Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
BAYESIAN INFERENCE
“The theory of probabilities is basically only common sense
reduced to a calculus.”
P.S. Laplace
Carlos Mana
Astrofísica y Física de Partículas
CIEMAT
Some references…
… The origins…
(1763)
… to find out a method by which we might judge
concerning the probability that an event has to
happen, in given circumstances, upon supposition that
we know nothing concerning it but that, under the
same circumstances, it has happened a certain
number of times, and failed a certain other number of
times.
Theory of Probability (1st pub. 1939)
Sir Harold Jeffreys
Oxford Classic Texts in Physical Sciences
Bayesian Theory; J.M. Bernardo, A.F.M. Smith
Wiley Series in Probability and Statistics
See also:
Bernardo, J.M. (1979) J. Roy. Stat. Soc. Ser. B 41 113-147
Berger, J.O., Bernardo J.M., Sun D (2009) Ann. Stat.; Vol. 37, No. 2; 905-938
Bernardo J.M., Ramón J.M. (1998) The Statiscian 47, 1-35
Bernardo J.M., “Reference Analysis”, http://www.uv.es/~bernardo/RefAna.pdf
+ many more:
An Introduction to Bayesian Analysis
J.K. Ghosh, M. Delampady, T. Samanta
Springer Texts in Statistics
Bayesian Data Analysis
A. Gelman, J.S. Carlin, H.S. Stern, D.B. Rubin
Chapman & Hall
Bayesian Inference in Statistical Analysis
G.E.P. Box, G.C. Tiao
Wiley Classics Library
Bayesian inference: Scheme
1) Model to describe data:
λ:
2) Full Model:
M { p x | λ ; x X ; λ }
Unknown parameters about which we want to make inferences
from observed data
θ parameter(s) of interest
Usually:
λ {θ , φ}
φ nuisance parameter(s)
p( x, θ , φ) p( x | θ , φ) (θ , φ)
(θ , φ) “Prior density” for the parameters
3) Get distribution of unknown parameters conditioned to observed data:
Bayes Theorem
(Bayes “rule”)
p( x, θ , φ) p( x | θ , φ) (θ , φ) p(θ , φ | x ) p( x )
p( x | θ , φ) (θ , φ)
p(θ , φ | x )
p( x )
supp{ p ( x )}
4) Draw inferences on parameters of interest from “posterior” densities:
(θ , φ) (φ | θ ) (θ )
Integrate on nuisance parameters:
p (θ | x ) (θ )
…if any, for otherwise simpler expression:
p ( x | θ , φ) (φ | θ )
dφ
p( x )
p(θ | x )
… may get conditional densities if needed: p(θ | φ, x )
p( x | θ ) (θ )
p( x )
p( x | θ ) (θ | φ)
p( x | θ) (θ | φ)dθ
Normalisation:
p( x )
p( x, θ, φ)dθdφ p( x | θ, φ) (θ, φ)dθdφ
and usually, domain does not depend on parameters so
p(θ | x) ~ (θ ) p( x | θ, φ) (φ | θ )dφ
p(θ | x ) ~ p( x | θ ) (θ )
5) Bayesian approach allows, eventually, to make “predictive inferences”
(… model checking)
Within same model
M X { p x | θ ; x X ; θ }
predict new data yet to come
p( x ' , x, θ ) p( x ' , x | θ ) (θ ) p( x ' | θ ) p( x | θ ) (θ )
x, x '
p( x '| x )
sampling independent
p( x | θ ) (θ )
p( x ' , x, θ )
dθ p( x ' | θ )
dθ
p( x )
p( x )
p( x ' | θ ) p(θ | x )dθ
info on x ' θ
x info on θ
x, x ' related through θ
Bayesian inference: Elements
p(θ | x )
p( x | θ ) p(θ )
p( x | θ ) p(θ )
p( x )
Likelihood: How data modifies our knowledge on the parameters
Experiment affect knowledge on parameters only through likelihood
(thus, same likelihoods same inferences)
Defined up to a multiplicative constant
Prior: Knowledge (“degree of credibility”) about parameters before data is taken
Informative: Include Prior knowledge (in particular, if trustable info from previous experiments)
Non-Informative: Relative ignorance before experiment is done (… independent experiment)
… posterior is dominated by likelihood
posterior
posterior
likelihood
likelihood
prior
prior
Bayesian inference: Structures
θ
One experiment (same conditions)
n
p( xi | ) ( )
p( x, ) p( x | ) ( )
x1
θ1
θj
xj
i 1
xn
θn
Results from isolated experiments ( independent)
n
p ( xi | i ) ( i )
p( x, θ ) p( x | θ ) (θ )
x1 x j
φ
θ1 θ j
i 1
xn
Parameters {1 , 2 ,, n } come from a common
source governed by hyperparameters φ
θn
x1 x j x n
p( x, θ , φ) p( x | θ ) p(θ | φ) (φ)
n
p( xi | i ) p(i | ) ( )
i 1
EXAMPLE:
Acceptance of events after cuts (or efficiency or whatever)
Total number of events
N
Number of events that have been observed to pass the cuts n
N n
pn | N , (1 ) N n
n
Model:
(B: OK… “a” model)
Frequentist / Classical Solution:
“Estimator” of θ:
(maximizing the likelihood)
θ* is a random quantity with:
…e(k>>)…
Confidence Level Interval:
n
N
E[n]
N
[n]
[ ]
N
(B: How
Why)
E[ ]
n(1 n / n)
N
[ c1 (n, N ), c2 (n, N )]
(B: So what?)
(B: [n] ?)
(B: did you e(k)?)
(B: inferences(e(k)) ?)
(B: if n=0, n=N?)
(B: What does it mean?)
(B: Does it contain
true?)
Bayes Solution:
p | n, N [ n (1 ) N n ] ( )
Bayes “rule”:
(F: θ is a fixed (albeit unknown) number. Can’t talk about probabilities…
B: Probability is…
+ Ramsey, de Finetti, Savage, Lindley, …)
Prior density:
Bayes-Laplace postulate (“Principle of Insufficient Reason”)
If no special reason, all possible outcomes are equally likely
Posterior density: p | n, N n (1 ) N n 1[ 0,1] ( )
Inferences on θ : ~ Be n 1, N n 1
E[ ]
n 1
N 2
N n 1
mode : m
V [ ]
n
N
(n 1)( N n 1)
( N 2) 2 ( N 3)
P[ (1 , 2 )]
2
p | n, N d
1
n
N
n
N
n(1 n / N )
N2
( ) 1[ 0,1] ( )
(F: Inferences depend
on π(θ) ?
(F: Is biased ?
B: So what? n=0,n=N)
EXAMPLE:
p( x | ) 1e x /
Frequentist / Classical Solution:
Maximum likelihood: n
1
n
x
i 1
100 identical experiments
2 n 50
i
e(n) {x1 , x2 ,..., xn }
n / n 1
n e
p ( | , n)
( n)
n
68%CL intervals
c (
1
, n), c2 ( , n)
…random intervals
Absolutely different philosophy:
34 do not contain
2
…you do one sampling (n=50)…
Frequentist: Given the parameters,
how likely is the observed sample?,…
Great but of hardly any interest;…
we are interested in the parameters
Bayesian: Given the data,
draw inferences on the parameters,…
In the Bayesian Solution for the Binomial example, we took a
uniform prior density:
Bayes-Laplace postulate (“Principle of Insufficient Reason”; J. Bernoulli)
If no special reason, all possible outcomes are equally likely
1) Not always reasonable choice
2) Consistency: Non-linear one-to-one transformation
Ex:
e
( )
( )d 1 ( )d ( )d 1 ( ) ( )
1
d
Task: Reasonable and sound criteria to choose a proper prior density:
Several arguments:
1) Invariances
2) Conjugated Priors
3) Probability Matching Priors
4) Reference Priors
5) Hierarchical Structures
6) … more…
(Jeffreys (1939))
(Raiffa+Schlaifer (1961))
(Welch+Peers (1963) … Ghosh, Datta, Mukerjee,…)
(Bernardo (1979), Berger)
Before we start with priors…
two important concepts:
1) Sufficient Statistics
2) Exchangeable sequences
(… make life easier)
(Frequentist / Classical care about unbiased, consistency, asymptotic
efficiency, minimum variance,…)
STATISTICS:
X e(m) x1 , x2 ,..., xm
X X1 , X 2 ,..., X m
xi i
Statistic:
t : x1 ,..., xm 1 m R k ( m)
Sufficient:
Statistics that have all relevant info on parameters of interest
iff
pθ | x1 , x2 ,..., xm pθ | t
m 1 and θ
Sufficient and Minimal:
dim( t ) k (m)
k (m) dim( t ) m
If they exist, we do not have to work with the whole sample
(better if
Example:
k (m) k
independent of m )
M X {N ( x | , ); x R; ( , ) R R }
X e(m) x1 , x2 ,..., xm
iid
m
m
2
t m, xi , xi
i 1
i 1
px1 , x2 ,..., xm | ,
m
2
1 m xi
exp
2 i 1
1
2
pdata | , t1 exp
t
2
t
t
2
1
2 3
2
Except some irregular cases, the only distributions that admit a fixed
number of minimal sufficient statistics
(k (m) k m) belong to the
exponential family
Exponential Family M { p x | θ ; x X ; θ θ }
Belongs to the k-parametric exponential family if:
k
p x | θ f x g θ exp cii θ hi x
i 1
g
1
θ
X
“regular” family if
X
k
f x g θ exp cii θ hi x dx
i 1
does not depend on
θ
… more than what you think …
… and less than what we would like…
k
p x | θ f x g θ exp cii θ hi x
i 1
Few examples:
e n
e ( n ln )
X ~ Pon |
(n 1)
(n 1)
N n
N
N n
X ~ Bi n | N , (1 )
exp n ln ( N n) ln( 1 )
n
n
ab
X ~ Gax | a, b
exp{ ax (b 1) ln x}
(b)
…
1
2
X ~ Cax | ,
exp
ln
1
(
x
)
1 ( x )2
3
X ~ px | a (1 x 2 ) ax
8
x [1,1]
X ~ px | a ap1 x (1 a) p2 x
No Sufficient and Minimal Statistics work with the whole sample
2) EXCHANGEABLE SEQUENCES:
X e(m) x1 , x2 ,..., xm
X ~ px|θ
The sequence
x1 , x2 ,..., xm
p( x1 , x2 ,..., xm | )
is exchangeable if the joint density
is invariant under any permutation of indices
Symmetry in observations so order
in which are taken is irrelevant
Any sequence x1 , x2 ,..., xm
with X X 1 , X 2 ,..., X m conditionally
independent and identically distributed (iid) , is exchangeable
Converse not true: exchangeable sequences are identically distributed but
not necessarily independent
X e(m) x1 , x2 ,..., xm
iid
m
p( x1 , x2 ,..., xm | ) p( xi | )
i 1
m
log p( x1 , x2 ,..., xm | ) log p( xi | )
i 1
Now …PRIORS
M { p x | θ ; x X ; θ θ }
Model:
p( | data) p(data | ) ( )
Posterior:
Prior ~
Knowledge (“degree of credibility”) about parameters
before data is taken
What “prior” info do we have on parameters of interest?
