Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
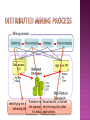
Spiros Papadimitriou Jimeng Sun IBM T.J. Watson Research Center Hawthorne, NY, USA Reporter: Nai-Hui, Ku Introduction Related Work Distributed Mining Process Co-clustering Huge Datasets Experiments Conclusions Problems Huge datasets Natural sources of data are impure form Proposed Method A comprehensive Distributed Co-clustering (DisCo) solution Using Hadoop DisCo is a scalable framework under which various co-clustering algorithms can be implemented Map-Reduce framework employs a distributed storage cluster block-addressable storage a centralized metadata server a convenient data access storage API for Map-Reduce tasks Co-clustering Algorithm cluster shapes checkerboard partitions single bi-cluster Exclusive row and column partitions overlapping partitions Optimization criteria code length Transform rawVisual data into results, or turned Identifying the source and the appropriate intoformat the input for other obtaining the data for data analysis applications. Data Processing 350 GB raw network event log pre-processing Needs over 5 hours to extract source/destination IP pairs Achieve much better performance on a few commodity nodes running Hadoop Setting up Hadoop required minimal effort Specifically for co-clustering, there are two main preprocessing tasks: Building the graph from raw data Pre-computing the transpose During co-clustering optimization, we need to iterate over both rows and columns. Need to pre-compute the adjacency lists for both the original graph as well as its transpose Definitions Matrices are denoted by boldface capital letters Vectors are denoted by boldface lowercase a letters aij:the (i, j)-th element of matrix A Co-clustering algorithms employs a checkerboard and overview the original adjacency matrix a grid of submatrices An m x n matrix, a co-clustering is a pair of row and column labeling vectors r(i):the i-th row of the matrix G: the k×ℓ group matrix A gpq gives the sufficient statistics for the (p, q) sub-matrix Map function Reduce function Global sync Setup 39 nodes Two dual-core processors 8GM RAM Linux RHEL4 4Gbps Ethernets SATA, 65MB/sec or roughly 500 Mbps The total capacity of our HDFS cluster was just 2.4 terabytes HDFS block size was set to 64MB (default value) JAVA Sun JDK version 1.6.0_03 The pre-processing step on the ISS data Default values 39 nodes 6 concurrent maps per node 5 reduce tasks 256MB input split size Using relatively low-cost components I/O rates that exceed those of high-performance storage systems. Performance scales almost linearly with the number of machines/disks.