Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Towards a Marine Environmental Information System
(MEnvIS) for the Northwest Atlantic: Experiences and
suggestions from a multi-disciplinary GIS conservation
research project using public large scale monitoring and
research data bases from the internet
Falk Huettmann*
Atlantic Cooperative Wildlife Ecology Research Network (ACWERN)
University of New Brunswick
Fredericton NB E6B 6C2
Canada
*
Current address: Biology and Wildlife Department, Institute of Arctic Biology
University of Alaska-Fairbanks
Fairbanks AK 99775-7000
USA
Abstract: - Large databases present a major investment. Often they are provided by governmental agencies and
fulfill a monitoring and descriptive purpose. Here an overview and experiences are presented from a six year
research project using a variety of environmental databases, freely available over the internet and from other
digital sources. This project makes extensive use of such databases relevant to the Northwest Atlantic
environment and for data analysis and predictive modeling for informed decision-making. Findings from this
study contribute to a Marine Environmental Information System (MEnvIS) for the study area. Detailed
experiences when using internet-databases for research purposes are presented, and suggestions are made how
to further improve the delivery of databases to the lay public and to the research community. An outlook is
given how the internet could become a central theme for data repository, data delivery and publication
towards informed and transparent decision making for the environment.
Key-Words: - Large Digital Databases, Seabird Monitoring, public internet/WWW download, Marine
Environmental Information System, Northwest Atlantic
1 Introduction
Recent and strong advancements in information
technology have made free internet/World Wide
Web (WWW) data downloads increasingly available
to the international community. However, sound
applications which use and evaluate such approaches
are still rare. Free internet data availabilty allows for
the first time for compiling pelagic environmental
data sets and seabird and sea mammal inventories
into a Geographic Information System (GIS) for the
study area of the Northwest Atlantic, Gulf of Maine
– Davis Strait - Canadian High Arctic; a Marine
Environmental Information System (MEnvIS) can
easily be built. This permits fast and quick answers
to queries of interest, and it permits to address
scientific and management questions related to
seabirds and their marine ecosystem. Using this
MEnvIS, here I address scientific and conservation
management project applications such as descriptive
habitat analysis and model predictions. This
publication covers results and experiences from a six
year research project 1995 – 2000 using the PIROP
(Programme Intégré des Recherches sur les Oiseaux
Pélagiques) monitoring database for seabirds in
concert with free environmental data sets for the
marine study area.
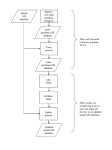
2 Project Overview and Objectives
The concept of this long-term project is
fundamentally based on computing-intense and free
environmental data downloads from the internet
which then got implemented into MEnvIS. These
data sets were selected in order to help explaining the
focus data set [see also 1 for using bird data and
biodiversity to assess national health questions].
Figure 1: An approach making use of free internet
data.
data, to create data labels and strata, and to prepare
them for the statistical data analysis. For further
methods and for selected results using this approach
see Fig 1. and Fig. 2 ,or see [11, 12, 13, 14, 15, 16].
Scientific approach,
e.g. hypothesis testing
and experiment
3 Results: Experiences from Chosen
Research Approach
and/or
Management
question
Existing data
Model building
Public data sets
from internet/ www
and /or governmental agencies
3.1 Locating internet databases of interest
Usually, it was not possible to locate most data sets
for this project by simply searching the internet for
the research data directly. Instead, all data sets were
Environmental
pointed out to me when visiting conferences or when
communicating with experts, e.g. by phone or email.
