Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Operational transformation wikipedia , lookup
Data Protection Act, 2012 wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Data center wikipedia , lookup
Clusterpoint wikipedia , lookup
Expense and cost recovery system (ECRS) wikipedia , lookup
Forecasting wikipedia , lookup
Data analysis wikipedia , lookup
Information privacy law wikipedia , lookup
3D optical data storage wikipedia , lookup
Data vault modeling wikipedia , lookup
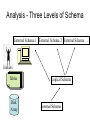
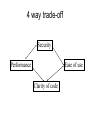
Introduction to Databases Data Organisation Definition Data modelling SQL DBMS functions Basics of data Organisation: DATA HIERARCHY (four categories) • Fields = represent a single data item • Records = made up of a related set of fields describing one instance of an entity • File / Table = a set of related records - as many as instances (occurrence) in the set • Database = a collection of related files Example of data structure Fields Records Name First name Telephone Zidane Feller Clinton Henry Zinedine Joe Bill Thierry File / Table 45 25 65 65 25 58 96 63 12 25 28 89 25 78 85 85 + Other files =>complete data Structure = DB Database: Definition. "A collection of interrelated data stored together with controlled redundancy, to serve one or more applications in an optimal fashion; the data is stored so that it is independent of the application programs which use it; a common and controlled approach is used in adding new data and in modifying existing data within the database." Definition - closer look • A collection of interrelated data stored together • with controlled redundancy • to serve one or more applications in an optimal fashion • the data is stored so that it is independent of the application programs which use it • a common and controlled approach is used in adding new data and in modifying existing data within the database. Advantages of Databases: • data are independent from applications - stored centrally • data repository accessible to any new program • data are not duplicated in different locations • programmers do not have to write extensive descriptions of the files • Physical and logical protection is centralised Disadvantages of DBs: • Centralisation can be a weakness • Large DBs require expensive hardware and software • specialised / scarce personnel is required to develop and maintain large DBs • Standardisation of data on a central repository has implications for the format in which it is stored Characteristics of DBs… • High concurrency (high performance under load) • Multi-user (read does not interfere with write) • Data consistency – changes to data don’t affect running queries + no phantom data changes • High degree of recoverability (pull the plug test) ACID test • • • • Atomicity Consistency Isolation Durability All or nothing Preserve consistency of database Transactions are independent Once committed data is preserved DataBase Management System (DBMS): • program that makes it possible to: – create – Use (insert / update / delete data) – maintain a database • It provides an interface / translation mechanism between the logical organisation of the data stored in the DB and the physical organisation of the data Using a database: Two main functions of the DBMS : • Query language – searching answers in data (SQL) • Data manipulation language - for programmers who want to modify tha data model in which the data is stored • + Host Language - the language used by programmers to develop the rest of the application - eg: Oracle developer 2000 Relational DBs: • Data items stored in tables • Specific fields in tables related to other field in other tables (joint) • infinite number of possible viewpoints on the data (queries) • Highly flexible DB but overly slow for complex searches • Oracle, SyBase, Ingres, Access, Paradox for Windows... Describing relationships • Attempt at modelling the business elements (entities) and their relationships (links) • Can be based on users’ descriptions of the business processes • Specifies dependencies between the data items • Coded in an Entity-Relationship Diagram (ERD) Types of Relationships • one-to-one: one instance of one data item corresponds to one instance of another • one-to-many: one instance to many instances • many-to-many: many instance correspond to many instances • Also some relationships may be: – compulsory – optional Example • Student registering system • What are the entities? • What type of relationship do they have? • Draw the diagram Entity Relationship Diagram Example 2 – Sales Order Processing • Entities • Relationships • Use a business object based approach? Next step - creating the data structure • Few rules - a lot of experience • Can get quite complex (paramount for the speed of the DB) • Tables must be normalised - ie redundancy is limited to the strict minimum by an algorithm • In practice, normalisation is not always the best Data Structure Diagrams • Describe the underlying structure of the DB: the complete logical structure • Data items are stored in tables linked by pointers – attribute pointers: data fields in one table that will link it to another (common information) – logical pointers: specific links that exist between tables • Tables have a key • Is it an attribute or an entity? ORDER Customer order number Item description Item Price Quantity ordered Customer number Item number Customer number Customer name Customer address Customer balance Customer special rate 1 2 3 4 Item Item number Item description Item cost Quantity on hand * compulsory attributes 0 optional attributes Normalisation • Process of simplifying the relationships amongst data items as much as possible (see example provided handout) • Through an iterative process, structure of data is refined to 1NF, 2NF, 3NF etc. • Reasons for normalisation: – to simplify retrieval (speed of response) – to simplify maintenance (updates, deletion, insertions) – to reduce the need to restructure the data for each new application First Normal Form • design record structure so that each record looks the same (same length, no repeating groups) • repetition within a record means one relation was missed = create new relation • elements of repeating groups are stored as a separate entity, in a separate table • normalised records have a fixed length and expanded primary key Second Normal Form • Record must be in first normal form first • each item in the record must be fully dependent on the key for identification • Functional dependency means a data item’s value is uniquely associated with another’s • only on-to-one relationship between elements in the same file • otherwise split into more tables Third normal form • to remove transitive dependencies • when one item is dependent on an item which is dependent from the key in the file • relationship is split to avoid data being lost inadvertently • this will give greater flexibility for the design of the application + eliminate deletion problems • in practice, 3 NF not used all the time speed of retrieval can be affected Beyond data modeling • Model must be normalised – Optimised model – “no surprise” model – resilience • Outcome is a set of tables = logical design • Then, design can be warped until it meets the realistic constraints of the system • Eg: what business problem are we trying to solve? – see handout [riccardi p. 113, 127] Realistic constraints • Users cannot cope with too many tables • Too much development required in hiding complex data structure • Too much administration • Optimisation is impossible with too many tables • Actually: RDBs can be quite slow! Key practical questions • What are the most important tasks that the DB MUST accomplish efficiently? • How must the DB be rigged physically to address these? • What coding practices will keep the coding clean and simple? • What additional demands arise from the need for resilience and security? Analysis - Three Levels of Schema External Schema 1 External Schema 2 External Schema … Tables Disk Array Logical Schema Internal Schema 4 way trade-off Security Ease of use Performance Clarity of code Key decisions • Oracle offers many different ways to do things – Indexes – Backups… • Good analysis is not only about knowing these => understanding whether they are appropriate • Failure to think it through => unworkable model • Particularly, predicting performance must be done properly – Ok on the technical side, tricky on the business side Design optimisation • Sources of problems: – Network traffic – Excess CPU usage • But physical I/O is greatest threat (different from logical I/O) • Disks still the slowest in the loop • Solution: minimise or re-schedule access • Also try to minimise the impact of Q4 (e.g. mirroring, internal consistency checks…) Using scenarios for analysis • • • • Define standard situation for DB use Analyse their specific requirements Understand the implications for DB design Compare and contrast new problems with old ones Categories of critical operations • Manual transaction processing = complex DE by small number of operators • Automatic transaction processing: large number of concurrent users performing simple DE • High batch throughput: automatic batch input into DB of very large number of complex transactions • Data warehousing: large volumes of new data thrown on top every day at fixed intervals + intensive querying Manual transaction processing • Insurance telemarketing broker – Data entry – Retrieving reference info – Calculations • On-line human-computer interaction!! – Instant validation (field by field) – Drop-down lists (DE accelerators) • Quick response time • Critical issue = user-friendly front end, but minimise traffic between interface and back end! Automatic transaction processing • Large number of user performing simple tasks • Real-time credit card system (e.g. authorisation) or check out (EPOS) • Human interaction at its most simple – eg typing a code or swiping a card • Minimum validation, no complex feed back… • Large numbers mean potential problems are: – Connection opening / closing rate – Contention between concurrent users – SQL engine pbs + data consistency costs • Design with multiple servers Automatic transaction processing • Another eg: on-line shopping • What specific problems would arise from shopping cart type applications? • How do you handle lost customers? High batch throughput • Eg mobile phone network operator • Real time + huge volume of simultaneous complex transactions – – – – Number checks Account info Price info Pattern checks • Large processing capacity required + need to tackle all transactions together in batches – DB query may not be only solution (or quickest) – Move customer account to cache – Copy updated figures for accounts to a log and updated accounts in slack periods (2.5GB an hour!) “Data warehouse” • Huge store of data • Large volume added every day – 99% new data, 1% corrections to existing data • Substantial analysis required prior to development: – What to include – How to aggregate and organise it – Where data comes from • Real Oracle territory because schedule is lax – ie not a real time application • Key issues: – Getting partitioning right – Deciding how many summary levels Partitioning • Oldest trick in the book to speed up retrieval (eg?) – Smaller bunch of data – Well labeled so it can be easily found – Smaller index • Data manipulation – maintenance, copy and protection far easier • Break down big problem (eg table) into small ones Internet Databases • In between types 1 and 2 – Many concurrent sessions – Reduced interaction front end back end – Internet = Extra response time (2 secs!) • In practice, many sites are quite slow • Key issues – “thin client” – Reduced dialogue – Management of sessions (eg coockies) to avoid multiple restarts Conclusion: Key issues • At one end: very large numbers of small transactions • Threat of network or process contention • At other end: small number of processes with complex data crunching and time constraints • Design of DB and application must reflect these constraints