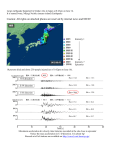
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
QUANTITATIVE LANDSLIDE HAZARD ASSESSMENT IN REGIONAL SCALE USING STATISTICAL MODELING TECHNIQUES A Dissertation Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy Manouchehr Motamedi August, 2013 QUANTITATIVE LANDSLIDE HAZARD ASSESSMENT IN REGIONAL SCALE USING STATISTICAL MODELING TECHNIQUES Manouchehr Motamedi Dissertation Approved: Accepted: ______________________________ Advisor ______________________________ Department Chair ______________________________ Co-Advisor or Committee Member Dr.Ala Abbas ______________________________ Dean of the College Dr. George K. Haritos ______________________________ Committee Member Dr. Lang Zhang ______________________________ Dean of the Graduate School Dr. George R. Newkome ______________________________ Committee Member Dr. Hamid Bahrami ______________________________ Date Dr.Robert Y. Liang Dr. Wieslaw K Binienda ______________________________ Committee Member Dr. Ali Hajjafar ii ABSTRACT In this research study, a new probabilistic methodology for landslide hazard assessment in regional scale using Copula modeling technique is presented. In spite of the existing approaches, this methodology takes the possibility of dependence between landslide hazard components into account; and aims at creating a regional slope failure hazard map more precisely. Copula modeling technique as a widely accepted statistical approach is integrated with the hazard assessment concept to establish the dependence model between ― landslide magnitude‖, ― landslide frequency‖ and ― landslide location‖ elements. This model makes us able to evaluate the conditional probability of occurrence of a landslide with a magnitude larger than an arbitrarily amount within a specific time period and at a given location. Part of the Seattle, WA area was selected to evaluate the competence of the presented method. Based on the results, the mean success rate of the presented model in predicting landslide occurrence is 90% on average; while the success rate is only 63% when these hazard elements were treated as mutually independent. Also, Seismic-induced landslides are one of threatening effects of earthquakes around the world that damage structures, utilities, and cause human loss. Therefore, predicting the areas where significant earthquake triggered hazard exists is a fundamental question that needs to be addressed by seismic hazard assessment techniques. The current methods used to assess seismic landslide hazard mostly ignore the uncertainty in the prediction of sliding displacement, or lack the use of comprehensive field observations of landslide and iii earthquake records. Therefore, a new probabilistic method is proposed in which the Newmark displacement index, the earthquake intensity, and the associated spatial factors are integrated into a multivariate Copula-based probabilistic function. This model is capable of predicting the sliding displacement index ( ) that exceeds a threshold value for a specific hazard level in a regional scale. A quadrangle in Northridge area in Northern California having a large landslide database was selected as the study area. The final map indicates the sliding displacements in mapping units for the hazard level of 10% probability of exceedance in 50 years. Furthermore, to reduce human losses and damages to properties due to debris flows runout in many mountainous areas, a reliable prediction method is necessary. Since the existing runout estimation approaches require initial parameters such as volume, depth of moving mass and velocity that are involved with uncertainty and are often difficult to estimate, development of a probabilistic methodology for preliminary runout estimate is precious. Thus, we developed an empirical-statistical model that provides the runout distance prediction based on the average slope angle of the flow path. This model was developed within the corridor of the coastal bluffs along Puget Sound in Washington State. The robustness of this model was tested by applying it to 76 debris-flow events not used in its development. The obtained prediction rates of 92.2% for pre-occurred and 11.7% for nonoccurred debris flow locations showed that the model results are consistent with the real debris-flow inventory database. iv DEDICATION To “Mahdi” & “Simin”, my parents, my honest friends and my life‘s giving trees, for their endless, pure and unconditional love and support To “Kamelia”, a loyal friend and a lovely and beautiful partner And to “……” for giving me the joys and sorrows of ― being‖, this everlasting journey v ACKNOWLEDGEMENTS First of all, I would love to express my appreciation to my advisor, Professor Robert Liang, for his guidance, vision, patience, and generous support. I have learned a lot from this great man especially a ― right perspective‖ that I will use for the rest of my life. Thanks to all committee members including Professor Ala Abbas, Professor Lan Zhang, Professor Ali Hajjafar and Professor Hamid Bahrami for valuable discussions, comments and reviews of this dissertation. I would love to express my deepest appreciation to my always dear siblings, Hessam and Negin; my loved ones, Abbas and Zarrin; a lovely and insightful lady, Mariel Barron; a generous friend, Leila Bolouri; a kind couple, Reza and Farnaz Noohi; a good humanbeing and friend, Alireza Shabani; kind buddies, Kiarash Kiantaj and Shahriar being‖ in my life, continuous support, patience, love, joy and Mirshahidi, for their ― encouragement throughout the hard and frustrating days, months and years of my PhD. Finally, I would like to acknowledge Ms. Kimberly Stone for her invaluable piece of advice, Ms. Christina Christian for her great help and all staffs and colleagues for cooperative and kindly environment. I would also like to acknowledge Majid Hosseini and Ali Tabatabai for their help and support; and thanks to Ms. Lynn Highland, for cooperative and valuable information in USGS. vi TABLE OF CONTENTS Page LIST OF TABLES……………………………………………………………………….Xi LIST OF FIGURES…………………………………………………………………….Xiii CHAPTER I. INTRODUCTION .....................................................................................................1 1.1 Problem Statement ...........................................................................................1 1.2 Objectives of the Study ....................................................................................8 1.3 Outline of the Dissertation ...............................................................................9 II. LITERATURE REVIEWS AND BACKGROUNDS ............................................11 2.1 Overview .......................................................................................................11 2.2 Landslides and their Causal Factors .............................................................11 2.3 Landslide Mitigation and Prevention ............................................................13 2.3.1 Landslide Risk Management and Assessment ...........................................14 2.3.2 Hazard Evaluation ..................................................................................16 2.3.3 Landslide Susceptibility Approaches .....................................................17 2.3.4 Probability of Landslide Magnitude ......................................................23 vii 2.3.5 Probability of Landslides Frequency .....................................................25 2.3.6 Vulnerability ..........................................................................................28 2.3.7 Landslide Risk Management Strategies .................................................30 III. QUANTITATIVE LANDSLIDE HAZARD ASSESSMENT USING COPULA MODELING TECHNIQUES ............................................................................................33 3.1 Overview .......................................................................................................35 3.2 The Proposed Methodology ...........................................................................38 3.3 Study Area and Data ......................................................................................44 3.4 Method of Analysis ........................................................................................46 3.4.1 Data Preparation....................................................................................48 3.4.2 Dependence Assessment ........................................................................53 3.4.3 Marginal Distribution of Variables ........................................................57 3.4.4 Model Selection and Parameter Estimation ..........................................62 3.4.5 Goodness-of-fit Testing……………………………………………... ..65 3.4.6 Copula-based Conditional Probability Density Function ......................67 3.4.7 Probability of Landslide Frequency .......................................................67 3.5 Validation and Comparison of the Results ......................................................72 3.6 Landslide Hazard Map .....................................................................................73 3.7 Discussion ........................................................................................................73 3.8 Summary and Conclusion ................................................................................77 viii IV .SEISMICALLY-TRIGGERED LANDSLIDE HAZARD ASSESSMENT: A PROBABILISTIC PREDICTIVE MODEL MODELING TECHNIQUES .....................79 4.1 Overview .........................................................................................................79 4.2 Literature review ............................................................................................80 4.3 Methodology ..................................................................................................86 4.4 Application of the Proposed Model ...............................................................91 4.4.1 Study area and Database ........................................................................91 4.4.2 Development of Seismic Hazard Model ...............................................95 4.5 Seismic Landslide Hazard Map .....................................................................105 4.6 Validation ........................................................................................................105 4.7 Summary and Conclusion ...............................................................................106 V. AN EMPIRICAL-STATISTICAL MODEL FOR DEBRIS-FLOW RUNOUT PREDICTION IN REGIONAL SCALE .........................................................................109 5.1 Overview ........................................................................................................109 5.2 Literature review ............................................................................................110 5.3 Methodology ..................................................................................................113 5.4 Application of the Proposed Model ...............................................................116 5.4.1 Study area and Database ..........................................................................116 ix 5.4.2 Development of the Empirical-Statistical Model ...................................120 5.5 Debris-flow Runout Prediction Results ..........................................................127 5.6 Validation ........................................................................................................128 5.7 Summary and Conclusion ................................................................................128 VI. CONCLUSIONS AND RECOMMENDATIONS ....................................................131 6.1 Summary of Important Research Results ........................................................131 6.2 Recommendations for Future Research ............................................................133 REFFERENCES .............................................................................................................135 x LIST OF TABLES Table 2.1 Page Pros and Cons of priority ranking systems for state transportation agencies (Huang et al., 2009) ........................................................................................................................17 3.1 Rank correlation coefficients of the pairs (M, S), (M, T) and (S, T) ........................65 3.2 Maximum likelihood estimation (MLE) of the examined distribution parameters ..69 3.3 AIC values of the examined probability distributions ..............................................71 3.4 Kolmogorov–Smirnov (KS) test for the data after Box–Cox transformation ..........71 3.5 Parameter estimation and confidence interval of the Copulas ..................................73 3.6 Landslide hazard probability values obtained from Copula-based and multiplication-based models for 79 failure events .............................................................86 4.1 Rank correlation coefficients of the pairs (ac, DN) and (Ia, DN ) ..........................114 4.2 Calculated Z-values for spatial autocorrelation significance test ...........................116 4.3 Performance of marginal distributions for random variables and selected probability density functions............................................................................................119 4.4 Kolmogorov–Smirnov (KS) test for the data after Box–Cox transformation.......119 xi 4.5 Parameter estimation and Kendall‘s τ of the Copulas ..........................................122 4.6 The AIC values of different Copulas functions ....................................................122 5.1 Summary of the three debris flow data subsets ....................................................144 5.2 Rank correlation coefficients of the pairs of the three debris flow data subsets...146 5.3 Summary of the significance tests of the best fit regression equation ..................149 xii LIST OF FIGURES Figure Page 2.1 Integrated risk management process (Lacasse et al., 2010) .....................................14 2.2 Example of multi-layered neural network in landslide susceptibility analysis........23 2.3 Classification of landslide susceptibility analysis approaches (Yiping 2007) .........24 2.4 Example of risk criterion recommendation (F-N curve)..........................................35 3.1 Current general approaches in quantitative landslide hazard assessment ................42 3.2 The proposed methodology for quantitative landslide hazard assessment using Copula modeling technique ...............................................................................................48 3.3 The location of the study area and landslide events in part of Western Seattle, WA area ....................................................................................................................................50 3.4 Temporal distribution of landslides from the landslide database versus the year of occurrence ..........................................................................................................................55 3.5 Definition of slope failure height (h), slope angle (β) and length (L) in a shallow landslide .............................................................................................................................57 3.6 a) Slope map; b) Geologic map; c) Landslide location index (S) map in the study area .....................................................................................................................................62 3.7 Scatter plot of landslide hazard component indices: a) Location index versus magnitude index, b) Frequency index versus magnitude index, c) Frequency index versus location index ....................................................................................................................66 xiii 3.8 Marginal distribution fitting to: a) transformed location index, b) magnitude index 3.9 Simulated random sample of size 10,000 from 14 chosen families of Copulas; a) Ali-Mikhail-Haq, b) Frank, c) Galambos, d) Gumbel-Hougard, e) BB2, f) BB3 : upon transformation of the marginal distributions as per the selected models (whose pairs of ranks are indicated by ― white‖ points) along with the actual observations .......................70 3.10 Goodness-of-fit testing by comparison of nonparametric and parametric K(z) for Copula models. ..................................................................................................................73 3.11 Cumulative Gumbel-Hougard joint probability density function of S and M indices; dark points represents the 79 validation points in ―1 -CDF‖ form .....................................74 3.12 Points indicating the landslide locations in part of the study area and a counting circle used for exceedance probability calculation in the mapping cell ― A‖ .....................77 3.13 Example of landslide hazard map (10m×10m cell size) for 50 years for landslide magnitudes, study area M ≥ 10,000 m^2 in the study area. The value in each map cell gives the conditional probability of occurrence of one or more landslide within the specific time in that location ..............................................................................................81 4.1 Infinite slope representation showing the sliding block and the parameters used to define the critical acceleration ...........................................................................................85 4.2 Flow chart showing the common required steps for developing earthquake-induced landslide hazard Map .........................................................................................................96 4.3 Flow chart showing the presented methodology in this study for developing earthquake-induced landslide hazard map .......................................................................101 4.4 Location of the study area, limit of greatest landslide concentration and Northridge earthquake epicenter ........................................................................................................105 xiv 4.5 a) Geologic map of the selected study area; (b) cohesion and (c) friction angle as the components of shear shear strength assigned to the geologic units (Yerkes and Campbell 1993, 1995); (d) Shaded-relief digital elevation model (DEM) of the selected area .......108 4.6 The contour map of the Arias intensity (I_a) generated by the 1994 Northridge earthquake in the selected quadrangle. Each displayed Intensity value is the average of the two horizontal components ........................................................................................110 4.7 Goodness-of-fit testing by comparison of nonparametric and parametric K(z) for Copula models .................................................................................................................112 4.8 Seismic landslide hazard maps (10m×10m cell size) indicating the displacements levels in mapping units for a) λ=0.0021 1/yr and b) λ=0.0021 1/yr in the study area ....123 4.9 Validation of the predicting model using the Q-Q plots of landslide areal percentages versus Newmark displacements .......................................................................................125 5.1 Flowchart showing different current runout models. .................................................127 5.2 Schematic cross section defining debris flow runout distance (L), and slope gradient (α) used in debris flow runout prediction.........................................................................135 5.3 Flow chart showing the presented methodology in this study for debris flow hazard assessment. .......................................................................................................................136 5.4 a) Example of debris flow near Woodway, Washington on January 17, 1997 (Harp et al. 2006), b) Selected study area in this paper. ................................................................139 5.5 Cumulative frequency plot of runout distances for the 326 debris-flow runout lengths mapped from north Seattle to Everett (Harp et al. 2006). ................................................141 5.6 Slope gradient map of the study area. ........................................................................143 5.7 a) Regressions of L versus α for the three field data subsets, b) the final developed regression model. .............................................................................................................144 xv 5.8 Calibration of the predictive model using the debris flow inventory data .................151 5.9 Example of debris flow hazard (exceedance probability) map for critical runout distance of (Lc= 80m) ......................................................................................................152 xvi CHAPTER I INTRODUCTION 1.1 Problem statement Landslides, which are mass of rock, debris or earth moving down a slope, are one of the most frequently occurring natural disasters in the world as they expose a lot of human and economic losses annually in different geographic areas. Study of landslides, understanding of their different types, the involving aspects and causal factors are necessary, specifically in more susceptible locations. In recent decades, landslide risk assessment and management have led to development of the land utilization regulations and minimized the loss of lives and damage to property. Landslide risk assessment and management includes the analysis of the level of potential risk, deciding whether or not it is acceptable, and applying the appropriate treatments to reduce it when the risk level cannot be accepted (Ho et al., 2000). Landslide hazard analysis is one of the fundamental components of the landslide risk management; and during the recent few decades many attempts have been made to develop that using a variety of techniques. Among the existing techniques, quantitative methods attempted to assess the landslide hazard more precisely. Quantitative methods mainly include different approaches for predicting ― where‖, ― when‖ and/or ― how frequently‖ the landslide might happen in the future. Although some advanced studies have been conducted to integrate the three components of location, time and frequency of landslide for hazard modeling (Guzzetti et al. 2005, Jaiswal et al. 2010), their models undertake simplifying and unrealistic assumptions. These assumptions which dictate the independence between landslide hazard components are mainly due to lacking of a more comprehensive methodology at hand. Therefore to overcome the existing shortcomings, more study and research is required in this regard. Landslides are among the most threatening effects of earthquakes all around the world. In fact, damage from triggered landslides is sometimes more than direct loss related to earthquakes; largest earthquakes have the capability to cause thousands of landslides throughout areas of more than 100,000 (Keefer, 1984). For example, on May 12, 2008, a magnitude (Mw) of 7.9 Sichuan earthquake in China had triggered more than 11,000 landslides and these events have threatened 805,000 persons and damaged their properties (Gorum, 2008).Hence predicting the magnitude and location of the strong shakings which trigger landslides are the fundamental questions need to be addressed in any regional seismic hazard assessment. Among different methods for assessment of earthquake-triggered landslides, probabilistic seismic landslide displacement analysis (PSLDA) offers the opportunity to an engineer to quantify the uncertainty in the assessment of the performance of susceptible slopes during the seismic loading, and it has been applied in different studies in recent years (e.g., Ghahraman and Yegian 1996; Stewart et al. 2003; Bray and Travasarou, 2007; Rathje and Saygili 2009). However due to the complexity of these methods, little progress in PSLDA has been made so far. The 2 recent availability of new earthquake records offer the opportunity to develop more realistic probabilistic techniques require advancing the assessment of landslide hazard during earthquake. Debris flow, which is sometimes referred as mudslide, mudflow or debris avalanche is defined in the literature as a mixture of unsorted substances with low plasticity including everything from clay to cobbles (Varnes 1978; Lin et al. 2006). Debris flows which are a common type of fast-moving landslides are produced by mass wasting processes. They are one of the most frequently occurring natural phenomena that cause a lot of human loss and damage to properties annually all around the world (Hungr et al. 1999; Prochaska et al., 2008). For instance, in 1996 and 2003 destructive debris flows took place in the Faucon catchment, causing significant damage to roads, bridges and property (Hussin 2011). Debris flows also play an important role in channel aggradations, flooding and reservoir siltation and also basin sediment yielding (Bathurst et al., 2003; Burton et al., 1998). Therefore, evaluation of the potential debris flows is a very vital task in landslide risk management and generally it helps to delimit the extension of the hazard and scope of endangered zones. The existing debris-flow runout approaches require estimation of the influencing factors that control the flow travel such as runout distance, depth of deposits, damage corridor width, depth of the moving mass, velocity, peak discharge and volume (Dai et al. 2001). However, accurate estimation of all of these initial parameters which are involved 3 with a lot of uncertainty is very difficult in practice (Prochaska et al. 2008). The main need is to develope a reliable probabilistic methodology which could be simply based on a single influencing factor. Therefore, such a methodology will be capable of considering the uncertainty of the debris-flow parameter(s) without complexity of the most existing models. This model can be used for preliminary estimation of triggered debris-flow runout distance based on the slope gradient of the travel path in regional scale. It is believed that such an approach is valuable, time saving and can be applied to any similar debris-flow hazard evaluation in the future. 1.2 Objectives of the study Developing a general methodology for quantitative modeling of landslide hazard in a regional scale inventory: In spite of the existing approaches, this methodology takes the possibility of dependence between landslide hazard components into account; and aims at creating a regional slope failure hazard map more precisely. Copula modeling technique as a widely accepted statistical approach is integrated with the hazard assessment concept to establish the dependence model between ― landslide magnitude‖, ― landslide frequency‖ and ― landslide location‖ elements. This model makes us able to evaluate the conditional probability of occurrence of a landslide with a magnitude larger than an arbitrarily amount within a specific time period and at a given location. 