Information
I recognized that even contacting agencies directly
System (EIS)
about their data holding did not necessarily result in
locating data sets since often the staff was not aware
of latest project data and website updates. Using a
communication approach eventually I was able to
locate 20 environmental data sets relevant for the
Test and evaluate
project and study area; most of them were derived
model with reserved,
from the website of the National Oceanic and
randomly selected,
Atmospheric Administration [17, 18], see Table 1 for
or additional data
an overview of data sets used and for additional
sets, and/or using
details.
model residuals
Scientific
conclusion
Prediction
Here GIS overlays of data sets were used to
investigate how seabird distribution in the Northwest
Atlantic is determined by its environment. The huge
long-term PIROP monitoring data set from the
Canadian Wildlife Service was used for seabird
baseline data [2, 3, 4]; other data sets, which were
relevant to seabirds and matched temporal and
spatial scales, were then selected in a multiple
regression scenario for different seasons (summer for
breeding, wintering, fall and spring for migration) in
order to describe, model and predict the distribution
of specific seabird species for the study area. I used
Visual FoxPro 6 for SQL queries of data bases,
SPLUS 2000 [5] for multivariate statistics and
SPANS-GIS for plotting, overlaying and surface
interpolation. For multivariate statistics techniques
clustering, multiple logistic regression [6, 7], CART
[8, 1] and Neural Networks [9] were used; see also
[10] for evaluation of prediction techniques. All data
sets discussed were imported as ASCII import
formats, and if necessary processed and modified
with SQL (Standard Query Language) code to filter
3.2 Experiences when using Environmental
Data for the study area
Data suppliers who offer data sets via the internet are
often specific public agencies which have spent for
decades time, money and effort on environmental
monitoring. Clearly this investment in field work and
data processing pays back now for the research
community, and usually it relates into a huge data
availability for the public - and if the internet is
applied - for the global community.
Most scientific data for the study area used in this
study were collected with public tax money, or by
governmental order. Due to the North American
Freedom of Information Act, all collected data from
North American governmental agencies need to be
shared, published and distributed. A strong pressure
exists nowadays to release such data, otherwise there
is a danger they might get forgotten, become
unusable or even get lost. Due to the recent strong
advances in hardware, data base software, GIS and
spatial statistics (particularly surface interpolation
and predictive modeling techniques), there is an
increasing availability of, but also an increasing
demand for, spatial information. This demand stems
from the public, as well as from scientific and
management interest.
Table 1: List and details for data sets used.
Data
Subject
Seabirds
Number and
Name of Data Set
1. PIROP
Atmosphere
2. Atmospheric
Temperature at 880
mbar
3. STD Temperature
Atmospheric at 880
mbar
4. Wind Speed
5. Air Pressure at
Sea Level
6. Air Temperature
Geology
Water
Additional
Data Source
Data Type
Units
Environment Canada,
Canadian Wildlife
Service, Manomet Bird
Observatory U.S.
Pathfinder Satellite
(NOAA)
Continuous
Pathfinder Setallite
(NOAA)
Continuous
Standard
Deviation
COADS (NOAA)
COADS (NOAA)
Continuous
Continuous
Meter/sec
Mbar
April 1987 December
1988
April 1987 December
1988
1854 - 1993
1854 - 1993
COADS (NOAA)
Continuous
Kelvin
1854 - 1993
7. Wind when
seabird observation
was done
8. Sea Depth
PIROP
Discrete
Classified
1966 - 1992
ETOPO5
Continuous
Meters
1988
9. Slope of Sea
Floor
10. Aspect of Sea
Floor
11. Distance from
Coast
12. Distance from a
Seamount
13. Distance from
Shelf Edge
14. Sea Surface
Temperature
15. Water
Temperature 30 m
below sea surface
16. Sea Surface
Salinity
17. Water Salinity
30 m below sea
surface
18. Salinity
Difference Surface 30 m depth
19. Temperature
Difference Surface 30 m depth
20. Sea State when
seabird observations
were done
21. Seabird
Colonies
SPANS-GIS from
ETOPO5
SPANS-GIS from
ETOPO5
SPANS-GIS
Continuous
Degrees
1988
Discrete
Classified
1988
Discrete
1998
SPANS-GIS from
ETOPO5
SPANS-GIS from
ETOPO5
WOA (NOAA)
Discrete
WOA (NOAA)
Continuous
Distance
bands
Distance
bands
Distance
bands
Degrees
Celsius
Degrees
Celsius
WOA (NOAA)
Continuous
WOA (NOAA)
Continuous
SPANS-GIS based on
WOA (NOAA)
Continuous
Discrete
Continuous
Seabirds
within a
10minute
block
Kelvin
Time cover
1966-1992
1996
1996
1948 - 1988
1948 - 1988
Parts per
million
Parts per
million
1948 - 1988
Continuous
Parts per
million
1948 - 1988
SPANS-GIS based on
WOA (NOAA)
Continuous
Degrees
Celsius
1948 - 1988
PIROP
Discrete
Classified
1966 - 1992
e.g. [3]
Continuous
Breeding
Pairs
1948 - 1988
1989,
1994
Abbreviations: COADS = Climate and Ocean Atlas Data Set, ETOPO5 = Earth Topographic
Information for 5 minute grids, WOA = World Ocean Atlas. Other abbreviations and details are
explained in the text.
