Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Measures of
Location
and
Variability
Spring, 2009
Skill set:
You should know the definitions of the major measures of location (mean, median,
mode, geometric mean) and variability (standard deviation, variance, standard error of
the mean, skewness and kurtosis).
You should know:
Set of Observations
xi
xi + c
cxi
Mean
x
x+c
cx
Variance
s2
s
s2
s
c2 s2
Descriptive Statistic
Standard deviation
c
cs
Means the absolute value of c.
You should be able to use Stata to graph histograms and box plots. You should know
how to use the help menu.
Outline
Scales of measurement
Page 1
Measures of Location
Mean
Median
Mode
Geometric Mean
Properties of Means
Page 2
Page 7
Page 9
Page 10
Page 15
Stata commands used:
Dropdown menus
log using
describe (des)
summarize (sum)
generate (gen)
codebook
label
display (di)
list
ameans
Page 25
Measures of spread or variability
Range
Percentiles
Interquartile range
Variance
Standard deviation
Standard error of the mean
Kurtosis
Skewness
Page 30
Page 30
Page 32
Page 33
Page 34
Page 34
Page 35
Page 35
Definition of whiskers
Page 36
Drop down menus
Box Plots
Page 38
Dataset used:
weight.dta
Scales used with data:
Four scales are used with variables: nominal, ordinal, interval and ratio.
nominal - the variable has no order, just category names
Gender (male, female) and hypertensive (yes, no) are examples
ordinal - the variable can be rank ordered but there is no consistent distance between
the categories
Income scaled as low, medium and high is an example. We know that
someone in the category low has a smaller income than someone in the
category high but we don’t know how much smaller.
Is the distance between low and medium the same as the distance between
medium and high? We just know the order not the difference or distance
between categories.
interval and ratio - both of these are scales of equally spaced units (i.e. consistent
distances) like height in inches.
A difference between the two scales is that variables on the ratio scale have a
zero point that can be interpreted as there is none of the quantity being
measured but variables on the interval scale do not have such a zero point.
Height is on the ratio scale and 0 inches tall means there is no height.
The Celsius scale is on the interval scale but not the ratio scale. Zero
degrees Celsius does not mean there is no heat.
In order to be on the ratio scale, the ratio of two numbers has to make sense.
A person 140 cm tall is twice as tall as one 70 cm tall. An oven at 300
degrees Celsius is not twice as hot as one at 150 degrees Celsius.
Measures of location:
We will consider several measures of location. The mean, which we consider first, is
the most commonly used measure of location.
Page -1-
Mean:
If the sample consists of
n points x1 , x2 , x3 ,..., xn , then the mean ( x )
is defined as
n
∑ xi
x1 + x2 + x3 +...+ xn
n
n
This is just the arithmetic mean of the n values. In order to calculate a mean, the
x=
i =1
=
variable has to be at least on the interval scale.
We will create and use the small data set “smalldbp.dta” with the diastolic blood
pressures of 10 people to illustrate means. We will follow the steps in the picture below.
1)
2)
3)
4)
5)
6)
We click on the log button which opens the “Begin logging Stata output” menu.
We select the folder in which we wish to save our log file (i.e. “Chapter2").
We tell Stata we want a “log” type of log file rather than the “smcl” type of log file.
We give our log file a name (smalldbp.log)
We save our log file to “Chapter2"
The results of 1 - 5.
Page -2-
6)
. log using "W:\WP51\Biometry\AAAABiostatFall2007\Data\Chapter2\smalldbp.log"
-----------------------------------------------------------------------------log: W:\WP51\Biometry\AAAABiostatFall2007\Data\Chapter2\smalldbp.log
log type: text
opened on: 29 Aug 2007, 18:49:36
“log on (text)”
tells you that you have a log file
running and that it is text as
opposed to smcl
We are going to enter our data using the data editor. Entering data here is just like
entering data in Excel.
(1) I click on the data editor button (the highlighted button below) and that brings up the
Data Editor menu. I then just type in an ID variable and 10 diastolic blood pressures
(DBP). (2) I preserve the data so I won’t lose it and (3) close the data editor because
Stata won’t let me type on the command line if the data editor is open
In the Introduction to Stata handout I show you how to use the dropdown menus to give
the variables names other than var1 and var2 and to give the variables descriptive
Page -3-
labels. Here I am just going to type in the appropriate commands on the command line.
- preserve
. rename var1 id
. label variable id "Unique Identifier"
. rename var2 dbp
. label variable dbp "Diastolic Blood Pressure in mm Hg"
. des
Contains data
obs:
10
vars:
2
size:
60 (99.9% of memory free)
------------------------------------------------------------------------------storage display
value
variable name
type
format
label
variable label
------------------------------------------------------------------------------id
byte
%8.0g
Unique Identifier
dbp
byte
%8.0g
Diastolic Blood Pressure in mm
Hg
------------------------------------------------------------------------------Sorted by:
Note: dataset has changed since last saved
“des” is short for describe.