4 Developing an improved model for earthquake-induced landslide hazard assessment methods: The proposed model is based on casual relationships between landslide displacement index (D), preparatory variables and seismic parameters using probabilistic perspective for application in the constructionplanning in landslide susceptible areas. The sub-objectives of this method are as follows: (a) to find out a more realistic indication of well-known Newmark displacement index (D) for each mapping unit; (b) to explore a more precise oneby-one relationship between Newmark displacement values and each of the affecting parameters in regional scale; and (c) to compare the results of empiricalbased technique and the proposed probabilistic method given the same involving parameters. Developing a reliable probabilistic method for debris-flow runout distance to be simply based on a single influencing factor: Such a methodology will be capable of taking the uncertainty of the debris-flow parameter(s) into account without complexity of the most existing models. Thus, the proposed model is used for preliminary prediction of debris-flow runout distance based on the slope gradient of the travel path in regional scale. This model is built upon a reliable regression analysis and exceedance probability function. This methodology can be usefully implemented for similar debris flow assessment and mapping purposes in regional scale studies. The final resulting hazard maps can be updated with any additional related information in the future. 5 1.3 Outline of the dissertation Chapter I provides the problem statement to be addressed in this research, together with the specific objectives to be accomplished and also the required approach of each part of the study. The organization of the dissertation is outlined in this chapter as well. Chapter II provides a literature review and background of related research. The basic understanding of different types of landslides and their casual factors together with landslide mitigation requirement is presented. Also landslide risk management and the most essential components of that including hazard analysis, susceptibility estimation, frequency-magnitude relations, recurrence probability and decision making strategies are reviewed in this chapter as well. Chapter III presents a general approach for quantitative modeling of landslide hazard in a regional scale. Western part of the Seattle, WA area is selected to evaluate the competence of the method. 357 slope failure events occurred from 1997 to 1999 and their corresponding slope gradient map and geology data are considered in the study area to establish and test the model. A comparison is also performed between the Copula-based hazard model and the traditional 6 multiplication-based one. Finally the result of the presented model is illustrated as a landslide hazard map in the selected study area. Chapter IV proposes a new probabilistic method in which the Newmark displacement index and corresponding earthquake intensity as well as spatial variables are integrated into one multivariate conditional function. The 1994 Northridge, earthquake California is used as appropriate database in this study which includes all of the data sets needed to perform a detailed regional assessment of seismic-triggered landslide. To validate the probability model, the probabilistic results is compared with the field performance; in that areal extension of the landslides already occurred in the study area is used as field performance in this study. A regional seismic-induced landslide hazard map is created using the presented probabilistic model as well. Chapter V provides an empirical-statistical model that predicts the runout distance based on the average slope angle of the flow path. This model is developed within the corridor of the coastal bluffs along Puget Sound (from north Seattle to Everett), in Washington state. 250 historic and recent debris-flow events are used to build the model. Correlation between the debris flow distance and slope gradient ( ) for debris flow events is examined using graphical and quantitative measures. The final regression model is applied in the normal exceedance probability function and it is calibrated based on Gauss error function. The 7 robustness of this model is tested by applying it to 76 debris-flow events not used in its development. Using the obtained predicting model, the debris flow hazard map of the study area is also created. Chapter VI provides a summary of work accomplished in this research and presents recommendations for future research. 8 CHAPTER II LITERATURE REVIEW AND BACKGROUND 2.1 Overview This chapter provides a review of early works and commonly accepted definitions relevant to the landslide hazard assessment and risk management. The classification of landslides and the principles of slope stability are discussed. Different methods of landslide mapping and monitoring, landslide susceptibility evaluation techniques, their hazard assessment and vulnerability concepts and common decision making approaches are reviewed as well. 2.2 Landslides and their causal factors Landslide is one of the most frequently occurring natural disasters in the world. They bring about a lot of human loss and damages to properties annually in different geographic areas. We define ― landslide‖ (or slope failure) as a mass of rock, debris or earth when it moves down a slope (Cruden, 1991). The main driving force in landslide is gravity and the amount of this force will be proportional to the angle of slope (Case, 1996). Increasing the slope angel will reduce the stability of the mass. Also in case of impact of a triggering factor such as rain or 9 earthquake, the resisting forces which prevent the mass from sliding down the slope can be significantly reduced. Understanding of the existing triggering factors of landslides helps figuring out the most suitable remediation strategies. Popescu (1994) and Dai et al. (2002) have compiled a framework for understanding the various causal variables of landslide which divides the causing factors into two categories as: preparatory variables and triggering variables. Preparatory variables place the slope in a marginally stable state without initiating the failure. These variables mainly include slope gradient and aspect, geology, slope geotechnical properties, elevation, vegetation cover and weathering. On the other hand, the landslide triggering factors are understood as rains, floods, earthquakes, and other natural phenomena as well as human activities such as terrain cutting, filling, grading and over-construction. These events change the slope state from a stable to an unstable condition in a short duration (Costa and Baker, 1981). Landslides can be classified based on the type of material of the slope and the type of slope movement (Varnes, 1978). The landslide movements are categorized into five classes of sliding, falling, toppling, spreading and flow as follows (Cruden and Varnes 1996). Sliding is understood as a downward movement of a soil or rock mass due to intense shear strain along rupture surfaces. Rock falls is defined as detachment of rock from a steep slope along a surface and then descending of particles mainly through the air by falling, bouncing, or rolling (Cruden, 1991). Rock toppling is the rotation of rock units about their base (below the gravitational center). Toppling happens due to gravity applied by upper units and sometimes due to water (or ice) in joints of the displaced rock units 10 (Pensomboon, 2007). The term spreading is described as sudden movements on waterbearing seams of sand or silt overlain by homogeneous clays or loaded by fills (Terzaghi and Peck, 1948). The dominant mode of such a movement is lateral extension accompanied by shear or tensile fractures (USGS fact sheet, 2004). Fast debris flow (also called mudslides, mudflows, or debris avalanches) is defined as a rapid mass movement in which a combination of loose soil, rock, air and water mobilize as slurry and flows downward. Debris flows occur during intense rainfall on saturated soil. They start on steep and once started, however, debris flows can even travel over gently slopes. Canyon bottoms, stream channels, areas near the outlets of canyons and slopes excavated for buildings and road-cuts could be the most susceptible areas (Hungr et al., 2001). 2.3 Landslide mitigation and prevention Landslides are of primary importance because they have caused huge human and economic losses all around the world. Numerous attempts have been made to mitigate the losses due to slope failures mainly due to increased urbanization and development in landslide-susceptible areas as a result of rapid population growth, increased precipitation due to changing climatic patterns and continued deforestation of different geographic regions (Dai, et al. 2002). 11 Landslide effects are lessen mainly through preventive means, such as restricting people from areas with landslides history and by installing early warning systems based on the measurement of ground conditions such as slope movement, groundwater level changes and strain in rocks and soils (Fell, 1994). There are also various direct methods of mitigating landslides, including geometric methods that modify the slope geometry; using chemical agents to strengthen the slope material, applying structures such as piles and retaining walls, grouting rock joints and fissures, hydro-geological methods to lower the groundwater level and rerouting surface and underwater drainage (Encyclopedia Britannica Inc., 2011). 2.3.1 Landslide risk management and assessment Although risk is an unavoidable component in all engineering processes and its prediction with certainty is not an easy task, it cannot be totally neglected. Risk management is a set of strategies required for solving or at least reducing the problem of landslides such as human losses and economical damages. Three main structures of landslide risk management have been suggested in the literature as: (a) risk analysis, (b) risk assessment, and (c) risk management (Fell and Hartfort, 1997). The risk analysis is aimed at providing a judgment basis to understand how safe a susceptible area is; and it can be practiced in different ways of qualitative to quantitative approaches (Aleotti and Chowdhury, 1999). The main aim of risk assessment is to decide whether to accept or to deal with the risk, or to set the priorities in that regard. This decision on acceptable risk 12 involves the responsibility of the owner, client or law-maker, based on risk comparison, treatment options, benefits, potential human and economic losses, etc. Finally the risk management is defined as a process at which the decision-maker decides whether to accept the risk or treat the existing risk (Dai et al., 2002) (see Figure 2.1). In terms of conditional probability, landslide risk when defined as the annual probability of economic loss (annual loss of property) value of a specific element may be calculated as follows (Morgan et al., 1992): (2.1) Where R: Risk ($/year); H: Hazard (0–1/year); V: Vulnerability (0–1); and C: Element value ($). In other words, risk analysis reveals that how much loss ($) we will have per year in any specific location of the study area. 13 Risk management Risk assessment Vulneribilty and elements of risk Hazard analysis Historical data Figure 2.1 Integrated risk management process (Lacasse et al., 2010) There are different levels in landslide risk assessment, including site-specific, global and distributed landslide risk. Site-specific landslide assessment map is made for evaluation of the economic loss at a specific site or landslide. On the other hand, a global risk assessment map is calculated by summing up site-specific risk of all landslides in the study area. Finally distributed landslide risk assessment provides a risk map that shows the economic loss or damage at different spots of a given area (Dai et al., 2002). The spatial subdivision in this type of landslide risk mapping is obtained using GIS and multiplication of spatial landslide probability, affected zones, land-use or spatial distribution of population or property and vulnerability (Leone et al., 1996). 14 One empirical method to do risk assessment is a priority ranking system for choosing the more critical landslide sites for more investigation which can systematically ranks landslide spots in an order of priority based on their probability and the consequence of failure occurrence. Such a priority system is based on an inventory database of all potentially unstable slopes in the study area. These ranking systems have mostly been developed for or by state transportation agencies in the U.S. and the concept of these systems are primarily based on the method of Pierson et al. (1990). Summing or multiplication of all individual category scores are two approaches that leads to the final rating score in such priority systems. Each of these developed ranking systems has its own advantages and disadvantages as summarized in Table 2.1. 2.3.2 Hazard evaluation Varnes and the IAEG Commission on Landslides and other Mass-Movements (1984) proposed that the definition adopted by the United Nations Disaster Relief Organization (UNDRO) for all natural hazards be applied to the hazard posed by mass movements )Guzzetti et al., 2005). Based on Varnes definition the landslide hazard is the probability of landslide occurrence within a specified period of time and a given area. Guzzetti et al. (1999) improved this definition and added the concept of landslide magnitude. In contrast to earthquakes hazard, in which the magnitude is applied as a measure of released energy during the event, measure of landslide magnitude is not uniform in the literature. Landslide magnitude has been defined as destructiveness of landslide by Hungr (1997). 15 Cardinali et al. (2002) and Reichenbach et al, (2005) defined landslide destructiveness as a function of the landslide volume and expected landslide velocity. However, evaluation of landslide volume and velocity is difficult for large areas and thus making the method impractical. Destructiveness can also be accessible from accurate inventory maps where landslide movements are primarily slow earth-flows (Hungr, 1997; Guzzetti, 2005). Therefore, based on the modified definition of landslide hazard assessment it includes the concepts of magnitude, frequency and location. Equation below expresses landslide hazard as the conditional probability of these three concepts. (2.2) Where , and predict how large a landslide will occur, how frequently it will occur and where it will be located respectively. The multiplication used in the equation above is due to the independence assumption among the three concepts. Although, due to lack of information regarding the landslide phenomenon, independence can be an approximation that makes the hazard assessment analysis easier to do but this assumption may not hold all the time and in every area (Guzzetti et al., 2005). For example in many areas it is seen that the larger landslides occurs less frequently than the small ones. The third component which is susceptibility of landslide was discussed earlier; therefore the other two probabilities of size and time are reviewed as follows. 16 2.3.3 Landslide susceptibility approaches To obtain the probability of occurrence for a landslide in a given geographic area, spatial probability (or called susceptibility) approaches are used. Numerous methods to analyze the probability of landslide occurrence are divided by Soeters and van Westen (1996) and van Westen et al. (1997) into inventory, heuristic, deterministic and statistical approaches. An initial step to any study of landslide hazard and landslide susceptibility mapping is to produce a landslide inventory. The basic information for assessment and decrease of landslide hazards or risk on a regional or community scale include the state of activity, certainty of identification, primary type of landslide, main direction of motion, thickness of material involved in landslide and dates of landslide occurrences. Detailed landslide inventory maps are able to provide these types of information (Wieczorek, 1984). Inventory maps preparation is done by collecting historic data of landslide events or using aerial photograph interpretation accompanied with field verification. Depending on the nature of problem, inventory maps can show detailed features of the landslides and sometimes they present only points representing locations of the landslides. In addition, the frequency of landslides can be determined in an area. It should also be mentioned that 17 Table2.1 Pros and Cons of priority ranking systems for state transportation agencies (Huang et al., 2009) Ranking system agency ODOT I ODOT II OHDOT NYSDOT UDOT WSDOT TDOT Pros Cons -Weak risk component -Strong hazard rating system -Lacking asset management -Include asset management -Weak hazard rating -Use highway function class -Does not include soil slopes, fill failures or frozen ground -Includes rock slopes, soil slopes -Complex review procedure and embankments -Does not include frozen ground -Includes risk assessment -Heavily weights ditch effectiveness -Does not include soil slopes, fill failures or frozen ground -Includes risk assessment with -Heavily weights ditch effectiveness adjustments for geologic factor -Does not include soil slopes, fill failures or frozen ground -Good risk and asset management -Weak hazard rating program -Does not include soil slopes, fill failures or frozen ground -Balanced hazard and risk rating -Lacking asset management -Does not include soil slopes, fill failures or frozen ground -Balanced hazard and risk rating MODOT -Unique graphic relationship between risk and consequence -Strong hazard rating system BCMOT -Scaling factors for each category -Lacking asset management -Does not include soil slopes, fill failures or frozen ground -Scaling factors increase low hazard and low risk potentialDoes not include soil slopes, fill failures or frozen ground are not equal -Includes cost estimates 18 the frequency-magnitude relations may be derived from landslide inventories that is useful to realize landslide probabilities (Yesilnacar, 2005). Heuristic approaches estimate landslide potential from data on preparatory variables based on expert knowledge and opinions. The assumption is that the relationships between landslide susceptibility and the preparatory variables are determined. Then a set of variables is entered into the model to estimate susceptibility of landslide (Gupta and Joshi, 1989). The heuristic models have some limitations such as they need long-term information about the landslides, their triggering factors, the subjectivity of weightings (and ratings of the variables) and mostly the required information for them is not available. Deterministic approaches deal with slope stability analyses and they are commonly used in site-specific scale. To be able to apply these methods, the ground condition should be uniform relatively across the study region and the landslide types should be clear and fairly easy to analyze (Terlien et al., 1995; Wu and Sidle, 1995). Statistical models determine the statistical combinations of influential variables in landslide occurrence in the past. This determination is done for areas which are currently free of landslides, but having conditions that are similar to those with landslide in the past. In the literature, there are two major statistical method groups, bivariate and multivariate methods (Wahono, 2010). 19 In bivariate statistical method, each variable influential in landslide is overlaid with the landslide inventory map, and considering landslide densities weighting values are calculated for each class. In order to calculate the weighting values, there are many methods such as information value, weights of evidence and statistical index methods in the literature (Gokceoglu et al., 2000; Zerger, 2002; Lee and Sambath, 2006; Kanungo, 2006). In multivariate statistical method, the weighting values are obtained by combining of all influential variables. These values denote the contribution degree of each combination for each influential variable to landslide susceptibility within each mapping unit. This method is based on the presence or absence of landslide occurrence in the mapping unit (Suzen and Doyuran, 2004; Gorum et al., 2008; Lamelas et al., 2008; Tunusluoglu et al., 2008). It should be mentioned that one of the limitations of multivariate statistical approaches is that it is probable that such statistical methods result in very deceptive analysis result when used in a black-box manner (Ho et al., 2000). In comparison with the bivariate method, the multivariate approach is to some extent costly and time consuming in gathering and data analysis (Firman, Wahono, 2010). In the following, some common bivariate and multivariate statistical approaches including multiple linear regression, discriminate factor and logistic regression models are discussed. Multiple regression and discriminant analysis are such conventional multivariate statistical methods in which the weights of influential variables in landslide occurrence denote the relative contribution of each variable in landslide occurrence in the study area. 20 It is needed to use continuous data in these multivariate statistical models and also when both methods takes only two values for influential variables (landslide occurs or not), they present limited value and under these conditions, the assumptions required to test the hypothesis in regression analysis are violated (Carrara, 1983). In such cases, another multivariate technique, named logistic regression is implemented to estimate the probability of landslide occurrence. Logistic regression, which is a multivariate analysis technique, predicts the presence or absence of a result based on values of a set of predictor variables. There are advantages in using logistic regression over the other methods. First, variables can be either continuous or discrete, or any combination of these two types and secondly the distributions of variables do not necessarily have to be normal (Lee and Evangelista, 1991). Among the recent methods for landslide susceptibility assessment, some studies adopted fuzzy logic and artificial neural network models. Fuzzy set theory presented by Zadeh (1973) is a powerful method to handle complicated problems in different disciplines (Lee, 2006). A fuzzy set can be described as a set containing members that have various degrees of membership in the set (Ross, 1995). In fact, membership of the elements can take on any value in the range of (0, 1) reflecting the degree of certainty of membership. For landslide susceptibility maps, generally, the attribute of interest like landslide causal factors measured over discrete intervals, and the membership function 21 can be expressed as membership values (Lee, 2006). Given two or more maps with fuzzy membership values for the same variable, a variety of operators can be applied to combine the membership values (Zimmerman, 1996). An artificial neural network (ANN) is a mechanism inspired by the structure of biological neural networks which makes us able to acquire, represent and compute a mapping from one multivariate area of information to another, given a set of data representing that mapping. In other words, an artificial neural network creates a model to generalize and predict outputs from inputs (Garrett, 1994). The most frequently used neural network method is the back-propagation training algorithm. Generally, this algorithm trains the network until the intended minimum error is obtained between the actual and desirable output values (Pradhan and Lee, 2010). The training process is done by a set of examples of associated input and output values. This learning algorithm which is a multi-layered neural network is composed of different layers including an input layer, hidden layers, and an output layer (see Figure 2.2). Multiplying each input by a corresponding weight is done by the hidden and output layer. After summing the product, they get processed using a nonlinear transfer function to obtain the final outcome (Gurney, 1997). The artificial neural network has many advantages over the other statistical approaches. For instance in this method we do not need to use specific statistical 22 variables and also any specific statistical distribution for the data. In addition, integration of GIS Figure 2.2 Example of multi-layered neural network in landslide susceptibility analysis data or remote sensing data is easier in artificial neural network because we are able to define the target classes with much more consideration to their distribution in the corresponding domain of each data source (Zhou, 1999). Also ANNs method give a more optimistic assessment of landslide susceptibility than logistic regression analysis (Nefeslioglu et al., 2008). The chart displayed in Figure 2.3 shows a classification for a various of landslide susceptibility methods discussed. 23 2.3.4 Probability of landslide magnitude To estimate the probability of landslide magnitude, different types of landslide inventories were used (Malamud et al., 2004; Picarelli et al., 2005). The area, volume, velocity or momentum of the landslide event were used as the proxy for the landslide Figure 2.3 Classification of landslide susceptibility analysis approaches (Yiping 2007) magnitude in different studies (e.g., Guzzetti, 2002; Marques, 2008; Jaiswal et al., 2010). Assuming landslide size as its magnitude approximation, the first component of the hazard assessment equation is estimated from the analysis of the frequency–area distribution of landslide dataset (inventory map). Studies show that the landslide size 24 increases up to a maximum value as the number of landslides grows; then it decreases rapidly along a power law (Malamud et al., 2004; Guthrie et al., 2004). Landslide hazard researchers (Pelletier et al., 1997; Stark and Hovius, 2001; Guzzetti et al., 2002; Guthrie and Evans, 2004; Malamud et al., 2004) have found that the probability density function (PDF) of landslide size is compatible with a truncated inverse gamma distribution very well. Using this distribution the probability density function of landslide size ( ) can be given as equation below. (2.3) Where is the gamma function of and are parameters of the distribution. By fitting equation above to the available inventories, the distribution parameters can be found. In another study of frequency–size (area) of landslides, double Pareto probability distribution has been found in agreement with probability distribution function of landslide size (Stark and Hovius, 2001). Using this distribution is given as equation below. (2.4) 25 Where and These probability distributions are converted to cumulative distribution function (cdf) to estimate the probability of occurrence of a landslide with a magnitude larger than a specific minimum amount. 