Informative:
Include Prior knowledge (for instance, if trustable info from previous experiments)
Non-Informative:
Relative ignorance before experiment is done (or independent analysis,…)
“~Non-Informative” …
reference priors
1) “Used as standard” such that posterior is dominated by likelihood
2) “Non-Informative”….One is never in a state of complete ignorance
“knowing little a priori”… is relative to info provided by experiment
3) Usually are improper densities:
… do not quantify prior knowledge on parameters in a pdf …
(sequence of compact coverings, admissible models, …)
… do we really need a proper prior?...
Task: Specify a prior which provides little info relative to what is
expected to be provided by experiment
General advise: Prior will have some (hopefully small) effect on inferences so
try with several reasonable priors …
Priors derived from
INVARIANCE ARGUMENTS
INVARIANCE: Position and scale parameters
Position parameter: X ~ px|θ f x θ
θ
New r.q.:
p( x, θ )dxdθ px|θ θ dxdθ f x θ θ dxdθ
J ; 1 p( y, θ)dydθ f y θ θ adydθ
Reparametrization: a ;
Model:
p( y, θ )dydθ f y a θ θ dydθ
Y X a ; J (Y ; X ) 1
f x θ
X e(m) x1 , x2 ,..., xm
iid
formally analogous to
Model:
f y θ
Prior knowledge on
Y e(m) y1 , y2 ,..., ym
iid
same as on
(θ ) θ a; a R
inferences on
inferences on
'
'
(θ ) c1 (θ )
Scale parameter:
1 x
X ~ px|θ f
θ
θ
1 x
p( x, θ )dxdθ px|θ θ dxdθ f
θ dxdθ
θ
θ
θ
New r.q.:
Y aX ; J (Y ; X ) 1
Reparametrization:
' a ; J ' ; 1 a
Model:
X e(m) x1 , x2 ,..., xm
1 y
f
θ θ
Prior knowledge on
1 y
p( y, θ )dydθ f
θ dydθ
aθ
aθ
1 y 1 θ
p( y, θ )dydθ f
dydθ
a
θ θ a
iid
1 x
f
θ
θ
formally analogous to
Model:
a
Y e(m) y1 , y2 ,..., ym
inferences on
inferences on
'
iid
same as on
1 θ
θ ; a R /{0}
a a
(θ ) 1θ 1 (θ )
For Location and Scale parameters:
( , θ ) ( ) (θ ) 1θ 1 (θ )1 ( )
(considered independent)
… Many important models with LOCATION AND SCALE parameters:
Example:
X ~ Exx|θ
xθ
p( x | θ ) θe 1[0,) ( x)
X e(m) x1 , x2 ,..., xm
iid
n
Given n,
n θ ( x1 x2 xn )
p( x1 , x2 ,..., xn | θ ) θ e
t xi is sufficient statistic
i 1
1 is scale parameter
unknown parameter of interest
θ n n 1 θt
p(t | θ , n)
t e
( n)
( 1 ) 1 1
p(θ | t , n) p(t | θ , n) (θ )
t n n1 θt
p(θ | t , n)
θ e
( n)
… consistency:
Model:
ln
z ln t
ln
Position parameter
( ) 1
p ( z | , n)
~ Ga(θ | t , n)
1
exp n( z ) e z
( n)
( ) c ( ) 1
Example:
1
X ~ Unx|0, θ 1( 0, ) x
θ
X e(m) x1 , x2 ,..., xm
iid
Sufficient statistic
unknown parameter of interest
p ( x1 , x2 ,..., xm | )
t max x1 , x2 ,..., xn
1
m
1( 0, ) max xi
t
p (t | n, θ ) n
θ
n 1
1
1( 0,θ ) (t )
θ
( ) 1
Scale parameter
tn
p(θ | n, t ) n n 1 1( t , ) (θ )
θ
p(θ | t , n) p(t | θ , n) (θ )
(by the way, Frequentists and bias:
X 0, θ
θ
freq
ML
t
and
~ Pa(θ | n, t )
n
n
E[θ ]
t t t / n)
n 1
Problem:
X ~ N x|,
iid
e(n) x {x1 , x2 ,..., xn }
1 n
1 n
2
1) Show that n; x xi ; s ( xi x ) 2 is a set of sufficient statistics
n i 1
n i 1
2) Being { , } location and scale parameters, take
(improper) prior and show that
x
T n 1
~ St (t | n 1)
s
inferences on
( , ) 1
as
s2 2
Z n 2 ~ χ ( z | n 1)
inferences on
E[T ] 0 (n 2)
E[Z ] n 1 (n 1)
V [T ] (n 1)(n 3) 1 (n 3)
V [Z ] 2(n 1) (n 1)
…
…
Problem: Comparison of means and variances
Let X1 ~ N x|1 , 1 and X 2 ~ N x|2 , 2 be independent r.q.
Consider the samplings x1 {x11, x12 ,..., x1n } (iid ) x2 {x21, x22 ,..., x2 n
and the sufficient statistics n ; x 1
k
k
nk
1
nk
1
x
;
s
ki
k
nk
i 1
2
2
} (iid )
( xki xk )
i 1
k 1, 2
nk
2
1) Show that for the priors (improper)
Comparison of variances: (1 , 1 , 2 , 2 ) 1
1 2
Comparison of means:
H1: same (but unknown) variances:
2
2
n2 (n1 1) 1 / s1
2 2 ~ Sn( z | n2 1, n1 1)
Z
n1 (n2 1) 2 / s2
1 2
(1 2 ) ( x1 x2 )
~ St (t | n1 n2 2)
T
1/ 2
s (1 / n1 1 / n2 )
(1 , 2 , ) 1
n s n2 s2
s 1 1
n1 n2 2
2
H2: unknown and different variances: (1 , 1 , 2 , 2 ) 1
1 2
W 1 2 ~
s
p( w | x1 , x2 ) ~
1
2
( x1 w u )
2 ( n1 1/ 2 )
s
2
2
( x2 u )
2
2 ( n2 1/ 2 )
(Behrens-Fisher problem)
du
INVARIANCES: under a Group of Transformations
X ~ px|θ
Model: M px|θ ; x X ;
Consider a Group of transformations that acts
on the sample space:
x x' gx ; g G; x, x' X
on the parametric space:
' g ; g G; , '
The model M is invariant under G if g G ;
quantity X ' gX is distributed as pgx|gθ px'|θ '
the random
► The action of the group on the sample and parameter space may be different
SCHEME:
1) Identify the group of transformations on sample space (if exists)
This induces the action of the group G on the parameter space under
which the model is invariant
Examples: Translations:
Scaling:
Affine:
Rotations:
x x' gx a x
x x' gx bx
x x' gx a bx
x x ' gx Rx (… matrix Transforms)
Important Case:
Location and Scale Parameters:
Affine group
On sample Space
p( x | , )
G g a ,b : a, b ; a R ; b R
xR
Model Invariant if on
(
,
)
R
R
Parameter Space
Group:
x R g a ,b x R
x
f
1
x x' g a ,b x a bx
( , ) ( , )' g a ,b ( , )
(a b , b )
g c ,d ( g a ,b x) g c ,d (a bx) (a da dbx) g a da,db x
g a,1b (a / b,1 / b)
g I (0,1)
2) Choose a prior density that is invariant under this group so that:
Initial transformations of data will make no difference on inferences
Same Prior Beliefs on original and transformed parameters
(…if we want to incorporate this as part of prior info)
For the action of group G of transformations, there exists an invariant measure
(Haar measure) such that
f ( gx)d ( x) f ( x' )d ( x' )
for any Lebesgue integrable function f (x)
Alfred Harr (1933)
► Unique (up to a multiplicative constant): Von Neuman (1934); Weil and Cartan (1940)
In our case:
x
f ( x)
and the measure we are looking for:
Group acting on the LEFT:
p( | ) 1 ( )
Lebesgue d (θ ) (θ )dθ
p( | g ) ( )d p( | ' ) ( ' )d '
R
RIGHT:
' R
p( | g ) ( )d p( | ' ) ( ' )d '
R
' R
Example: Location and Scale Parameters θ ( , )
p( | g ) ( )d p( | ' ) ( ' )d '
Group acting on the LEFT:
R
' R
d ( ' )
d ( )
p( | g ( , )) ( , )dd p( | ' , ' ) ( ' , ' )d ' d '
R
' R
G g a ,b : a, b ; a R ; b R
Affine group
…on the left:
p( | g ( , )) ( , )dd
R
g a ,b ( , ) ( ' , ' ) (a b , b )
'a '
( , ) g a,1b ( ' , ' )
,
1
J ( ' , ' ; , ) 2
b
b
b
p( | ' , ' ) ( g 1 ( ' , ' )) J ( ' , ' ; , ) d ' d '
' R
R
'a ' 1
( g 1 ( ' , ' )) J ( ' , ' ; , )d ' d '
, 2 d ' d ' ' , 'd ' d '
b b
b
'a ' 1
, 2 d ' d ' ' , 'd ' d '
b b
b
LEFT Haar Invariant Measure
Group acting on the RIGHT:
' , a R
;
' , b R
L ,
1
2
p( | g ) ( )d p( | ' ) ( ' )d '
R
' R
( ' , ' ) ( , ) g a ,b ( a, b)
a '
( , ) ( ' , ' ) g a,1b ' ' ,
b b
1
J ( ' , ' ; , )
b
RIGHT Haar Invariant Measure
R ,
1
►For the Group of affine transformations, LEFT and RIGHT invariant Haar
measures are not the same
L ,
1
2
R ,
1
0) As invariant measures, both are OK.