The mean diastolic pressure of these 10 people is:
10
x=
∑ xi
i =1
10
90 + 85 + 100 + 87 + 92 + 78 + 80 + 96 + 93 + 99
=
10
900
=
= 90.0
10
It is customary to write the value for the mean to one more decimal place than the
original data. The original DBP’s are integers so I report the mean of the DBP’s as
90.0. We usually report the standard deviation to two decimal places beyond the
original data (7.51).
Page -4-
The easy way to get the mean is to just type in “sum dbp” or for more information type
“sum dbp, det” where sum is short for summarize and det is short for detail. The
results are below.
. sum dbp
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------dbp |
10
90
7.512952
78
100
. sum dbp,det
Diastolic Blood Pressure in mm Hg
------------------------------------------------------------Percentiles
Smallest
1%
78
78
5%
78
80
10%
79
85
Obs
10
25%
85
87
Sum of Wgt.
10
50%
75%
90%
95%
99%
91
96
99.5
100
100
Largest
93
96
99
100
Mean
Std. Dev.
90
7.512952
Variance
Skewness
Kurtosis
56.44444
-.248569
1.914099
To use dropdown menus to do the same thing see the back of this handout.
Graph #1 based on original set of 10 DBP values.
Page -5-
The mean can be thought of as the center of gravity (if you have weights of equal size
hanging off each sample point, the mean would be the balance point.).
Advantages of using the mean:
it uses all the observations in the sample
each sample has a unique mean
A disadvantage of using the mean is that it is sensitive to extreme values (and the
smaller the sample, the more impact the extreme values have).
Below I create a new variable which is equal to the old variable dbp except the value 99
is changed to 130 (we’ll call this set of 10 values the newdbp). Note that this changes
the mean of the sample from 90.0 to 93.1 (see graph below to understand how the
center of gravity has changed just by changing one value).
. gen newdbp = dbp
. replace newdbp = 130 if dbp == 99
(1 real change made)
“gen” is short for generate
. sum newdbp
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------newdbp |
10
93.1
14.64734
78
130
Graph #2 is based on the set of 10 DBP values with 99 replaced by 130.
Page -6-
Notice that the mean is pulled from 90.0 to 93.1 (i.e. the mean is pulled toward the
outlying value).
. save smalldbp.dta
file smalldbp.dta saved
. log close
log:
log type:
closed on:
W:\WP51\Biometry\AAAABiostatFall2007\Data\Chapter2\smalldbp.log
text
29 Aug 2007, 20:29:53
The largest value for baseline cholesterol in the dataset weight.dta is 412. Try changing
that to 1500 and comparing the mean of the original sample with the mean of the
changed sample. Notice that there are 10,273 participants with baseline cholesterol
values but there are 10,355 participants in the dataset.
The way to create the new DBP variable with dropdown menus is given at the back of
the handout.
When we study the Central Limit Theorem, we will find that the mean has some nice
properties that allow us to get confidence intervals and do hypothesis testing.
The type of data needed to calculate a mean is interval (i.e. you have to have the ability
to divide and still have a legitimate observation). So we calculate means for variables
such as age and diastolic blood pressure (i.e. continuous variables).
Median:
If the sample contains an odd number of observations, the median is the middle
observation provided the sample is ordered from smallest to largest.
If the sample contains an even number of observations, the median is the average of
the two middle observations given that the sample is ordered from smallest to largest.
You can see that this definition makes the median such that an equal number of points
are greater than or equal to and less than or equal to the median.
An advantage for the median over the mean is that the median is not sensitive to
extreme values. Notice that both the variable dbp and the variable newdbp have the
same median, but not the same mean. The median is the 50th percentile.
Median
Mean
dbp
91
90.0
newdbp
91
93.1
Page -7-
. sum(dbp),det
(original set of 10 values for DBP)
Diastolic Blood Pressure (dbp)
------------------------------------------------------------Percentiles
Smallest
1%
78
78
5%
78
80
10%
79
85
Obs
10
25%
85
87
Sum of Wgt.
10
50%
75%
90%
95%
99%
91
96
99.5
100
100
Largest
93
96
99
100
Mean
Std. Dev.
90
7.512952
Variance
Skewness
Kurtosis
56.44444
-.248569
1.914099
Note that in the Stata output below the 50th percentile is the median and that although
the largest value changes from 100 to 130 the median remains the same.
. sum(newdbp),det
New version of DBP with 99 changed to 130
------------------------------------------------------------Percentiles
Smallest
1%
78
78
5%
78
80
10%
79
85
Obs
10
25%
85
87
Sum of Wgt.
