Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
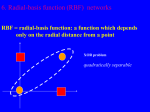
In Proceedings of the First International Workshop on Multiple Classifier Systems, June 2000, Sardingia A hybrid projection based and radial basis function architecture? Shimon Cohen Nathan Intrator Computer Science Department Tel-Aviv University www.math.tau.ac.il/∼nin Abstract. A hybrid architecture that includes Radial Basis Functions (RBF) and projection based hidden units is introduced together with a simple gradient based training algorithm. Classification and regression results are demonstrated on various data sets and compared with several variants of RBF networks. In particular, best classification results are achieved on the vowel classification data [1]. 1 Introduction The duality between projection-based approximation and radial kernel methods has been explored theoretically [2]. it was shown that a function can be decomposed into mutually exclusive parts, the radial part and the ridge (projection based) part and that the two parts are mutually exclusive. It is difficult however, to separate the radial portion of a function from its projection based portion before they are estimated, and sequential methods which attempt to first find the radial part and then proceed with a projection based approximation are likely to get stuck in non-optimal local minima. Earlier approaches to kernel based estimation were based on Volterra and Wiener kernels [17, 19] but they failed to produce a practical optimization algorithm that can compete with MLPs or RBFs. The relevant statistical framework is Generalized Additive Models (GAM) [6, 7]. In that framework, the hidden units (the components of the additive model) ? This work was partially supported by the Israeli Ministry of Science and by the Israel Academy of Sciences and Humanities — Center of Excellence Program. Part of this work was done while N. I. was affiliated with the Institute for Brain and Neural Systems at Brown University and supported in part by ONR grants N0001498-1-0663 and N00014-99-1-0009. have some parametric form, usually polynomial, which is estimated from the data. While this model has nice statistical properties [18], the additional degrees of freedom, require strong regularization to avoid overfitting. Higher order networks have at least a quadratic terms in addition to the linear term of the projections [9] as a special case of GAM. While they present a powerful extension of MLPs, and can form local or global features, they do so at the cost of squaring the number of input weights to the the hidden nodes. Flake has suggested an architecture similar to GAM where each hidden unit has a parametric activation function which can change from a projection based to a radial function in a continuous way [4]. This architecture uses a squared activation function, thus called Squared MLP (SMLP) and only doubles the number of free parameters. The use of B-Splines was also suggested in this context [8] with the argument that such network can combine properties of global and local receptive fields. These networks are more general than the proposed model. In high dimensional problems, a network that is too general has more free parameters and is more likely to over-fit the data. We shall compare the proposed model to the current state of the art in performance on the data set that we use to show that our proposed model does not suffer from such over-fitting problem. It achieved very good results on some data sets and was only outperformed by our proposed architecture (see below). This paper introduces a simple extension to both MLP and RBF networks by combining RBF and Perceptron units in the same hidden layer. Unlike the previously described methods, this does not increase the number of parameters in the model, at the cost of predetermining the number of RBF and Perceptron units in the network. The new hybrid architecture, which we call Perceptron Radial Basis Net (PRBFN), automatically finds the relevant functional parts from the data concurrently, thus avoiding possible local minima the result from sequential methods. It leads to superior results on data sets on which radial basis function have so far produced best results, in particular the vowel classification data [1] where current best results are obtained. 