1) For models with one parameter, prior derived from RIGHT invariant
measure coincides with Jeffreys’ prior (will came in a while)
2) Prior derived from RIGHT invariant measure is
probability matching (will come in a while2)
3) For models with several parameters, prior derived from LEFT Haar
measure coincide with Jeffreys’
(and, as we shall see, gives problems …although is interesting too…)
Common approach:
►Usually there is no invariance (“obvious?”) of the model but…
►If the structure of the model has a group invariance, … RIGHT Haar prior
( X1 , X 2 ) ~ N x1 , x2|0,0,
Problem: Bivariate Normal
p( x | Σ ) (2 ) 1 | |1/ 2 exp 1 / 2 x t 1 x
x t ( x1 , x2 )
12
1 2
2
2
1 2
| | 12 22 (1 2 )
1) Obtain Right and Left Invariant Haar measures under the action of Lower
(Upper) Triangular Matrix Group
Solution:
1) Cholesky decomposition in lower triangular matrices
1
| | 1 2
1
2
2
1 2
t
A
A
2
1
1
1
| 1 | | A |2
New parametrization of the model
1
1
A
2
1 1
1
1 2
0
2
| |
A {A11, A21, A22}
1 t t
p( x | A) (2 ) | A | exp x A Ax
2
1
G {T LT22 ; Tii 0}
T 1 G
TT 1 T 1T 1
2) Group of lower triangular 2x2 matrices
…and the action on the Sample Space
On the Left
x (T (T )
t
) At A(T 1T ) x
T x Tx x'
t
t 1
On the Right
x ((T )
Mx x '
xM
x'
T t ) At A(TT 1 ) x
x T T 1 x x '
M T 1
M T
1
t 1
t
x' x M
t
t
t
1
dx
dx '
|M |
| A|
p( x ' | A) (2 )
exp 1 / 2 x 't ( AM 1 )t ( AM 1 ) x '
|M |
1
► Model is invariant under G if the action on the Parameter Space is:
G : A A' AM 1 A' M A | A || A'|| M |
p( x' | A' ) (2 ) 1 | A' | exp 1 / 2 x't ( A't A' ) x'
p( | gA) ( A)dA p( | A' ) ( A' )dA'
Haar Equation:
p( | A' ) ( A' M ) J ( A' ; A)dA' p( | A' ) ( A' )dA'
( A' M ) J ( A' ; A)dA'11 dA'21 dA'22 ( A' )dA'11 dA'21 dA'22
M G
a 0
M T
b c
J ( A' ; A) a 2c
(aA'11 , aA'21 bA'22 , cA'22 )(a 2c)dA'11 dA'21 dA'22 ( A' )dA'11 dA'21 dA'22
( A'11 , A'21 , A'22 )
M T 1
1 c 0
ac b a
J ( A' ; A)
1
2
A'11 A'22
1
ac 2
A'11 cA'21 bA'22 A'22
1
(
,
,
)( 2 )dA'11 dA'21 dA'22 ( A' )dA'11 dA'21 dA'22
a
ac
c
ac
1
( A'11 , A'21 , A'22 )
2
A'11 A'22
Transform back to parameters of interest:
1
1
A
2
1
1
M T
M T 1
1
1 2
0
2
T x Tx x'
x T T 1 x x '
Upper Triangular:
a b
T
0 c
{ 1 , 2 , }
1
dA11dA21dA22 3 2
d 1d 2 d
2 2
1 2 (1 )
LH ( 1 , 2 , )
1
1 2 (1 2 )3 / 2
J ( 1 , 2 , )
1
RH ( 1 , 2 , ) 2
1 (1 2 )
1
RH ( 1 , 2 , ) 2
2 (1 2 )
LH ( 1 , 2 , ) J ( 1 , 2 , )
INVARIANCE under reparameterisations
(Sir H. Jeffreys; 1950)
Any criteria to specify a prior density (θ ) for θ should give a consistent result
for parameter h(θ ) with h() a single-valued function
d
dθ
θ
(θ )
(θ ) ( (θ ))
θ
(θ )
(θ )dθ ( )d ( (θ ))
dθ
θ
Fisher’s Matrix:
2 log p( x | )
dx
I ij ( ) p( x | )
i j
…obviously if exists:
1) suppx { p ( x | )} does not depend on
2) p( x | ) Ck ( ) (...k 2)
()
(
)
dx
dx
3) well behaved so
X
X
X
X ~ p( x | )
2 log p( x | )
dx ( 0)
I ( ) p( x | )
2
X
and under a transformation (s.v. function)
(θ )
p( x | )dx 1
X
J ( ) I ( )
1
I ( ) I ( )
2
log p( x | )
2 E
X
2
2
(Not unique: other expressions are also invariant against reparametrizations)
1
2
Example: (back to efficiency, acceptance,…)
X ~ Bi k | n,
n k
p X k | n, (1 ) nk
k
2 log p( x | )
n
I ( ) E X
2
(1 )
( )
p | n, k pk | n, ( )
k1
2
1
1
(1 ) 2
~ Be ( | 1 , 1 )
2 2
2
(1 )
~ Be (k 1 2 , n k 1 2)
nk 1
2
proper
By the way… I ( ) I ( )
iid
e(n) x {x1 , x2 ,..., xn }
2
… “Normalization”
n
p( x | ) p( xi | )
w( | ) log p( x | ) log p( xi | )
i 1
Taylor expansion around max likelihood
i
m:
n 1 n 2 ( log p( x | )
2
w( | x ) w( m | x )
(
)
...