10
50%
75%
90%
95%
99%
91
96
115
130
130
Largest
93
96
100
130
Mean
Std. Dev.
93.1
14.64734
Variance
Skewness
Kurtosis
214.5444
1.644196
5.212837
Another advantage for the median is that each sample has a unique median.
A disadvantage for the median is that it does not utilize all the data in the sample.
In order to obtain a median, the data has to be on at least the ordinal scale (i.e. you can
order the observations).
When should we use the mean and when should we use the median? The cartoon
below sort of gives the correct answer.
Page -8-
Mode:
The mode is the most frequently occurring value in a set of observations.
A disadvantage for the mode is that not all samples have a mode and some samples
have multiple modes.
Sample 1 = {1,2,3,4,5,6,7,8,9,10} has no mode.
Sample 2 = {1,1,1,2,3,4,4,4,5} has modes 1 and 4.
Sample 3 = {M, F, F, F, M, M, M, F, F, F} has mode F where M = male and F = female.
The mode can be calculated with data on the nominal scale (i.e. all you have to be able
to do is categorize each observation). The mode will not come up again in this course
unless it is in a discussion of a bimodal distribution because it is not amenable to
mathematical manipulation.
Things about logs you have probably long since forgotten. log here can be to any base
(i.e.
log e , log10 )
1)
2)
3)
4)
log(a) is defined only if a > 0.
log(ab) = log(a) + log(b)
log(a/b) = log(a) - log(b)
k
log( a ) = k log( a )
Page -9-
Geometric mean:
If the sample is
x1 , x2 , x3 ,..., xn
x g = n x1 ⋅ x2 ⋅ x3 ⋅⋅⋅ xn
then the geometric mean (
(This is the nth root of the product of sample elements)
xg = ( x1 ⋅ x2 ⋅ x3 ⋅⋅⋅ xn )
This can also be written as
x g ) is defined as
1
n
or as
n
log( x g ) =
∑ log( xi )
i =1
n
The geometric mean turns up when doing such things as dilution assays.
So using our newly remembered facts about logs we have the following:
1
⎛
n⎞
log( x g ) = log⎜ ( x1 ⋅ x2 ⋅ x3 ⋅⋅⋅ xn ) ⎟
⎝
⎠
1
= log( x1 ⋅ x2 ⋅ x3 ⋅⋅⋅ xn )
n
=
log( x1 ) + log( x2 ) + log( x3 ) + ⋅⋅⋅ log( xn )
n
n
=
∑ log( x )
i
i=1
n
So we have that the mean of the logs is the log of the mean.
Rosner gives a good example of the use of the geometric mean on pages 14 and 15,
Table 2.4.
Page -10-
The geometric mean is more appropriate than the arithmetic mean in the following
circumstances:
1) When losses/gains can best be expressed as a percentage rather than a fixed value.
2) When rapid growth is involved, as in the development of a bacterial or viral
population.
3) When the data span several orders of magnitude as with a concentration of
pollutants.
Taken from Common Errors in Statistics 2nd edition by Good and Hardin.
The most commonly used of the above measures of location is the mean with the
median second because it is used in non-parametric analyses.
Question:
Why would the CMS (Center for Medicare and Medicaid Services) present the
geometric mean to summarize the length of hospital stay.
Note that this doesn’t fit any of the reasons given above. It has to do with transformed
data.
Below is a small study of the length of hospital stay for 25 patients. The dataset used is
hospital.dta which is a file that is also used in the Introduction to Stata. hospital.dta is
on the class website.
Page -11-
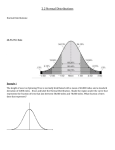
The distribution of a variable is said to be symmetric if the pieces on either side of the
center point are mirror images. Otherwise the distribution is described as skewed. If
the distribution is symmetric the skewness value given in the detailed version of the
command summarize is zero.
The variable length of hospital stay is skewed to the right (also described as positively
skewed). Notice that the skewness value is 2.2 . A positive skewness value (i.e. value
> 0) indicates that the skewness is to the right (see the histogram of hospital stay
above). A negative skewness value indicates the distribution is skewed to the left.
Individuals who have much longer hospital stays than most of the other patients is very
common for length of stay data.
. sum stay,det
Length of hospital stay in days
------------------------------------------------------------Percentiles
Smallest
1%
3
3
5%
3
3
10%
3
3
Obs
25
25%
5
4
Sum of Wgt.
25
50%
75%
90%
95%
99%
8
11
14
17
30
Largest
11
14
17
30
Mean
Std. Dev.