2.3.5 Probability of landslides frequency To obtain the probability of landslide occurrence time, we should gain the exceedance probability of occurrence of the event during time ‗t‘. To be able to model the landslide occurrence time in this way, we need to make an assumption that landslides are independent random point-events over time (Crovelli, 2000). Two common probability models in this regard are the Poisson and the Binomial models. The Poisson model shows the probability of a random-point events occurring in a fixed period of time if these events occur with a known average rate and independently of the time since the last event (Ahrens, 1982). Frequency analysis of natural phenomena such as volcanic eruptions floods and landslides are modeled using the Poisson model (Crovelli, 2000). The probability occurrence of ‗n‘ landslides during time ‗t‘ using the Poisson model is given by equation below. (2.5) 26 Where is the average rate of landslide occurrence and corresponds to the reverse of mean recurrence interval between successive events. These variables can be obtained from a multi-temporal landslide inventory maps. Also, the exceedance probability of landslide (the occurrence probability one or more event during time ― t‖ is given as: (2.6) There are some assumptions which should be taken into account in both prediction of future landslide occurrences and applications of the results of the probability model. These assumptions include: (1) the probability of a landslide event happening in a very short time is proportional to the length of the time period; (2) the number of landslide events in separate time periods are independent (3) the probability of more than one event can be neglected in a short time period; (4) The past and future events observations have the same mean recurrence time; and (5) The probability distribution of landslide events having fixed time period length is the same (Crovelli, 2000, Guzzetti, 2005). These assumptions should be considered for the binomial probability model as well which is discussed as follows. 27 The second commonly used model is binomial model which consider the landslide events as random-point events in time. In this model, time is divided into discrete intervals of fixed length that within each time interval an event may or may not occur (Neumann, 1966). The binomial model was adopted to study the temporal occurrence of phenomena such as floods and landslides. The exceedance probability of landslide occurrence during time ― t‖ by employing the binomial probability model is given as equation below. (2.7) Where P is the estimated probability of a landslide event in time ― t‖, and its reverse (1/P) is the estimated mean recurrence interval between successive landslide events. This parameter(s) is obtained from landslide inventory maps the same as Poisson model. The results of Poisson and binomial probability models are not the same for short mean recurrence intervals while the binomial model overvalue the exceedance probability of landslide events in the future. But for long intervals these two models result in the compatible and similar outcomes (Crovelli, 2000). 2.3.6 Vulnerability 28 The International Society of Soil Mechanics and Geotechnical Engineering defines ― vulnerability‖ as the degree of loss to a given element (or set of elements) within the area affected by the landslide hazard. It is a non-dimensional value between 0 (no loss) and 1 (total loss). For properties, the loss is expressed as (the value of the damage)/(the value of the property); for persons, it is shown as the probability that a person will die, given the person is hit by the landslide (Wong et al., 1997). Vulnerability can also be used to predict the damage probability for properties and persons; In this case it will be expressed as the probability of loss and not the degree of loss (Fell, 1994; Leone et al., 1996). There is no completely united methodology for quantitatively assessment of landslide vulnerability in the literature. This estimation of vulnerability for landslides is qualitative, subjective and based on expert knowledge most of the time. As an example, the vulnerability of a property which is located at the base of a steep slope is more vulnerable (higher vulnerability) than a property located further from the base and it is because of the debris movement velocity (Dai et al., 2002). Although vulnerability is often defined as a value varying between 0 and 1, it has been considered in some literature (e.g. Remondo et al., 2008) as a value greater than 1 (i.e. (the value of the damage)/(the value of the property) >1 or repair cost more than a new construction). Vulnerability depends on both the landslide intensity ― I‖ and the element susceptibility ― S‖ (or reverse of element resistance at risk which is ― 1/R‖). The general equation can be 29 written in form of V = f (I, S) (Li et al., 2010). Various types of landslide have different intensity levels and therefore impose different degree of vulnerability. For example based on study of Amatruda et al. (2004), large rock falls intensity level in the open areas is always high to very high, while slides display low to medium intensity most of the times. In the meantime, if a person is buried by debris, (s)he will die most likely but if (s)he is struck by a rockfall, only injury may happen (Li et.al., 2010). In order to differentiate low, medium, and high intensity for block fall, rockfall, slides, and flows, Heinimann (1999) determined the vulnerability to different landslide intensities for different types. However, he mentioned the necessity of assumption for required information as a main limitation of the method. Some ranges and values on vulnerability of persons in exposed areas, in a vehicle or in a building have been recommended based on historic records of Hong Kong by Finlay (1996). The vulnerability matrices were provided by Leone et al., (1996) which can be used to obtain the vulnerability of structure, person, facilities, etc. Duzgun and Lacasse (2005) proposed a 3D conceptual framework with scale (S), magnitude (M) and elements at risk (E) to assess vulnerability. Also Zêzere et al., (2008) provided the vulnerabilities of structures and roads affected by different intensities of landslides their work were based on experiences or historic databases while using the information of structure type, age, etc. In addition, a univocal conceptual framework for quantitative assessment of physical vulnerability to landslides was introduced by Uzielli et al. (2008). Kaynia et al. (2008) studied the use of first-order second-moment method application in vulnerability 30 estimation. Some researcher (Li and Farrokh, 2010) proposed approximate functions for vulnerability of properties and persons based on landslide intensity and the susceptibility of elements at risk. Generally speaking, it is very complex to assess vulnerability to landslides in contrast to other natural phenomena such as floods and earthquakes. For example, the location, the status of a person (sleeping or awake) within the affected property or the size of windows in the building would influence significantly the amount of loss and therefore vulnerability degree. Moreover, vulnerability to landslide is impacted by some other factors such as mass velocity, impact angle and strength of the structure material; since it is not easy to estimate exactly all of these factors involved in vulnerability, it is advised to analyze the vulnerability in an average sense (Li, 2010). 2.3.7 Landslide risk management strategies As discussed, the landslide risk management is a process on whether the obtained risks by risk analysis are tolerable and whether the existing risk control methods are adequate. If the control measures are not enough, this landslide assessment process tells us what alternative approaches are required. These recommendations should be done by consideration of the significance of the estimated risks and the related social, environmental and economic aftermaths (Fell et al., 2005). Landslide risk management is described as a whole process including susceptibility, hazard, vulnerability and risk 31 mapping done to assess the existing landslide threat in the study area (Lacasse et al., 2010). When the risk from a landslide in susceptible areas to landslide is recognized, the relevant authorities have to select a solution form a variety of strategies to deal with it and mitigate the risk. Dai et al., (2002) categorized these strategies into planning control, engineering solution, acceptance criterion and monitoring and warning systems as follows. i) Planning control Planning control tries to direct the development pattern of the susceptible (or affected) area in a way that reduces the landslide risk and is very economical approach to choose. This strategy can be performed by eliminating the current constructions and/or discouraging new constructions in high risk areas to implement regulating in susceptible areas (Kockelman, 1986). ii) Engineering solution Two engineering solutions are commonly applied in general to mitigate the landslide risk in susceptible area. The first one is to modify the unstable slope to stop onset of 32 landslide and the second one is to control the landslide movement not to be too damaging. It should be mentioned that this is the most expensive option to reduce landslide risk (Dai et al., 2002). iii) Acceptance option When a landslide risk is well understood, it may be recommended to select the acceptance option. It is one of the most difficult steps in landslide risk management process and the selection of this option depends mainly on whether the benefits the people receive in the area under the study by this option compensate the risks of landslide or not (Bromhead, 1997). To select this strategy, acceptable risk criteria should be set up first which is shown as F–N curve in theory and is established using the existing observations for different events such as road traffic, plane crash, dam failure and landslide as well. This curve is a plot relating the number of fatalities (N) to the cumulative frequency (F) of N or more fatalities in log–log scale (see Figure 2.4). To define the acceptable and tolerable risk levels the public concern is considered by the authorities. Acceptable level is described as a level of risk in which no further reduction is obtained. This is desirable for the society to reach. Tolerable risk criteria usually require that maximum risk of mortality (death of a person) in a specific place should not be higher than a pre-defined threshold (Bunce et al., 1995). Acceptability of landslide risk depends upon factors such as the nature of the risk (engineered or natural slope failure), media coverage about the incident and the public 33 expectation from the event (whether it is frequent or rare to occur) (Lacasse and Farrokh, 2010). Figure 2.4 Example of risk criterion recommendation (F-N curve) iv) Monitoring and warning systems The main goal of a monitoring and warning system for a specified landslide is to evaluate the current status of the slope in terms of stability. This system determines 34 whether the landslide is in active condition or not. In case it is active and risky, some strategies as discussed earlier are at hand to choose. One can be to accept the consequences of landslide occurrence and the other option is to stabilize the slope or any other engineering solution (a monitoring system can be applied to confirm the effectiveness of the engineering work) (Dai et al., 2002). Finally a monitoring and warning system can be employed to warn people for emergency preparations or evacuation. Therefore landslide monitoring and warning system would be an alternative strategy to reduce landslide risk in case that engineering solutions were not practical and economical to choose or they did not work (Kousteni et al., 1999). A common used system for monitoring is inclinometer which detects small movements and deformations. The other widely used device is down-hole slope extensometer and although its sensitivity and precision are not the same and will not present completely the same result, it is able to support large soil displacements. Interferometric Synthetic Aperture Radar (InSAR) technique is a modern and powerful tool for monitoring mass movements of unstable slopes. The InSAR methodology is that using a couple of satellites on different orbits and based on the assessment of phase difference of two SAR interferogram of the same area, InSAR makes 3D maps form the terrain as discussed earlier (Kimura and Yamaguchi, 2000). The choice between available options is dependent on the preference of the decisionmakers considering all possible outcomes of each of the options. After the probabilities 35 and consequences have been estimated, methods of decision analysis may be used to arrive at management decisions by identifying the alternatives of actions, possible outcomes, and respective consequences or cost for each scenario. v) Decision making Risk assessment has the principal objective of deciding whether to accept, or to treat the risk, or to set the priorities. The decision on acceptable risk involves the responsibility of the owner, client or regulator, based on risk comparison, treatment options, benefits, tradeoff, potential loss of lives and properties, etc. Risk management is the final stage of risk management, at which the decision-maker decides whether to accept the risk or require the risk treatment. The risk treatment may include the following options (AGS, 2000): (i) accepting risk (ii) avoiding risk, (iii) reducing the likelihood, (iv) reducing consequences, (v) monitoring and warning system, (vi) transfering the risk, and (vii) postponing the decision (Pensomboon 2007). The alternative with the least expected cost is usually chosen if the expected value is the criterion for decision. Cost–benefit analysis is the most widely used method in the process of decision making. It involves the identification and quantification of all desirable and undesirable consequences of a particular mitigation measure. When measuring the cost of risk, a monetary value is generally used. By identifying the various available options together with relevant information for assigning design parameters, the cost and benefit of each mitigation measure can be assessed (Dai et al., 2001). 36 CHAPTER III QUANTITATIVE LANDSLIDE HAZARD ASSESSMENT USING COPULA MODELING TECHNIQUES 3.1. Overview Landslide is one of the most frequently occurring natural disasters on the earth. They cause a lot of human loss and damages annually in different areas around the world. Study of landslides and understanding of different involving aspects and their various causes are urgent in today world specifically in more susceptible areas and developing societies. In recent years, landslide hazard assessment has played an important role in developing land utilization regulations aimed at minimizing the loss of lives and damage to property. Vernes (1984) has defined landslide hazard as the probability of occurrence of a potentially destructive landslide within a specified period of time and within a given geographical area. Guzzetti et al. (1999) modified this definition and added the concept of landslide magnitude to that. This new component of landslide hazard mostly denotes 37 the destructiveness extent (landslide area) or intensity of the landslide event however there is no unique measure for that in the literature (Hungr 1997; Guzzetti 2002). Equation 3.1 presents this currently used definition of landslide hazard. H = P[M ≥ m in a specified time period & in a given location with specified preparatory factors] (3.1) Where in this equation H is the landslide hazard value (0-1)/year; ― M‖ is the landslide magnitude and ― m‖ is a specific magnitude amount (to be considered as an arbitrary minimum amount). In other words, Equation 3.1 is a conditional probability of occurrence of a landslide with a magnitude larger than an arbitrary minimum amount within a specific time period and in a given location. The ― preparatory factors‖ in the equation refer to all of the specifications of the area including geology, geometry and geotechnical properties. To evaluate landslide hazard quantitatively in regional scale, three probability components related to the concepts of ― magnitude‖, ― frequency‖ and ― location‖ need to be estimated. a) To estimate the probability of landslide magnitude, the area, volume, velocity or momentum of the landslide event have been used as the proxy for the landslide magnitude in different studies (e.g., Guzzetti 2002; Marques 2008; Jaiswal et al. 2010). However, no single generally accepted measure of landslide magnitude exists (Hungr 1997; Guzzetti 2005). In order to estimate the probability of landslide magnitude 38 in most studies, the relationship of the landslide magnitude and frequency is observed to typically have a power law distribution with a flattening of curve at the lower amount (e.g. Pelletier et al. 1997; Stark and Hovius 2001; Malamud et al. 2004; Guthrie and Evans 2004). These probability distributions are converted to cumulative distribution function (cdf) to estimate the probability of occurrence of a landslide with a magnitude larger than a specific minimum amount. b) To assess the probability of landslide recurrence (frequency) the first approximation is that landslides can be considered as independent random point-events in time (Crovelli, 2000). Two common models named the Poisson model and the binomial model are used to investigate the occurrence of slope failures using this approximation (Coe et al. 2000; Onoz and Bayazit 2001; Guzzetti 2005). The Poisson model is a continuous model consisting of random-point events that occur independently during time. Also the binomial model is a discrete model in which time is divided into equal discrete intervals and a single point-event may or may not occur within each time interval (Haight 1967). c) To estimate the probability of occurrence a landslide in a given location, spatial probability (or called susceptibility) approaches are applied. Generally speaking, landslide susceptibility methods are divided into two categories of qualitative and quantitative approaches. Qualitative techniques such as geomorphological mapping demonstrate the hazard levels in descriptive terms (Yesilnacar 2005) which are subjective and based on expert‘s knowledge and experience. On the other hand, quantitative techniques mainly include deterministic and statistical methods which both guarantee less subjectivity. 39 After evaluation of the hazard component values for the study area, the common quantitative approach is to multiply them assuming they are mutually independent (e.g., Guzzetti, 2005; Jaiswal et al., 2010). Chart displayed in Figure 1 presents the common steps required for quantitative landslide hazard assessment based on the independence assumption. In fact, in probabilistic terms landslide hazard is calculated as the joint probability of three probabilities as equation below. (3.2) Where is the probability of landslide magnitude, is the probability of landslide spatial probability‖ (susceptibility). The terms ― spatial recurrence (frequency) and S is ― probability‖ and ― susceptibility‖ are used in the literature interchangeably for describing the probability related to the ― location‖ of a landslide occurrence. Also ― probability of landslide recurrence‖ is used in this paper in a same meaning with ― exceedance probability‖ and ― temporal probability‖ as maybe seen in other studies (Coe, 2004; Guzzetti, 2005). 40 Magnitude-frequency analysis Probability of landslide magnitude (Pm) Triggering factors Temporal probability models Probability of landslide recurrence (Pt) Independent preparatory factors Susceptibility analysis Validation Historical landslide database Spatial probability (S) Landslide Hazard = Pm ˟ Pt ˟ S Validation Landslide hazard assessment/map Figure 3.1 Current general approaches in quantitative landslide hazard assessment 3.2 The Proposed Methodology The expression of landslide hazard in Equation 3.2 which is currently used for quantitative probabilistic landslide hazard assessment at medium mapping scale (1:25,000-1:50,000) could be argued (Jaiswal et al. 2010). This assumption that the 41 landslide hazard components including ― magnitude‖, ― frequency‖ and ― location‖ of a landslide are independent may not be valid always and everywhere (Guzzetti et al. 2005). This currently used simplification may be due to lack of enough historical data in a study area, lack of a suitable approach and also because of complexity of the landslide phenomenon (Jaiswal et al. 2010). It can be seen in lot of areas that geographical settings (― location‖ component of hazard) such as lithology, gradient (slope angle), slope aspect (the horizontal direction to which a mountain slope faces), elevation, soil moisture and soil geotechnical properties impact the landslide magnitude (Dai et al. 2002). Also, more frequent severe rainfalls (higher ― frequency‖ of landslide) can trigger more destructive (larger ― magnitude‖) landslides; or as Jaiswal (2010) mentions small triggering events will result in another landslide magnitude distribution than a large triggering event and also the locations where landslides will occur may be substantially different. Furthermore, in many areas we expect slope failures to be more frequent (higher ― frequency‖ of landslide) where landslides are more abundant and landslide area is large (Guzzetti et al. 2005). In fact, the dependence between the landslide hazard components is neglected just for simplification which can notably reduce the accuracy of the landslide hazard prediction. Other attempts have been done to overcome this simplifying assumption by estimating landslide hazard by direct using the number of landslides per year per mapping unit (Chau et al. 2004). However such approach requires a comprehensive multi-temporal landslide database, which is rarely available in practice (Jaiswal et al. 2010). To do a contribution in this regard, in this section we present a general methodology to consider the possible dependence between the landslide hazard 42 elements. Inventing such a general procedure seems to be necessary for better forecasting landslide hazard in regional scale. The required steps needed to quantitatively estimate the landslide hazard under the assumption of dependence between the hazard elements is explained as follows. In terms of landslide hazard elements of ― magnitude‖ and ― frequency‖, we obtain probability distribution for these two components if there is no noticeable dependence between any of these two and the others. Otherwise, any dependent component is evaluated as a ― numerical index‖ and not a probability distribution value. The ― numerical index‖ for landslide magnitude could be the quantity of area, volume, momentum or velocity of landslide depending on the data availability. Also, in terms of landslide frequency, ― mean recurrence interval‖ between successive failure events is implemented as the ― numerical index‖. In terms of landslide location, the meaning of the susceptibility values changes depending on the relationship they have with the other hazard components but their values remain the same. In other words, since the susceptibility values are membership indices (Lee and Sambath 2006) they could be both probability values to be employed independently (in case there is no dependence between ― location‖ and the other components) and ― numerical indices‖ to be applied in joint probability functions (when there is a dependence relationship). Different spatial factors such as slope gradient, aspect, curvature, distance from drainage, land use, soil parameters, altitude, etc are 43 selected by different authors depending on the study area and are combined using various quantitative methods to produce these membership indices in each mapping unit (e.g. Remondo et al. 2003; Santacana et al. 2003; Cevik and Topal 2003; Chung and Fabbri, 2003, 2005; Lee 2004; Saito et al. 2009). In case we have a noticeable dependence between landslide hazard components, there must be a joint probability function to be established and be applied for precise landslide hazard prediction. Therefore, selection of a suitable joint multivariate probability function is required. In the last years, different multivariate techniques were presented in different fields especially hydrological and environmental applications as follows. Gaussian distribution (normal) has been widely and easily applied in the literature but it has the limiting feature that the marginal distributions have to be normal. To obtain such a feature for Gaussian distribution, data transformation has been used in the literature through Box–Cox‗s formulas (Box and Cox, 1964). However, these transformations are not always useful and they could sometimes cause distortions of statistical properties of the variables (Grimaldi and Serinaldi, 2005). To overcome such a shortcoming, bivariate distributions with non-normal margins have been proposed: Gumbel bivariate exponential model with exponential marginals has been applied in the literature (Gumbel, 1960; Bacchi et al., 1994); bivariate Gamma distribution has been suggested in flood frequency analysis (Yue et al., 2001); bivariate Logistic and mixed models with Gumbel margins have also been used (Yue and Wang, 2004). In addition application of multivariate extreme value distributions have been presented and used by Tawn (1988, 44 1990) and Coles and Tawn (1991). Moreover, models such as multivariate Exponential, Liouville, Dirichlet and Pareto has been completely described in detail by Kotz (2000). Long and Krzysztofowicz (1992) studied the Farlie–Gumbel–Morgenstern and Farlie polynomial bivariate distribution functions in hydrological frequency which are not dependent of marginals. Also a general form of a bivariate probability distribution, using the meta-Gaussian distribution introduced by Herr and Krzysztofowicz (2005) which characterize the stochastic dependence between measured variables. However, all these distributions and models have these shortcomings: (a) increasing the number of involved variables gets the mathematical formulation complicated; (b) although analyzed variables could show different margins in reality, all of the univariate marginal distributions have to be the same type; (c) marginal and joint behavior of studied variables could not be distinguished (Genest and Favre 2007). Fortunately, the Copula modeling technique can overcome all of these drawbacks. In fact it is able to formulate a variety types of dependence between variables (Nelsen 1999); it could allow each of the random variables to follow its own distribution types independently from the other variables; and it can model marginal distribution of each random variable unbiased and not based on a pre-defined distribution type (Zhang et al. 2006); also marginal properties and dependence structure of variables can be investigated separately using Copula modeling technique (Grimaldi and Serinaldi 2005). 