m
2
2 n i 1
p( | x ) ~ N | m , 2 nI ( m )
m
LLN
n I ( m )
Transformation (θ )
d
I 1/ 2 ( ) I 1/ 2 ( ) const
d
p( | x) ~ N | 0 , const
such that
“Data translated likelihood”
I 1/ 2 ( )d d
(G.E.P. Box, G.C. Tiao)
EX: Binomial Distribution
I 1/ 2 ( )d
1
2 atan
2
(1 )
1
1
2
d
Posterior density
Example:
e n
P X n |
(n 1)
X ~ Pok |
Example:
0
2 log p( x | ) 1
1
I ( ) E X
( ) 2
2
(improper)
p | n Ga(1, n 1 )
2
(proper)
X ~ Pax | , x0
1
p( x | , x0 )
x0
x0 x
1( x0 , ) ( x)
0
x0
known
2 log p( x | , x0 ) 1
1
(improper)
I ( ) E X
(
)
2
2
( t ln( x) scale parameter)
Posterior density
p( | x, x0 ) ln( x) x
(proper)
Jeffrey’s in n dimensions:
Fisher’s Matrix:
ln p x θ ln p x θ
I ij (θ ) E X
i
j
smooth one-to-one transformation φ φ(θ )
k l
I kl (θ )
i j
… like a covariant tensor
I ij (φ)
Connection: Geometry, Information and Probability
1
Largest difference
…and same Euclidean distance
2
2
1
1
θ n
(If..) The parameter space of a distribution Riemannian Manifold
I ij (θ ) g ij (θ )
metric tensor
2
1
ds
2
g ij ( )d i d j
2
g ik ( ) g kj ( ) ij
Let φ φ(θ ) be a smooth one-to-one transformation such that at
the Fisher’s matrix becomes
φ0
In a neighborhood of
i
dφ det
j
[ Fij (φ0 )] I
Gamma Distribution:
(identity matrix)
(location)
(φ)dφ dφ
, the geometry is Euclidean
1
1/ 2
dθ det[ F (θ )] dθ (θ )dθ
(θ ) det[ F (θ )]
k l
Fij (φ)
Fkl (θ )
i j
EXAMPLE:
φ0 φ(θ0 )
1/ 2
J ( ) I ( ) 2
1
b
a
p( x | a, b) e ax x b 1
1[ 0, ) (x)
(b)
1) Fisher’s matrix elements are:
det[ F ] (b' (b) 1)a 2
Faa
b
a2
Fab
1
a
a, b R
Fbb ' (b)
J (a, b) a 1 b' (b) 1
But (θ ) det[ F (θ )]1/ 2 may not be the best choice…
(as pointed out by Jeffreys)
Example: Normal distribution
F 2
; F 2 2
p ( x | a, b )
; F 0
( x )2
1
exp
2 2
2
known
{}
( ) F1/ 2 c
OK (Jeffreys’ / location)
known
{ }
( ) F 1/ 2 1
OK (Jeffreys’ / scale)
,
unknown
F 0
{ , }
(θ ) det[ F (θ )]1/ 2
assumed independent
| F | 2 4
( , ) 2 (L-Haar)
( , ) ( ) ( ) 1
( , ) a
(R-Haar)
E[ns 2 2 ] n 1
a 1
x
T n 1
~ St (t | n 1)
s
s2 2
Z n 2 ~ χ ( z | n 1) OK
E[Z ] n 1
a2
x
T n
~ St (t | n)
s
s2 2
Z n 2 ~ χ ( z | n)
E[ Z ] n
PRACTICAL SUMMARY
From Invariance arguments:
For ONE parameter Models:
J ( ) I ( )
1
log p( x | )
2 E
X
2
2
(if exists)
LOCATION parameters:
( ) c1 ( )
SCALE parameters:
(θ ) 1θ 1 (θ )
If
Group of Transformations: RH (θ )
LH (θ)
1
2
Priors from
CONJUGATED FAMILY
Conjugated Priors
Make life easier … Simplify calculations (?)
Let S be a class of sampling distributions
Let P be a class of prior distributions for parameter θ
p( x | θ )
p(θ )
The class P is conjugated for S if
for all
p( x | θ ) S
and p(θ ) P
p(θ | x) P
Natural Conjugated:
If P is the class of prior distributions with same functional form as S
Conjugated Prior Distributions are “closed under sampling”
Likelihood functions p( x | θ ) for which there is a conjugated family of
priors are those which belong to the exponential family
n
n
k
n
px1 , x2 ,..., xn | θ f ( xi )g θ exp c j j θ h j xi
i 1
i 1
j 1
k
1 0
p θ | 0 , 1 , 2 ,..., k
g θ exp c j j θ j
K (τ )
j 1
k
K (τ ) g θ exp c j j θ j dθ
j 1
0
General Scheme:
Model
1) Choose a class of priors
M p( x | θ) ; x X ; θ
(θ | φ)
that reflect the structure of the model
(φ)
2) Choose a prior distribution for the “hyperparameters”
3) Posterior density
p(θ, φ | x) p( x | θ ) (θ | φ) (φ)
and marginalise for parameters of interest:
p(θ | x) p( x | θ ) (θ | φ) (φ)dφ
… 2) How do we choose the “hyperprior”
(φ)
?
Option 1):
From marginal density:
p(φ, x ) (φ) p( x | θ ) (θ | φ)dθ (φ) p( x | φ)
p( x | φ) p( x | θ ) (θ | φ)dθ
reference prior
(φ) for model p( x | φ)
(θ ) (θ | φ) (φ)dφ
Option 2): “Empirical method”: assign numeric values to hyperparameters
from p( x | φ)
(for instance MaxLik)
φ , p(θ, φ | x)
No variability (uncertainty) of hyperparameters but may help to guess
Option 3): … Consider “reasonable hyperpriors”
(proper posteriors; may look at Option 2 for indication)
EXAMPLE:
X ~ Pok |
e n
e ( n ln )
pn |
(n 1)
(n 1)
f n
g 1
1
(n 1)
express in the form:
n
k
px1 , x2 ,..., xn | θ f ( xi )g θ exp c j j θ h j xi
i 1
i 1
j 1
n
n
k {1,2}
k 1 c1 1 1 ( ) h1 (n) 1
k 2 c2 1 2 ( ) ln h2 (n) n
k
1 0
pθ | 0 , 1 , 2 ,..., k
g θ exp c j j θ j
K (τ )
j 1
2
1
p , 1 , 2 | n
e (1 1) n 2 1 1 , 2
( 2 )
1 2 1 2 1
p | 1 , 2
e
( 2 )
p | n p , 1 , 2 | ndτ
(n 2 ) 1 2
p 1 , 2 | n p , 1 , 2 | n d
1 , 2 pn | 1 , 2 1 , 2
n 2
0
( 2 ) (1 1 )
pn | 1 , 2
Example: Dirichlet and Generalised Dirichlet
no
Conjugated priors for Multinomial:
p (d | θ ) C i
ni
i 1
1 1 2 1
p(θ | α ) D(α ) 1 2
Θ {1 ,..., n } ~ Di (θ | α)
n n 1
1
n
n
k 0 D(α) ( 0 ) ( k )
0 k
k 1
k 1
n
n 1
k [0, 1]
k 1
n 1 k
k 1
Degenerated Distribution:
E[i ] i
0
k 1
n 1
n 1 i 1
p(θ | α) D(α) i (1 k ) n 1
k 1
i 1
i 0 ij i j
V [ i , j ]
02 ( 0 1)
Control on E or V; not both:
Generalised Dirichlet
EXAMPLE: UNFOLDING a simple distribution
Interest in distribution of X
no
DATA: Y observed quantity in categories
data n1 , n2 ,..., nno nE ni
i 1
MC simulation of detector response and selection
p( y, x) R( y | x, ) pG ( x)
pobs ( y) R( y | x, ) pG ( x)dx
X
p
G
“Migration” (unfolding) Matrix
P(i | j )
j
( x)dx R( y | x, )dy
i
p
G
( x)dx
j
no
MODEL:
Po :
p(d | φ) C i i e nEi
i 1
no
Mn : p(d | φ) C i
Interest in:
θ 1 , 2 ,..., nt
nt no
i 1
n
φ 1 , 2 ,..., no
ni
nt
i P(i | j ) j
j 1
Θ {1 ,..., n } ~ GDi(θ | α, β )
n 1
p(θ | α)
i 1
n 1
0 i 1
k 1
k 0
E[i ]
i
i i
k
k 0
( i i ) i 1
i 1 k
( i )( i )
k 1
i
i
n 1
n 1 k
1
k 1
i
Si
i ij
V [i ] E[i ]
Ti E[i ]
i i 1
i i 1 i 1 ; i 1,2,..., n 2
n1 1 ; i n 1
i 1
Si k ( k k ) 1
k 1
i 1
Ti ( k 1)( k k 1) 1
k 1
PRIOR:
POSTERIOR:
θ ~ (θ | α ) Di (θ | α )
...GDi(θ | α )
p(θ | d , α ) p(d | φ(θ )) (θ | α )
p(θ | d , α ) p(d | φ(θ )) (θ | α ) (α )
(Still more work…
See later “Priors with Partial Information”)
The structure
(θ, φ) (θ | φ) (φ)
…hierarchical structures and “hyperpriors”
Priors for
HIERARCHICAL STRUCTURES
Hierarchical Structures
φ
p (φ)
Parameters {1 2 n } are drawn from
a common “super-population” governed by
“hyperparameters”φ
M p(θ | φ) ; θ ; φ Φ
θj
θn
p(θ | φ)
considers variability of
i
usually, conjugate models simplify life
x1 x j
xn
p( x | θ )
M X p( x | θ) ; x X ; θ
θ1
p ( x, θ , φ) p( x | θ , φ) p (θ , φ)
p( x | θ ) p(θ | φ) p (φ)
Under exchangeability
n
p (1 ,..., n | φ) p ( i | φ)
i 1
Posterior:
p(θ , φ | x ) p( x | θ ) p(θ | φ) p(φ)
n
p( x1 ,..., xn | 1 ,... n ) p( xi | i )
i 1
n
p(φ) p( xi | i ) p( i | φ)
i 1
Parameterisation {θ , φ}
… usually, parameters of interest {θ}
1) What data tell us about φ ?
