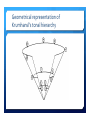
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Language and Music Cognition Elizabeth W. Marvin (Eastman School of Music)) Language and music – commonalities? Ê What do language and music share? Ê In the auditory signal? (phonological level) Ê In the underlying structure? (syntactical level) Language and music – commonalities? Ê What do language and music share? Ê In the auditory signal? (phonological level) Ê In the underlying structure? (syntactical level) Ê Anything else? Ê Auditory demonstration – speech to music…. Ê (D. Deutsch, 2003) Composition: speech to music Ê Steve Reich, “The Cave” -‐ the composer interviewed people about holy sites. Then took the pitches and rhythms of speech and composed music based on them. Ê Added repetitions and accompanying instrument parts Ê Speech: “The Midrash says Adam and Eve were buried there” Temporal aspects of music: Rhythm and meter Ê Definitions of rhythm and meter? Ê Meter is hierarchical system of equally spaced pulses or beats that create expectations of strong/weak beats (groupings in twos or threes; e.g., march or a waltz) Ê Crucial to perceiving meter is the ability to entrain to a beat; to infer a beat from musical stimulus Ê At one time, beat perception was thought to be unique to humans à but is present in vocal-‐learning species Vocal learning and beat entrainment Beat entrainment in animals argues against music as evolutionary adaptation Ê For traits to qualify as adaptations : Ê Innate – genetically encoded Ê Uniquely human – adaptive to humans (separated from evolutionary predecessor) Ê Specific to music – functions for music (not some related trait) McDermott & Hauser (2005) Ê Beat entrainment in non-‐human animals suggests that musical rhythm is not an evolutionary adaptation; since found in animals Ê Beat entrainment also may not be “specific to music” but instead serves speech (vocal learning) An aside: Vocal learning – the lyrebird Beat entrainment àmeter perception Ê Hierarchical framework with recurring beats at different simultaneous levels (or beats and beat divisions) Ê Beats at each level are roughly equally spaced Meter = hierarchy of expectations Ê Meter inferred from various kinds of cues in the music – “phenomenal accents” – loud notes, long notes, etc. Ê But once established, meter has inertia – it keeps going on its own (in the listener’s mind) Ê Musical accents need not always reinforce it and may even conflict with it (syncopation) Ê • • • • • • (beat) Ê • • • • • • • • • • • • (division) Ê •••• •••• •••• •••• •••• •••• (subdivision) Meter facilitates cognition Ê Patterns that strongly reinforce a single meter are more easily learned than those that are ambiguous (Povel & Essens 1985) Ê Both are 9 attacks, 4 beats Ê . . . . (beats) Ê |||||..||.|.|... (easy) Ê ||.|.|||.||.|... (hard) Meter also “tunes” attention Ê Tone Comparison tone Ê Dynamic Attending Theory: Task is to judge whether the comparison tone is the same pitch as the standard, where interfering tones set up meter (Jones et al, 2002). Ê Listeners are better at this task if the last tone falls squarely on the beat. Attention is focused, affects accuracy judgment. Dynamic attending theory Ê Best accuracy when pitch appears on the beat; metric timing affects pitch perception Experiment 1: Expectancy Profile Proportion Correct 0.8 0.75 0.7 0.65 0.6 0.55 0.5 Very Early Early On Time Late Onset Time of Comparison Very Late What about meter in speech? Ê Stress in language is often represented using metrical grids similar to music x (e.g., Lerdahl & Jackendoff, 1983) x x x x x x x x x x x x x Take me out to the ball game Ê Cues to stress in language are similar to “phenomenal accents” cues in music: loudness, length, pitch, and word duration all can create linguistic stress Is there regularity in linguistic stress? Ê Metrical grids in language are frequently irregular (see previous slide), but what about timing of syllables? Ê We’ll “pause” the lecture here, and talk about Patel & Daniele (2003) Ê Linguists used to distinguish between two types of linguistic timing – what are they? Is there regularity in linguistic stress? Ê Linguists used to distinguish between: Ê “syllable-‐timed” languages (with evenly spaced syllables— e.g. French, Italian), and Ê “stress-‐timed” languages (with evenly spaced stresses— e.g. English, German, Dutch ). Ê Stress-‐timed languages shorten some words to maintain equal timing between stresses Ê This results in more variability in word length in speech Is there regularity in linguistic stress? Ê But in fact, studies show that in supposedly “stress-‐timed” languages (like English), inter-‐stress intervals are quite irregular (Dauer, 1983). Ê Even so, the distinction seems to capture something that sounds different in these languages Ê QUESTION: is the difference in rhythmic structure of the languages reflected in the rhythms of the national music? Rhythmic influences of language on