8.6
5.715476
Variance
Skewness
Kurtosis
32.66667
2.203535
8.959067
This is a case where the value 30 days is probably correct so we can’t just set it to
missing. One thing that we can do is transform the data to bring the 30 days closer to
the rest of the data. One of the transformations which will bring in the larger values is
the natural (i.e. base e) logarithmic transformation (log to base 10 will also bring in the
more distant data). To get the log transformation we simply generate a new variable
that is equal to log base e of the variable stay.
. gen logofstay = log(stay)
. label variable logofstay "The natural logarithm of the variable length of hospital
stay"
You can also use ln(stay) to get the log base e of stay. To get the log base 10 you use
log10(stay). The things about logs that we’ve probably long since forgotten are true
regardless of the base.
Notice in the histogram below that the log transformation has pulled the largest value in
nearer the other values.
Page -12-
Histogram 2 above is the graph of the natural logarithm of the variable stay, so the log
of the geometric mean of stay will equal the arithmetic mean of the variable logofstay.
. ameans stay
Variable |
Type
Obs
Mean
[95% Conf. Interval]
-------------+---------------------------------------------------------stay | Arithmetic
25
8.6
6.240767
10.95923
| Geometric
25
7.303239
5.774765
9.236272
|
Harmonic
25
6.308454
5.148257
8.143695
-----------------------------------------------------------------------. ameans logstay
Variable |
Type
Obs
Mean
[95% Conf. Interval]
-------------+---------------------------------------------------------logstay | Arithmetic
25
1.988318
1.753498
2.223138
| Geometric
25
1.907722
1.685849
2.158796
|
Harmonic
25
1.8248
1.613525
2.09974
-----------------------------------------------------------------------. di log(7.303239)
1.9883179
Or the antilog of the arithmetic mean of the variable logstay is the geometric mean of
the variable stay.
. di exp(1.988318)
7.3032394
The antilog in this case is the inverse of the log function which is the exponential
x
function (i.e.
where
).
e
e = 2.7182818
Page -13-
So what does the log transformation do?
If the ratios of two pairs of points are equal then on the log scale the distance between
the two members of a pair is the same for both pairs.
10 = 1
100 10
so
10 ⎞⎟
1
= log⎛⎜ ⎞⎟
log⎛⎜
⎝ 100⎠
⎝ 10⎠
but
10 ⎞⎟
1
= log⎛⎜ ⎞⎟ = log(1) − log(10)
log(10) − log(100) = log⎛⎜
⎝ 100⎠
⎝ 10⎠
So we have
. di log(10/100)
-2.3025851
. di log(1/10)
-2.3025851
. di log(1) - log(10)
-2.3025851
. di log(10) - log(100)
-2.3025851
So instead of having 1 and 10, 9 units apart while 10 and 100 are 90 units apart both
are 2.3 units apart on the natural log scale.
So the short answer to why CMS presents the geometric mean is to lessen the
influence of outlying values.
Page -14-
Properties of means:
Property 1:
Sometimes we wish to rescale the elements of our sample. For example, we may have
collected the weight of our participants in pounds and now we are going to publish our
paper in a journal that requires the weight to be reported in grams.
The data file we are using is “weight.dta”. I double (left) clicked on the data set weight
which was stored on the W drive and the file opened in Stata. In the “use” statement
below from the “W” to “weight.dta” gives the path to find the data set. When we open a
data set in this fashion, Stata will store any log file we create in the same folder where
the dataset was stored.
Page -15-
There are several properties that I would like you to notice about the file above:
1)
2)
3)
The file is sorted by the variable weight. This means if I list the variable weight,
the smallest weight will be listed first and the largest weight will be listed last.
Each variable has a variable label describing the data the variable contains.
The categorical variables have value labels.
Notice in the description above that the number of observations is given as 10,355 but
the summary of weight below says there are 10,341 values for weight.
. sum weight
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------weight |
10341
183.1275
39.37125
54
392
If I use the command codebook, we can see that there are 14 missing values for weight.
. codebook weight
-----------------------------------------------------------------------------weight
Weight (lbs) at Baseline
-----------------------------------------------------------------------------type:
numeric (float)
range:
unique values:
[54,392]
262
mean:
std. dev:
183.127
39.3713
percentiles:
10%
136
units:
missing .:
25%
156
50%
180
1
14/10355
75%
206
90%
234
We know that 1 pound = 453.26 grams. So let us create a new variable called
“wtingms” that is the baseline weight in grams.
. gen wtingms = weight*453.26
(14 missing values generated)
. label variable wtingms “Weight in grams”
Note that wtingms is missing 14 values because weight is missing 14 values (i.e.
missing × 453.26 = missing). Stata uses the period to represent missing data.
Page -16-
Below I used the command “list” to list the values of weight and wtingms for the last 19
participants (when the data is ordered by weight) which includes the 14 people with
missing values for wtingms. “noobs” asks that Stata not to number the rows.