p( x, φ) p(φ | x ) p( x ) p( x, θ , φ)dθ p( x | θ ) p(θ | φ) p(φ)dθ
p(φ | x ) p( x | φ) p(φ) p(φ) p( x | θ ) p(θ | φ)dθ
(… make sure it is proper…)
2) Inferences on θ
p(θ | x, φ)
MX
M
p ( x | φ)
p(θ , x, φ) p( x | θ ) p(θ | φ)
p( x, φ)
p( x | φ)
p(θ | x, φ) p( x | θ ) p(θ | φ)
… nicely suited for MC sampling:
1) Draw φ
from
p (φ | x )
2) Draw θ
from
p(θ | x, φ)
(usually can be drawn in dependently)
p(θ | x, φ) p( i | xi , φ)
i
3) Interest in Marginal… θ
3.1) p(θ, x) p(θ | x) p( x) p( x, θ, φ)dφ p( x | θ ) p(θ | φ) p(φ)dφ
p(θ | x) p( x | θ ) p(θ | φ) p(φ)dφ
MX
M
3.2) p(θ, x) p(θ | x) p( x) p( x, θ, φ)dφ p(θ | x, φ) p(φ | x) p( x)dφ
p(θ , x, φ)
p( x | θ ) p(θ | φ)
p(φ | x ) p( x )dφ
p(φ | x ) p( x )dφ
p( x, φ)
p( x | φ)
p(θ | x ) p( x | θ ) p(θ | φ)
p (φ | x )
dφ
p( x | φ)
Usually draw inferences on each i
p ( x | i ) p ( i | φ)
p( i | x )
p (φ | x )dφ
p ( x | φ)
4) Predictive distribution p(θ, x, x new ) p( x new | θ, x) p(θ, x) p( x new | θ ) p(θ | x) p( x)
p( x new | x ) p( x new | θ ) p(θ | x )dθ
(independent samplings correlated
through model+ posterior)
Example: Comparing sample means
We have seen the case for two means:
differences between two means:
Student’s t-Distribution
Differences among a group of means: Generalize Student’s t-Distribution
Classical Approach: ANOVA (R.A. Fisher):
To compare means, consider variances within groups
and variances between groups
Classically… under hypothesis of Normality
transformations to get “close” to Normal
Clear and general scheme as
Hierarchical Bayesian Structure
φ { , , }
Hierarchical Structure
(assume Normality in
this example)
1) J groups of observations:
(, 2 , 2 )
J
y1
y j
y J
yij ~ N ( j , 2 )
j
J
y j { y1 j ,..., yn j j }
j 1
2) For each group j 1,..., J , observations { y1 j , y2 j ,..., yn j j }
are considered as an exchangeable sequence (within groups;
conditional on { j , } ) drawn from the model
3) For the J groups, the parameters {1 , 2 ,..., J }
are considered as an exchangeable sequence conditional on
{ , } drawn from the model
4) Set up prior
j ~ N (, 2 )
1 j
yij ~ N ( j , 2 )
j ~ N (, 2 )
(, 2 , 2 )
nj
yij ~ N ( j , )
2
p ( y j | j , ) ~ e
1
( yij j ) 2
2 2
i 1
J
( j )2
( yij j )
nj
1
2 2
e
i 1
2
j ~ N ( , )
p ( y j , j | , , ) ~ e
{ y j , j , , , } ~
p( y j , j , , , ) ~ p( y j , j | , , ) ( , , )
2
For the J groups:
1
2 2
j 1
2 nj
yij 2
2 2
j ~ N i 21
,
nj 2
2 n j 2
For { , , } :
( ) N ( 0 , 02 )
J
2
2
0 0 j
2 02
j 1
~ N
, 2
2
2
0 J
02 J
2
1 J
J
2
~ Ga ( j ) c, b
2
2 j 1
2
J
1 J nj
1
2
~ Ga ( yij j ) a, n j b
2 j 1
2 j 1 i 1
2
( ) Ga(c, d )
( ) Ga(a, b)
2
(…Inverse Gamma Distribution… )
(Uniform priors for
and
Gibbs Sampling:
0) Set
correspond to
ac0 ; bd
1
)
2
(see lecture on MC sampling)
{0 , 0 , a, b, c, d }
1) Draw from marginal densities
1): {1 , 2 ,..., J } j ~ N (,)
~ N (,)
2): { }
3): {}
4): {}
~ Ga(,) 1/ 2
~ Ga(,) 1/ 2
Repeat step 1) until equilibrium is reached and then take 1 every 5 or 10 samples
For this example I took, without further checks, (all densities are proper)
{0 , 0 } sample mean and rms
a c
1
; b d ( )
2
Sampling Distribution of differences
Real data (now a days irrelevant and forgotten) on scaled transmittance of aerogel tiles under
different pressure and temperature
Predictive Distribution:
SAMPLING from POSTERIOR (“Bayesian Bootstrapping”)
As starting hypothesis, we consider a model:
M X p( x | θ) ; x X ; θ
…but any model is an approximate description of nature
Is the model reasonable to describe the observed data?
From the posterior p(θ | x ) we make inferences but do not have a feeling
on the adequacy of the model
If doubts:
M Xi ) pi ( x | θ ) ; x X ; θ
1) Check other models (obvious)
2) Get a feeling of the adequacy of the model from predictive density
p( x new | x obs ) p( x new | θ ) p(θ | x obs )dθ
usually MC sampling under the assumption that model is adequate and test
statistics (for instance order statistics)
PROBABILITY MATCHING PRIORS
Welch B. , Pears H. (1963) J. Roy. Stat. Soc. B 25 318-329
Ghosh M., Mukerjee R., Biometrika 84 970-975
Probability Matching Priors
Prior distribution such that one-sided credible intervals derived from posterior
distribution coincide (to a certain degree of accuracy) with those derived from
frequentist approach
Expand
p(θ | x) p( x | θ ) (θ )
around θm max θ p( x | θ ) up to O ( m ) 4
T nI ( m ) ( m )
12
1
2
Z ( z ) I ( ) ( )
z 2 I 2 ( )
P(T z | x ) P( z )
O 1
n
3
n ( )
m
m
“Frequentists” : 0 m O 1
n
1 x2 2
Z ( x)
e
2
x
P( x) Z (t )dt
and, for a sequence of priors that shrink to m 0
1
Z ( z ) z 2 1 I 2 ( )
PF (T z | x ) P( z )
O 1
n
n 3
m
same Probability if
I 12 ( ) ( )
I 12 ( )
( )
m
m
( ) I ( ) 2
1
…Jeffrey’s prior is PMP
p( x | θ1 , θ2 ,..., θn )
n-dimensional case:
Parameter of interest:
θ1
…same argument…
ordered parameterization
{θ1 , θ2 ,..., θn }
1) S F 1
2)
k 1 k
p
S k1
(θ ) 1/ 2 0
S11
EXAMPLE:
Gamma Distribution:
any solution
b
a
p( x | a, b) e ax x b 1
1[ 0, ) (x)
(b)
1) Fisher’s matrix elements are:
2) ordering
(θ ) will do the job
b
Faa 2
a
1
Fab
a
a, b R
Fbb ' (b)
{b, a}
PM (b, a) a 1b 1/ 2 b' (b) 1
{a, b}
PM (a, b) a 1 ' (b) b' (b) 1
( ais a scale parameter)
J (a, b) a 1 b' (b) 1
PROBLEM: Correlation Coefficient of the Bivariate Normal Model
1
t
p( x | μ, Σ ) det[ Σ ]1/ 2 exp x μ Σ 1 x μ
2
μ 1
2
x
x 1
x2
12
Σ
1 2
1 2
2
2
iid
e(n) x {( x11, x21 ), ( x12 , x22 ),..., ( x1n , x2 n )}
1) Show that a probability matching prior with
given by
the parameter of interest is
( , 1 , 2 , 1 , 2 ) 11 2 1 (1 2 ) 1
2) Show that the posterior for the correlation coefficient is:
( | x ) (1 2 ) ( n 3) / 2 (1 r ) ( n 3 / 2) F 1 / 2,1 / 2, n 1 / 2,
sample correlation r
(x
1i
1 r
2
x1 )( x1i x1 )
i
2
2
(
x
x
)
(
x
x
)
1i
1
2i
2
i
i
1/ 2
is a sufficient statistic for
REFERENCE PRIORS
Reference Priors
Bernardo, J.M. (1979)
J. Roy. Stat. Soc. Ser. B 41 113-147
M X p( x | θ) ; x X ; θ
e(1) x1
I e(1), p(θ )
Expected amount of info on parameter provided by one
observation of the model p( x | ) relative to prior knowledge p( )
, X
p(θ , x )
p(θ | x )
p(θ , x ) log
dxdθ p(θ )dθ p( x | θ ) log
dx
p( x ) p(θ )
p(θ )
X
Expected Mutual Information:
Given two continuous random quantities X and Y with density
X if we observe Y is
p( x, y)
, the info we expect to get on
p( x, y)
p ( x | y )
I ( X : Y ) dx dy p( x, y) ln
p( y)dy dx p( x | y) ln
p ( x) p ( y ) Y
p ( x)
X
Y
X
Kullback-Leibler Discrepancy between two distributions
A sequence { pi ( x)}i 1 of pdf’s converges
logarithmically to a pdf p (x ) iff:
f ( x)
dx
DKL g f f ( x) ln
g
(
x
)
X
lim i DKL p | pi 0
X e(k ) x1 , x2 ,..., xk
iid
For k independent observations