45 Dependence assessment using Copula model is widely applied in finance such as credit scoring, asset allocation, financial risk estimation, default risk modeling and risk management (Bouy et al. 2000; Embrechts et al. 2003; Cherubini et al. 2004; Yan 2006). In biomedical studies, Copulas are applied in modeling correlated event times and competing risks (Wang and Wells 2000; Escarela and Carri`ere 2003). In engineering, Copulas are used in probabilistic analysis of mechanical and offshore facilities (Meneguzzo, et al. 2003, Onken, et al. 2009) and also multivariate process control and hydrological modeling (Yan 2006; Genest and Favre 2007). More specifically, in hyrological engineering, bivariate Copula function (2D) has been used in order to model rainfall intensity and duration (De Michele and Salvadori, 2003); bivariate Copula was applied to describe the dependence between volume and flow peak (Favre et al., 2004); trivariate Copula (3D) was employed in multivariate flood frequency analysis (Grimaldi and Serinaldi, 2005); and also De Michele et al. (2005) employed 2D Archimedean Copulas which is the most common form of Copula models to simulate flood peakvolume pairs to check the adequacy of dam spillways. In geotechnical engineering studies, Copula modeling approach has not been applied yet so it is believed that this presented work could pave the way of implementing such a powerful statistical tool in this field. Based on the proposed methodology three scenarios are possible: a) when there is no significant dependence between the hazard components in a study area, obviously ― multiplication‖ would be performed to obtain the hazard values. b) bivariate Copula function would be applied when there are only two dependent hazard elements. And c) 46 when all of the three components are significantly dependent to each other, trivariate Copula function would be employed (Fig.2). Historical landslide database Triggering factors Independent preparatory factors Magnitude index (M) Frequency index (T) Location index (S) Dependent? No H = Pm ˟ Pt ˟ S Probability of landslide magnitude (Pm) if M is independent H = Pm ˟ P(t ∩ S) Probability of landslide recurrence (Pt) if T is independent H = Pt ˟ P(m ∩ S) Spatial probability (S) if S is independent H = P(m ∩ t) ˟ S Otherwise Validation Landslide Hazard Yes H = P(m ∩ t ∩ S) Landslide hazard assessment/map Figure 3.2 The proposed methodology for quantitative landslide hazard assessment using Copula modeling technique 3.3 Study Area and Data Part of Western Seattle area was selected as a suitable region to evaluate the proposed methodology (Fig.3.3). The Seattle area has long been received damages and losses to 47 people and properties due to landslides. Shallow landslides which are the most common type of slope failure in this area usually occur every year from October through April within the wet season (Thorsen 1989; Baum et al. 2005). In 1998, the Federal Emergency Management Agency (FEMA) launched a hazard management program called Project Impact and Seattle was one of the pilot cities in this study. Shannon and Wilson, Inc. was assigned to collect a digital landslide database dating from 1890 to 1999 (Laprade et al. 2000) and the landslide data became freely available to the USGS for use. This comprehensive compiled database in Seattle, WA was an exceptional opportunity for scientists for further study of landslide in Seattle area. For example, Coe (2004) employed this historical database to conduct the probabilistic assessment of precipitationtriggered landslides using Poisson and bionomial probability models. He expressed the results as maps that show landslide densities, mean recurrence intervals, and annual exceedance probabilities in the area. Also Harp et al. (2006) using this database performed an infinite-slope analysis to establish a reliable correlation between a slopestability measure (factor of safety, FS) and the locations of shallow slope failures in the Seattle area. Most of these mentioned efforts including analysis results, maps and the historical landslide database established an appropriate base for this presented study in this section. Seattle area was selected as the study area because it was believed that the number of landslide events in the selected region was large enough (357 events) (Fig.3.3). 48 Figure 3.3 The location of the study area and landslide events in part of Western Seattle, WA area (Coe et al. 2004) This number of landslide record makes it possible to test the dependence between hazard components with more accuracy and also to evaluate the presented model more confidently. Further, the temporal length of the landslide database was long enough (87 years from 1912 to 1999) to make the expected validity time of the model longer. Also as it was required to use one part of the landslide records for modeling and the other part for validation, a division was required to be done. The number of landslide events in each part was the basis for this categorization. In fact, it was needed to choose a 49 time duration (yearly basis) before the year of the last landslide record (1999) which the landslide events within that be applied for validation part. The time duration of 19971999 that include 79 slope failure events was selected to verify how much the proposed model is capable to predict the future landslide hazard. Although this selection was subjective, it is believed that in any other way of data grouping, the total dataset would be poorly divided due to the large number of landslide events available in 1996 (see Fig.3.4). Furthermore, it should be noted that a shortcoming of the existing landslide database is that all of the geographical locations of failures consist of point locations, not polygons, which cause some level of approximation in the analysis (Harp et al. 2006). 3.4 Method of analysis As previously mentioned, Copula is a type of distribution function used to describe the dependence between random variables. In other words, Copulas are functions that connect multivariate probability distributions to their one-dimensional marginal probability distributions (Joe 1997). The Copula concept in dependence modeling goes back to a representation theorem of Sklar (1959) as follows. Let assume that we have n variables (or populations) as variable as ( and N observations are drawn for each are the marginal cumulative ; and also distribution functions (CDFs) of the variables the non-normal multivariate distribution Now in order to determine of the variables, denoted as Copula, C, could be used as an associated dependence function. 50 This function returns the joint probability of variables as a function of marginal probabilities of their observations regardless of their dependence structure as below. (3.3) Where if ( ) for i = 1, 2,.. n is the marginal distribution and C: = Copula is continuous (Grimaldi and Serinaldi 2005). Different families of Copulas have been developed in last decades and the comprehensive descriptions of their properties have been compiled by some authors (Genest and MacKay 1986; Joe 1997; Nelsen 1999). The most popular Copula family is Archimedean Copulas (Yan 2006). Archimedean Copulas are frequently used because they allow modeling dependences easily and very well with only one parameter. Archimedean Copula for two random variables, X and Y, with their CDFs, respectively, as F(x) = U and F(y) = V is given by (3.4) Where and denote a specific value of U and V respectively; and also Copula generator which is a convex decreasing function satisfying is the ; and when Also the conditional joint distribution based on Copula is expressed as follows. Let X and Y be random variables with their CDFs, respectively, as F(x) = U and F(y) = V. 51 The conditional distribution function of X given Y = y can be presented by the equation below. (3.5) As discussed earlier, this paper presents three random variables of ― S‖, ― T‖ and ― M‖ as the ― numerical index‖ for landslide location, landslide frequency and landslide magnitude respectively for all 278 landslide events (i.e. observations). Considering what discussed above regarding the Copula theory, equation below presents the mathematical terminology used hereafter in this paper: Variables: (S, T, M) Observations: ( ,( Dependence modeling using Copula function: (3.6) Where depending on the degree of correlation between the variables, the Copula function (C) could be in either bivariate or trivariate form. 52 3.4.1 Data preparation Obviously as the first step toward the modeling, it was needed to prepare the input data for all of the three landslide hazard components including landslide magnitude, landslide frequency (recurrence) and landslide location. As discussed earlier, these components could be either ― numerical index‖ or probability distribution values depending on their dependence relationship with each other. But in order to begin the modeling, we assume that they are all numerical indices (Fig3.2). Using this assumption, we would be able to test the mutual dependence to observe if it is required to keep each hazard component values as numerical indices or to transform them to probability distribution form. The calculation process for landslide magnitude index (M), landslide frequency index (T) and landslide location index (S) is discussed as follows for 278 out of 357 landslide events from 1912 to 1996 (the rest of the dataset records will be applied for validation part). 3.4.1.1 Landslide magnitude Although different proxies have been used for landslide magnitude in different studies as mentioned earlier, ― area‖ (aerial extent) is recognized as one of the most common and reasonable representatives for ― landslide magnitude‖ by different authors (Stark and Hovious 2001; Guthrie and Evans 2004; Malamud et al. 2004; Guzzetti 2005). In the 53 historical landslide database of West Seattle region the ― landslide area‖ was not directly recorded and the ― slope failure height‖ was the only available dimension of the slope failure events. The ― slope failure height‖ (h) is defined as the approximate elevation difference between the head-scarp and the slip toe (Fig3.5), and it was estimated from historical records and also field verification (Shannon and Wilson Inc 2000). Figure 3.4 Temporal distribution of landslides from the landslide database versus the year of occurrence To estimate the ― area‖ of the each landslide from its ― slope failure height‖ (h), this height dimension was converted to the ― landslide length‖ (L) assuming that the angle of the slope and the slip gradient of the failure are the same for each landslide event (Eq3.7) (Fig3.5). Furthermore, to estimate the failure area, a general relationship between the landslide dimensions (length and width) was required. Such a relationship was needed to 54 be generic, geometry-based and independent from the geology of the displaced materials in landslide; and therefore the ― fractal theory‖ was the best tool to be used in this regard. The fractal is a mathematical theory developed to describe the geometry of complicated shapes or images in nature (Mandelbrot, 1982). The fractal character of landslides can be described by a self-similar geometry and it was recommended as a valuable tool for investigation of landslide in susceptible areas (Kubota, 1994; Yang and Lee 2006). Yokoi (1996) states that landslide blocks in a huge landslide have a fractal character. He also concluded that their fractal dimension with respect to width is 1.24 and with respect to length is 1.44 on average and this fractal dimension in width (or length) for a large landslide area is not dependent on the base rock geology. These findings were valuable mathematical relationships (between length and width) to be applied in our landslide database for estimating the ― area‖. Assuming each landslide event as one block in our dataset we estimated the width of the ― failure area‖ from the available length (Eq3.8 and Eq3.9). (3.7) L h/ D ∝ 1.24W and A L D ∝ 1.44L 1.16 W ∝ 1.16 L (3.8) (3.9) / Where D is the landslide fractal dimension, W is the width of each landslide block, L is the length of each landslide block, is the slope gradient, h is the slope failure height and 55 A is the landslide ― area‖ estimation (Fig3.5). This calculation was done for 278 landslide events in the study area to estimate one magnitude index (M) for each record. Figure 3.5 Definition of slope failure height (h), slope angle ( and length (L) in a shallow landslide 3.4.1.2 Landslide frequency In terms of landslide frequency, ― mean recurrence interval‖ between successive failure events was selected as the landslide frequency index (T) in the study region. The ― mean recurrence interval‖ is simply a representative of landslide frequency; and easily calculated by dividing the total landslide database duration over the number of events. Every single landslide event (totally 278 events) is assigned either a ― mean recurrence 56 interval‖ or its corresponding value from a ― probability distribution‖ depending on the dependence between hazard components. 3.4.1.3 Landslide location As discussed earlier, landslide susceptibility values should be determined to obtain the ― membership indices‖ for the landslide location component. These susceptibility values could be estimated using different methods. Among all of the available approaches, deterministic method was selected for this study. This method deals with slope stability concept and can be used in both site-specific scale and regional-scale studies (Terlien et al. 1995; Wu and Sidle 1995; Guzzetti et al. 1999, 2005; Nagarajan et al. 2000; Ardizzone et al. 2002; Cardinali et al. 2002; Santacana et al. 2003). Deterministic methods in regional-scale studies mostly calculate the factor of safety (FS) in the mapping units (cell) of the study area. FS is the ratio of the forces resisting slope movement to the forces driving it, i.e. the greater the FS value the more stable is the slope in the mapping unit. Number of methods has been invented by different authors using GIS analyses to calculate the FS values in different scales (Pack et al. 1999; Montgomery and Dietrich, 1994; Hammond et al. 1992; Iverson, 2000; Baum et al. 2002; Savage et al. 2004). In this paper, the FS values of susceptibility analysis performed by Harp et al. (2006) in Seattle area was used as the required ― membership indices‖ (Eq3.10). This method is described as follows. (3.10) 57 Where FS is the factor of safety, α is the slope angle and is water unit weight, γ is the unit weight of slope material, c′ is the effective cohesion of the slope material, υ′ is the effective friction angle of the slope material, t is the normal slope thickness of the potential failure block, and r is the proportion of the slope thickness that is saturated. It was assumed that groundwater flow is parallel to the ground surface (with the condition of complete saturation, that is r = 1) (Harp et al. 2006). The FS was then calculated by inserting values for friction, cohesion and slope gradient in Equation 10 for each preassigned mapping cell in the area. In order to provide the initial values of the FS equation (Eq3.10), geology and topography data was needed to be employed. The geology data was obtained from the digital geology map of Seattle area at a scale of 1:12,000 created by Troost (2005) (Fig3.6 a). Material properties (including friction angle and cohesion values as shear-strength components) were selected based on an archived database of shear-strength tests performed by geotechnical consultants. These properties were assigned to each of the geologic units of the digital geology map. Also topography data was acquired from the topography (slope gradient) map produced by Jibson (2000) in Seattle area. This map was created by applying an algorithm modified in GIS format to the used Digital Elevation Model (having 1.8-m cell) which compares the elevation of adjacent cells in the region to calculate the steepest slope (Harp et al. 2006) (Fig3.6 b). According to the probabilistic definition of location index, the values are basically between (0, 1) however the results for FS show that there are some values of FS > 1.0 58 (Eq.10) (Harp et al. 2006). In order to use the FS value of each mapping cell as a ― numerical index‖, it was needed to become normalized between (0, 1) and inverted. Then each landslide point location was assigned the numerical index of its corresponding mapping cell. Figure 3.6.c displays the landslide location (S) map in the study area. 3.4.2 Dependence assessment In previous section three index values of frequency, location and magnitude were obtained for each landslide record. In other words, there are three sets of data for the whole study area including ― T‖, ― S‖ and ― M‖ each having 278 members (Eq3.7). Since the Copula modeling technique is used to model the dependence between random variables, two critical questions need to be answered here first: 1) can we consider all of the indices obtained in previous sections for 278 landslide events as ― uncorrelated random variable‖? 2) how is the dependence relationship between the three sets of ― T‖, ― S‖ and ― M‖? To respond to the first question, ― random variable‖ concept is required to be defined first. ― Random variable‖ is a variable whose value is subject to variations due to chance. In fact, a random variable does not have a pre-known amount and it can take different values, each with an associated probability (Fristedt et al. 1996). Considering this definition, three index values of frequency, location and magnitude of every single 59 landslide event in our study area are unknown and random by nature. In other words, it is not difficult to understand that none of the three values (S, T, M) of a single landslide event can be predicted when the event is considered separately from the other landslides. Furthermore analysis of the historical record of landslides indicates that the 357 events listed in the catalogue occurred at 322 different spots (in digital map), with only 28 sites affected two or more times. In fact, the same spot was hit on average 1.1 times, indicating a low rate of recurrence of events at the same place. All this concurs that for the Western Seattle area landslides can be considered as ―un correlated random‖ events in time. To address the second question, visual and quantitative tools were used to check the dependence between ― T‖, ― S‖ and ― M‖ sets. To visually measure the correlation between each two sets, a scatter plot of data could be a good graphical check (Genest and Favre 2007). This visual check was performed for 278 landslide events starting in 1912 and ending in 1996 for all three potential dependence scenarios (Fig3.7). Scatter plots show that although the correlation between ― S‖ and ― M‖ sets is significant enough the correlation between the other sets is negligible in the study area. The trivial correlation between ― S‖ and ― T‖ indices is also confirmed by the previous study conducted by Coe (2004) in which concluded that there is no significant correlation between slope angle (as the location parameter) and landslide frequency in the Seattle area. 60 (a) (b) (c) Figure 3.6 a) Slope map; b) Geologic map; c) Landslide location index (S) map in the study area 61 In addition, to quantify the level of dependence, a standard test was required. In cases such as ours where the association is non-linear (Fig3.7 a), the relationship can sometimes be transformed into a linear one by using the ranks of the items rather than their actual values (Everitt, 2002). For instance, instead of measuring the dependence between ( and ( ( values the ( are employed where and stands for the rank of stands for the rank of among ( and among ( . In this regard, well-known rank correlation indicators such as Spearman's and Kendall's rank correlation coefficient were used in this study (Spearman 1904, Kendall 1973). These rank correlation coefficients were preferred to be applied here because they have been developed to be more robust than traditional Pearson correlation and more sensitive to nonlinear relationships (Croxton 1968). Spearman‘s rho (rank correlation coefficient) is given by equation below. =1– Where (3.11) is the Spearman‘s rho (rank correlation coefficient) and is the difference in the ranks given to the two variable values. Also the Kendall's rank (empirical version) is defined by = (3.12) 62 Where is the Kendall's Tau (rank correlation coefficient); and and number of concordant and discordant pairs respectively. For instance, two pairs of ( and ( are said to be concordant when ( ( are ) and discordant when (Genest and Favre 2007). Both of these rank correlation coefficients were computed for measuring dependence between each two pairs of sets i.e. (M, S), (M, T) and (S, T) (Table 3.1). The findings verify the negligible correlation between (M, T) and also (S, T). Further, it shows a significant and positive correlation between location and magnitude indices (M, S) as expected. Therefore, magnitude and location indices were considered as the only significant correlated pair to be used for building the bivariate Copula model in the following sections. Table 3.1 Rank correlation coefficients of the pairs (M, S), (M, T) and (S, T) Correlation M-S M-T S-T Spearmans’ 0.653 -0.012 -0.043 Kendalls’ 0.541 -0.008 -0.031 63 3.4.3 Marginal distribution of variables To create the bivariate Copula model, it was required to obtain the best fitted marginal probability distributions for both location (S) and magnitude indices (M). Different marginal probability distributions can be examined when the initial values of the random variables are not limited to a maximum value. Since the values of location indices (FS) are limited to the range of (0, 1), data transformation needs to be performed first. This transformation changes the range of the limited data to an unlimited positive range of [0, ∞) theoretically. This unlimited positive range was (0, 452) for our transformed location indices. These transformed location indices are labeled as ― TS‖ hereafter for simplification. To be able to find the best marginal distribution for the variables, both visual and quantitative methods were employed. As a visual approach, histograms of TS and M datasets were obtained, drawn and several probability density functions were fit to each to find out which one is the best choice (Fig3.8). Table 3.2 shows the parameters of the candidate distributions for the variables of both sets. Also as a quantitative method, AIC criterion was used to choose the best distributions. AIC criterion is a measure of the relative goodness of fit of a statistical model (Akaike 1974). ― AIC‖ of each model is calculated using its likelihood function (the probability density function of each distribution with the estimated parameters) and the number of parameters in the model (Eq3.13). The model having smaller AIC is the most appropriate one for the data. 64 (a) (b) (c) Figure 3.7 Scatter plot of landslide hazard component indices: a) Location index versus magnitude index, b) Frequency index versus magnitude index, c) Frequency index versus location index 65 (3.13) Where ― L‖ is the maximized value of the likelihood function for the estimated model and ― K‖ is the number of parameters in the model. The estimated AIC criterion for all the distributions can be seen in Table 3.3. The Kolmogorov–Smirnov test is another goodnessof-fit statistics which can be used to determine if a random variable X could have the hypothesized, continuous cumulative distribution function; it uses the largest vertical difference between the theoretical and the empirical cumulative distribution function (Yevjevich, 1972). As given in Table 3.4, the KS test at the 5% significance levels shows that the Box–Cox transformed data are normally distributed. Considering and comparing all the visual and quantitative results, Exponential distribution (Eq3.14) was selected as the best fit to TS set. Exponential distribution is defined on the interval of [0, ∞) and is given by (3.14) Where λ > 0 is the parameter of the distribution and it was calculated as λ = 2.71 here for TS data. Moreover, it was recognized that M set is faithfully described by a lognormal distribution (Eq3.15) with mean 3.753 and standard error 3.344 66 . (3.15) is the shape parameter and k is the scale parameter of the distribution. Where These two obtained marginal distributions were applied to create the bivariate Copula function in the following sections. Table 3.2 Maximum likelihood estimation (MLE) of the examined distribution parameters Variable Exponential Extreme value Gamma Generalized Pareto Rayleigh k = 0.44 µ = 24.01 TS a = 0.48 λ = 2.71 σ = 0.87 σ = 91.39 b = 5.60 ϴ Variable a = 16.09 =0 Weibull Extreme value Gamma Lognormal a = 66.23 µ = 69.98 a = 9.36 µ = 4.04 Rayleigh a = 44.28 M b =3.15 σ = 26.38 b = 6.38 67 σ = 0.36 3.4.4 Model selection and parameter estimation In order to model the dependence between the ― TS‖ and ― M‖ sets and to have a variety of choices from different families of Copula, fourteen Copula functions were considered at first. These Copula functions can be classified into four broad categories: a) Archimedean family including Frank, Clayton, Ali-Mikhail-Haq and Gumbel–Hougaard functions (Nelsen, 1986; Genest 1986) and also the BB1–BB3 and BB6–BB7 classes (Joe, 1997); b) Elliptical Copulas mainly including normal, student, Cauchy and t-Copula functions (Fang et al., 2002); c) Extreme-value Copulas, including BB5, Hüsler-Reiss and Galambos families (Galambos, 1975; Hüsler and Reiss 1989); d) Farlie–Gumbel– Morgenstern family as a miscellaneous class of Copula (Genest and Favre, 2007). These (a) (b) Figure 3.8 Marginal distribution fitting to: a) transformed location index, b) magnitude index 68 mentioned Copula functions were used to model the dependence between ― TS‖ and ― M‖ sets mostly using ― R‖ which is a free software environment for statistical computing (R Development Core Team 2007); and also MATLAB, that is a numerical programming language (MathWorks Inc.). To sieve through the applied Copula models, an informal graphical test was performed as follows (Genest and Favre 2007). The margins of the 10,000 random pairs ( , ) from each of the 14 estimated Copula models were transformed back into the original units using the already defined marginal distributions of Exponential and Lognormal Table 3.3 AIC values of the examined probability distributions Distribution TS Distribution M Exponential 11.187 Weibull 10.302 Extreme value 16.545 Gamma 14.501 Gamma 10. 