Figure 2: A research approach predicting Northern Fulmar (Fulmarus glacialis)
distribution in the arctic section of the study area (Greenland, Davis Strait, Canada),
based on distribution data from the PIROP data base (a), overlaid with 20
Environmental Data sets (see Table 1), and analyzed (b) and predicted (c) with a
Classification and Regression Tree (Cart); see [11] for an approach using Artificial
Neural Networks.
a
b
c
Data collection protocols for large-scale and longterm data bases can be inconsistent and these data
sets often have temporal and spatial gaps.
Depending on the data history, study area and data
collection infrastructure, it is a common situation
that some data were collected on a very fine scale
for a certain location, perhaps even throughout
years. On the other hand, other locations may have
never been sampled at all, or may have been
surveyed with a different data collection scheme and
with varying effort throughout years. However, due
to strong data demands and interests, individual data
sets then were often merged, pooled together and
homogenized since this would be the only way to
obtain information and data as good as possible.
However, accuracy assessments, reliability and
consistency could have been seriously sacrified for
such data sets.
A typical list of applications for environmental data
sets from the internet cover (i) general data queries,
(ii) trend information on long-term ecological data,
e.g. global change, abundance and resource
overexploitation, (iii) GIS applications and (iv)
using data for scientific multiple regression
scenarios, spatial statistics, modeling and
predictions.
Such demanding and advanced research questions
cause often the problem of using data sets in ways
for which they were originally not created for.
Sound multipurpose data set collection protocols are
still rare. Instead, single purpose data sets are often
brought into a very different context than they were
originally designed for, e.g. from originally
addressing general monitoring questions towards
being used to answer scientific questions on longterm and spatial quantitative trends with a high
statistical accuracy.
3.3 Experiences when using the internet as a
research tool
The development of the internet, including free use
of email, make data widely available to the public
for a relatively cheap price to the data provider
(provision costs: formatting data set for the internet
server, website, maintenance and updates) as well as
for the receiver (user costs: computing and internet
infrastructure).
Since the internet can be accessed and used
nationally and internationally, the international
community can benefit greatly from national
approaches for no costs, as obvious with the North
American Freedom of Information Act. However,
such advantages could also turn into disadvantages,
e.g. when the user is faced with communication
problems between North American federal vs.
provincial/state agencies. The national legal set-up
is still crucial for free internet data, and it can affect
for instance data availability for internationally
owned marine offshore waters, their management
and conservation.
3.4.Experiences when using data from
the internet
3.4.1.Database websites and data base support
All web publications and data sets used for this
project were provided in the English language,
allowing for a truly international usage. However,
most websites suffered from information overload
and a poor graphical design; they failed to indicate
what they really had to offer. Abbreviations were
rarely explained. Normally, a support staff was
necessary to guide me via phone through the
website and its design, and explain data available
and data policy provided at the specific URL.
Therefore, directly connecting email addresses and
telephone numbers were found of major importance
to request for help and guidance with data access
and downloads, but they were not always provided.