Expected amount of info on parameter provided by k independent observations
of the model p( x | ) relative to prior knowledge p( )
zk x1 , x2 ,..., xk
dzk dx1dx2 dxk
p(θ | zk )
I e(k ), p(θ ) p(θ )dθ p( zk | θ ) log
dzk
p(θ )
X
p( z
k
| θ )dzk 1
X
f k (θ )
p(θ )dθ p( zk | θ ) log p(θ | zk )dzk log p(θ ) p(θ ) log
dθ
p(θ )
X
f k (θ )
I e(k ), p(θ ) p(θ ) log
dθ
p(θ )
“Perfect info”
f k (θ ) exp p( zk | θ ) log p(θ | zk )dzk
X
I e(), p(θ ) lim I e(k ), p(θ )
k
(if )
measures maximum info on θ that could be obtained from model p( x | )
relative to prior knowledge p( )
Central Idea:
M X p( x | θ) ; x X ; θ
Reference prior relative to model
… that for which “perfect info” is maximal
… “less informative” for this model
Calculus of Variations
p(θ ) p (θ ) (θ )
p(θ )dθ p
log f k (θ ) log f k (θ ) O( 2 )
(θ )
log p(θ ) log p (θ )
O( 2 )
(θ )dθ 1
(θ )dθ 0
p (θ )
f k (θ )
I e(k ), p(θ ) I e(k ), p (θ ) (θ )log
1dθ O( 2 )
p (θ )
θ p(θ ) f k (θ )
Problems:
1) implicit equation since f k (θ ) depends on
2) usually lim f k ( ) divergent:
k
p(θ )
through posterior p(θ | xk )
∞ info needed to know θ
3) In general, info not defined on unbounded sets sequence of priors
(Propper priors, defined on a sequence of compacts
k
k ( )
k k
)
Define what is a “Reference Prior”
Berger, J.O., Bernardo J.M., Sun D (2009)
Ann. Stat.; Vol. 37, No. 2; 905-938
Def.: Permissible Prior:
A strictly positive prior function ( ) is a permissible prior for the model
M X p( x | θ) ; x X ; θ if :
1) x X
p( x |θ ) (θ )dθ
proper posterior
2) For some approximating compact sequence, k
k k
the sequence of posteriors
k (θ | x) p( x | θ ) k (θ )
converges logarithmically (DKL) to (θ | x ) p( x | θ ) (θ )
Def.: Reference Prior
A permissible prior that maximizes “perfect info”
(for model MX )
Explicit form of the reference prior:
Berger, J.O., Bernardo J.M., Sun D (2009)
Ann. Stat.; Vol. 37, No. 2; 905-938
1) Consider a continuous strictly positive function ( )
p( zk | ) ( )
such that the corresponding posterior
( | zk )
is proper and asymptotically consistent
p( zk | ) ( )d
(… the easier the better …)
2) Obtain
f (θ ) exp p( zk | θ ) log (θ | zk )dzk
X
k
and for any interior point
f k (θ )
θ0 of define hk (θ , θ0 )
f k (θ0 )
3) If
3.1) each f k (θ ) is continuous
3.2) For any fixed θ and large k hk (θ , θ0 ) is either monotonic in k
or bounded above by some h(θ ) which is integrable on any compact set
3.3) f (θ ) lim k hk (θ , θ0 ) is a permissible prior function
Then (θ ) f (θ ) is a reference prior for the model M X p( x | θ) ; x X ; θ
Easy to implement a MC. algorithm
If I exists, ( )
Usually are PMP
I ( ) 2
1
EXAMPLE: Scale Parameter
Show that
1
( )
p( x | )
is a reference prior for the model
1 x
f
x R; R
Solution:
1 k xi
p( x1 , x2 ,..., xk | θ ) k f
i 1
X e(k ) xk x1 , x2 ,..., xk
1
Take, for instance: ( ) a
1 ( k a ) k xi
Proper posterior: k ( | x )
f
I ( x)
i 1
iid
I (x )
( k a )
0
x
log ( | x ) (k a) log log I ( x ) log f i
i 1
k
k
p
(
x
,
x
,...,
x
|
θ
)
log
( | x)dx1dx2 dxk (k a) log J1 (k ) J 2 (k , , a)
1
2
k
k
X
xi
f
d
i 1
k
J1 (k )
k
k
f xi
X i 1
k
1
log f x dx dx dx
j
X i 1
X i 1
j
j 1
J 2 (k , , a) k f xi 1
k
1
1
2
k
~
k f w log f wdw kJ1
W
( k a ) k
1
log '
f
x
'
d
'
dx1dx2 dxk
i
i 1
0
( k a 1) ( k a ) k
f wi log
s
f
sw
ds
dw1dw2 dwk
i
i 1
0
~
J 2 (k , a) (k a 1) log
~ ~
p( x | θ ) log ( | x)dx log kJ1 J 2 (k , a) log G(k , a)
k
Xk
1
f k (θ ,) exp p( x | θ ) log k ( | x )dx exp{G (k , a)}
X k
f k (θ ,) 1
( ) lim
k f ( ,)
k
0
PROBLEM: Poisson Distribution
p(n | ) e
Consider X e(k ) xk n1 , n2 ,..., nk
iid
Show that
f k (θ,) k
1/ 2
(n 1)
(θ ) 1
and
and, in consequence
f k (θ ,)
1
( ) lim
1/ 2
k f ( ,)
k
0
N n
p(n | , N ) (1 ) N n
n
PROBLEM: Binomial Distribution
Consider X e(k ) xk n1 , n2 ,..., nk
iid
Show that
n
θ (0,1) (θ ) θ a 1 (1 θ )b1
and
f k (θ ,)
1
( ) lim
1/ 2
1/ 2
k f ( ,)
(
1
)
k
0
Hint: Analize the behaviour of
f k (θ ,)
expanding
log ( z,)
around
E[z ]
and considering the asymptotic behaviour of the Polygamma Function
n ) ( z ) ~ an z n an 1 z ( n 1) ... , the moments of the Distribution,…
For n>1 dimensions
1) arrange parameters in order of importance
{1 , 2 ,3 ,...}
2) proceed sequentially with conditionals
( n | 1 , 2 ,..., n1 ) ( 2 | 1 ) (1 )
(… check if they are proper)
Ex: n=2
X ~ px|θ,
parameter of interest:
nuisance parameter:
ordered parameterization
{ , }
p(θ , , x) p( x | θ , ) ( | θ ) (θ )
1) get conditional prior
( | )
2) find the marginal model:
3) get reference prior
( )
(reference prior for
keeping
fixed)
p(θ , x) (θ ) p( x | θ , ) ( | θ )d (θ ) p( x | θ )
from marginal model
p( x | θ )
EXAMPLE: Multinomial
X ~ Mn(n | θ )
p(n | θ ) θ θ θk (1 k )
n1 n2
1 2
nk
k
k θ j
nk 1
j 1
{θ1 , θ2 ,, θk }
ordered parameterization
(θ1 , θ2 ,, θk ) (θk | θk 1 ,..., θ1 ) (θk 1 | θk 2 ,..., θ1 ) (θ1 )
(θm | θm1 ,..., θ1 ) θ
All are proper
1/ 2
m
(1 m )
1/ 2
k
R (θ1 , θ2 ,, θk ) θi
1/ 2
(1 i )
1/ 2
i i
k ni 1/ 2
1/ 2
p(θ | n) θi
(1 i ) (1 k ) nk 1
i i
… 2) proceed sequentially with conditionals …
Usually
p( x | θ, ) ( | θ )d
( | ) is improper
divergent
Define k ( | ) over a sequence k of compact sets
of the full parameter space such that in the limit tend to
For instance:
(0, )
k [1 / k , k ]
One nuisance parameter with
Joint Posterior Asymptotic Normality:
If:
independent of θ
such that
F (θ , )
S (θ , ) F (θ , )
1
Then
such that
k
k 1
Bernardo J.M., Ramón J.M. (1998)
The Statiscian 47, 1-35
F
S
2, 2 (θ , )
1/ 2
a1 (θ ) b1 ( )
1/ 2
a0 (θ ) b0 ( )
1,1 (θ , )
( | θ ) b1 ( )
(θ , ) a0 (θ )b1 ( )
(θ ) a0 (θ )
even if conditional reference
priors are not proper
EXAMPLE:
Gamma Distribution:
b
a
p( x | a, b) e ax x b 1
1[ 0, ) (x)
(b)
1) Fisher’s matrix elements are:
2) Jeffrey’s prior
2) ordering
{b, a}
b
Faa 2
a
1
Fab
a
a, b R
Fbb ' (b)
J (a, b) a 1 b' (b) 1
(a
is a scale parameter)
R (b, a) a 1b1/ 2 b' (b) 1
PM (b, a) a 1b 1/ 2 b' (b) 1
{a, b}
R (a, b) a 1 ' (b)
PM (a, b) a 1 ' (b) b' (b) 1
PROBLEM: Negative Binomial
( a x )
a (1 ) x
( x 1)(a)
a0
X {0,1,2,}
0 1
X ~ p( x | , a)
a: number of failures until experiment is stopped (fixed)
X: number of successes observed
θ: probability of failure
E[ X ] a(1 ) 1
F ( ) a 2 (1 ) 1
R ( ) J ( ) 1 (1 ) 1/ 2
p( | x, a)
PROBLEM: Weibull Distribution
1) Find the transformations
a 1 (1 ) x 1/ 2
Be (a, x 1 / 2)
p( x | , ) (x) 1 exp{(x) }1[0,) (x)
Z Z(X )
and
φ φ( , )
, R
such that the new parameters are location and scale parameters and
transform them back to get the corresponding (improper) prior
2) Obtain the Fisher’s matrix and the Jeffrey’s prior
3) Find the reference prior
4) Show that it is a Probability Matching Prior
( , ) 2 1
EXAMPLE: Ratio of Poisson Parameters