647 12.091 Lognormal 10.225 11.633 Rayleigh 11.092 Generalized Pareto Rayleigh Extreme value 69 13.800 Table 3.4 Kolmogorov–Smirnov (KS) test for the data after Box–Cox transformation Goodness-of-fit statistics TS M P-value 0.82 0.92 KS statistics 0.07 0.06 models. Then the scatter plots of resulting pairs =( ( ), ( )) were created, along with the actual observations for all families of Copulas. This graphical check made it possible to generally judge the competency of the models and to select the best contenders along with the actual observations. Therefore, six best Copula model were selected (Fig3.9). The next step was to estimate the parameters of all six selected models. This estimation was done based on maximum pseudo-likelihood. Pseudo-likelihood is a function of the data and parameters, which has properties similar to those of a likelihood function. Pseudo-likelihood is primarily used to estimate the parameters in a statistical model when the maximization of the likelihood function will be complicated (Arnold and Strauss 1991). In order to do that, an estimating equation which is related to the logarithm of the likelihood function is set to zero and maximized (Lindsay 1988). The obtained parameter values of each Copula model using maximum pseudo-likelihood with 95% confidence intervals are given in Table 3.5. 70 3.4.5 Goodness-of-fit testing Now the question is that which of the six models should be used to obtain the joint distribution function of variables. As the second attempt towards our model selection, the generalized K-plot of each six Copulas was obtained and compared to each other. The generalized K-plot indicates whether the quantiles of nonparametrically estimated is in agreement with parametrically estimated for each function. is basically defined as the equation below (Genest and Rivest, 1993). (3.16) Where is derivative of with respect to z; and z is the specific value of Z = Z(x, y) as an intermediate random variable function. If the plot is along with a straight line (at a 45° angle and passing through the origin) then the generating function is satisfactory. Figure 3.10 depicts the K-plot constructed for all of the six Copula functions. Considering the K-plots and the graphical check (Fig3.10 and Fig3.11), it is clear that Gumbel-Hougaard distribution (Eq3.17) is the best fit to the data and should be used for the rest of the analysis. 71 (a) (b) (c) (d) (e) (f) Figure 3.9 Simulated random sample of size 10,000 from 14 chosen families of Copulas; a) AliMikhail-Haq, b) Frank, c) Galambos, d) Gumbel-Hougard, e) BB2, f) BB3 : upon transformation 72 of the marginal distributions as per the selected models (whose pairs of ranks are indicated by ―whit e‖ points) along with the actual observations. Table 3.5 Parameter estimation and confidence interval of the Copulas Copula Estimate (ϴ) 95% confidence interval (CI) Ali-Mikhail-Haq ϴ = 1.465 CI = [1.324 1.606] Frank ϴ = 0.384 CI = [0.249 0.518] Galambos ϴ = 3.037 CI = [2.270 3.805] Gumbel-Hougard ϴ = 2.126 CI = [0.670 1.801] BB2 ϴ 0.174, ϴ = 1.638 CI = [0.255 2.801] [0.260 3.316] BB3 ϴ 1.424, ϴ = 1.053 CI = [1.512 1.404] 1.903] [0.134 3.4.6 Copula-based conditional probability density function The presented analysis so far shows that Gumbel-Hougaard distribution is the best fitted Copula function for modeling the dependence between transformed location indices (ST) and magnitude indices (M) for the selected landslide database of West Seattle area. Since, the concept of landslide hazard assessment in this methodology is ―c onditional‖, the obtained joint distribution also needs to be compatible to this definition. In other 73 74 Figure 3.10 Goodness-of-fit testing by comparison of nonparametric and parametric K(z) for Copula model (3.17) Figure 3.11 Cumulative Gumbel-Hougard joint probability density function of S and M indices; dark points represents the 79 validation points in ―1 -CDF‖ form words, the probability of landslide hazard in this study is expressed as ― the probability of occurrence of a landslide having a magnitude larger than a specified value ( ) under the condition of having a specific spatial index in that location‖; and therefore the obtained Copula function is required to be used in its conditional form. Considering Eq3.5 and Eq3.17, the conditional Gumbel-Hougaard distribution is given by 75 (3.18) By substituting the parameters estimated previously for the Gumel–Hougaard Copula (Table 3.5) into the above equation, the desirable conditional joint distribution is obtained for this analysis (Eq3.19). Since the transformed location indices (ST) was used to build the model, the results of this function was transformed back to the initial location indices. Moreover, this conditional cumulative density function was illustrated as can be seen in Figure 3.11. ( ln )2.126]0.5) (3.19) 3.4.7 Probability of landslide frequency (exceedence probability) In previous sections, the dependence between two landslide hazard components including ― magnitude‖ and ― location‖ was modeled using Copula theory. As explained earlier, the concept of landslide hazard consists of three elements; hence, the third component which is ― frequency‖ needs to be taken into account as well. As the dependence tests suggested earlier, there is no significant correlation between the indices 76 of frequency component and the ones of the other two hazard elements (Fig3.7 b & c). Therefore, the landslide frequency was needed to be applied in form of ― probability distribution values‖ and not numerical indices. In order to do that, the ― mean recurrence interval‖ (µ) of each landslide event was required to be inserted into a temporal probability model as follows. One of the most popular probability models that are used to investigate the occurrence of naturally occurring random point-events in time is Poisson distribution (Guzzetti 2005). Poisson distribution is a discrete model that expresses the probability of a number of events occurring in a fixed period of time if these events occur with a known average rate and independently of the time since the last event (Hu 2008). Poisson distribution has been applied to temporal modeling of different natural phenomena such as floods (e.g. Yevjevich, 1972; Onoz and Bayazit, 2001); volcanoes (e.g. Klein 1982; Connor and Hill 1995; Nathenson 2001) and landslides (e.g. Coe et al. 2000; Guzzetti 2005). Assuming landslides as independent random events in time (Crovelli 2000) Poisson distribution is used for the temporal modeling as below. (3.20) Equation 3.20 expresses the probability of experiencing ― n‖ landslides during time ― t‖; where λ is the average rate of occurrence of landslides as 1/µ, which again µ is the estimated mean recurrence interval between successive landslide events and is calculated 77 as D/N; where N is the total number of events ( and D is the total duration (year) within all N landslides occurred. The special case of Equation 20, i.e. the probability of occurrence of one or more landslides during time ― t‖, is given by (3.21) exceedance probability‖ was applied to determine the Equation 3.21 which is called ― probability of landslide frequency for our landslide database. The process of such analysis was adopted from the work done by Coe et al. (2004). The Seattle area was digitally (in GIS format) overlain with a grid of 25 covering an area of 40,000 25-m cells. Next, a count circle (4 ha) was digitally placed at the center of each cell, and the number of landslides occurring within the circle was counted. Then, ― mean recurrence interval‖ (µ) was calculated by dividing the total database duration (D = 84 years; 1912-1996) over the number of landslides. Next, the ― exceedance probability‖ was obtained for every counting circle using Equation 3.21 and this value was assigned to the corresponding mapping cell (Fig3.12). An example of such calculation for a mapping cell is given below. exceedance probability computation: t = 1, µ = D/N = 84/8 = 10.5 , 0.095 78 = = This means that the annual probability of occurrence of one or more landslides in that mapping cell is about %10. As Coe et al (2004) described, the above method of calculating ― mean recurrence intervals‖ is more accurate than making average of sample recurrence intervals and there are some explanations for that: a) map cells having one landslide event cannot be calculated using mean sample interval method; b) using sample interval would be inaccurate for some slope failures having occurrence date accuracy within plus or minus 1 year; c) sample interval approach is not able to consider the period between the last event and the end of the database. Also it should be mentioned that the 4-ha counting circle was used because it is roughly equivalent in ― area‖ to the largest landslides that have occurred in the region and also 25 25-m cell sizes was chosen because it is approximately equivalent in ― area‖ to an average-sized city lot (Coe et al. 2004). 79 Figure 3.12 Points indicating the landslide locations in part of the study area and a counting circle used for exceedance probability calculation in the mapping cell ―A‖ Finally, we now have all the information to quantitatively determine landslide hazard in the Western Seattle area. Therefore, three components of landslide hazard need to be combined based on the proposed methodology (Fig3.2). Since the ― frequency‖ element is independent of the other two components, its corresponding obtained values will be multiplied to the Copula function results as below. (3.22) 3.5 Validation and comparison of the results Validation is a necessary part of any model in hazard analysis to prove its capability in forecasting landslides (Chung and Fabbri, 2003; Fell et al. 2008). The best way to check the validity of a model is to employ landslides independent from the one used to obtain it (Jaiswal et al. 2010). As mentioned earlier, we chose 79 landslide events from 1997 to 1999 to be used for validation part. Since the validation process was performed for the already occurred landslides, the incident is certain i.e. the probability of their occurrence is 100%. Therefore, the closer the predicted values of the landslide hazard model (Eq3.22) to 100%, the more valid and reliable it would be. Table 3.6 presents location 80 indices (S), magnitude values and the result of landslide hazard computations for all 79 landslide events. Based on the result, the success rate of the Copula-based model in prediction of landslide hazard is 90% on average. 81 Additionally, a comparison was performed to observe how the dependence modeling of the hazard components in this study can enhance the forecasting accuracy of the landslide hazard in practice. This comparison was conducted for the 79 landslide events and probability of landslide hazard was computed this time under the assumption of independence (Fig3.1). In fact, the probabilities of ― location‖, ― time‖ and ― magnitude‖ of landslide events multiplied to each other to calculate their hazard values. Based on the results, the mean success rate for multiplication-based model is only 63% (Table 3.6). This comparison shows that Copula-based model predicts landslide hazard much more precisely than the traditional method does. 3.6 Landslide hazard map In order to portray the model results conveniently as a landslide hazard map, the study area was first digitally overlain with a grid of 1.83 1.83-m cells. This size of mapping cells was selected because it was compatible with the smallest size of the mapping units in the ― FS‖ and ― exceedance probability‖ maps (Fig3.6 b, and Fig3.12). Then, the ― location‖ index (FS) of every mapping cell and an arbitrary ― magnitude‖ value were inserted into Equation 3.22. Lastly, the result was multiplied by the probability of landslide frequency (exceedance probability) of the mapping unit. Figure 3.13 displays the resulting map (in GIS format) for landslide magnitude of M ≥ 10,000 within a time period of 50 years. Each mapping cell expresses the probability of occurrence of one 82 or more landslide larger than 10000 in that location. The arbitrary value of landslide magnitude and time periods was selected only for illustration purpose. 3.7 Discussion Some assumptions made in this chapter are reviewed and discussed as follows. Some points are also made to help the future studies to applying the proposed methodology properly. a) To have valid FS values obtained from susceptibility analysis; the main assumption was that the geological and also topographical features of the study area won‘t change in an expected validity time-frame of the model. In fact, we assumed that landslides will occur in the future under the same conditions and due to the same factors that triggered them in the past. Such an assumption is a recognized hypothesis for all functional statistically-based susceptibility analyses (Carrara et al. 1995; Hutchinson 1995; Aleotti and Chowdhury 1999; Yesilnacar and Tropal 2005; Guzzetti et al. 2005; Ozdemir 2009). Therefore, depending on the selected validity time-frame for another study using this methodology, geology and also topography need to be evaluated first. This evaluation is required to make sure that these features won‘t change significantly during the selected time frame. 83 Figure 3.13 Example of landslide hazard map (10m 10m cell size) for 50 years for landslide magnitudes, M ≥ 10,000 in the study area. The value in each map cell gives the conditional probability of occurrence of one or more landslide within the specific time in that location. b) Considering the FS equation (Eq3.10), it was assumed that groundwater flow is parallel to the ground surface (condition of complete saturation, that is r = 1). Harp et al. (2006) mentioned in his work that changing the saturation value is not going to make any difference in the correlation of the FS values with the actual failures from the data set. Also previous studies show that regional groundwater conditions do not appear to strongly affect the general distribution of Seattle landslides (Schulz et al. 2008). In fact, historical landslides are equally distributed inside and outside of the region potentially influenced by regional groundwater. Therefore, the accuracy of the calculated susceptibility values (FS) by Harp et al. (2006) was not reduced by that assumption. 84 Table 3.6 Landslide hazard probability values obtained from Copula-based and multiplication-based models for 79 failure events Landslide Year S 1 1997 0.93 2 1997 3 M( 1 - Copula Conditional CDF Multiplication 5.39 0.965 0.417 0.46 6.18 0.944 0.579 1997 0.96 4.32 0.954 0.668 4 1997 0.83 1.35 0.890 0.625 5 1997 0.21 2.51 0.912 0.664 6 1997 0.25 3.16 0.951 0.613 7 1997 0.89 4.18 0.923 0.652 8 1997 0.54 1.95 0.972 0.710 9 1997 0.36 5.22 0.890 0.630 10 1997 0.26 2.37 0.949 0.571 11 1997 0.36 7.11 0.845 0.284 12 1997 0.35 2.42 0.761 0.593 13 1997 0.08 3.07 0.804 0.526 14 1997 0.92 1.53 0.954 0.744 15 1997 0.95 2.42 0.791 0.586 16 1997 0.82 3.21 0.981 0.614 17 1997 0.27 1.58 0.989 0.680 18 1997 0.32 2.37 0.868 0.553 number 85 19 1997 0.89 6.32 0.802 0.664 20 1997 0.15 2.32 0.970 0.546 21 1997 0.82 3.08 0.803 0.529 22 1997 0.98 4.31 0.834 0.605 23 1997 0.12 2.53 0.941 0.513 24 1997 0.40 2.44 0.869 0.694 25 1997 0.23 1.49 0.980 0.631 26 1997 0.69 2.24 0.908 0.762 27 1997 0.03 2.41 0.899 0.474 28 1997 0.52 6.60 0.979 0.538 29 1997 0.92 2.46 0.812 0.537 30 1997 0.02 4.88 0.891 0.524 31 1997 0.53 3.16 0.926 0.713 32 1997 0.21 4.97 0.842 0.761 33 1997 0.56 2.18 0.981 0.521 34 1997 0.55 5.02 0.870 0.423 35 1997 0.82 2.55 0.975 0.780 36 1997 0.42 5.34 0.779 0.609 37 1997 0.10 4.78 0.670 0.383 38 1997 0.76 2.32 0.933 0.316 39 1997 0.54 6.64 0.694 0.460 40 1997 0.87 2.18 0.819 0.511 86 41 1997 0.26 3.16 0.838 0.527 42 1997 0.86 3.21 0.925 0.680 43 1997 0.97 5.06 0.891 0.530 44 1997 0.80 3.94 0.728 0.512 45 1997 0.27 5.34 0.951 0.673 46 1997 0.25 6.61 0.983 0.665 47 1997 0.69 3.91 0.882 0.554 48 1997 0.04 0.79 0.814 0.699 49 1997 22.8 2.00 0.922 0.516 50 1997 21.2 4.83 0.839 0.570 51 1997 11.3 6.61 0.840 0.518 52 1997 31.9 0.85 0.905 0.601 53 1997 27.5 1.24 0.881 0.562 54 1997 31.9 2.70 0.903 0.710 55 1997 30.0 2.74 0.878 0.685 56 1997 21.1 4.88 0.897 0.542 57 1997 25.0 5.71 0.876 0.513 58 1997 19.2 4.09 0.794 0.657 59 1997 26.9 4.83 0.990 0.747 60 1997 39.9 1.67 0.917 0.716 61 1997 24.8 2.33 0.767 0.235 62 1997 5.4 3.95 0.980 0.434 87 63 1997 7.6 2.28 0.924 0.520 64 1997 17.3 3.21 0.952 0.548 65 1997 9.0 6.60 0.879 0.756 66 1997 35.7 3.62 0.946 0.634 67 1997 16.2 2.34 0.971 0.601 68 1997 11.7 3.26 0.893 0.548 69 1997 33.0 2.55 0.834 0.622 70 1997 26.1 5.90 0.997 0.539 71 1997 22.6 3.95 0.968 0.623 72 1997 17.1 5.71 0.936 0.768 73 1998 10.8 3.99 0.947 0.526 74 1998 11.8 2.28 0.968 0.432 75 1998 15.6 3.11 0.946 0.533 76 1997 14.6 5.90 0.941 0.719 77 1999 42.6 1.77 0.891 0.980 78 1999 16.3 4.83 0.974 0.713 79 1999 17.6 5.03 0.894 0.529 Furthermore, in the FS equation (Eq3.10) average thickness of 2.4 m was used for ― t” to reflect the average thickness of landslides. This depth was a good estimate because most landslides that occur in Western Seattle area are shallow; and the field observations and 88 measurements showed that the average thickness of shallow failures is 2.4 m (Harp et al. 2006). c) In regard to FS map (Fig3.6 c), the stability of each mapping unit was assumed to be independent from the surrounding mapping cells. The validity of such an assumption was confirmed by testing the low rate of recurrence of events in previous sections. d) Considering the temporal distribution of landslide events in the selected study area (Fig 3.6), we assumed that the ― mean recurrence interval‖ of landslide events will remain the same in the expected validity time of the model in the future. The previous studies in Seattle area indicate that most of the landslides in the region are rainfall-triggered (Baum et al. 2005). It means that if the rate of occurrence of the meteorological events or the intensity-duration of the triggering rainfalls does not change significantly over time, the recurrence interval of landslides will almost remain the same. Therefore, the possible change in the pattern of precipitations needs to be considered before applying this methodology in any other study. 3.8 Summary and conclusions The simplifying assumption of independence among the hazard elements which is commonly used in the literature was addressed and discussed elaborately in this chapter. 89 A new quantitative methodology was presented to assess the landslide hazard in regional scale probabilistically. This approach considers the possible dependence between the components and attempts to forecast the future landslide using a reliable statistical tool named Copula modeling technique. We tested the model in western part of the Seattle, WA area. 357 slope-failure events and their corresponding slope gradient and geology databases were considered to establish and test the model. The mutual correlation between landslide hazard elements were assessed by standard dependence tests; and Copula modeling technique was applied for building the probabilistic hazard function. Based on the results, the mean success rate of Copula model in prediction of landslide hazard is 90% on average, however this mean success rate for traditional multiplicationbased approach is only 63%. The results verify the superiority of the presented methodology over the traditional one. Furthermore, an example of landslide hazard map of the study region was generated using the proposed approach. 90 CHAPTER IV SEISMICALLY-TRIGGERED LANDSLIDE HAZARD ASSESSMENT: A PROBABILISTIC PREDICTIVE MODEL 4.1 Overview Seismically-triggered landslides are one of the most important impacts of moderate and large earthquakes. These landslides usually account for a significant portion of total earthquake loss. Largest earthquakes have the capability to cause thousands of landslides throughout areas of more than 100,000 (Keefer 1984). For instance, on May 2008, a magnitude (Mw) of 7.9 Sichuan earthquake in China had triggered more than 11,000 landslides and these events have threatened 805,000 persons and damaged their properties (Gorum 2008). Other examples include Chi-Chi and Northridge earthquakes which had triggered widespread shallow and deep-seated slope failures and resulted in extensive damage and human loss (Wang et al., 2008). Also failure of a solid-waste landfill or an earth embankment can trigger significant human and financial losses and severe environmental impact (Bray and Travasarou 2007). Therefore, assessment of the 91 potential for earthquake-induced landslides is a very vital and important task associated with earthquake hazard management initiatives. Among different methods for assessment of earthquake-triggered landslides, probabilistic methods offer unique capabilities for the engineers to quantify the uncertainties in the assessment of the performance of susceptible slopes during the seismic loading. Probabilistic seismic landslide displacement analysis takes into consideration the uncertainties of seismic and preparatory parameters (related to topography, geology, and hydrology). The probabilistic approach has been applied in different studies in recent years (e.g., Del Gaudio and et al. 2003; Stewart et al. 2003; Bray and Travasarou 2007; Rathje and Saygili 2008 and 2009). Seismic landslide hazard maps, which are the main result of such studies, have been developed throughout seismically active areas to identify zones where the hazard of earthquake-induced landslides is high. Improvement in creating more precise seismic hazard maps help making decisions regarding infrastructure development, hazard planning in the susceptible areas, and providing the necessary tool for reducing human and financial loss. The main objective of this paper is to propose a probabilistic method for use in construction-planning in earthquake susceptible areas. This presented approach is based on casual relationships between landslides displacement index ( ), preparatory variables and seismic parameters. In this method, the Newmark displacement index, the earthquake intensity, and the associated spatial factors are integrated into a multivariate Copula-based probabilistic function. This model is capable of predicting the sliding 92 displacement index ( ) that exceeds a threshold value for a specific hazard level in a regional scale. The predicted results will be presented as an earthquake-induced landslide hazard map in a regional-scale. 4.2 Literature Review In the past, considerable effort has been devoted to improve earthquake-induced landslide hazard assessment methods using a variety of approaches. Newmark‘s model for modeling earthquake-induced landslide displacements provides the basis to forecast the displacements resulting from seismic loading in a susceptible area. This method models a landslide as a rigid block on an inclined plane and calculates cumulative displacement of the block resulting from the application of an acceleration time record (Newmark 1965). The main assumption is that the sliding boundary has a rigid plastic behavior and that displacement can occur when the sum of driving forces exceeds the resistance (Wang, 2008). In order to conduct the spatial analysis, an infinite slope model is used to analyze regional static slope instability. This model assumes that the slope failure is the result of translational sliding along a single plane of infinite length which is parallel to the ground surface. The first step of the Newmark sliding block model is to obtain the static factor of safety (FS) using the infinite slope model as shown in Figure.1: (4.1) 93 Where c' is the effective cohesion (kPa); ϕ' is the effective angle of friction; α is the slope angle; m is the percentage of the sliding depth below the water table; z is the depth of sliding block ( ); γ is the unit weight of soil (KN/ ); and is the unit weight of water. Also, the following relationship was presented by Newmark (1965) to calculate the critical acceleration in terms of gravity in a case of planar sliding: (4.2) Where g is the gravity acceleration, is critical (yielding) acceleration in g unit, and α' is the thrust angle of the landslide block which can be approximated by the slope angle (in case of shallow landslides, one can assume α'=α). Although some other expressions for have been obtained with different assumptions for ground acceleration, their computed are only slightly different (Saygili and Rathje 2009). 