2 The hybrid RBF/FF architecture and training For simplicity, we shall consider a single hidden layer architecture, since the extension to a multi-layer net is simple. In the hybrid architecture, some hidden units are of radial functions and the others are of projection 2 type. All the hidden units are connected via a set of weights to the output layer which can be linear, for regression problems, or non-linear for classification problems. Figure 1 presents the proposed hybrid architecture. There is a set of weights connecting the hidden units to the output units and a set of weights for the hidden units, which is in case of the perceptron units the projecting vectors, and the RBF centers for the RBF units. Y1 Yc Out layer for c output classes. Hidden layer composed of M1 Ridge units and M2 RBF units. Bias Bias Ridge1 x1 ... RidgeM1 Rbf1 ... ... RbfM2 xd Fig. 1. PRBF hybrid neural network with M hidden units, M1 RBFs and M2 Perceptrons and M = M1 + M2. There are several steps in estimating parameters to the hybrid architecture; First, the number of cluster centers is determined from the data and the number of RBF hidden units is chosen accordingly. Each RBF units is assigned to one of the cluster centers. The clustering can be done by a k-means procedure [3]. A discussion about the benefits of more recent approaches to clustering is beyond the scope of this paper. Unlike Orr [11], we assume that the clusters are symmetric, although each cluster may have a different radius. This is done in order to reduce the number of free parameters, while it is likely that in data-sets where Orr’s method outperforms other RBF methods (see results on Friedman’s data below), this assumption is not valid. The weights for the hidden projection based units can be set randomly using a certain weight distribution. The second 3 layer of weights can then be found using a pseudo-inverse of the activity matrix or via a least mean square procedure. The last step in the parameter estimation is to refine the weights of the hybrid network via some form of gradient descent minimization on the full architecture. 2.1 Gradient based parameter optimization We start by deriving the gradient of the full architecture. The output of a radial basis unit is given by: φ(x, wi) = exp −(x−wi )2 2r2 i . The output of a projection based unit is given by: aj = g( X (wji · zi )), i Where z is the output of the previous layer or the input to the hidden layer and w is the weight vector associated with this unit. The transfer function g is monotone and smooth such as sigmoidal. It is linear in the case of regression. The total error is given by the sum of the errors for each pattern: E= N X E n. n=1 The error on K outputs for the n’th pattern is given by: En = K 1X (y n − tnk )2 , 2 k=1 k where tnk and ykn are the target value and output value for the n’th pattern of the k’th output respectively. The partial derivatives of the error function with respect to the output weights is given by: ∂E n = g 0 (ak )(ykn − tnk )zi . ∂wkj where zi is the output of the previous layer and g 0 (ak ) is the derivative of the transfer function at the linear value ak . 4 The error term δ for the radial hidden units is given by: δkn = (ykn − tnk )g 0 (ak ), and for the projection hidden units by: δjn = g 0 (aj ) K X δkn wkj . k=1 Using this notation, the partial derivatives of the error function with respect to first layer of weights (from the patterns to Ridge units) is given by: ∂E n = δjn xni . ∂wji The partial derivatives of the error function with respect to the centers of the RBFs is given by: X ∂E n (xn − mj ) = δkn wkj φ(xn , wj ). 2 ∂mj r j k=1 K The partial derivatives of the error function with respect to the radii is given by: K X ∂E n k xn − m j k 2 = δkn wkj φ(xn , wj ). 3 ∂rj r j k=1 A momentum term can be added to the gradient, however it was not found to be useful with the hybrid gradient. A Levenberg Marquardt updating rule was found to be very useful for updating the weights, the centers and the radii. It is given by wnew = wold − (Z T Z + λI)−1 Z T wold , where the matrix Z is given by: (Z)ni = 3 ∂y n . ∂wi Eliminating un-needed RBF units It is likely that after the clustering algorithm, some cluster centers do not represent real clusters which could be approximated by an RBF, thus such cluster centers should be eliminated with the hope that the projection based units will be more useful in approximating the function in those regions. We have used several criteria for eliminating such clusters. 5 Size of a cluster We discard clusters whose size in terms of number of patterns is too small, or the size in terms of scatter is too large. Given a certain threshold a, we consider only clusters which satisfy (N/k ≥ a) where N is the total number of patterns and k is the number of clusters. The scatter of cluster i is given by: Ji = N 1 Xi (k Xk − Mi k)2 Ni k=1 We discard clusters for which Ji ≥ a for a certain threshold a. This criterion however is not very effective for non-radial clusters. In that case the Mahalanobis distance should be used. Spectrum criteria Clusters with a large difference between highest to lowest eigen values indicate that some directions have little variation which can be attributed to noise only. Such clusters should be projected on the more meaningful directions. At this point, we discard such clusters, and leave the approximation in this region to the MLP. 4 Experimental results This section describes regression and classification results of several variants of RBF and the proposed PRBFN architecture on several data sets. The results which are only given for the test data are an average over 10 runs and include the standard deviation. We start with a comparison on four simulated regression data sets that were used by Orr to asses the performance of RBF. The results are summarized in Table 1. The first data set is a 1D sine wave [11]. y = sin(12x), with x ∈ [0, 1]. A Gaussian noise was added to the outputs with a standard deviation of σ = 0.1. 