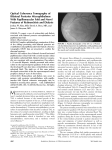
Sky maps showing the arrival directions of selected 16–350 GeV electrons (left) and positrons (right) in galactic coordinates
using a Hammer-Aitoff projection. The color code reflects the number of events per bin. J. Casaus et al.; 33rd ICRC-2013
Model:
X1 ~ Pon1 | 1
independent
X 2 ~ Pon2 | 2
Previous case with same efficiencies
and exposure times:
12
Nuisance parameter:
2
Ordered parameterisation: { , }
Parameter of interest:
e (1 ) n1 n1 n2
pn1 , n2 | ,
(n1 1)(n2 1)
1
1
F
1
Prior:
F
2, 2 (θ , )
1/ 2
S
1/ 2
1,1 (θ , )
(1 ) 1
1
(1 )
1
(1 ) 1
( | θ ) b1 ( ) 1/ 2
1/ 2
(θ ) a0 (θ ) (1 )1/ 2
a0 (θ ) b0 ( )
( , ) ( | ) ( ) 1/ 2 (1 ) 1/ 2
Posterior:
p | n1 , n2 p , | n1 , n2 d
(n1 n2 1)
n1 1/ 2
p | n1 , n2
(n1 1 / 2)(n2 1 / 2) (1 ) n1 n2 1
(n1 1 m)(n2 1 m)
2
2
E[ ]
(n1 1 )(n2 1 )
2
2
m
a1 (θ ) b1 ( )
1/ 2
(1 ) 1
F
1
E[ | n2 1]
n1 1
2
n2 1
2
Example: Characterization of a source
region S
Events are produced with a rate
s
and collected during an “exposure” time
Model:
Events produced at S follow
ts
S
S
ns ~ Po(ns | s t s )
Produced events are detected with probability s
s ~ Bi ( s | ns , s )
Observed events:
Poisson-Binomial model s ~
Bi (s | n ,
ns s
s
s
)Po(ns | s t s ) Po( s | s t s s )
region S
Background inferred from observations at
Model:
b ~ Po(b | btb b )
p(s, b | ) Po(s | s t s s ) Po(b | btb b )
2) Prior:
Parameters of interest: Ratio of Poisson Parameters
s s
, b b
b b
(usually s b )
atb 1
F
atb
1
tb (1 a )
atb
p( s, b | ) e tb (1 a ) s b s
n bs
F
1
(1 a )(atb ) 1
1
tb
a
ts
tb
1
tb
1
tb
( , ) ( | ) ( ) 1/ 2 (1 a ) 1/ 2
3) Posterior:
p( , | s, b, a, tb ) e tb (1 a ) s 1/ 2 (1 a ) 1/ 2 b s 1/ 2
4) Integrate nuisance parameter:
I m I 0 E[ m ]
m ns
1
a m s 1/ 2
s 1/ 2
p( | s, b, a, tb ) I 01
(1 a ) n 1
(n s m 1 / 2)( s m 1 / 2)
(n 1)
Sensitivity to existence of a source:
λS=4.0
MC simulation with
λS=5.0 λS=6.0
s b
b 4.0; t B 200
t s 50
p ( | )
pmax
F ( | )
If Source…
s b
Ordered Parameterization { , b }
Info on b : Get p(b | ) from
S
region
p(s | n, nB , t , t B ) ( ) Po( s | (b )t s s )Ga(b | tb b , b 1 / 2)db
0
( ) e
t s
s k
ak
k 0 k
s
ak (t ) k (n k 1 / 2)
s b
t t s tb
n bs
PRIORS WITH PARTIAL INFORMATION
…Including Partial Information in the PRIOR…
g (θ ) (θ )d a
(θ )
j
1) get reference prior
X ~ p( x | θ )
j
0
( ) from model p( x | θ )
2) find the prior (θ ) for which ( ) is the best approximation in the
0
Kullback-Leibler sense with Lagrange multipliers for the constraints:
(θ )
I (θ ) ln
dθ j g j (θ ) (θ )d a j
0 (θ )
j
(θ ) s (θ ) (θ )
j g j (θ )
S (θ ) (θ )e j
S (θ )
I I s (θ )ln
1 j g j (θ ) dθ O( 2 )
j
(θ )
j
g (θ ) p (θ )d a
j
0
j
EXAMPLE: Unfolding (2)
PRIOR:
θ ~ 0 (θ | α, β ) GDi(θ | α, β )
nt
θ
i 1
i
1
Additional constraints:
for instance existence of 1st derivative g j (θ) ( j , j 1θ j 1 j 1, j θ j 1 θ j j 1, j 1 )2 0
(θ | α, β ) 0 (θ | α, β )e
POSTERIOR:
j g j (θ )
i ,k xi xk
j
p(θ | d , α, β ) p(d | φ(θ )) (θ | α, β )
MCM to draw sampling of θ
MC simulation of AMS-02
Cosmic Ray spectrum for p
PRIORS for MODELS WITH
DISCRETE PARAMETERS
Discrete Parameter Prior
1) Hierarchical Model:
θ Discrete (or continuous)
Specify: p(θ | )
Model: p( x | θ )
: continuous hyperparameter
p(θ , ) p(θ | ) p( )
p(θ , , x) p( x | θ , ) p(θ , ) p( x | θ ) p(θ | ) p( )
p( , x ) p(θ , , xk )dθ p( ) p( x | θ ) p(θ | )dθ p( x | ) p( )
Model:
p( x | ) p( x | θ ) p(θ | )dθ
p(θ , ) p(θ | ) p( )
Prior: p ( )
Prior: p(θ ) p(θ , )d p(θ | ) p( )d
2) Simpler approach:
Continuum embedding of parameter space
Example: CHARGE Determination with a Cherenkov Detector
X ~ Po(n | n0 Z 2 )
Observed Number of Cherenkov Photons
n0 :
(known) Expected number of photons for a Z=1 particle
(Z ) ~ c
p( Z | n , n0 ) e
n0 Z 2
Z
2 n
P(Z i | n, n0 ) (i) (i)
(i)
(n 1 / 2, n0 (i ) 2 )
(n 1 / 2)
(Check accuracy)
Last,
Another kind of problems you may be
interested in:
Regression Problems
Regression Problems: linear regression
Data:
Linear Model:
Model:
{( xi , yi ); i 1,..., n}
yi a bxi i
i ~ N ( | 0, )
unknown
1 n
2
n
p( y | x, a, b, ) exp 2 yi a bxi
2 i 1
0) Parameters of interest:
{a, b, }
1) Less messy in matrix form ( and easier to generalize)
y1
Y
y
n
a
P
b
1 x1
D
1 x
n
1
t
p( y | x, a, b, ) n exp 2 Y DP Y DP
2
a
2) Express the exponent in a more convenient form: Find the minimum P
b
P ( Dt D) 1 Dt Y
Dt D P Dt Y
S Y DP Y DP Y DP
t
Y DP P P D DP P
t
t
t
dependence on {a, b}
1
p( y | x, a, b, ) n exp
S
(
a
,
b
,
y
,
x
)
2
2
Model:
S (a, b, y, x ) Y DP
Y DP P P D DP P
t
t
1
Prior:
(a, b, )
Posterior:
1
p(a, b, | y, x ) ( n 1) exp
S
(
a
,
b
,
y
,
x
)
2
2
p ( a, b | y , x )
0
t
P P Dt D P P
p (a, b, | y, x )d 1
Y DP t Y DP
1) Different and known variances:
2) Other functional form:
t
i ~ N ( | 0, i )
yi g ( xi ) i
i
n / 2
(*)
unknown
Regression function
►Prior specification quite involved
►may work… decompose the regression function in a linear
combination of orthogonal polynomials…
(*) (Same formal solution for
yi b0 b1 xi1 ... bn xin i
)
Example: Spherical harmonics
… different approaches…
Real basis in Ω:
Ylm ( , )Yl 'm' ( , )d ll' mm'
Y
lm
r n1 1/ 2
p(r | n1 , n2 ) N (n1 , n2 )
(1 r ) n1
cos( )
1
p( , | a )
1 a lmYlm ( , | a )
4
l 1
( , ) p( , | a ) 0
4
)
3
l
ri alm Ylm ( , )d
l 0 m l
1
a12m
m 1
a11 , a10 , a11 Un S3 (r
( , )d 4 l 0
d sin dd
4
3
i
Problem: Linear Regression
(with uncertainty in x and y)
Linear Model:
{( xi , yi ); i 1,..., n}
y a bx
Model:
( X i , Yi ) ~ N ( xi , yi | xi0 , yi0 , xi , yi )
Data:
Assume precisions
( xi , yi ) are known and show that:
xi yi
p(a, b | x, y ) ~ (a, b)
2
2 2
i 1
b
xi
yi
n
Take (a, b) (a) (b) c
2
1 n ( yi a bxi )
exp
2
2 2
2
b
i 1
yi
xi
and obtain p(a, b | x, y )
y
x2
x
2
2
y
TEST OF HYPOTHESIS
…Evaluate evidence in favour of a scientific theory
Again fundamental conceptual difference:
F: What is the probability to get this data given a specific model?
B: What are the probabilities of the various hypothesis given the data?
DECISION THEORY
DECISION THEORY
PROBLEM: How to choose the optimal action among a set of different
alternatives
(… Games Theory)
For a given problem, we have to specify:
X
A
Set of all possible “states of nature”
(Parameter Space)
Set of all possible experimental outcomes
(Sample Space)
Set of all possible actions to be taken
Example: Disease Test
X
A
{sane, ill}
{test +, test -}
{apply treatment, do not apply treatment}
In nontrivial situations, we can’t take any action without potential losses
2) Loss Function
Basic element in Decision Theory: Loss Function
l (a | ) : ( , a) A {0}
Quantifies the loss associated to take an action (or decision)
when the “state of nature” is
a
…What do we know about ?