Twenty-four hour support was not encountered, but
could easily be justified when dealing with the
international community and customers across the
continent.
In terms of database support I experienced cases
where staff was not trained, and the user got simply
referred to URLs without getting the specific
questions answered. In similar cases staff was not
able to answer basic questions on the presented data,
e.g. correct data set citations for publications, data
collection schemes, error fixes, data upgrades, data
set versions, temporal and spatial scale of data,
accuracy assessments or processing algorithms used.
Mailing
of
publications
and
data
set
documentations, instead of downloading PDF
(Portable Document Format) files, was found very
useful.
3.4.2. The data sets
Although the legal copyright situation is relatively
clear and often stated online for such data, the
international downloading situation across countries
and legal spheres still can create confusion about
ownerships and copyrights once data are in hand of
the user.
Information on database software and operating
systems in which the data were stored by the agency
was never provided ad-hoc. Since data sets can
change hands and ownership, confusing situations
can occur with names, labels, data quality and data
subsets. A typical issue for North American data
sets can arise from readily available raw data sets
released by federal agencies to the public for free
via internet, which then get re-interpreted and
extended by provincial/state agencies or consultants,
e. g. commonly the case for road networks, Digital
Elevation Models (DEM) or remote sensing
information about land use.
To improve the documentation, it was found very
useful when data sets were already published under
a peer-review system, e.g. as a special journal
edition or as an Atlas [3,19]. In general, I did not
find a meta-data standard for all data sets I used.
Although meta-data standards exist, particularly for
data hosted in the U.S., I never came across any
standardized ways of presenting them, nor were they
really made available. Descriptions of data are
crucial to the user but sometimes lacking or
inaccurate, e.g. for logs of error fixes, names and
versions of data sets, collection schemes, and their
compatibility.
With large data sets I found sometimes that several
data sets were merged together using different
collection schemes, which are often not fully
consistent. Exact protocols about such a policy were
not available to the public; other data processing
work was simply given to contractors which could
not be contacted anymore once the contract was
completed. In addition, the applied types of
classification schemes for data sets can be subjective
and intransparent, and accuracy assessments are
often lacking.
A very important issue for georeferenced data sets is
their spatial accuracy [see 20, 21]. However, spatial
accuracy questions were not discussed or mentioned
in most of the data sets I used. This presents for
instance a particular uncertainty for offshore
bathymetrical information where ground-truthing
and data evaluation can hardly be done; in such
cases the user relies entirely on the data provider.
For large data bases the same could be said in
regards to errors, such as caused by typing and data
handling (rounding, data transfers and imports).
3.4.3. Online data queries
Speed of server and internet connection was found
to be of major importance for a convenient data base
query and for the success of a website per se. Slow
server and internet connections, including loading
and transfer errors, lead to query problems, slow
data transfers, or even data loss for the user.
Zooming, pre-mapping and data selection features
were found to be very important to investigate and
to pre-view data of interest before downloading.
3.4. 4. Data download and data compression
All downloads of data used were free of charge, and
were usually done directly onto the hard drive of the
user machine. Data download formats found most
useful were ASCII, DBF and EXCEL; other specific
formats like ArcInfo Export files (E00) or HDF
(Hierarchical Data Format) exist but were not used.
In most cases ftp (File Transfer Protocol) was used
for file transfer, where occasionally a confusion
occurred about how to log-in, where the data were
stored, and if binary or ASCII transfer options was
to be used. Email attachment was not offered by
data providers as a data transfer, but could also be
useful when transfering smaller data sets. Due to the
large size of requested data, data sets were normally
compressed using WinZip or Tar. However, these
techniques can already constrain the free availability
of data because user skills, basic though, are
required to make data useable. So far, I found that
most large data sets on the internet were provided,
queried and processed on UNIX servers. Although
using ftp, problems can still occur when transferring
data sets and query results across operating systems,
e.g. Windows vs. UNIX and LINUX. CD-ROM is a
good option to deliver data, but this option creates
costs and delays, which mostly are covered by the
user.