. list id weight wtingms
if weight >= 364,noobs
+---------------------------+
|
id
weight
wtingms |
|---------------------------|
| 10337
364.00
164986.6 |
| 10338
370.00
167706.2 |
| 10339
382.00
173145.3 |
| 10340
392.00
177677.9 |
| 10341
392.00
177677.9 |
|---------------------------|
| 10342
.
. |
| 10343
.
. |
| 10344
.
. |
| 10345
.
. |
| 10346
.
. |
|---------------------------|
| 10347
.
. |
| 10348
.
. |
| 10349
.
. |
| 10350
.
. |
| 10351
.
. |
|---------------------------|
| 10352
.
. |
| 10353
.
. |
| 10354
.
. |
| 10355
.
. |
+---------------------------+
I have listed the last 19 observations for
weight.
The periods represent missing data.
Since the missing data is listed last, we
know that Stata considers missing values
to be larger than any other values.
The other thing to notice is that
164986.6 = 453.26 × 364
167706.2 = 453.26 × 370
etc.
Below we see that the mean of the wtingms variable is 453.26 times the mean of the
weight variable.
. sum weight
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------weight |
10341
183.12745
39.37125
54.00000 392.00000
. sum wtingms
Variable |
Obs
Mean
Std. Dev.
Min
Max
-------------+-------------------------------------------------------wtingms |
10341
83004.35
17845.41
24476.04
177677.9
. di 453.26*183.12745
83004.348
The “di” above stands for display. The “*” says multiply 183.12745 times 453.26. That
is, I’m using Stata like it is a calculator.
Page -17-
c is a constant (here 453.26), the sample cx1 , cx2 , cx3 ,..., cxn
(wtingms) has mean cx where x is the mean of the sample x1 , x2 , x3 ,... xn
This shows that if
(weight). That is, you can obtain the mean of a sample and then multiply by the
constant or you can multiply each element by the constant and then get the mean.
Property 2:
x1 + c, x2 + c, x3 + c,..., xn + c has mean x + c
x1 , x2 , x3 ,..., xn has mean x and c is a constant.
Sample
if the sample
This says you can add (or subtract) a fixed value to each of the original values and then
get the mean or you can get the mean of the original values and then add (or subtract)
the fixed value.
You will find later when doing regression that people sometimes “center” their data by
subtracting the mean of the variable from each of the original observations. So instead
of putting the original variable in the regression equation, the variable they use is the
original variable minus its mean.
So let’s take a look at what happens when you add a fixed value to each element of a
sample. Let us take the variable chol (this is the baseline cholesterol from the dataset
weight.dta) and add 50 to the baseline value for each of the10273 people who have a
baseline value (i.e. 82 people have missing listed for the baseline value of cholesterol
and missing + 50 = missing).
. sum chol,det
Lipid BL Cholesterol
------------------------------------------------------------Percentiles
Smallest
1%
167
130
5%
181
134.5
10%
189.5
142.5
Obs
10273
25%
205
144
Sum of Wgt.
10273
50%
75%
90%
95%
99%
223
241.5
259
269
288.5
Largest
320.5
322
345
412
Mean
Std. Dev.
223.7146
26.80037
Variance
Skewness
Kurtosis
718.2601
.2067261
3.099006
. gen cholplus = chol + 50
(82 missing values generated)
. label variable cholplus50 "Baseline cholesterol + 50 mg/dL"
Soapbox moment: I recommend always labeling your variables. You think you’ll
remember how the variable is defined, but when you come back to the data six months
later you may find that you’ve forgotten.
Page -18-
. sum cholplus50,det
Baseline cholesterol + 50 mg/dL
------------------------------------------------------------Percentiles
Smallest
1%
217
180
5%
231
184.5
10%
239.5
192.5
Obs
10273
25%
255
194
Sum of Wgt.
10273
50%
75%
90%
95%
99%
273
Largest
370.5
372
395
462
291.5
309
319
338.5
Mean
Std. Dev.
273.7146
26.80037
Variance
Skewness
Kurtosis
718.2601
.2067261
3.099006
So we can see that adding 50 to each baseline value shifts all of the percentiles, the
mean, the minimum and the maximum up by 50 points. Notice that the standard
deviation and the variance (which we will define on later) remain unchanged (this is
because they refer to shape, while the mean and percentiles etc. refer to position). The
skewness and kurtosis (to be defined later) also remain the same because the only
thing we’ve done is to shift the curve up 50 points. See the graphs on the next 2 pages.
Below is the codebook for both chol and cholplus50.