94 Figure 4.1 Infinite slope representation showing the sliding block and the parameters used to define the critical acceleration ( ) To perform the conventional Newmark analysis, selection of a suitable earthquake record and determination of the yielding (critical) acceleration of the selected slopes are required. The conventional Newmark analysis calculates the cumulative displacement of the friction block by double-integrating those parts of the horizontal earthquake timehistory that exceed the critical acceleration (Wilson and Keefer, 1983). The Newmark calculation process can be represented as: (4.3) Where is the Newmark displacement, is the critical acceleration and a(t) is the ground acceleration time history. Such a conventional analysis involves computational complexity and difficulties of selecting an appropriate earthquake time-history (Jibson et al. 1998). To estimate the Newmark displacement ( ) and avoiding such limitations, different approaches have been presented previously as follows. The flow chart in Figure.2 shows the common framework for integrating the critical acceleration and seismic parameters to estimate the Newmark displacements which finally leads to developing an earthquake-induced 95 landslide hazard map. Common approaches that are used in this framework are described as follows. Time-history technique presented by McCrink (2001) is based on a single ground motion acceleration-time history. In this method, an acceleration-time history is selected and used to compute displacement index ( ) for several values of yielding acceleration. The selection of the single acceleration-time history is based on the probabilistic seismic hazard analysis (PSHA). Although some of the existing ground motion uncertainty was considered by the PSHA-derived ground motion information, it has been shown that this method does not consider the fact that different time-histories can produce significantly different levels of displacement index ( ) (Jibson 2007; Bray and Travasarou 2007; Saygili and Rathje 2008). The other approach for seismic-induced hazard assessment is to deterministically use an empirical relationship that relates to as well as other ground motion parameters, such as peak ground motion acceleration (PGA), Arias Intensity ( ) and peak ground velocity (PGV). These deterministic models could be considered as pseudo-probabilistic when the ground motion level is derived from PSHA (Rathje and Saygili 2008). Although these models have been applied in many studies (e.g. Wilson and Keefer 1985; Jibson et al. 1998; Miles and Hoxx 1999; Bray and Travasarou 2007; Rathje and Saygili 2009), they generally do not account for the ground motion uncertainty. Also, as Rathje (2009) described, the standard deviations in such empirical relationships are too large such that 96 the range of predicted for a specific yielding acceleration and ground motion level is usually greater than one order of magnitude. In contrast to the above deterministic or pseudo-probabilistic methods, expressing slope instability within a fully probabilistic framework is theoretically capable of taking all the uncertainty of the ground motions into account. Lin and Whitman (1983) analyzed the probability of failure of sliding blocks using a rigid block modeling technique. They considered the strong ground motion as a Gaussian stationary process and characterized ground motions by several parameters including PGA, central frequency, and root mean square acceleration. As a result, to obtain the annual probability of exceedance from a specified displacement threshold, the seismic hazard for peak ground acceleration needs to be evaluated. Also, Yegian et al. (1991) studied the probability of failure of sliding blocks using the Newmark rigid block concept. In this study, seismic displacements were normalized by the PGA, predominant period, and number of equivalent cycles of loading of the ground motions acquired from 86 earthquake records. They developed a relationship between the normalized seismic displacements and the ratio of yield acceleration over PGA. Finally, since the seismic displacement is conditioned on more than one ground motion parameter, computing the joint hazard of these parameters was required. Another method proposed by Bray et al. (1998) for solid-waste landfills uses seismic slope stability analysis to provide median and standard deviation estimates of maximum horizontal equivalent acceleration and the normalized seismic displacement. As a more recent probabilistic study, Bray and Travasarou (2007) presented a model that 97 can be applied within both fully probabilistic and deterministic frameworks to evaluate seismic-induced slope instability. Earthquake-triggered displacements in this method were computed using 688 seismic records; further yield acceleration, the initial fundamental period of the sliding mass, the earthquake magnitude and the spectral acceleration were used as the model parameters. In addition, Rathje and Saygili (2008, 2009) recently presented two approaches named the scalar and vector probabilistic models using over 2,000 acceleration time histories. The scalar model uses PGA and magnitude to predict sliding displacements, while the vector approach implements PGA and PGV to estimate seismic-induced displacements. Compared to the vector approach that requires vector PSHA analysis or an estimate of the VPSHA distribution, the scalar approach can be implemented using the results from probabilistic seismic hazard assessment (PSHA). Although these probabilistic models were developed using real datasets and advanced techniques, as Kaynia et al (2010) described, there is still more than a magnitude difference in their final prediction results. Also, most of the recent presented probabilistic methods have applied the predictor variables such as peak ground acceleration (PGA) and peak ground velocity (PGV), which only represent the instantaneous maximum values regardless of the earthquake duration (Luco 2002; Rathje and Saygili 2008, 2009). The other main drawback is that, none of these probabilistic models has been validated using comprehensive field observations of seismic-triggered landslide and associated earthquake records (Kaynia et al. 2010). For instance, Rathje and Saygili (2008, 2009) 98 stated that their proposed models required additional future wok to assess accuracy of their method. Moreover, the recent availability of new earthquake records and also more realistic probabilistic techniques require the researchers to updated and advance the existing probabilistic methods. This paper attempts to address the above mentioned shortcomings by presenting a new probabilistic model using a rigorous statistical technique. It is believed that the proposed methodology will present an accurate and advanced method which can be verified by comprehensive field observations. Figure 4.2 Flow chart showing the common required steps for developing earthquake-induced landslide hazard map 99 4.3 Methodology The first step toward modeling the seismic hazard in this study is to apply a suitable empirical relationship between Newmark displacement and selected predictor variables (e.g., peak ground acceleration, Arias Intensity, peak ground velocity). Since Arias intensity ( ) is considered the most relevant ground motion parameter for studies of earthquake-induced landslides (Wang et al. 2011), the presented model in this paper requires as one of the predictor variables. Arias intensity (Arias, 1970) is defined as the sum of all the squared acceleration values from a strong motion record; and it is a measure of the energy dissipated at a site by shaking as below: (4.4) Where a(t) is the acceleration value from the record, is the acceleration due to gravity and is the duration of the shaking, g is in m/s. The use of Arias intensity ( ) rather than PGA was first suggested by Jibson (1993) to characterize the strong shaking. This measure incorporates both amplitude and duration information, making it more capable of representing the shaking intensity of ground motion than other parameters, such as PGA and PGV, which only consider the instantaneous maximum in the shaking intensity. 100 As can be seen in Equation.2, the use of yielding acceleration is affected by the geological, hydrological and geometrical features of a seismic-susceptible location. Hence, the other selected variable for building the hazard model in this paper is yielding acceleration ( . Among a variety of regression equations previously suggested by different authors for various sets of data (Ambraseys and Menu 1988; Yegian et al. 1991; Jibson 1993; Jibson et al. 1998, 2000; Jibson 2007; Bray and Travasaro, 2007; Saygili and Rathje 2008), the regression model suggested by Jibson et al (2007) was selected (Eq.5). This model includes both Arias intensity and yielding acceleration and it was regressed using 875 Newmark displacements extracted from a large data set. This model is fit well enough ( 71%) and has a very high level of statistical significance. As Jibson et al (2007) described, this model has an improvement over the previous ones and it is recommended for regional scale seismic landslide hazard mapping. (4.5) Where Dn is Newmark displacement in centimeters, is Arias intensity in and ac is the critical acceleration in g’s. Applying the regression equation using the yielding accelerations ( motion records ( ) of the study area, we can compute a and ground- value for each mapping unit. The next step would be to calculate the probability of exceedance the computed given a seismic displacement threshold. This exceedance probability is called the seismic 101 hazard and is conditioned on two previously mentioned predictor variables of and (Eq.6). + > (4.6) Assumption: Where is mapping unit subscript, represents the seismic hazard; and represent the yield acceleration and Arias intensity, respectively in each selected mapping unit. Also represent the joint probability of and Newmark displacement exceedance and the predictor variables in a mapping unit. In the equation above, it is assumed that yield acceleration and Arias Intensity represent two random exhaustive events in a given location, which means that they cover the spectrum of all possible events. In fact, we presume that the union of occurrence of critical acceleration and Arias intensity creates the possibility of occurrence of seismic displacement ( ). Such an assumption has been undertaken in many different studies (e.g., Miles and Keefer 2000, 2001; Del Gaudio et al. 2003; Murphy and Mankelow 2004; Haneberg 2006). The flow chart displayed in Figure.3 shows the presented probabilistic methodology in this paper for developing earthquake-triggered landslide hazard map. This flow chart shows how that Factor of safety (FS) obtained from geospatial database results in critical acceleration, which in turn is implemented in an empirical relationship to obtain the Newmark displacement values. These Newmark 102 displacement values are applied in a probabilistic analysis using Copula method to estimate the seismic-induced hazard of the landslides for every mapping unit. To obtain the conditional probabilities of and in our presented model, a multivariate joint probability function is required. In the past, some multivariate joint functions were introduced for different applications; however most of them are restricted by the following main assumptions: a) either the used random variables have the same type of the marginal probability distribution, b) or all the applied variables follow the normal distribution. In practice, the random variables do not follow the same types of probability distributions and they are not necessarily normal, Thus, the mentioned assumptions are not always true (Zhang and Singh 2006). The Copula joint probability functions, which do not require the above mentioned assumptions, offer more flexibility compared to the other joint probability functions. Therefore we will use Copula joint probability function in this paper. In general, Copula is a type of distribution function used to describe the dependence between random variables. In other words, Copulas are functions that connect multivariate probability distributions to their one-dimensional marginal probability distributions (Joe 1997). The Copula concept in dependence modeling goes back to a representation theorem of Sklar (1959) as follows. 103 Figure 4.3 Flow chart showing the presented methodology in this study for developing earthquake-induced landslide hazard map Let‘s assume that we have n variables (or populations) as observations are drawn for each variable as ( and N ; and also are the marginal cumulative distribution functions (CDFs) of the variables Now in order to determine the non-normal multivariate distribution of the variables, denoted as Copula, C, could be used as an associated dependence function. This function returns the joint probability of variables as 104 a function of marginal probabilities of their observations regardless of their dependence structure as below. (4.7) Where if ( ) for i = 1, 2,.. n is the marginal distribution and C: = Copula is continuous (Grimaldi and Serinaldi 2005). Different families of Copulas have been developed in last decades and the comprehensive descriptions of their properties have been compiled by some authors (e.g., Genest and MacKay 1986; Joe 1997; Nelsen 1999). The most popular Copula family is Archimedean Copulas (Yan 2006). 4.4 Application of the Proposed Model 4.4.1 Study area and database To demonstrate the application of the presented methodology, the inventory of 1994 Northridge earthquake occurred in Northern Los Angeles, California was used as a comprehensive ground motion database in this study. Several studies (e.g. Jibson et al. 1998, 2000) applied this earthquake database to perform a detailed regional assessment of seismic-triggered landslides. In fact the features that distinguish this dataset from the other available databases include a) its extensive inventory of occurred slope failures; b) about 200 ground motion records throughout the region; c) detailed geologic map and 105 available engineering properties throughout the area (1:24,000-scale), d) and available high-resolution digital elevation models (DEM) of the topography in the region. All of the mentioned datasets have been digitized at 10-m grid spacing in the ArcGIS platform in the selected quadrangle centered at 34.241° N, -118.592°W in Northridge area (Fig.4). This quadrangle was selected based on greatest landslide concentration and the availability of a significant amount of shear strength data in that region (Jibson et al. 1998). By integrating these data sets in the presented model based on Newmark‘s sliding block concept and Copula modeling technique, the seismic-triggered landslide displacement is estimated in each grid-cell throughout the study area as follows. Figure 4.4 Location of the study area, limit of greatest landslide concentration and Northridge earthquake epicenter (Celebi et al. 1994) 106 To calculate yielding acceleration values for each mapping unit, it was required to use Equation.1 to obtain the factor of safety (FS) first. Factor of safety (FS) values were calculated by inserting available friction angle, cohesion and slope angle data into Equation.1. Topographic and shear strength data for the quadrangle were mainly supplied by Jibson et al. (1998) as follows. Geology: A digital geologic map is essential to assign material properties throughout the area (Fig.5a, b, c). For this purpose, the 1:24,000-scale digital geologic map of the region originally created by Yerkes and Campbell (1993, 1995) was used. By using this map, we assigned representative values of the frictional and cohesive components of shear strength values to each geologic unit. As Jibson et al. (1998) indicated in his work: these shear-strength parameters were initially selected based on compilation of numerous local direct-shear test results and the judgment of experienced engineers in the region. Digital elevation model: Using high-resolution scanning of the original USGS contour plates of the 1:24,000-scale map, a 10-m digital elevation model (DEM) was created. As Jibson et al. (1998) indicated that the10-m scanning resolution was used because too many topographic irregularities are not considered in the more commonly used 30-m elevation models. 107 Figure 4.5 a) Geologic map of the selected study area; (b) cohesion and (c) friction angle as the components of shear strength assigned to the geologic units (Yerkes and Campbell 1993, 1995); (d) Shaded-relief digital elevation model (DEM) of the selected area Topography: The slope map (Fig.5d) was created by using a simple algorithm to the DEM which compares the elevations of adjacent mapping units and calculates the maximum slope. This slope map might underestimate some of the slopes (steeper than 60°) due to not so good representation of the slopes on the original contour map. It should be noted that because almost all of the landslides in the Northridge earthquake occurred 108 in dry conditions, no pore water pressure was considered (m = 0) in Equation.1. Also as Jibson et al. (1998) suggested a typical unit weight of 15.7 kN/m3 and sliding depth of 2.4 m were used for simplicity to be representative of Northridge shallow landslides. Regarding the Arias intensity values, the method applied by Jibson et al. (1998) was adopted. In this method, a ground-shaking grid from the Northridge earthquake was produced. In fact, the average Arias intensity was plotted in a regularly-spaced grid for each of 189 earthquake records using its two existing horizontal components. Then, the kriging algorithm (Krige 1951) was applied to interpolate the intensity values across the grid (Fig.6). Finally, Newmark displacements ( values from the Northridge earthquake were computed for each mapping unit (10-m cell) of the selected quadrangle by using Equation.2 , together with the corresponding grid values of critical acceleration and Arias intensity. The obtained Newmark displacements range from 0 to 2414 cm that represent seismic landslide susceptibility values in the selected region. These computed displacements are used in our probabilistic analysis as follows. 4.4.2 Development of seismic hazard model Dependence assessment 109 Figure 4.6 The contour map of the Arias intensity ( ) generated by the 1994 Northridge earthquake in the selected quadrangle. Each displayed Intensity value is the average of the two horizontal components As the first step toward establishment of the probabilistic model (Eq.6), the dependence between the involving variables has to be assessed. To check the linear association between the pairs of and , Pearson‘s product-moment correlation coefficient was computed as below: (4.8) 110 Where N is the sample size; are sample variance of and are sample means of the variables; and and and . As given in Table.1, the findings verify the significant and positive correlation between and negative correlation between . Such a significant correlation between seismic parameters and Newmark displacement was already confirmed by earlier studies in different landslide-earthquake inventories, including 1994 Northridge, 1995 Kobe, 1999 Duzce and 1999 Kocaeli (Kao and Chen 2000; Rathje 2001; Jibson et al 2007; Hsieh and Lee 2011). It is not difficult to understand that a larger , a parameter representing the surrogate of strength properties of a slope, means that the slope has a higher ability to withstand earthquake, resulting in a smaller Newmark displacement. On the other hand, represents the ground motion intensity of an earthquake, and the same slope will result in a larger Newmark displacement when subjected to a stronger ground motion intensity. These findings were used for building the hazard prediction model and also for creating the regional landslide hazard map as follows. Table 4.1 Rank correlation coefficients of the pairs 111 and Spatial auto correlation test Although, commonly used statistical methods including Copula technique often assume that the measured outcomes are independent of each other, it might be the case that some results exhibit spatial autocorrelation (Knegt et al. 2010). When spatial autocorrelation exists, the relative result of two points is related to their distance; and it violates the main assumption of using uncorrelated random variables. Therefore, it is important to check for autocorrelation before performing the Copula modeling technique. In order to do that, the well-known Moran‘s I autocorrelation index (Moran 1950) was used to calculate the autocorrelation of the mapping units with their adjacent units using the ArcMap software. This index is expressed as below: (4.9) Where N is the total number of units; and is the spatial adjacency between units i and j; are the index values of the units i and j. It should be noted that the Moran index values range from -1 to +1 indicating prefect negative and positive correlations respectively. A zero value indicates a random spatial pattern for the units. To calculate Moran's I, a matrix of inverse distance weights was created. In the matrix, entries for pairs of units that were close together were higher than for pairs of 112 units that were far apart. For simplicity, the latitude and longitude values were considered on a plane rather than on a sphere in this chapter. Then the significance test was performed for Z value (Eq.10). (4.10) Where and are the Expected Value and Standard Deviation in Moran's I respectively. Using the 5% significance level and one-tailed test, calculated were compared with values (the corresponding critical value to 5% significance level is 1.645). As given in Table.2, all the obtained Z values are smaller than the critical value, indicating that spatial autocorrelation is not significant for our data. Therefore, the result of spatial autocorrelation test suggests proceeding with the standard Copula modeling technique. Table 4.2 Calculated Z-values for spatial autocorrelation significance test All the values are compared with = 1.645. 113 Marginal distribution of variables To create the bivariate Copula model, it requires to obtain the best fitted marginal probability distributions for yield acceleration ( displacement ( ), Arias intensity ( ) and Newmark ). Therefore, Akaike information criterion (AIC), developed by Akaike (1974), was used for identifying the appropriate probability distribution as given below. (4.11) Where ― MSE” represents the mean square error of a distribution against its empirical non-exceedance probability function. The empirical probability function used in this study was Gringorten position-plotting formula (Gringorten 1963; Cunnane 1978); and accordingly the best model is the one which has the minimum AIC (Table.3). Considering the AIC values summarized in Table.3, Log-normal distribution is best fit to ( ), ( ) sets, while Gamma is the best model for ( ) set. The parameters of these distributions were estimated by the maximum likelihood method. In addition, the Kolmogorov–Smirnov (KS) test is another goodness-of-fit statistics which uses the maximum absolute difference between the empirical distribution and the 114 hypothesized probability distribution (Yevjevich 1972). This test was used to determine whether the data after applying the Box–Cox transformation (Box and Cox 1964) could be considered as normally distributed. As given in Table.4, the KS test at the 5% significance levels expresses that the Box–Cox transformed data are normally distributed. Model selection and parameter estimation In order to model the dependence between the pairs of and and to have a variety of choices from different families of Copula, fourteen Copula functions were considered from four broad categories: a) Archimedean family including Frank, Clayton, Ali-Mikhail-Haq and Gumbel–Hougaard functions (Nelsen 1986; Genest 1986) and also the BB1–BB3 and BB6–BB7 classes (Joe 1997); b) Elliptical Copulas mainly including normal, student, Cauchy and t-Copula functions (Fang et al. 2002); c) Extremevalue Copulas, including BB5, Hüsler-Reiss and Galambos families (Galambos 1975; Hüsler and Reiss 1989); d) Farlie–Gumbel-Morgenstern family as a miscellaneous class of Copula (Genest and Favre 2007). To sieve through the available Copula models, an informal graphical test (Genest and Favre 2007; Reddy and Ganguli 2012) was performed as follows. The margins of the 10,000 random pairs ( , ) from each of the fourteen estimated Copula models were transformed back into the original units using the already defined marginal distributions of Log-normal and Gamma functions. Then the scatter plots of resulting pairs 115 = ( ( ), ( )) were created, along with the actual observations for all families of Copulas. This graphical check makes it possible to generally judge the competency of the functions and to select the best contenders along with the actual observations. Therefore, three best Copula model were selected for each pair (Table 5). The next step was to estimate the parameters of the three selected models for each pair. This estimation was carried out over a random sample of bivariate observations for the selected Copula models. Table 4.3 Performance of marginal distributions for random variables and selected density functions The bold values are the statistical models with the best estimate for the variables. Table 4.4 Kolmogorov–Smirnov (KS) test for the data after Box–Cox transformation 116 P-value is the probability of the maximum KS statistic being greater than or equal to the critical value (0.05). This estimation is based on the procedure described by Genest and Rivest (1993) as follows: a) Obtain the Kendalls‘τ from observations using equation below, (4.12) Where N = number of observations; sign = 1 if < 0, i, j = 1, 2 … N; and b) Determine the Copula parameter > 0, sign = -1 if = estimate of τ from the observations; from the above value of τ for each Copula function. As can be seen in Table.5, there are closed-form relations between for the used Copula families in this paper. In each relation, and and τ denote a specific value of the marginal cumulative distribution functions (CDFs) of the variables. The obtained parameter values of each Copula model ( ) and values of Kendall‘s are given in Table.5. These values are used for further examination, narrowing down the results and building the final hazard model as follows. Goodness-of-fit testing 117 Now we would like to determine which of the three models should be used for each pair of to obtain their final joint distribution function. As the and second step towards our model selection, AIC criterion (Eq.8) was applied. The values of AIC were computed (Table 6) and the results show that Frank and Cook-Johnson Copula models have the smallest AIC value for the correlated pair of respectively. and Moreover, the generalized K-plot of each four Copulas was obtained and compared to each other. The generalized K-plot indicates whether the quantiles of non-parametrically estimated is in agreement with parametrically estimated (Genest and Rivest 1993). for each function is basically defined as the equation below: (4.13) Where is derivative of with respect to z; and z is the specific value of Z = Z(x, y) as an intermediate random variable function. If the plot is along with a straight line (at a 45° angle and passing through the origin) then the generating function is satisfactory. Figure.7 depicts the K-plot constructed for all of the six Copula functions. The result of K-plots is in agreement with the obtained AIC values that Frank and CookJohnson Copula models are the best-fitted functions. It should be noted that the Copula model in the form of cumulative distribution functions produces the probability of nonexceeding values ( . However, the desired joint function should be able to predict the exceedance Newmark displacement as it was discussed earlier (Eq.6). Hence, the (1118 CDF) forms of the selected Copulas were used to build the seismic-triggered landslide hazard model as below: Table 4.5 Parameter estimation and Kendall‘s of the Copulas The reasom for ‗NA‘ is that Ali–Mikail–Haq Copula can only be used to simulate the correlated random variables within Kendall‘s belongs to roughly [-0.2, 0.3] Table 4.6 The AIC values of different Copulas functions The reason for ‗NA‘ is that Ali–Mikail–Haq Copula can only be used to simulate the correlated random variables within Kendall‘s belongs to roughly [-0.2, 0.3]. 