I found it inconvenient and confusing when queries
from data requests were split up into smaller data
packages or subsets (mostly due to file size
problems). Sometimes these subsets were given
intransparent file names; after the data transfer the
user has to compile these data sets into one again.
This issue particularly occurs when working with
GIS map sheets (for a discussion see 3.4.5 below).
However, most requested data queries were ready
for ftp pick-up within seconds, or within a day,
which met the project time frame very well.
Some data sets require a user registration, which can
be time consuming. A particular problem with free
data sets occurred when the user has to pay for, or to
obtain, a compression software, or any other
technical tool, beforehand. Such approaches still
present a bottleneck in the whole concept of free
data availability. Any data provided free of charge
through the internet to the public in any directly
non-readable format are technically not useable to
all users. A similar problem occurred with formats
such as HDF, or data that require programming
languages (e.g. FORTRAN), where the user had to
know the compression software and the algorithms,
and had to learn the specifics about particular
formats.
3.4.5. GIS and Remote Sensing
GIS applications demand their own standards;
formatting compatibilities occurred when using
different GIS software other than the offered ones.
Data can be downloaded in GIS formats, or better,
as general point and raw data for specific or further
processing. Projection free coordinate systems, such
as latitude and longitude, were preferred. However,
due to file size, and lack of compatibility among
GIS software and across operating systems, the
latter approach still proved to be problematic. Most
GIS download applications provided DXF (Data
Exchange Format) and/or E00 ArcInfo export files;
although other GIS formats were also found, e.g.
Spatial ORACLE data bases or specific local and
agency GIS formats. Still, a full and true
compatibility hardly exist among GIS formats, and
even among compatible formats information still
might get lost during the transfer process, e.g.
specific formatting and column attributes. A major
issue in GIS data downloads can be the separation of
the data for a requested area into smaller GIS map
sheets. Often, such situations offer no guidance or
contact addresses about how to merge map sheets
into one after the data were downloaded.
I experienced that data from remote sensing
applications were usually not provided in GIS
formats but as a matrix. No help was provided to
import these data into a GIS. Instead, a viewing and
de-compression software was necessary to look at
the data. If raw data for satellite images were
provided, most of these data consisted of
georeferenced raster pixels with a bit value (x,y,z
format) in ASCII format. This approach proved
convenient, but could present a problem if raster
grids and data sequence were not accurately
documented.
4 Conclusions and Suggestions
The internet can offer a borderless research tool to
be used across countries. Therefore, the
international community can benefit greatly from
national approaches at no costs, as currently
achieved with the North American Freedom of
Information Act for instance. So far, countries
which do not have such a legal framework, or which
do not share their national data heritage with others,
clearly do not contribute fully to this concept. Due
to this imbalance, they even put this great concept at
risk since not fully and equally supported by the
global community as a whole.
Free internet data availability is a (research)
infrastructure to the international community; but
who pays for it to improve, evaluate and maintains
it? Data sets for the internationally owned body of
the offshore ocean are a good example for such a
situation. Proprietory information for these
international waters and for which a larger
international community has a strong interest (e.g.
conservation or fish harvest data) present such a
classical problem. In addition, criticism is often
expressed that consultants and NGOs could have
financial benefits from free internet data, for which
these data were originally not meant for.
Agencies have the tendency not to publish
controversial data, and instead provide only
smoothed out information. For the public user such
a selective information provision can lead to a
wrong perception of reality. Agencies that have the
monopoly on data sets clearly can drive assumptions
and opinions due to loss of variety and additional
evaluation options for the public.