. codebook chol cholplus50
-----------------------------------------------------------------------------chol
Lipid BL Cholesterol
-----------------------------------------------------------------------------type:
range:
unique values:
mean:
std. dev:
percentiles:
numeric (float)
[130,412]
326
units:
missing .:
.1
82/10355
223.715
26.8004
10%
189.5
25%
205
50%
223
75%
241.5
90%
259
-----------------------------------------------------------------------------cholplus50
Baseline cholesterol + 50 mg/dL
-----------------------------------------------------------------------------type:
range:
unique values:
mean:
std. dev:
percentiles:
numeric (float)
[180,462]
326
units:
missing .:
.1
82/10355
273.715
26.8004
10%
239.5
25%
255
Page -19-
50%
273
75%
291.5
90%
309
Below I have created a histogram for each of chol and cholplus50. You can see that the
two histograms below are the same shape. The lower one is just shifted 50 mg/dL to
the right.
600
400
0
200
Frequency
800
1000
Original Baseline Cholesterol
100
150
200
224
250
300
350
400
450
Baseline Cholesterol mg/dL
600
400
200
0
Frequency
800
1000
Baseline Cholesterol + 50
100
150
200
250
273.7
300
350
Baseline Cholesterol mg/dL + 50 mg/dL
Page -20-
400
450
The height of the box (i.e. from
25th to 75th percentile) is called the
interquartile range and it is a
measure of variability.
Lipid BL Cholesterol
Upper whisker
75th percentile
50th percentile
25th percentile
Lower whisker
100
The bottom of the box is the 25th
percentile and the top of the box
is the 75th percentile.
200
The line in the middle of the box
is the median or 50th percentile.
300
400
Box and whisker plots:
Box and Whisker Plot
500
400
300
200
100
Cholesterol for baseline and baseline + 50
Adding a constant changes location but not variability
Lipid BL Cholesterol
Baseline cholesterol + 50 mg/dL
The box plot above shows even more clearly that the distribution is just shifted up
without changing the relationship of the various pieces. So what I’ve worked hard to
show is that adding a fixed number to each unit of a sample changes the location of the
distribution but leaves the shape unchanged. We will discover that multiplying each unit
of a sample by a fixed number changes the shape of the distribution.
Page -21-
Now go back to multiplying the original values by some constant
We’ll generate a new variable which we obtain by multiplying each of the original
baseline cholesterol values by 2.
. gen cholX2 = 2*chol
(82 missing values generated)
. label variable cholX2
"Baseline cholesterol times 2 mg/dL"
Notice below that almost all of the values produced by the summarize command are
multiplied by 2. There are three exceptions. The variance is multiplied by 4 = 22 (we will
later learn the variance = SD2, where SD = standard deviation) and the skewness and
kurtosis are the same as they were for baseline cholesterol (as opposed to being
multiplied by 2). We’ll discuss skewness and kurtosis later.
. sum cholX2,det
Baseline cholesterol times 2 mg/dL
------------------------------------------------------------Percentiles
Smallest
1%
334
260
5%
362
269
10%
379
285
Obs
10273
25%
410
288
Sum of Wgt.
10273
50%
75%
90%
95%
99%
446
483
518
538
577
Largest
641
644
690
824
Mean
Std. Dev.
447.4292
53.60075
Variance
Skewness
Kurtosis
2873.04
.2067261
3.099006
. sum chol,det
Lipid BL Cholesterol
------------------------------------------------------------Percentiles
Smallest
1%
167
130
5%
181
134.5
10%
189.5
142.5
Obs
10273
25%
205
144
Sum of Wgt.
10273
50%
75%
90%
95%
99%
223
241.5
259
269
288.5
Largest
320.5
322
345
412
Mean
Std. Dev.
223.7146
26.80037
Variance
Skewness
Kurtosis
718.2601
.2067261
3.099006
I have created a histogram for each of baseline cholesterol and baseline cholesterol
times 2. In order to compare the 2 graphs they need to be on the same scale. Notice
that the smallest value for cholesterol is 130 mg/dL and the largest for cholesterol times
Page -22-
600
400
0
200
Frequency
800
1000
2 is 824 mg/dl. So I will select the x-axis scale as 125(100)825 for both versions of
cholesterol. 125(100)825 says label the x-axis starting with the smallest value (i.e. 125)
and then going up by units of 100 until you reach 825.
125
225
325
425
525
625
725
825
600
400
200
0
Frequency
800
1000
Baseline cholesterol mg/dL
125
225
325
425
525
625
Baseline cholesterol mg/dL times 2
Page -23-
725
825
200
400
mg/dL
600
800
Baseline cholesterol and baseline cholesterol times 2
Lipid BL Cholesterol
Baseline cholesterol times 2 mg/dL
Looking at the graphs on the previous page and above we see that multiplying by 2 has
changed not only the location (mean) but also the shape. The cholesterol times 2 is
much more spread out (we’ll come back to these graphs when we discuss measures of
variability).