119 Figure 4.7 Goodness-of-fit testing by comparison of nonparametric and parametric K(z) for Copula models 120 (4.14) Where and are the selected marginal distributions of critical acceleration, Newmark displacement and Arias intensity respectively, as described earlier in Table.3. 4.5 Seismic landslide hazard map Using the obtained predicting model, the seismic hazard map of the study area was created in 10-m grid spacing in the ArcGIS platform (Fig 4.8). This size of mapping cells was selected because it was compatible with the size of the mapping units in the applied geology and topography maps. The obtained map represents the hazard level of 10% ) for the study area. The obtained probability of exceedance in 50 years ( map indicates that the most significant hazard (having the largest displacements) is associated with the steeper slopes in the northern and southeast areas of the quadrangle. 4.6 Validation Newmark displacements do not necessarily represent the measurable slope movements in the field; rather, these estimated displacements provide an index related to the field 121 performance. In order to validate the Newmark-based predictive models, calculated displacements need to be correlated with a quantitative indicator in the field; such as landslide displacement area (Jibson et al. 1998). Therefore, in this chapter the previous landslides occurred in the study area were used (USGS, open report 1995) to examine their relevancy to the obtained Newmark displacements. Figure 4.8 Seismic landslide hazard maps (10m×10m cell size) indicating the displacements and b) levels in mapping units for a) in the study area. The areal percentage of seismic-triggered slope movements in every mapping cell was digitally measured and plotted versus its corresponding Newmark displacement value using a Q-Q plot (Fig.9). Generally speaking, the points in the Q-Q plot will approximately lie on a straight line when the datasets are linearly related (Wilk and 122 Gnanadesikan 1968). As can be seen in Figure.9, the extremely good correlation ( shows how well the model results are related to the real landslide inventory data in the field. This consistency proves the capability of the predictive model in seismicinduced landslide hazard assessment. 4.7 Summary and conclusion Seismic landslide hazard maps are important in development and zoning decisions, and provide a very useful tool for detailed studies of seismic-triggered landslides in susceptible areas. In the last decade, considerable efforts have been devoted to improve these hazard mapping techniques using a variety of different approaches. The current procedures used to develop seismic landslide hazard maps have one major limitation in that they mostly ignore the uncertainty in the prediction of sliding displacement. Also, almost none of the existing probabilistic models have been validated using comprehensive field observations of seismic-triggered landslide and associated earthquake records (Kaynia et al. 2010). In this chapter, a new probabilistic method was proposed in which the Newmark displacement index, the earthquake intensity, and the associated spatial variables are integrated into one multivariate conditional probabilistic function. This model is built based on a powerful statistical approach: Copula modeling technique. 123 Figure 4.9 Validation of the predicting model using the Q-Q plots of landslide areal percentages versus Newmark displacements The presented approach was applied to a quadrangle in Northridge area in Northern California having a large landslide database. The predictive hazard model was applied to the study area and it was tested using standard goodness-of-fit procedures. Also, to compare the model results with the field performance, areal extension of the landslide events previously occurred in the region were used. The validation showed that the model results are consistent with the real landslide inventory database. Finally, the presented probabilistic model was used to develop a seismic landslide hazard map for the selected 124 area. The obtained regional hazard map provides the sliding displacement values for the hazard level of 10% probability of exceedance in 50 years ( ). The probabilistic model proposed and demonstrated here represents a rational approach to take the uncertainties of the commonly involved seismic and spatial variables into account for assessing the earthquake-triggered landslide hazards. This methodology can be implemented for similar seismic hazard assessment and mapping purposes in regional-scale studies. The final resulting hazard maps can be updated with any additional seismic and spatial information in the future. 125 CHAPTER VI AN EMPIRICAL-STATISTICAL MODEL FOR DEBRIS-FLOW RUNOUT PREDICTION IN REGIONAL SCALE 5.1 Overview Debris flow which is sometimes referred as mudslide, mudflow or debris avalanche is defined in the literature as a mixture of unsorted substances with low plasticity including everything from clay to cobbles (Varnes 1978; Lin et al. 2006). Debris flows which are a common type of fast-moving landslides are produced by mass wasting processes. They are one of the most frequently occurring natural phenomena that cause a lot of human loss and damage to properties annually all around the world (Hungr et al. 1999; Prochaska et al., 2008). For instance, in 1996 and 2003 destructive debris flows took place in the Faucon catchment, causing significant damage to roads, bridges and property (Hussin 2011). Debris flows also play an important role in channel aggradations, flooding and reservoir siltation and also basin sediment yielding (Bathurst et al., 2003; Burton et al., 1998). Therefore, evaluation of the potential debris flows is a very vital task in landslide risk management and generally it helps to delimit the extension of the hazard and scope of endangered zones. 126 The existing debris-flow runout approaches require estimation of the influencing factors that control the flow travel such as runout distance, depth of deposits, damage corridor width, depth of the moving mass, velocity, peak discharge and volume (Dai et al. 2001). However, accurate estimation of all of these initial parameters which are involved with a lot of uncertainty is very difficult in practice (Prochaska et al. 2008). The main scope of this paper is to present a reliable probabilistic methodology which could be simply based on a single influencing factor. Therefore, such a methodology will be capable of considering the uncertainty of the debris-flow parameter(s) without complexity of the most existing models. This model is used for preliminary estimation of triggered debris-flow runout distance based on the slope gradient of the travel path in regional scale. It is believed that such an approach is valuable, time saving and can be applied to any similar debris-flow hazard evaluation in the future. 5.2 Literature Review Current and past methods in studying runout behavior of a landslide are generally classified into three categories of dynamic methods, physical scale modeling and empirical approaches (Chen and Lee 2000; Hurlimann 2006). Dynamic methods are physically based on momentum or energy conservation of the flow (Rickenmann 2005). These models require two parameters named the flow velocity and the frictional parameter which their exact estimate can be complicated (Cannon and 127 Savage 1988; Kang 1997). The dynamic modeling generally includes simplified analytical method and numerical approach as follows: a) Simplified analytical methods describe the physical behavior of debris flow movement using lumped mass models and assuming the debris mass as a single point (Zahra 2010). Although different studies have been performed in this regard (e.g. Hutchinson 1986; Skempton et al. 1989; Bracegirdle et al. 1991; Takahashi 1991; Hungr 1995; Rickenmann 2005) the lumped mass models are not able to consider the lateral confinement and spreading of the flow and the possible changes in flow depth. Thus, these models should be applied only for comparing very similar downhill paths which have the same geometry and material properties to some extent (Dai et al. 2001); b) the numerical methods mainly include fluid mechanics models and distinct element approaches (Naef et al. 2006). Continuum fluid mechanics models employ the conservation equations of mass, momentum and energy and also a rheological model which describe the dynamic motion and the material behavior of debris fellow respectively (Hurlimann et al. 2008). A lot of studies have been conducted on runout behavior of debris flow using numerical methods (e.g. Hungr 1995; Chen and Lee 2000; Jakob et al. 2000; Hürlimann et al. 2003 and Revellino et al. 2004). Although these models have generally the potential to provide accurate runout estimation results, they are complex and their analysis is costly (Gonzalez et al. 2003; Prochaska et al. 2008). The second group of the runout models is the physical scale modeling which uses field and laboratory experiments to study debris flow mechanics. Debris flow flumes are applied in these models to simulate an actual debris flow runout and also to assess the flow with high-speed photography and videotaping (Iverson 1997). It should be noted 128 that these simulations can be costly to perform and also the geometric scale applied in such models could be uncertain (Hussin 2011). Also as Dai et al. (2001) stated due to the difference in scale and mechanics of the modeled outputs, using these methods to field situations is not always recommended. The third type of approaches is empirical models aimed at providing practical tools for predicting the runout distance and distribution of landslide debris. Empirical methods are one of the most common approaches to estimate the runout distance of debris flows by establishing a relation between effective elements such as slope gradient, morphology and volume rate using multivariate regression analysis (Hurlimann et al. 2008). There are many various studies regarding this topic including Hsü (1975), Corominas, (1996), Legros, (2002), Fannin and Wise (2001), Bathurst et al. (2003) and Crosta et al. (2003). The empirical approaches can be classified into mass-change method and the angle of reach technique as follows: a) The concept of mass-change method is that as the debris flow moves down slope, the initial mass of the landslide changes and that the landslide debris stops when the volume of the moving materials becomes negligible (Cannon 1988). In such a method, stepwise multivariate regression analysis is applied to establish a relationship between the effecting factors (like gradient of the down slope path and vegetation types) and the channel morphology on the volume loss-rate (Hungr et al. 1987; Corominas 1996; VanDine 1996; Lo 2000); b) the other empirical method named the angle of reach which this angle is defined as the angle of the line connecting the head of the failure source to the distal margin of the mobilized debris mass. These approaches usually develop a linear relationship between angle of reach of debris flow and the 129 average slope of the travel path (Prochaska 2008). Regression equations for obtaining the angle of reach were developed by different authors (e.g. Scheidegger, 1973; Corominas 1996; Bathurst et al. 2003, Prochaska et al. 2008). Figure 1 displays the flowchart summarizing all the described runout prediction approaches. Generally speaking, empirical approaches are much more straightforward, common and less time-consuming compared to the other techniques mentioned earlier. These approaches have an advantage over the other techniques that prevent the use of uncertain and variable initial parameters such as volume, velocity, and frictional parameters (Bathurst et al. 1997; Prochaska et al., 2008). The initial information required by these techniques is generally accessible and when the historical landslide database is available, the empirical modeling can be easily developed (Dai et al. 2002). However, a common problem with this kind of methods is that the scatter of the data is too large to allow the reliable application of the results. Therefore, these techniques should be used only for preliminary prediction of the runout travel distance (Dai et al., 2002). Also as Harp et al. (2006) stated, no current empirical method is able to model runout distances except in uniform materials with few irregular particles such as trees and other types of vegetation. Moreover, the debris-flow estimation techniques are generally limited to deterministic perspective. That is, existing methods including dynamic methods, physical scale modeling and empirical approaches mostly ignore the uncertainties involved with the influencing parameters in practice (Archetti and Lamberti, 2003; Lin et al., 2006). Removing these mentioned limitations was the main motivation in this paper to develop a new empirical approach for the estimation of debris-flow runout distances. 130 Figure 5.1 Flowchart showing different current runout models 5.3 Methodology To compute the configuration of debris-flow travel in this study, deposit toe, the runout travel distance, slope height and gradient need to be shown and defined first. In this paper, runout distance (L) is the distance from the debris flow initiation point until the point of complete sedimentation of the flow; and the slope failure height (h) is defined as the approximate elevation difference between the head-scarp and the deposit toe (see Fig 6.2). These simplified geometrical relationships between debris flow parameters would help us to develop our predictive model in the following sections. 131 Figure 5.2 Schematic cross section defining debris flow runout distance (L), and slope gradient ( ) used in debris flow runout prediction In order to assess the hazard due to debris flow events, it is needed to assign a probabilistic perspective to the definition of this flow mobilization. In this paper, this hazard (H) is the probability of the exceedance of the travel distance of the debris materials from a critical distance in a location with a specific slope gradient. This probability is mathematically expressed as below: (5.1) Where represents the critical travel distance; represents the safety margin as is the debris flow travel distance and . The Equation.1 can be further written as 132 (5.2) Where variable; is the standardized normal random represents the reliability function which is the cumulative distribution function of the standardized random variable ; and standard deviation of , respectively. The and are the mean and the can be estimated as below: (5.3) Where is the expectation operator, and respectively. When and are independent, and are the means of and , is given by (5.4) Where and are respectively the variance of and . Since, certain deterministic distance, it‘s only required to estimate and and is set equal to a to calculate using the Equations 3 and 4. On the other hand, the topography of a slope impacts the debris materials mobilization so that the steeper slopes magnify the acceleration of the debris runout of an occurred 133 landslide (Dai et al. 2001; Chen and Lee 2000). Also another study performed by Nicoletti and Valvo (1991) showed that the down slope morphology where debris from rock avalanches mobilized influences significantly the runout distance. Therefore, the slope gradient could be the main influencing factor which is related to the debris flow distance. In other words, the debris travel distance should be related to the slope gradient of the flow path as below: (5.5) Where represents the slope gradient of the debris flow path. Such an empirical relationship could be found separately for the debris flow database of interest. This empirical relationship is applied in the exceedance probability function (Eq.2) and gets calibrated to obtain the final model. The final predictive model would be capable of estimating the probability of exceedance of the debris flow from a specific critical length given a path having a specified slope gradient. The flow chart displayed in Figure.3 shows the presented method in this paper. This flow chart shows how debris flow runout data are integrated into the predictive model to help assessing the debris flow hazard in a study area. 5.4 Application of the Proposed Model 134 5.4.1 Study area and database Bluffs and hillsides in Seattle WA in the Puget Sound area have long been exposed to a significant amount of damage to people and properties due to landslides and debris flows which occur almost every year during the wet season (Thorsen 1989). Figure 5.3 Flow chart showing the presented methodology in this study for debris flow hazard assessment Debris flows is one of the main types of landslides in Seattle area (Baum et al. 2005). These flows which move onto the mid bluff bench or to the base of the slope typically involve colluviums derived from glacial till, silt and outwash sand. They can travel at 135 velocities as high as 60 km/hr which makes them one of the most hazardous types of landslides (Harp et al. 2006, see Fig.4.a). In 1996, the U.S. Geological Survey (USGS) started a program to study natural disasters in the five counties bordering on Puget Sound. Also in 1998, the Federal Emergency Management Agency (FEMA) launched a hazard management program called Project Impact and Seattle was one of the pilot cities in this study. In this regard, Shannon and Wilson, Inc. was assigned to create a digital landslide database from 1890 to the 2000 (Laprade et al. 2000). This comprehensive database was a great opportunity for scientists for further study of landslide and debris flows especially in Seattle area. The debris flow database is available for the slope failures that mostly occurred during two precipitation events on January and March in the winter of 1996/97 (Baum et al. 2000). Slope failures in the database were mostly the debris flows that were plotted on 1:24,000-scale USGS maps from stereo aerial photography acquired in April 1997. Totally 326 debris flows recorded within the corridor of the coastal bluffs along Puget Sound (from north Seattle to Everett), in Washington. This region was selected as the study area in this paper (see Fig.4b). The horizontal runout length and also the elevations of both the head and toe of the slide for each debris flow event were available in the dataset (Baum et al. 2000). The distribution of runout distances from this data set is shown in Figure.5. From 326 records of debris flow 250 records are selected for model development and the remaining records are implemented for validation in this paper. From 250 debris flow events, the minimum length from headscarp to toe is about 11.9 m, the maximum length is around 174.1 m and the mean length is 89.3 m. 136 (a) (b) Figure 5.4 a) Example of debris flow near Woodway, Washington on January 17, 1997 (Harp et al. 2006), b) Selected study area in this paper 137 In this study the slope map created by Jibson (2000) was applied to determine the slope gradient values for each failure event (see Fig.6). This slope map was produced by using an algorithm modified in GIS format to the DEM (1.83-m cell) which compares the elevation of adjacent cells to calculate the steepest slope. To estimate the average gradient of each slope in runout dataset, the mid-elevation from headscarp to toe of each failure events from aerial photos were used (see Fig.2). This selected average reference point which has a physical meaning was localized for the dataset in GIS format. Several different reference points were examined before this one was decided upon. The use of these other reference points was rejected due to subjectivity in identification of their placement, sensitivity in their application, or lack of a physical meaning to their locations. It should be noticed that there was no aerial photos available for some of thefailure events in the dataset. For those cases, based on a method presented by Coe et al. (2004), the approximate point location corresponding to each failure area was considered to estimate the mean slope gradient. 5.4.2 Development of the empirical-statistical model Statistical data As the first step toward establishment of the predictive model in this paper, 250 selected debris flow records were divided into three subsets based on their triggering factors reported by Shannon and Wilson Inc. (2000). This division was done in order to examine the effect of triggering mechanism upon the relationship between runout lengths 138 and mean slope gradients. These three subsets include: subset1) debris flows triggered by natural factors; subset2) debris flows induced by water ground/surface; and subset3) debris flows triggered by cut and/or fill. The statistics of these subsets are summarized in Table.1. Figure5.5 Cumulative frequency plot of runout distances for the 326 debris-flow runout lengths mapped from north Seattle to Everett (Harp et al. 2006) 139 Figure 5.6 Slope gradient map of the study area Table 5.1 Summary of the three debris flow data subsets 140 Dependence assessment The second step toward development of the model is to measure the dependence between debris flow length (L) and slope gradient ( ) data for each data subset. To check the linear association between each category of the pairs , Pearson‘s product- moment correlation coefficient was computed as below: (5.6) Where N is the sample size; are sample variance of and are sample means of the variables; and and and . As given in Table.2, the findings verify the significant and positive correlation between Such significant correlations between geometric parameters of debris flow was already confirmed by earlier studies in different landslidedebris flow inventories, including Swiss Alps debris flows, Canadian Cordillera debris flows and Japan (Kamikamihori valley) debris flows (Schilling and Iverson 1997; Okuda and Suwa 1981; Zimmermann 1996; Rickenmann 1999; Jakob 2000). Our dependence assessment findings are used for building the hazard predictive model and also for creating the regional debris flow hazard map in the following sections. 141 Table 5.2 Rank correlation coefficients of the pairs of the three debris flow data subsets As a result, the three field data subsets were then combined into a single regression equation, which is plotted on Fig.7.b: (5.8) The small intercept of the equation above makes a physical sense, so that debris materials do not flow so long for flat basins with small or negligible angles. Figure 5.7 a) Regressions of L versus α for the three field data subsets, b) the final developed regression model 142 Table 5.3 Summary of the significance tests of the best fit regression equation Predictive model The relationship between debris flows distance (L) and mean slope gradient (α) was established in the previous section (Eq.8). Now it‘s required to apply this linear relationship into the probability exceedance function of the debris flow distance as discussed earlier. Using the calculated statistical data (mean and standard deviation) of the total 250 records, and integrating the final regression equation (Eq.8) with the normal cumulative exceedance probability function (Eq.2), the general form of the predictive model is obtained as below: (5.9) 143 Once calibrated, the equation above can be used to predict the hazard of the debris flow as a function of the mean slope angle in that location and the selected critical debris flow distance. In order to obtain the coefficients of A, B and C in the equation above, the existing 250 debris flow events were used for calibration. The curve fits the data very well, 87.1%, (see Fig.8). Therefore the final predictive model was obtained as below: (5.10) Where ‗erf‘ represents the Gauss error function (Andrews 1997); and represent the mean slope angle of the debris flow travel path, and the corrected critical debris flow distance respectively. 5.5 Debris-flow runout prediction results Using the obtained predicting model, the debris flow hazard map of the study area was created in 10-m grid spacing in the ArcGIS platform (Fig.9). This size of mapping cells was selected because it was compatible with the size of the mapping units in the applied geology map. The obtained map represents the exceedance probability of a potential debris flow from a critical arbitrary length ( 144 ) in each mapping unit with a specific mean slope gradient. This critical value was selected because it‘s very closed the mean of the debris flow distances and could be a good index for comparison. The obtained map indicates that the most significant hazard is associated with the steeper slopes in the northern and coastal regions of the study area. Figure 5.8 Calibration of the predictive model using the debris flow inventory data 145 Figure 5.9 Example of debris flow hazard (exceedance probability) map for critical runout distance of ( = 80m) 5.6 Validation The best way to check the validity of a model is to employ landslides data independent from the one used to develop it (Jaiswal et al. 2010). As mentioned earlier, we chose 76 debris flow events to be used for validation part. Since the validation process was performed for the already occurred debris flow events, the incident is considered as certain, i.e. the probability of their occurrence is 100%. Therefore, the closer the predicted values of the hazard model (Eq.10) to 100%, the more valid and reliable it 146 would be. Based on the results, the prediction rate of the model predictions is 92.2%. This prediction rate is calculated as the average amount of the hazard value of the 76 debris flow events. Additionally, a computation was performed to compute the hazard for 100 random locations throughout the area with zero debris flow record (probability of their occurrence is considered as 0%). The mean prediction rate for this group of data is only 11.7%. 