Currently, the internet is not making use of its full
potential to promote its own research potential and
data sets; standardized ways to present free data
sets, and data inventory pages are still missing in
search engines. During my six years research work I
did not experience that a distinction was made
between data for the public, or for data for the
scientific community. However, most data provided
were very specific and technical knowledge was
needed; the lay public would not really be able to
make use of data and information potentially
available to them. Generally, it might be a good
approach to present the same data for scientists, and
alternatively offer on the same website for the lay
public an interpretation of these data and how the
conclusions were derived. I do not recommend to
pre-screen, filter or smooth-out raw data, nor
carrying out any other type of intransparent data
interpretation. Suggestions on how to interpret data
best might prove useful though. However, if any
data smoothing and interpretation has occurred, raw
data and algorithms should be provided and must
allow for a transparent evaluation process of results
for the public.
A frequently discussed topic is the problem of data
overload ('digital data jungle') resulting from the
free internet downloading policy of data agencies. I
feel that currently a data overload is not an existing
problem for the scientific community. A more
relevant problem might be the transparent data
presentation, e.g. for the lay public.
Because of the increasing availability of data sets
through the internet there is a temptation for
scientists and others to make use of these data
without a proper research design and without prior
investigation of data history and data purpose. A
sound and well thought-out hypothesis still needs to
be the driving force for the science done with these
data sets, instead of ‘surfing the internet’ to see
which data set might explain trends, perceptions and
models best, and then dismissing the ones that do
not.
Current tendencies for free internet data downloads
using increasing beaurocratic or technological
thresholds, and also the release of governmental
data on a cost recovery basis only, hinders the
concept of free data availability through the internet
to the global community; a MEnvIS, crucial for
effective management and conservation of the study
area, cannot possibly be built without free data.
Research from this project has shown how internet
data free of charge can be used efficiently for
management, conservation and research questions in
the study area. Only providing free data through the
internet made compiling an MEnvIS for the study
area possible, which better ensures the management
and conservation of the huge offshore ecosystem we
know so little about.
applications matching this future trend very well,
and which strongly benefit from free data
availability. The spatial and temporal resolution of
GIS and databases are still increasing, and so are its
data volumes. This raises several issues, such as
data storage, data handling, data management, data
presentation and data provisioning to be addressed
in an efficient manner. In addition, questions like
international copyrights, data accuracy, meta-data
standards, implementation of standards, sharing
costs for data provision and downloading, and
providing
a
public,
well-maintained
and
scientifically sound internet infrastructure will
become of increasing importance.
References:
[1] O’Connor, R., and Jones, M. T. Using
hierarchical models to index the ecological health of
the nation. Transactions Number 62 of the American
Wildlife and Natural Resources Conference. 1997
pp. 501- 608.
[2] Brown, R.G.B., Nettleship, D.N., Germain, P.,
Tull, C.E. and Davis T. Atlas of Eastern Canadian
Seabirds. Canadian Wildlife Service, Halifax 1975.
[3]Lock, A.R., Brown, R.G.B., and Gerriets, S.H.
Gazetteer of marine birds in Atlantic Canada.
Canadian Wildlife Service. Atlantic Region. 1994.
[4] Huettmann, F., and Lock, A.R. A new software
system for the PIROP database; data flow and an
approach for the seabird-depth analysis. ICES
Journal for Marine Science Vol. 54 1997 pp. 518523.
[5] Venables, W. N., and Ripley, B. D. Modern
Applied Statistics with S-Plus. 2.ed. Statistics and
Computing, Springer Verlag, New York. 1994.
[6] Brennan, L.A., Block, W.M., and Gutierrez, R.J.
The use of multivariate statistics for developing
habitat suitability index models. In Verner, J.,
Morrison, M.L., Ralph, C.J. (ed.). Wildlife 2000:
modelling habitat relationships of terrestrial
vertebrates. University of Wisconsin Press,
Madison. 1986 pp 177-182.
4.1 Future Trends
The internet is well established now, and very likely
its research use will still be increasing. Therefore,
future research trends can be characterized by using
data from these sources, and for similar applications
world-wide, as described above. Environmental
Information Systems and predictive modeling are
[7] North, M., and Reynolds, J. H. Microhabitat
analysis using radiotelemetry locations and
polytomous logistic regression. Journal for Wildlife
Management Vol. 60 1996 pp. 639-653.