music? (Patel & Daniele, 2003) Analysis of rhythm in language and music Ê Measured “normalized pairwise variability index” for each pair of durations in a wide selection of French/English music Ê Quarter-‐note = 1; others fractions or multiples Findings: English, higher variability (just as in language) Findings: clusters composers by rhythmic practices Turning to melody and prosody Ê Patel (2005): similar study with English/French sentences and melodies Ê Sample analysis of pitch in speech (Praat “prosogram”) Measurements in the pitch domain Ê Prosogram (for speech) Ê Gives raw fundamental frequency (F0) contour of sentence in time-‐weighted averages; mostly discrete pitches, few glides Ê Graphed in semitones to compare speech with melody Ê Looked at pairwise variability of melodic intervals Ê Again, measuring variability Ê Hypothesis: English speech and music have more pitch variability than French speech and music Patel’s Results: Coefficient of Variability Rhythm, meter, and… Grouping in language and music Ê Lerdahl & Jackendoff (1983) -‐ A Generative Theory of Tonal Music – Separated grouping from rhythm: new. Develop grouping rules (based on Gestalt principles). Grouping preference rules Ê Lerdahl & Jackendoff: Ê GPR2 (Proximity): Consider a sequence of four notes n1 n2 n3 n4. All else being equal, the transition from n2– n3 may be heard as a group boundary if the interval of time from the end of n2 to the beginning of n3 is greater than that from the end of n1 to the beginning of n2…. n1 n2 n3 n4 Ê So 1 and 2 group together, as do 3 and 4. Is this type of grouping universal? Auditory grouping and universality Ê Iambic-‐Trochaic law (Hayes, 1995) Ê (1) A louder sound tends to mark the beginning of a perceptual group (trochee) Ê (2) A lengthened sound tends to mark the end of a group (iamb; see also Lerdahl & Jackendoff GPR2) Ê Are these universal grouping principles? Ê Amplitude (trochee) Duration (iamb) Two challenges: (1) language influence Ê Group differences in duration grouping (Iverson, Patel, & Ohgushi, 2008) Ê English speakers preferred short-‐long grouping Ê Japanese speakers showed no preference as a group but individuals grouped long-‐short more often than short-‐long Ê Researchers believe language influences grouping Ê English is head-‐complement language; Japanese is the opposite Ê Functor-‐content à “the book” = short-‐long grouping Ê Content-‐functor à “hon ga” = long-‐short grouping Two challenges: (2) music training Bixby, Marvin, and McDonough, 2012 Turning to the pitch domain…. Ê Syntax in music Ê Not all pitches have equal strength in a key; some are viewed as stable and others as unstable Ê Pitches are viewed as having different “functions” but no direct mapping to language: tonic is noun, dominant is verb…. Ê But the means by which we learn tonal and linguistic hierarchies may be related à statistical learning. Experimental data on hierarchy (Krumhansl & Shepard, 1979) Tone probe technique: Given a context, rate the tone from 1-‐7 on how well it completes the sequence (7 is best completion) Many replication studies Ê Harmonic context given (four chords); with a new key each trial Ê How well does the probe tone “fit” within the context of the chords given? Ê Rate from 1 (low) to 7 (high). Let’s try two – which one gets a higher rating? (More closely related?) Resulting “tone profile” – not all tones are perceived as having equal stability Geometrical representation of Krumhansl’s tonal hierarchy Listener responses correspond well with tallies of pitch classes in music repertoire Ê Diagram below: pitch-‐class tallies of scale degrees in opening of Haydn/Mozart string 4tets (Temperley) Ê Temperley’s work: views tallies as probability distributions: at any moment, 25% chance of hearing tonic; almost no chance of hearing #1, etc. 0.3 0.25 0.2 0.15 0.1 0.05 0 1 #1/b2 2 #2/b3 3 4 #4/b5 5 #5/b6 6 #6/b7 7 0.223 0.006 0.12 0.003 0.154 0.109 0.019 0.189 0.007 0.076 0.005 0.089 Listeners learn these statistics implicitly from every-‐day listening Ê Do listeners use a distributional strategy in key-‐finding? That is, determining the tonic note of a piece “by ear” Ê Temperley & Marvin (2008) Ê Give listeners melodies that are generated randomly from a “correct” major or minor key’s pitch-‐class distribution: only distributional information is present (no familiar melodic patterns, quasi-‐random order except for distributional information) Ê People sing & identify tonic (keyboard) and mode (major or minor) Stimuli Ê 60 “distributional” melodies Ê Generated from pitch-‐class distributions drawn from Mozart and Haydn string 4tets (1st 8 mm) Ê Melodies mirror the distributions, do not begin-‐end on tonic, no cadential formulas, no repeated motives – random within distribution Results Ê Performance at above-‐chance levels, but not as strong as we had hoped Ê Zeroth-‐order probabilities alone do not account for key-‐ finding by listeners Ê We may need information 1st order or transitional