5.7 Summary and conclusion The current debris-flow runout methods require estimation of the initial parameters that control the flow travel such as runout distance, depth of deposits, damage corridor width, depth of the moving mass, velocity, peak discharge and volume (Dai et al. 2002). However, accurate estimation of all of these influencing factors which are involved with a lot of uncertainty is very difficult in practice (Prochaska et al. 2008). The main purpose of this paper was to present a reliable probabilistic method which could be simply based on a single influencing factor. Hence, such a methodology will be capable of taking the uncertainty of the debris-flow parameter(s) into account without complexity of the most existing models. Thus, the proposed model is used for preliminary prediction of debris-flow runout distance based on the slope gradient of the 147 travel path in regional scale. This model is built upon a reliable regression analysis and exceedance probability function. The presented approach was applied to 326 debris flow events in Seattle area, WA. The data was divided into three subcategories and regression analysis was performed on them. The final regression equation was applied into the exceedance probability function; and then it was calibrated using 250 debris flow events to obtain the predictive hazard model. This model was applied to the study area and it was tested by measuring the prediction rate of two groups of debris flow records. The obtained success rates of 92.2% and 11.7% showed that the model results are consistent with the real landslide inventory database very well. Finally, the presented probabilistic model was used to develop a debris flow hazard map for the selected area. The obtained map represents the exceedance probability of a potential debris flow from a critical arbitrary length ( ) in each mapping unit with a specific mean slope gradient. The model proposed and demonstrated here represents a rational approach to take the uncertainties of the commonly involved geometric variables of the debris flow into account; and also presents a preliminary technique to assess the debris flow hazards. It should be mentioned that this method like the other topographic models have the limitation of requiring knowledge of an initiation point for the failure on the slope to obtain the average slope of travel path. However, this methodology can be usefully implemented for similar debris flow assessment and mapping purposes in regional scale 148 studies. The final resulting hazard maps can become updated with any additional related information in the future. CHAPTER VI CONCLUSIONS AND RECOMMENDATIONS 6.1 Summary of Important Research Results In chapter III, the simplifying assumption of independence among the hazard elements, which has been commonly used in the literature, was discussed. A new quantitative methodology was presented to assess the landslide hazard probabilistically in a regional scale. This approach considers the possible dependence between the hazard components and attempts to forecast probabilistically the future landslide using a reliable statistical tool named Copula modeling technique. We tested the model in western part of the Seattle, WA area. A total of 357 slope-failure events and their corresponding slope gradient and geology databases were used to build the model and to test its validity. The mutual correlations between landslide hazard elements were considered; and Copula modeling technique was applied for building the hazard function. Based on the comparison results, the mean success rate of Copula model in prediction of landslide hazard is 90% on average; however, this 149 mean success rate of the traditional multiplication-based approach is only 63% which is due to neglecting the existing dependency between hazard elements. The comparison results validate the advantages of the presented methodology over the traditional one due to explicit considerations of dependence among landslide hazard components. In this chapter, considering the probability of landslide frequency, we assumed that the ― mean recurrence interval‖ of landslide events will remain the same in the expected validity time of the model in the future. The previous studies in Seattle area indicate that most of the landslides in the region are rainfall-triggered (Baum et al. 2005). It means that if the rate of occurrence of the meteorological events or the intensity-duration of the triggering rainfalls does not change significantly over time, the recurrence interval of landslides will almost remain the same. Therefore, the possible change in the pattern of precipitations needs to be considered and checked for a study area before applying this methodology in the future. In chapter IV, a new probabilistic method was proposed in which the Newmark displacement index, the earthquake intensity, and the associated spatial variables are integrated into one multivariate conditional probabilistic function. This model is built based on a powerful statistical approach: Copula modeling technique. The presented approach was applied to a quadrangle in Northridge area in Northern California having a large landslide database. The predictive hazard model was applied to the study area and it was tested using standard goodness-of-fit procedures. Also, to compare the model results with the field performance, areal extension of the landslide events previously occurred in the region were used. The validation showed that the model results are consistent with the real landslide 150 inventory database. Finally, the presented probabilistic model was used to develop a seismic landslide hazard map for the selected area. The obtained regional hazard map provides the sliding displacement values for the hazard level of 10% probability of exceedance in 50 years ( ). The probabilistic model proposed and demonstrated in this chapter represents a rational approach to take the uncertainties of the commonly involved seismic and spatial variables into account for assessing the earthquake-triggered landslide hazards. This methodology can be implemented for similar seismic hazard assessment and mapping purposes in regionalscale studies. The final resulting hazard maps can be updated with any additional seismic and spatial information in the future. The main purpose of chapter V was to present a reliable probabilistic method for predicting debris-flow runout distance which could be simply based on a single influencing factor. Hence, such a methodology will be capable of taking the uncertainty of the debrisflow parameter(s) into account without complexity of the most existing models. Thus, the proposed model is used for preliminary prediction of debris-flow runout distance based on the slope gradient of the travel path in regional scale. This model is built upon a reliable regression analysis and exceedance probability function. The presented approach was applied to 326 debris flow events in Seattle area, WA. The data was divided into three subcategories and regression analysis was performed on them. The final regression equation was applied into the exceedance probability function; and then it was calibrated using 250 debris flow events to obtain the predictive hazard model. This model was applied to the study area and it 151 was tested by measuring the prediction rate of two groups of debris flow records. The obtained success rates of 92.2% and 88.3% showed that the model results are consistent with the real landslide inventory database. Finally, the presented probabilistic model was used to develop a debris flow hazard map for the selected area. The obtained map represents the exceedance probability of a potential debris flow from a critical arbitrary length ( ) in each mapping unit with a specific mean slope gradient. The model proposed and demonstrated in chapter V represents a rational approach to take the uncertainties of the commonly involved geometric variables of the debris flow into account; and also presents a preliminary technique to assess the debris flow hazards. 6.2 Recommendations for Future Research Areas for future research are recommended as follows. a) To have valid FS values obtained from susceptibility analysis in chapter III; the main assumption was that the geological and topographical features of the study area won‘t change in an expected validity time-frame of the model. In fact, we assumed that landslides will occur in the future under the same conditions and due to the same factors that triggered them in the past. Such an assumption is a recognized hypothesis for all functional statisticallybased susceptibility analyses (Carrara et al. 1995; Hutchinson 1995; Aleotti and Chowdhury 1999; Yesilnacar and Tropal 2005; Guzzetti et al. 2005; Ozdemir 2009). Therefore, in the future depending on the selected validity time-frame for any study using this methodology, 152 geology and also topography need to be evaluated first. This evaluation is required to make sure that these features won‘t change significantly during the selected time frame. b) The implemented geospatial data in chapter IV helped to estimate the seismic-induced landslide hazard accurately. However, the more influencing data we involve in our analysis, the more precise results can be obtained (Fig.4.3). It is recommended to consider a predictive multivariable model in the future to be able to predict the seismic-triggered landslide hazard even more precisely. c) It should be mentioned that the presented method in chapter V, like the other topographic models has the limitation of requiring knowledge of an initiation point for the failure on the slope to obtain the average slope of travel path. However, this methodology can be usefully implemented for similar debris flow assessment and mapping purposes in regional scale studies. The final resulting hazard maps can be updated with any additional related information in the future. 153 REFERRENCES Akaike H (1974) A new look at the statistical model identification, IEEE Transactions on Automatic Control AC-19 (6), pp. 716–722. Aleotti P, Chowdhury R. (1999) Landslide hazard assessment: summary review and new perspectives. Bulletin of Engineering Geology and the Environment 58, 21– 44. Ardizzone F, Cardinali M, Carrara A, Guzzetti F, Reichenbach, P, (2002) Uncertainty and errors in landslide mapping and landslide hazard assessment. Natural Hazards and Earth System Association, 55, 698–707. Arnold Barry C., Strauss David, Pseudolikelihood Estimation: Some Examples, Sankhyā: The Indian Journal of Statistics, Series B (1960-2002) Vol. 53, No. 2 (Aug., 1991), pp. 233-243. Bacchi B, Becciu G, Kottegoda, N.T. (1994) Bivariate exponential model applied to intensities and durations of extreme rainfall. Journal of Hydrology 155, 225–236. Baum R.L., Coe Jeffery A, Godt, J.W., Harp E.L., Reid Mark E, Savage William Z, Schulz William H, Brien Dianne L, Chleborad Alan F, McKenna Jonathan P. · Michael John A. (2005). Regional landslide-hazard assessment for Seattle,Washington, USA: Landslides 2: 266–279. Baum R.L., Savage W.Z, and Godt J.W, (2002) TRIGRS A Fortran program for transient rainfall infiltration and grid-based regional slope-stability analysis: U.S. Geological Survey Open-File Report 02-0424, 27 p. 2. Bouye Eric, Durrleman, Valdo, Nikeghbali Ashkan, Riboulet, Roncalli GaÄel, Thierry (2000), Copulas for Finance, a Reading Guide and Some Applications, Working paper, Goupe de Recherche Op´erationnelle, Cr´edit Lyonnais. 62–72. (1964) An analysis of transformations, Journal of the Royal Statistical Society, Series B 26 (2): 211–252. Cardinali, M., Carrara, A., Guzzetti, F., Reichenbach, P, (2002) Landslide Hazard Map for The Upper Tiber River Basin. CNR GNDCI Publication Number 2116, Map At 1: 100,000 Scale. Box, George E. P., Cox, D. R. 154 Carrara A, Cardinali, M., Guzzetti, F., Reichenbach, P,(1995) GIS technology in mapping landslide hazard. In: Carrara, A., Guzzetti, F. (Eds.) Geographical Information Systems in Assessing Natural Hazards. Kluwer Academic Publisher, Dordrecht, the Netherlands, pp. 135– 175. Cevik E, Topal, T, (2003) GIS-based landslide susceptibility mapping for a problematic segment of the natural gas pipeline, Hendek (Turkey). Environmental Geology 44(8), 949–962. Chau K.T., Sze Y.L., Fung M.K., Wong W.Y., Fong E.L., Chanm, L.C.P., (2004) Landslide hazard analysis for Hong Kong using landslide inventory and GIS, Computers & Geosciences 30 (2004) 429-443. Cherubini U, Luciano E, Vecchiato W (2004) Copula Methods in Finance. John Wiley & sons. Chung, C.J., Fabbri, A.G., (2005) Systematic procedures of landslide hazard mapping for risk assessment using spatial prediction models. In: Glade, C.J., et al., (Eds.), Landslide Risk Assessment. John Wiley, pp. 139–174. Chung, C.J., Fabbri, A.G., 2003. Validation of spatial prediction models for landslide hazard mapping. Natural Hazards 30 (3), 451–472. Coe J A, Michael JA, Crovelli RA, Savage WZ (2000) Preliminary map showing landslide densities, mean recurrence intervals, and exceedance probabilities as determined from historic records, Seattle, Washington. US Geological Survey Open-File Report 00-303. Coe JA, Michael JA, Crovelli RA, Savage WZ, Laprade WT, NashemWD (2004) Probabilistic assessment of precipitation-triggered landslides using historical records of landslide occurrence, Seattle, Washington. Environ Eng Geosci 10(2):103–122. Coles SG, Tawn JA (1991) Modelling extreme multivariate events. J. R. Statist. Soc. B 53: 377– 392. Connor C.B., Hill, B.E. (1995) Three non-homogeneous Poisson models for the probability of basaltic volcanism: application to the Yucca Mountain region, Nevada. Journal of Geophysical. Crovelli, R.A., 2000. Probability models for estimation of number and costs of landslides. United States Geological Survey Open File Report 00-249. Croxton, F.E., Cowden, D.J., and Klein.S; (1968) Applied general statistics, p 625. Dai, F.C., Lee, C.F., (2002) Landslide characteristics and slope instability modelling using GIS, Lantau Island, Hong Kong. Geomorphology 42, 213– 228. De Michele, C. and Salvadori, G. (2003) A Generalized Pareto intensity-duration model of storm rainfall exploiting 2-Copulas.Journal of Geophysical Research 108(D2): doi: 10.1029/2002JD002534. issn: 0148-0227. 155 Embrechts P, Lindskog F, McNeil A (2003) Modelling Dependence with Copulas and Applications to Risk Management, In S Rachev (ed.), ―Ha ndbook of Heavy Tailed Distribution in Finance,‖ pp. 329– 384. Elsevier. Everitt, B. S. (2002) The Cambridge Dictionary of Statistics, Cambridge: Cambridge University Press, ISBN 0-521-81099-X Failure-time Data (C/R: p73-76) Journal of the American Statistical Association, 95(449). Fang, H.-B., Fang, K.-T., and Kotz, S. (2002) The meta-elliptical distributions with given marginals, J. Multivariate Anal., 82(1), 1–16 corr. J. Multivariate Anal., 94(1), 222–223. Favre, A.-C., El Adlouni, S., Perreault, L., Thiémonge, N., and Bobée, B. (2004) Multivariate hydrological frequency analysis using copulas Water Resour. Res., 40-W01101, 1–12. Fell R, Corominas, J, Bonnard, C, Cascini, L, Leroi, E, Savage, W.Z (2008) Guidelines for Fristedt, Bert; Gray, Lawrence (1996) A modern approach to probability theory. Boston: Birkhäuser. Galambos, J. (1975) Order statistics of samples from multivariate distributions J. Am. Stat. Assoc., 70(3), 674–680. Genest C., and Rivest, L.-P. (1993) Statistical inference procedures for bivariate Archimedean copulas J. Am. Stat. Assoc., 88(3), 1034– 1043. Genest C., Favre, A.C., (2007) Everything You Always Wanted to Know about Copula Modeling but Were Afraid to Ask, Journal of Hydrologic Engineering. Genest C., Mackay, L., (1986) The joy of copulas: Bivariate distributions with uniform marginals, The American Statistician 40 (4), 280–283. Genest, C., and MacKay, R. J. (1986) Copules archimédiennes et familles de lois bidimensionnelles dont les marges sont données, Can. J. Stat., 14(2), 145–159. Grimaldi S, Serinaldi F, Napolitano F, Ubertini L(2005) A 3-copula function application for design hyetograph analysis. In: Proceedings of symposium S2 held during the Seventh IAHS Scientific Assembly at Foz do Iguac¸u, Brazil, April 2005. IAHS Publ 293, 203–11. Gumbel EJ (1960) Bivariate Exponential Distributions, Journal of the American Statistical Guthrie, R.H., Evans, S.G., (2004) Magnitude and frequency of landslides triggered by a storm event, Loughborough Inlet, British Columbia, Natural Hazards and Earth System Science 4, 475– 483. Guzzetti F, Malamud, B.D., Turcotte, D.L., Reichenbach, P. (2002) Power-law correlations Guzzetti F., Carrara, A., Cardinali, M., Reichenbach, P., (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 31, 181–216. Guzzetti F., Reichenbach P., Cardinali M., Galli M., Ardizzone, F, (2005) Probabilistic 156 Haight Frank A. (1967) Handbook of the Poisson distribution. New York: John Wiley & Sons. Hammond, C., Hall, D., Miller, S., and Swetik, P., (1992), Level I stability analysis (LISA) documentation for version 2, General Technical Report INT-285, USDA Forest Service Intermountain Research Station, 121 p. Harp, E.L., Michael, J.A., and Laprade, W.T., (2006), Shallow-Landslide Hazard Map of Seattle, Washington, USGS report. hazard analysis for Hong Kong using landslide inventory and GIS. Computers & Geosciences 30, 429–443. Herr, H.D., Krzysztofowicz, R., (2005) Generic probability distribution of rainfall in space: The bivariate model. Journal of Hydrology 306, 237–264. Hu, Hao (2008) Poisson distribution and application, a Course in Department of Physics and Astronomy,University of Tennessee at Knoxville, Knoxville, Tennessee, USA. Hüsler J, Reiss R.-D. (1989) Maxima of normal random vectors: Between independence and complete dependence Stat. Probab. Lett., 7(4), 283–286. Hungr, O., (1997) Some methods of landslide hazard intensity mapping. In: Cruden, D.M., Fell, R. (Eds.), Landslide Risk Assessment. Balkema Publisher, Rotterdam, pp. 215– 226. Hutchinson, J.N., (1995) Keynote paper: landslide hazard assessment. In: Bell, J.N. (Ed.), Landslides. Balkema, Rotterdam, pp. 1805– 1841. Iverson, R.M., (2000) Landslide triggering by rain infiltration: Water Resources Research, v. 36, no. 7, p. 1897–1910. Jaiswal P., Westen Cees J. van, Jetten V., (2010) Quantitative landslide hazard assessment along a transportation corridor in southern India, Engineering Geology 116 236–250. Jibson, R.W., Harp, E.L., and Michael, J.A., (2000), A method for producing digital probabilistic seismic landslide hazard maps: Engineering Geology, v. 58, pp. 271–289. Joe, H. (1997) Multivariate models and dependence concepts, Chapman and Hall, London. Kendall, M.G., Stuart, A. (1973) The Advanced Theory of Statistics, Volume 2: Inference and Relationship, Griffin. ISBN 0-85264-215-6 (Sections 31.19, 31.21). Klein, F.W., (1982) Patters of historical eruptions at Hawaiian volcanoes, Journal of Volcanology and Geothermal Research 12, 1– 35. Kotz S, Balakrishnan N, Johnson NL (2000) Continuous multivariate distributions. New York: John Wiley. Kubota, T. (1994) A Study Of Fractal Dimension Of Landslides- The Feasibility For Susceptibility Index, Journal Of Japan Landslide Society, 31(3), 9-15. landslide hazard assessment at the basin scale. Geomorphology 72, 272–299. landslide susceptibility, hazard and risk zoning for land use planning. Engineering Geology 102, 85–98. 157 Laprade W.T., Kirkland TE, Nashem WD, Robertson CA, (2000) Seattle landslide study, Shannon &Wilson, Inc Internal Report W-7992-01, p. 164. Lee S, Sambath T (2006) Landslide susceptibility mapping in the Damrei Romel area, Cambodia using frequency ratio and logistic regression models. Environ Geol 50:847–855. Lee, S., (2004) Application of likelihood ratio and logistic regression models to landslide susceptibility mapping using GIS, Environmental Management 34 (2), 223– 232. Lindsay, Bruce G (1988) Composite Likelihood Methods Contemporary Mathematics 80: 221– 239. Long, D., Krzysztofowicz, R. (1992) Farlie–Gumbel–Morgenstern bivariate densities: Are they applicable in hydrology? Stochastic Hydrology and Hydraulics 6 (1), 47–54. Malamud, B.D., Turcotte, D.L., Guzzetti, F., Reichenbach, P. (2004) Landslide inventories and their statistical properties. Earth Surface Processes and Landforms 29 (6), 687– 711. Mandelbrot, Benoît (2004) Fractals and Chaos. Berlin: Springer. ISBN 978-0-387-20158-0, A fractal set is one for which the fractal (Hausdorff-Besicovitch) dimension strictly exceeds the topological dimension". Marques, F.M.S.F; (2008) Magnitude-frequency of sea cliff instabilities, Journal of Natural Hazard and Earth System Sciences 8, 1161–1171. MATLAB 7.9.0(R2009b), Mathworks Inc. 1984. Meneguzzo, David; Walter Vecchiato (2003) Copula sensitivity in collateralized debt obligations and basket default swaps, Journal of Futures Markets 24 (1): pp. 37–70. Methods in Medical Research, 12(4), 333–349. Montgomery, D.R., and Dietrich, W.E., (1994) A physically based model for the topographic control on shallow landsliding: Water Resources Research, v. 30, no. 4, p. 1153–1171. Nagarajan R., Roy A., Vinod Kumar, R., Mukherjee, A. & Khire, M.V. (2000) Landslide hazard susceptibility mapping based on terrain and climatic factors for tropical monsoon regions. Bulletin of Engineering Geology and Environment, 58: 275-287. Nathenson M (2001) Probabilities of volcanic eruptions and application to the recent history of Medicine Lake Volcano. In: Vecchia, A.V. (Ed.), U.S. Geological Survey Open-file Report 2001324, pp. 71– 74. Nelsen, R. B. (1986) Properties of a one-parameter family of bivariate distributions with specified marginals, Commun. Stat: Theory Meth., 15_11_, 3277–3285. Nelsen, R.B., (1999) An Introduction to Copulas, Springer. ISBN 0387986235. of landslide areas in Central Italy. Earth and Planetary Science Letters 195, 169–183. 158 Onken, A; Grünewälder, S; Munk, MH; Obermayer, K (2009) Analyzing Short-Term Noise Dependencies of Spike-Counts in Macaque Prefrontal Cortex Using Copulas and the Flashlight Transformation, PLoS Computational Biology 5 (11): e1000577. Onoz, B., Bayazit, M., (2001) Effect of the occurrence process of the peaks over threshold on the flood estimates. Journal of Hydrology 244, 86–96. Ozdemir Adnan, (2009) Landslide susceptibility mapping of vicinity of Yaka Landslide (Gelendost, Turkey) using conditional probability approach in GIS, Environmental Geology Volume 57, Number 7, 2009, 1675-1686, DOI: 10.1007/s00254-008-1449z. Pack, R. T., Tarboton, D. G., and Goodwin, C. N. (1999) GIS-based landslide susceptibility mapping with SINMAP, in: Proceedings of the 34th Symposium on Engineering Geology and Geotechnical Engineering, edited by: Bay, J. A., Logan, Utah. Pelletier, J.D., Malamud, B.D., Blodgett, T., Turcotte, D.L., (1997) Scale-invariance of soil moisture variability and its implications for the frequency–size distribution of landslides. Engineering Geology 48, 255– 268. R Development Core Team (2007b) Writing R Extensions. R Foundation for Statistical Computing, Vienna, Austria. ISBN 3-900051-07-0, URL http://www.R-project.org/. Remondo Juan, González-Díez Alberto, Ramón Díaz De Terán José And Cendrero Antonio, (2003) Landslide Susceptibility Models Utilising Spatial Data Analysis Techniques. A Case Study from the Lower Deba Valley, Guipúzcoa (Spain) Natural Hazards 30: 267–279, 2003, Research 100, 10107–10125, Research Letters 28 (6), 1091– 1094. Saito Hitoshi, Nakayama Daichi, Matsuyama Hiroshi, (2009) Comparison of landslide susceptibility based on a decision-tree model and actual landslide occurrence: The Akaishi Mountains, Japan Geomorphology 109 (2009) 108–121. Santacana, N., Baeza, B., Corominas, J., De Paz, A., Marturia´, J. (2003) A GIS-based multivariate statistical analysis for shallow landslide susceptibility mapping in La Pobla de Lillet Area (Eastern Pyrenees, Spain). Natural Hazards 30 (3), 281– 295. Savage, W.Z., Godt, J.W., and Baum, R.L., (2004) Modeling time-dependent areal slope stability, in Lacerda, W.A., Ehrlich, M., Fontoura, S.A.B., and Sayão, A.S.F., eds., Landslides—Evaluation and Stabilization: Proceedings of the 9th International Symposium on Landslides, Rio de Janeiro, Brazil, v 1., p. 23–36. Schulz, William H., Lidke David J., Godt, Jonathan W, (2008) Modeling the spatial distribution of landslide-prone colluvium and shallow groundwater on hillslopes of Seattle, WA, Earth Surface Processes and Landforms, Volume 33, Issue 1, pages 123–141.Science 2 (1–2), 3 – 14. Shannon & Wilson, Inc. (2000) Geotechnical Report, Feasibility Study: Evaluation of Works Progress Administration Subsurface Drainage Systems, Seattle, Washington: Internal Report 211- 08831-001, Shannon & Wilson, Seattle, WA, 41 p. 159 Sklar, A. (1959) Fonctions de Repartition a` n Dimensions et Leurs Marges, Publishing Institute of Statistical University of Paris 8, pp. 229–231.Sons. Spearman C., The proof and measurement of association between two things, Amer. J. Psychol., 15 (1904) pp. 72–101. Stark, C.P., Hovius, N., (2001) The characterization of landslide size distributions. Geophysics. Tawn, J. A. (1988) Bivariate extreme value theory: Models and estimation, Biometrika, 75(3), 397–415. Tawn, J.A. (1990), Estimating probabilities of extreme sea levels. Journal of the Royal Statistical Society C (Applied Statistics), Vol. 41, No. 1 (1992), pp. 77-93. Terlien M.T.J., van Asch, T.W.J., van, Westen, C.J., (1995) Deterministic modelling in GIS-based landslide hazard assessment. In: Carrara, A., Guzzetti, F. (Eds.), Geographical Information Systems in Assessing Natural Hazards. Kluwer Academic Publishing, The Netherlands, pp. 57– 77. Thorsen GW (1989) Landslide provinces in Washington. In: Galster RW (ed) Engineering geology in Washington.Washington Division of Geology and Earth Resources Bulletin 78, vol I, pp 71– 89. Troost, K.G., Booth, D.B., Wisher, A.P., and Shimel, S.A., (2005), The geologic map of Seattle, A progress report: U.S. Geological Survey Open-File Report 2005-1252, scale 1:24,000, digital file at 1:12,000. Varnes, D.J., (1984) Landslide Hazard Zonation: A Review of Principles and Practice. Wang W, Wells MT (2000) Model Selection and Semiparametric Inference for Bivariate. Wu,W., Sidle, R.C., (1995) Adistributed slope stability model for steep forested basins.Water Resources Research 31 (8), 2097– 2110. Yan J (2006) Multivariate Modeling with Copulas and Engineering Applications, In H Pham (ed.), Handbook in Engineering Statistics, pp. 973–990. Springer-Verlag. Yang Zon-Yee, Lee Yen-Hung (2006) The Fractal Characteristics of Landslides Induced By Earthquakes And Rainfall In Central Taiwan In Iaeg 2006 Paper Number 48, The Geological Society of London. Yesilnacar, E., Topal, T., (2005) Landslide susceptibility mapping: a comparison of logistic regression and neural networks methods in a medium scale study, Hendek region (Turkey). Engineering Geology 79, 251–266. Yevjevich, V., (1972) Probability and Statistics in Hydrology, Water Resources Publications, Fort Collins, Colorado. 302 pp. 160 Yokoi, Y., Carr, J.R. & Watters, R.J. (1996) Analysis of landslide block development process using its fractal character, Journal of the Japan Society of Engineering Geology 37(1), 29-38. Yue S, Wang CY (2004) A comparison of two bivariate extreme value distributions. Stochastic Environmental Research 18: 61–66. Yue, S (2001) A bivariate extreme value distribution applied to flood frequency analysis, Nord. Hydrol., 32(1), 49–64. Zhang L., Vijay P. Singh, (2006), Bivariate rainfall frequency distributions using Archimedean copulas, Journal of Hydrology. 161