The knowledge we have on the “state of nature” is quantified by the
posterior density p( | x)
3) Risk Function
R(a | x) E [l (a | )] l (a | ) p( | x) d
Risk associated to take the action
having observed the data
a
x
4) Bayesian Decision: Take the action
(Minimum Expected loss)
a(x)
that minimises the Risk
a( x) | min{ R(a | x)}
Two types of problems:
Hypothesis Testing:
Inference:
A
{accept, reject} an hypothesis
A
a(x) statistic that we shall take as an estimator of
Hypothesis Testing: Example with two alternatives
P( H i | data)
P(data | H i ) P( H i )
P(data)
Hypothesis are exclusive
and exhaustive
Possible actions:
a1
a2
H1
action to be taken if we decide for hypothesis
Loss function
l (a1 | H1 ) l11 0
l (a2 | H 2 ) l22 0
l (a1 | H 2 ) l12 0
l (a2 | H1 ) l21 0
take action
(i.e. choose hypothesis)
H2
when “state of
nature” is
a1
a2
H1
H1
H2
H2
a1
a2
H1
H2
H2
H1
2
Risk Function:
R(ai | data) l (ai | H j ) p( H j | data)
j 1
R(a1 | data) l11 p( H1 | data) l12 p( H 2 | data)
R(a2 | data) l21 p( H1 | data) l22 p( H 2 | data)
Bayesian Decision: Take the action that minimises the Risk
take action
a1 (choose hypothesis H1 ) if R(a1 | data) R(a2 | data)
p( H1 | data)(l11 l21) p( H 2 | data)(l22 l12 )
If we take l11 l22 0
p ( H1 | data) l12
p ( H 2 | data) l21
(same for a2 )
p ( H 2 | datos) l21
p ( H 1 | datos) l12
Bayes Factor:
take action
P( H i | data)
P(data | H i ) P( H i )
P(data)
a1 (decide for hypothesis H1 ) if
p( H1 | data) p(data | H1 )
p( H 2 | data) p(data | H 2 )
Posterior odds
p( H1 ) l12
p( H 2 ) l21
Evidence from
data
Prior odds
Change of prior beliefs…
How strongly data favours one model over the other
B12
p(data | H1 )
p(data | H 2 )
Choose hypothesis H1
if
l12 p ( H 2 )
B12
l21 p ( H 1 )
Ratio of likelihoods
Usually:
l12 l21
p(H1 ) p(H 2 )
( … 0-1 loss function)
decide for hypothesis H1 if
B12 1
HYPOTHESIS TESTING: General cases:
Hypothesis:
SIMPLE: specify everything about the model/models,
including values of parameters
1 2 ; i {i }
COMPOSITE: parameter values are not specified by hypothesis
(+ different models and nuisance parameters)
S-S:
p ( H 1 | data)
p ( H 2 | data)
p ( x | , )
1
...
1
1
(1 , )d
p
2
( x | 2 , ) 2 ( 2 , )d
...
p( x | 1 ) (1 )
p( x | 2 ) ( 2 )
...
p( x | M 1 )
p( x | M 2 )
C-C:
p1 ( x | , ) 1 ( , )d dθ
1
p2 ( x | , ) 2 ( , )d dθ
2
Marginal likelihoods of data
for the two models
Example:
S-S:
H
H
: particle with Z=2 is a 3He nucleus
: particle with Z=2 is a 4He nucleus
(mobs m2 ) 2 (mobs m1 ) 2
2
p (mobs | H )
N (mobs | m1 , 1 )
B12
exp
2
2
p (mobs | H ) N (mobs | m2 , 2 )
1
2
2
2
1
l12 l21
l11 l22 0
In favour of H if:
p( H )
p( H )
B12
ln B12 ln
p( H )
p( H )
Critical mass value: 12 (mC m2 ) 2 2 2 (mC m1 ) 2 2 12 2 2 ln
mo mC 3He
mo mC 4He
Usually, keep p(H) and P(Hbar)
P( H ) 1
P( H ) 2
Receiver Operating Characteristic
optimum
For each value of mc
H
(1,1)
(0,1)
H
P( H , c) P ( H , c)
P( H )
true positives
P( H , c) P ( H , c)
c
f (u )du
P( H , c) F1 (c)
1
c
P( H , c) F2 (c)
f
2
(u )du
x F2 (c) f ( x) F1 ( F21 ( x))
1
1
0
0
( f ( x), x)
random
A 0.5
( x, x )
A f ( x)dx F1 ( F21 ( x)) dx
A
F (u) f
1
(0,0)
2
u
(u )du f 2 (u )du f1 ( x)dx
P( H )
false positives
d 2 ( f ( x) x) 2 max( d )
X ~ Unx|0, θ
Example:
X 0, θ
X e(m) x1 , x2 ,..., xm
iid
We have seen already that:
Sufficient statistic
Scale parameter
C-C:
Hypothesis:
t max x1 , x2 ,..., xn
tn
p(θ | n, t ) n n 1 1( t , ) (θ )
θ
~ Pa(θ | n, t )
( ) 1
Ho (null hypothesis)
(0, ]
H1 (alternative hypothesis)
( , )
P( H 0 ) :
p(θ | n, t )1
( t , )
(θ )dθ
1( 0,t ) ( ) t
0
P ( H1 ) :
0-1 Loss:
p(θ | n, t )1
( t , )
P( H 0 )
P ( H1 )
(θ )dθ
1 t n 1
(t , ) ( )
1
0 if t
n
1 if t
t
if
t
n
( t , )
( )
P(θ [ , )) t
n
STATISTICAL INFERENCE
Point Estimation
“…when you cannot express it in numbers,
your knowledge is of a meagre and unsatisfactory kind.”
(Lord W.T. Kelvin)
INFERENCE: (Point estimation)
1) Quadratic Loss: l (a | ) ( a) 2
R(a | x) E [l (a | )] ( a) 2 p( | x) d
mean
a E[ ]
a | min[ R(a | x)] ( a) p( | x) d 0
l (a | ) c1 (a )1( ,a ] ( ) c2 ( a)1( a , ) ( )
2) Lineal Loss:
a
a
R(a | x) c1 (a ) p( | x) d c2 ( a) p( | x) d
c2
a | min[ R(a | x)] P( a)
c1 c2
3) Zero-one Loss:
min
(1 1
B ( a ; )
c1 c2
l (a | ) 1 1B ( a; ) ( )
( )) p( | x) d max
p( | x) d
B ( a; )
median
mode
| max{ p( | x)}
θ2
CREDIBLE REGIONS
[θ1 , θ2 ] | p(θ | x ) dθ
θ1
HPD (Highest Probability Density): Smallest possible volume V
in parameter space such that p(θ | x ) dθ
V
Equivalent definitions:
1) V {θ } such that
1)
p(θ | x) dθ
V
2)
2) V {θ | p(θ | x ) k }
where k is the largest constant
for which P(θ V )
HPD regions may not be connected
(for instance more than one mode)
θ1 V and θ2 V
p(θ1 | x) p(θ2 | x)
p(θ | x ) k
k
p(θ | x ) k
V {θ | p(θ | x) k }
One dimension:
1
p( 2 | x)
2
1
p (1 | x)
p(1 | x) p(2 | x)
If distribution has one mode and is symmetric
Some useful properties:
p( | x) d
1
1 2
2 2E[ ] 1
Usually, HPD regions determined from MC sampling
1) p(θ1 | x) p(θ2 | x) both are included
or excluded
θ1 ,θ2 HPD
θ1 ,θ2 HPD
2) For a given CL there is a p value such that HPD {θ | p(θ | x ) p }
(Def. 2)
3) ( ) one to one:
Region with probability content in has probability content in
… but in general is not HPD unless linear relation
4) In general equal tailed credible intervals may not have the smallest size
(are not HPD)
EXAMPLE: 3He and 4He nuclei (AMS-01)
Observed (identified as):
n3 97
Identification criteria:
P4 | 4 , P3 | 3
Parameter of interest:
Probability to identify a
nucleus as 3He:
( , p33 , p34 ) P(3 | 3) P(3 | 4)(1 )
n 115
Probability that an event of type i=3,4
is identified correctly
Probability that a nucleus is of 3He
(1 p44 ) (1 p33 p44 )
Model:
X 3 ~ P(n3 , n4 | , p33 , p34 ) n3 (1 ) nn3
Ordered parametrisation:
{ , p33 , p34}
prior: ( , p33 , p34 )
( , p33 , p34 ) ( p33 ) ( p34 ) ( )
{ , p33 , p34}
Knowledge on:
0
( p33 ) ~ N ( p33 | p33
, 33 )
0
( p44 ) ~ N ( p44 | p44
, 44 )
(from MC sampling)
( ) (1 )1/ 2
(from MC sampling)
0
0
( p33
0.852, p44
0.803, ii 0.005)
p( | n3 , n4 )
n 1 / 2
n
(
,
p
,
p
)
(
1
(
,
p
,
p
))
33
34
33
34
3
4 1 / 2
( p33 ) ( p34 )dp33dp34
p33 , p34
E[ ] 0.951
P( (0.94,1) 0.68
P( (0.88,1) 0.95
The END
… of L2