 CV 2 (d/)2 CV= (s/ Y ) < 0.1 and 2d<s (then s>2d) Y >s/0.10 d/μ=(s/2)/(s/0.1))= 0.1/2=0.05 Normal approximation: r = 1.962 * 0.102 /0.052 = 15.4 Or CV = s/ Y , so s = CV* Y = 0.10 * 7500= 750, and s < 750 2d <750, thus d < 375 and r = 1.962 * 7502 / 3752 = 15.4 Using r = t2 /2, r-1 s2 / d2, the sample size, is estimated iteratively, initial-n t 2.5%, df n 2 16 2.131 (2.131) (750)2 /3752 = 18.2 19 2.101 (2.101)2 (750)2 /3752 = 17.66 18 2.110 (2.110)2 (750)2 /3752 = 17.8 10 1.11 18 replications are necessary to have a 95% confidence interval for the mean= 1s 11