10 sets of 50 train and 50 test patterns randomly sampled from the data with the additive noise were used. The second data-set is a 2D sine wave, y = 0. sin(x1 /4) sin(x2 /2), 6 with 200 training patterns sampled at random from an input range x1 ∈ [0, 10] and x2 ∈ [−5, 5]. The clean data was corrupted by additive Gaussian noise with σ = 0.1. The test set contains 400 noiseless samples arranged as a 20 by 20 grid pattern, covering the same input ranges. Orr measured the error as the total squared error over the 400 samples. We report the error as simply the MSE on the test set. The third data set [10, 12] is based on a one dimensional Hermite polynomial 2 y = (1 + (x + 2x2 )e−x . 100 input values are sampled randomly between −4 < x < 4, and Gaussian noise of standard deviation σ = .1 was added to the output. The fourth data-set is a simulated alternating current circuit with four input dimensions (resistance R, frequency p ω, inductance L and capacitance C and one output impedance Z = R2 + (ωL − 1/ωC)2 . Each training set contained 200 points sampled at random from a certain region [13, for further details]. Again, additive noise was added to the outputs. The experimental design is the same as the one used by Friedman in the evaluation of MARS [5]. Friedman’s results include a division by the variance of the test set targets. We do not make this division and report the MSE on the test set. Orr’s regression trees method [13] outperforms the other methods on this data set. Rbf-Orr Rbf-Matlab Rbf-Bishop PRBFN MacKay 1.7e-3±0 2.1e-3±9.5e − 5 1.8e-2±9.7e − 6 1.5e-3±9.1e − 4 1D Sine 1.2e-3±0 8.0e-4±6.0e − 3 1.7e-2±1.5e − 5 1.1e-3±2.0e − 4 2D Sine 7.4e-3±6e − 3 8.3e-3±5e − 4 4.9e-3±1.4e − 3 6.8e-3±1.8e − 4 Friedman 7.0±0.1 10.9±0.4 11.7±0.7 10.6±0.6 Table 1. Comparison of Mean squared error results on two data sets (see [13] for details). Results on the test set are given for several variants of RBF networks which were used also by Orr to asses RBFs. MSE Results of an average over 10 runs including standard deviation are presented. 4.1 Classification We have used several data sets to compare the classification performance of the proposed methods to other RBF networks. The sonar data set attempts to distinguish between a mine and a rock. It was used by Gorman 7 and Sejnowski [14] in their study of the classification of sonar signals using neural networks. The data has 60 continuous inputs and one binary output for the two classes. It is divided into 104 training patterns and 104 test patterns. The task is to train a network to discriminate between sonar signals that are reflected from a metal cylinder and those that are reflected from a similar shaped rock. There are no results for Bishop’s algorithm as we were not able to get it to reduce the output error. Gorman and Sejnowski report on results with feed-forward architectures [16] using 12 hidden units. They achieved 84.7% correct classification on the test data. This result outperforms the results obtained by the different RBF methods, and is only surpassed by the proposed hybrid RBF/FF network. The Deterding vowel recognition data [1, 4] is a widely studied benchmark. This problem may be more indicative of the type of problems that a real neural network could be faced with. The data consists of auditory features of steady state vowels spoken by British English speakers. There are 528 training patterns and 462 test patterns. Each pattern consists of 10 features and it belongs to one of 11 classes that correspond to the spoken vowel. The speakers are of both genders. The best score so far was reported by Flake using his SMLP units. His average best score was 60.6% [4] and was achieved with 44 hidden units. Our algorithm achieved 65.7% correct classification with only 19 hidden units. As far as we know, it is the best result that was achieved on this data set. The seismic1 and seismic2 data sets are two different representations of seismic data. The data sets include waveforms from two types of explosions and the task is to distinguish between the two types. This data was used a “Learning” course in the last two years for performance evaluation of many different classifiers1. one of these two classes. The dimensionality of seismic1 is 352 representing 32 time frames of 11 frequency bands, and the dimensionality of seismic2 patterns is 242 representing 22 