[8] Miller, T., and Ribic, C. (1995). Tree-Structured
variable selection methods. Proceedings of the
Statistical Computing Section of the American
Statistical Association. 1995 pp. 142-147.
[9] Oezesmi, S. L. and Oezesmi, U. An artificial
neural network approach to spatial habitat modelling
with interspecific interaction. Ecological Modelling
Vol 116 1999 pp. 15-31.
[10] Dettmers, R., Buehler, D.A. and Bartlett, J. G.
A test and comparison of wildlife-habitat modeling
techniques for predicting occurrence on a regional
scale. In Predicting Species Occurrences: Issues of
Accuracy and Scale. Scott, J. M. , Heglund, J. P.,
Samson, F. et al. (ed.). Island Press, Washington
DC. in press
[11] Huettmann, F. Making use of public large-scale
environmental databases from the WWW and a GIS
for geo-referenced prediction modelling: An
application based on Generalized Linear Models,
Classification and Regression Trees and Neural
Networks. In Tochtermann, K. and Rieckert, W.-F.
(ed.). Proceedings 3. Workshop “Hypermedia im
Umweltschutz”. FAW Ulm, Germany. 2000 pp 308
– 312.
[12]Huettmann,
F.,
and
Diamond,
A.W.
Characterizing, Modeling and Predicting locations
of Seabird Colonies in the Davis Strait: Using the
PIROP database, GIS and Environmental Data to
Evaluate the Suitability of Marine Breeding Habitats
for Arctic Seabirds. In Shaw, R.W., Danks, M.M.E.,
Miller, S. (ed.). Proceedings of Environmental
Prediction Workshop, 1998. Environment Canada,
Halifax. 1998 pp 86-94.
[13]Huettmann, F., and Diamond, A.W. Seabird
migration in the Canadian North Atlantic: moulting
locations and movement patterns of immatures.
Canadian Journal of Zoology. Vol. 33 1999 pp.1-25.
[14]Huettmann F., and Diamond, A.W. Seabird
colony locations and environmental determination
of seabird distribution: A spatially explicit seabird
breeding model in the Northwest Atlantic. Journal
for Ecological Modelling Vol. 141 2001 pp.261298.
[15]Huettmann, F., and Diamond, A.W. Using PCA
Scores to classify species communities: an example
using seabird classifications at sea. Journal for
Applied Statistics Vol 28 2001 pp. 843-853.
[16]Huettmann,
F.,
and
Diamond,
A.W.
Characterizing the marine Environment in the
Canadian North Atlantic using GIS, multivariate
statistics and environmental large scale data bases.
Canadian Journal for Aquatic Sciences and
Fisheries. in review.
[17]National
Oceanic
and
Atmospheric
Administration. Five minute gridded earth
topography data. Http:// edcwww.cr.usgs.gov/glis/
hyper/guide/etopo5. 1996.
[18]National
Oceanic
and
Atmospheric
Administration. Live Access to Climate Data.
Http://ferret.wrc.noaa.gov/fbin/climate_server.
1997.
[19]Levitus, S. World Ocean Atlas 1994.
Washington, D.C., National Oceanic and Atmospheric Administration, National Oceanographical
Data Center. 4 volumes 1994.
[20]Agumya, A. and Hunter G.J. Translating
uncertainty in Geographical Data into risk in
decisions. In Shi, W., Goodchild, M.F., Fisher, P. F.
(ed.). Proceedings of The International Symposium
on Spatial Data Quality ’99. The Hong Kong
Polytechnic University Dept. of Land Surveying and
Geo-Informatics, Hong Kong. 1999 pp. 574 – 584.
[21]Shi, W., Goodchild, M.F., and Fisher, P. F.
(ed.). Proceedings of The International Symposium
on Spatial Data Quality ’99. Dept. of Land
Surveying and Geo-Informatics, The Hong Kong
Polytechnic University. 1999