So we’ve learned that adding to the elements of a sample changes only the location but
multiplying changes both the location and the shape. We know that we can measure
location using the mean and median, but we don’t yet know how to indicate (other than
graphically) that the shape has changed.
Page -24-
Menus to get means:
Click on “Submit” to run the command but
leave the menu up so you can make
changes as needed.
Click “OK” just to run the command.
Click on “?” to bring up the help menu for
summarize.
Click on “R” to clear the entries in the
menu.
Page -25-
How to change the values of a variable.
. replace chol = 1500 if chol == 412
(1 real change made)
Page -26-
How to get geometric, arithmetic and harmonic means.
Page -27-
How to get a histogram.
Page -28-
2000
1500
Frequency
1000
500
0
200
250
300
350
cholplus50
Page -29-
400
450
Measures of spread or variability:
Range:
range = largest value - smallest value
Note that codebook gives the range as an interval. Statisticians tend to
use the definition as given so that the range is a single number
Advantage:
This is the simplest measure of spread.
Disadvantage
Very sensitive to extreme values
The range for the baseline cholesterol is 412 - 130 = 282.
If we change the largest value (412) to 550, then the range becomes
550 - 130 = 420
One of the problems with the range is there is a tendency for larger samples, to
have larger ranges.
How does adding 50 to the variable cholesterol or multiplying by 2 change the range.
The range for the baseline cholesterol is 412 - 130 = 282.
The range for the cholesterol + 50 = 462 - 180 = 282.
So these two variables with the same shape also have the same range.
The range for cholesterol times 2 = 824 - 260 = 564 = 2 times the range
of baseline cholesterol.
The range for cholesterol times 2 is twice that of the original cholesterol. We can see
that in the histograms and the box-and-whisker plots in the Chapter 2 Part 1 handout.
Percentiles:
Rosner says that intuitively, the
p th
percentile is the value V p such that p percent of
the sample points are less than or equal to V p . The median is the 50th percentile.
You will also see percentiles called quantiles.
Quartiles are the 25th , 50 th , 75th percentiles
Quintiles are the 20 th , 40 th , 60 th , 80 th percentiles
Deciles are the 10 th , 20 th , 30 th , 40 th , K , 90 th percentiles
Page -30-
Below we can see the change in the 25th, 50th and 75th percentiles as you add a constant
(here 50) to the original cholesterol or multiply the original cholesterol by a constant
(here 2).
Percent
Cholesterol
Cholesterol + 50
Cholesterol x 2
25%
205
205 + 50 = 255
205 x 2 = 410
50%
223
223 + 50 = 273
223 x 2 = 446
75%
241.5
241.5 + 50 = 291.5
241.5 x 2 = 483
Page -31-
Interquartile range:
Interquartile range = value of the
75th
percentile - value of the
25th
percentile
As we saw in the last handout, the interquartile range is the height of the box in
the box plot graph.
Notice below that the values of baseline cholesterol cluster together whereas the
values of baseline cholesterol times 2 are much more spread out. We would like to be
able to describe this variability in a way that uses all of the data as opposed to the
range and interquartile range which use only 2 of the values in the dataset. We’ll call
this new statistic the variance.
Page -32-
Variance:
A first guess at a definition for variance might be
n
guess(1) = ∑ ( xi − x )
i= 1
This definition uses all of the observations in the sample. It also seems reasonable to
use the distance of each observation from the mean as a measure of how spread out the
values are. The problem is that this sum is always equal to zero.
A second guess might be
n
guess(2) = ∑ | xi − x |
i= 1
This second guess solves the problem of the sum adding to zero and it is scaled the
same as the original data. However, this second guess has two problems: (1) is that the
absolute value is mathematically intractable and (2) this sum gets larger as the sample
size gets larger. The second problem could be dealt with by dividing the sum by the size
of the sample, namely .
n
Guess number 3 is to square the difference because the square is easier to deal with
mathematically than the absolute value and it prevents the sum from being zero as the
absolute value did. If we also divide by , then we have provided a correction for the
sample size (i.e. we adjusted the sum of squares so that the sum doesn’t increase just
because the sample size increases).
n
n
guess(3) =
∑ ( xi − x ) 2
i=1
n
The problem with this estimate, which we won’t understand until we learn about biased
and unbiased estimators, is that on the average it is too small (this means if we took a
large number of repeated samples of size
from a given population and averaged all of
the variances from these samples, the average would be smaller than the true variance
n
of the population). To solve this problem we divide by n − 1 rather than .
What we haven’t stated before is that the sample estimate for the variance is intended to
n
Page -33-
estimate the variance of the population from which the sample was drawn.