time frames of 11 frequency bands. Principal Component Analysis (PCA) was used to reduce the data representation into 12 dimensions. Both data-sets have 65 training patterns and 19 test patterns which were chosen to be the most difficult for the desired discrimination. Table 2 summarizes the percent correct classification results on the different data sets for the different RBF classifiers and the proposed hybrid architecture. As in the regression case, the STD is also given however, on the seismic data, due to the use of a single test set (as we wanted to see the performance on this particular data set only) the STD is often 1 For details see http://www.math.tau.ac.il∼nin/learn98,9 8 zero as only a single classification of the data was obtained in all 10 runs. Algorithm RBF-Orr RBF-Matlab RBF-Bishop PRBFN Sonar 71.7±0.5 82.3±2.4 – 87.1±3.3 Vowel – 51.6±2.9 48.4±2.4 65.7±1.9 Seismic1 Seismic2 63±0 79±0 73±4 81±3 60±4 77±5 89±0 85±3 Table 2. Percent classification results of different RBF variants on four data sets. 5 Discussion The general ideas of a hybrid architecture is not new and is covered in the theory of generalized additive models [7]. The novelty of the proposed architecture and training algorithm is the simplicity of training, and the fact that the number of model parameters is not increased. The draw back compared with more flexible methods is that the number of RBFs and ridge functions have to be pre-determined. In the extensively studied vowel data set, our proposed hybrid architecture achieved average results which are superior to the best known results [15]. Moreover, this result was achieved with a smaller number of hidden units suggesting that the internal representation found by the hybrid architecture is richer and generalizes better. The proposed method also outperformed a feed-forward architecture and RBF architectures on the sonar data [14]. This architecture is thus a viable alternative to the use of either projection based or radial basis functions. It shares the good convergence properties of both, and with a good parameter estimation procedure it is expected to outperform either on difficult tasks. References 1. D. H. Deterding. Speaker Normalisation for Automatic Speech Recognition. PhD thesis, University of Cambridge, 1989. 2. D. L. Donoho and I. M. Johnstone. Projection-based approximation and a duality with kernel methods. Annals of Statistics, 17:58–106, 1989. 3. R. O. Duda and P. E. Hart. Pattern Classification and Scene Analysis. John Wiley, New York, 1973. 4. G. W. Flake. Square unit augmented, radially extended, multilayer percpetrons. In G. B. Orr and K. Müller, editors, Neural Networks: Tricks of the Trade, pages 145–163. Springer, 1998. 9 5. J. H. Friedman. Mutltivariate adaptive regression splines. The Annals of Statistics, 19:1–141, 1991. 6. T. Hastie and R. Tibshirani. Generalized additive models. Statistical Science, 1:297–318, 1986. 7. T. Hastie and R. Tibshirani. Generalized Additive Models. Chapman and Hall, London, 1990. 8. S. Lane, D. Handelman, J. Gelfand, and M. Flax. Function approximation using multi-layered neural networks and b-spline receptive fields. In R. P. Lippmann, J. E. Moody, and D. S. Touretzky, editors, Advances in Neural Information Processing Systems, volume 3, pages 684–693, San Mateo, CA, 1991. Morgan Kaufmann. 9. Y. C. Lee, G. Doolen, H. H. Chen, G. Z.Sun, T. Maxwell, H.Y. Lee, and C. L. Giles. Machine learning using higher order correlation networks. Physica D,, 22:276–306, 1986. 10. D. J. C. MacKay. Bayesian interpolation. Neural Computation, 4(3):415–447, 1992. 11. M. J. Orr. Introduction to Radial Basis Function networks. Technical report, 1996. http://www.anc.ed.ac.uk/∼mjo/rbf.html. 12. M. J. Orr. Recent advances in Radial Basis Function networks. Technical report www.anc.ed.ac.uk/∼mjo/papers/recad.ps.gz, 1999. 13. M. J. Orr, J. Hallman, K. Takezawa, A. Murray, S. Ninomiya, M. Oide, and T. Leonard. Combining regression trees and radial basis functions. Division of informatics, Edinburgh University, 1999. Submitted to IJNS. 14. Gorman R. P. and Sejnowski T. J. Analysis of hidden units in a layered network trained to classify sonar targets. Neural Network, pages 75–89, 1988. Vol. 1. 15. A. J. Robinson. Dynamic Error Propogation Networks. PhD thesis, University of Cambridge, 1989. 16. D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning internal representations by error propagation. In D. E. Rumelhart and J. L. McClelland, editors, Parallel Distributed Processing, volume 1, pages 318–362. MIT Press, Cambridge, MA, 1986. 17. M. Schetzen. The Volterra and Wiener Theories Of Nonlinear Systems. John Wiley and Sons, New York, 1980. 18. C. J. Stone. The dimensionality reduction principle for generalized additive models. The Annals of Statistics, 14:590–606, 1986. 19. V. Volterra. Theory of Functional and of Integro-differential Equations. Dover, 1959. 10