probabilities between pitches (given this pitch, which pitch likely follows next) or other learned tonal cues What does this have to do with language cognition? Ê We know from research that asks listeners to learn words in an artificial language that our brains track the statistics of which syllables appear together (transitional probabilities) Ê Researchers at UR have shown statistical learning generalizes across domains to language, pitch, vision, etc. (e.g., Saffran, Johnson, Newport, & Aslin, 1999) Ê Makes sense that similar mechanisms are at work in processing music; currently an active area of research Statistical learning and expectation Ê Look at 1st-‐order probabilities of which tones follow others in major keys Ê Thicker line = higher probability: 3-‐2, then 5-‐5, then 5-‐4, 2-‐1 Ê 5-‐4-‐3-‐2-‐1 Ê We track these patterns and they inform our expectations musical syntax Do language and music share neural processing? Or are they distinct? Ê Domain-‐specific hypothesis (processed by the brain separately) supported by instances of double dissociation: two clinical cases, one has amusia without aphasia; the other has aphasia without amusia Ê Aphasia (language deficit, often by stroke) may leave musical ability unimpaired Ê Amusia (“tone deafness”), usually spares language Ê If one perceptual ability is intact while the other is impaired, they must activate a different location in the brain Amusia and pitch processing Ê Amusia is a disorder of small interval pitch processing (cannot distinguish whole/half steps, or contour up/down) Ê Since most melodies are comprised of small intervals, there is no opportunity for statistical learning of transitional probabilities (can’t hear the difference between intervals) Ê Famous amusics: Amusia and pitch processing Ê Amusics CAN discriminate pitch changes in speech but fail when given a pitch analog (Patel et al, 2005) Ê WHY MIGHT THIS BE? Ê Sentences Pitch Analog Pitch w/glide Amusia: Perception-‐Action Mismatch Ê Loui et al (2008) asked amusic subjects to sing back an interval played, and then to judge its direction (up or down) Ê Amusics were unable to judge pitch direction, even when they sang back the correct contour Ê They find intact (but imprecise) ability in production, despite impaired perception -‐-‐ but no impairment in perceiving and producing speech Patel disagrees with the domain-‐specific hypothesis Ê Patel believes that syntactic aspects of language and music are processed together (but stored separately) – storage difference accounts for double dissociation. Ê His experiments focus on musical and linguistic syntax. Ê Syntax: Set of principles governing the combination of discrete structural elements (words or musical tones) into sequences by combinatorial principles that operate at multiple levels. Aphasia and syntax Ê Tested aphasics on musical and linguistic syntax Ê Hypothesis: Participants with impaired language syntax will show impaired music syntax Ê Rather than showing different areas of the brain at work for language and music, this would show shared processing of syntactical understanding Testing linguistic syntax Ê Testing syntax in language: sentence-‐picture matching task Ê Tested/compared aphasic patients and controls Music syntax – priming test Ê Priming test: Ê Presented with a context, then giving a “speeded” task Ê Reaction times faster when target is related to the context; tests influence of preceding harmonic context on processing of target chord Ê Task: Two chords (close or distant on circle of fifths); is the 2nd chord is “in tune” or not? Findings Ê Hypothesis confirmed: Aphasics with syntactic comprehension problems in language also had a music syntactic deficit Ê Patel: aphasia is a processing disorder; a problem activating stored syntactic representations rather than a language-‐ specific disruption. Ê Supports his theory that music and language are stored separately, but processed together. Double dissociation is due to separate storage areas. Other evidence for shared processing Ê In vocal music, stressed syllables are almost always set on metrically strong beats. Difficulty when stresses are displaced suggests that we’re unable to apply independent metrical grids to music and language simultaneously. Ê The “shifted” version of “Take Me Out to the Ball Game” is difficult to process (try singing it!) Music and Language Syntax… Younger subjects Time permitting…. Evolution of music and language Ê Returning to Diana Deutsch and the thin distinction between speech and song (“they sometimes behave so strangely”) Ê She believes that this “fuzzy boundary” between speech and song is an evolutionary relic – that human ancestors did not have such a boundary between the two Ê They spoke a “protolanguage” (Darwin’s theory) that was neither language nor music, and that each evolved separately out of this early protolanguage Ê Steven Mithen, The Singing Neanderthals Mithen on music/language evolution Thank you! Ê Questions?