2
So the variance ( s ) is defined as follows:
n
s2 =
∑ ( xi − x ) 2
i= 1
n −1
The variance of each of the baseline cholesterol and the baseline cholesterol + 50 is
718.26. The variance of the cholesterol times 2 = 2873.04 (i.e. 22 × baseline cholesterol
variance). Notice that the variance is not in the same units as the original data (i.e.
mg2/dL2 versus mg/dL). See the Stata output on page 2.
Standard deviation:
The only problem left with the above definition is that the variance is not in the same
units as the original data. This can be solved by taking the square root of the variance.
The square root of the variance is called the standard deviation and is denoted by s.
We take the non-negative square root so s $ 0.
n
s=
∑ ( xi − x ) 2
i=1
n −1
Standard Error of the Mean:
The standard error of the mean, denoted either SEM or SE is the standard deviation
divided by the square root of
or
n
SE =
s
n
The SE is going to come in handy when we get to confidence intervals and the Central
Limit Theorem. Small preview: The standard deviation ( s ) tells us about the spread for
Page -34-
a single sample. The standard error (SE) is actually the standard deviation of the
distribution of all sample means from samples of size . Notice that the size of the SE
is dependent upon the size of the sample.
n
Kurtosis:
The kurtosis of a distribution describes its peakedness relative to the length and size of
its tails. The kurtosis of the normal distribution is 3. Distributions with values of kurtosis
higher than 3 tend to have sharp peaks and long tapering tails (see the histogram of
triglycerides ). Values lower than 3 indicate distributions that are relatively flat with short
tails.
Users of SAS need to be aware that the value that SAS gives for kurtosis is Stata’s value
minus 3 (i.e. the normal distribution will have a kurtosis of 3 according to Stata and 0
according to SAS).
There are at least two different definitions of kurtosis and SAS and Stata have just
selected different definitions.
Kurtosis = 17.6
Skewness = 1.8
Skewness:
A symmetric distribution is one that you can fold over at the mean and the two halves will
coincide. A symmetric distribution (e.g. the normal distribution) will have a skewness of
zero. Those distributions that are skewed to the right, like triglycerides, have a positive
number for skewness. Those skewed to the left will have a negative number for
skewness.
Page -35-
The direction of the skewness goes with the side the longer tail is on. So the
triglycerides graph above is said to be skewed to the right.
500
1,000
The 50th percentile line is not in the
center of the box. This is hard to
see but the median line is a little
below the middle if the box.
The whiskers are not the same
length.
And, of course, that long string of
points outside the upper whisker with
no similar string outside the lower
whisker.
0
Lipid BL Triglycerides
1,500
How to tell the graph is skewed
when using a box plot:
Definition of the whiskers.
First order the units of the sample in ascending order (smallest to largest).
Let
x[ p] denote the pth percentile.
The box extends from
Define
So
x[25] is the 25
x[25] to x[75] .
th
percentile.
The line in the “middle” is
x[50] .
U = x[75] + 15
. ( x[75] − x[25])
and
L = x[25] − 15
. ( x[75] − x[25])
Page -36-
Notice that if the whiskers were defined by U and L, then the length of the upper and
lower whiskers would always be the same. After we’ve looked at a bunch of examples
you’ll know the upper and lower whiskers are not always the same length. The length
depends on the upper and lower adjacent values defined below.
x( i ) indicates that the x ' s are ordered from smallest to largest.
n x ' s , then x(1) is the smallest and x( n ) is the largest.
The notation
are
If there
The upper adjacent value (i.e. the upper whisker) is defined as the x( i ) such that
x( i ) ≤ U
and
x(i + 1) > U (i.e. x(i )
is just inside or on U).
The lower adjacent value (i.e. the lower whisker) is defined as the x( i ) such that
x(i ) ≥ L and
x(i − 1) < L
(i.e.
x( i )
is just inside or on L).
Notice that Rosner refers to points outside the whiskers as outlying values.
The upper and lower adjacent values (defined above) are a creation of John Tukey
(Exploratory Data Analysis, 1977).
Page -37-
John Tukey - Statistician
He died at 85 in 2000
Coined the Word 'Software' and the word ‘bit’ for binary digit.
Tukey used the term software three decades before the
founding of microsoft.
John Wilder Tukey was one of the most influential statisticians
of the last 50 years and a wide-ranging thinker.
Mr. Tukey developed important theories about how to analyze
data and compute series of numbers quickly. He spent
decades as both a professor at Princeton University and a
researcher at AT&T's Bell Laboratories, and his ideas
continue to be a part of both doctoral statistics courses and
high school math classes. In 1973, President Richard M.
Nixon awarded him the National Medal of Science.
Taken in part from the New York Times Obituary.
How to graph a box plot
In the menu above click on box
plot and you will get the menu on
the right. There are a lot of fancy
things you can do but just putting
“trig” in the variables window gets
you the graph a couple of pages
up.
Page -38-