Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
EI 209
Computer Organization
Fall 2013
Chapter 3: Arithmetic for
Computers
Haojin Zhu (http://tdt.sjtu.edu.cn/~hjzhu/ )
[Adapted from Computer Organization and Design, 4th Edition,
Patterson & Hennessy, © 2012, MK]
EI 209 Chapter 3.1
CSE, 2013
Assignment III
3.6, 3.8, 3.11, 3.14
Due: Nov. 14
EI 209 Chapter 3.2
CSE, 2013
Review: MIPS (RISC) Design Principles
Simplicity favors regularity
Smaller is faster
limited instruction set
limited number of registers in register file
limited number of addressing modes
Make the common case fast
fixed size instructions
small number of instruction formats
opcode always the first 6 bits
arithmetic operands from the register file (load-store machine)
allow instructions to contain immediate operands
Good design demands good compromises
three instruction formats
EI 209 Chapter 3.3
CSE, 2013
Specifying Branch Destinations
Use a register (like in lw and sw) added to the 16-bit offset
which register? Instruction Address Register (the PC)
- its use is automatically implied by instruction
- PC gets updated (PC+4) during the fetch cycle so that it holds the
address of the next instruction
limits the branch distance to -215 to +215-1 (word) instructions from
the (instruction after the) branch instruction, but most branches are
local anyway
from the low order 16 bits of the branch instruction
16
offset
sign-extend
00
32
32 Add
PC
32
EI 209 Chapter 3.4
32
4
32
Add
32
branch dst
address
32
?
CSE, 2013
Other Control Flow Instructions
MIPS also has an unconditional branch instruction or
jump instruction:
j
label
#go to label
Instruction Format (J Format):
0x02
26-bit address
from the low order 26 bits of the jump instruction
26
Why shift left by two bits?
00
32
4
PC
EI 209 Chapter 3.5
32
CSE, 2013
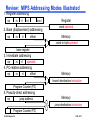
Review: MIPS Addressing Modes Illustrated
1. Register addressing
op
rs
rt
rd
funct
Register
word operand
2. Base (displacement) addressing
op
rs
rt
offset
Memory
word or byte operand
base register
3. Immediate addressing
op
rs
rt
operand
4. PC-relative addressing
op
rs
rt
offset
Memory
branch destination instruction
Program Counter (PC)
5. Pseudo-direct addressing
op
Memory
jump address
||
jump destination instruction
Program Counter (PC)
EI 209 Chapter 3.6
CSE, 2013
Number Representations
32-bit signed numbers (2’s complement):
0000 0000 0000 0000 0000 0000 0000 0000two = 0ten
0000 0000 0000 0000 0000 0000 0000 0001two = + 1ten
...
0111
0111
1000
1000
...
MSB
1111
1111
0000
0000
1111
1111
0000
0000
1111
1111
0000
0000
1111
1111
0000
0000
1111
1111
0000
0000
1111
1111
0000
0000
1110two
1111two
0000two
0001two
=
=
=
=
+
+
–
–
maxint
2,147,483,646ten
2,147,483,647ten
2,147,483,648ten
2,147,483,647ten
1111 1111 1111 1111 1111 1111 1111 1110two = – 2ten
1111 1111 1111 1111 1111 1111 1111 1111two = – 1ten
minint
LSB
Converting <32-bit values into 32-bit values
copy the most significant bit (the sign bit) into the “empty” bits
0010 -> 0000 0010
1010 -> 1111 1010
sign extend
EI 209 Chapter 3.7
versus
zero extend (lb vs. lbu)
CSE, 2013
MIPS Arithmetic Logic Unit (ALU)
zero ovf
Must support the Arithmetic/Logic
operations of the ISA
add, addi, addiu, addu
1
1
A
32
sub, subu
ALU
mult, multu, div, divu
sqrt
result
32
B
32
and, andi, nor, or, ori, xor, xori
4
m (operation)
beq, bne, slt, slti, sltiu, sltu
With special handling for
sign extend – addi, addiu, slti, sltiu
zero extend – andi, ori, xori
overflow detection – add, addi, sub
EI 209 Chapter 3.8
CSE, 2013
Dealing with Overflow
Overflow occurs when the result of an operation cannot
be represented in 32-bits, i.e., when the sign bit contains
a value bit of the result and not the proper sign bit
When adding operands with different signs or when subtracting
operands with the same sign, overflow can never occur
Operation
Operand A
Operand B
Result indicating
overflow
A+B
≥0
≥0
<0
A+B
<0
<0
≥0
A-B
≥0
<0
<0
A-B
<0
≥0
≥0
MIPS signals overflow with an exception (aka interrupt) –
an unscheduled procedure call where the EPC contains
the address of the instruction that caused the exception
EI 209 Chapter 3.9
CSE, 2013
Addition & Subtraction
Just like in grade school (carry/borrow 1s)
0111
0111
0110
+ 0110
- 0110
- 0101
1101
0001
Two's complement operations are easy
do subtraction by negating and then adding
0111
- 0110
0001
0001
0111
+ 1010
1 0001
Overflow (result too large for finite computer word)
e.g., adding two n-bit numbers does not yield an n-bit number
0111
+ 0001
1000
EI 209 Chapter 3.11
CSE, 2013
Building a 1-bit Binary Adder
carry_in
A
1 bit
Full
Adder
B
carry_out
S
A
B
carry_in
carry_out
S
0
0
0
0
0
0
0
1
0
1
0
1
0
0
1
0
1
1
1
0
1
0
0
0
1
1
0
1
1
0
1
1
0
1
0
1
1
1
1
1
S = A xor B xor carry_in
carry_out = A&B | A&carry_in | B&carry_in
(majority function)
How can we use it to build a 32-bit adder?
How can we modify it easily to build an adder/subtractor?
EI 209 Chapter 3.12
CSE, 2013
Building 32-bit Adder
c0=carry_in
A0
B0
A1
B1
A2
S0
1-bit
FA
c2
S1
1-bit
FA
c3
S2
Just connect the carry-out of
the least significant bit FA to the
carry-in of the next least
significant bit and connect . . .
Ripple Carry Adder (RCA)
advantage: simple logic, so small
(low cost)
disadvantage: slow and lots of
glitching (so lots of energy
consumption)
...
B2
1-bit
FA
c1
c31
A31
B31
1-bit
FA
S31
c32=carry_out
EI 209 Chapter 3.13
CSE, 2013
A 32-bit Ripple Carry Adder/Subtractor
Remember 2’s
complement is just
complement all the bits
control
(0=add,1=sub)
B0
B0 if control = 0
!B0 if control = 1
add a 1 in the least
significant bit
A
0111
B - 0110
0001
EI 209 Chapter 3.15
0111
+ 1001
1
1 0001
c0=carry_in
A0
1-bit
FA
c1
S0
A1
1-bit
FA
c2
S1
A2
1-bit
FA
c3
S2
B0
B1
B2
...
add/sub
c31
A31
B31
1-bit
FA
S31
c32=carry_out
CSE, 2013
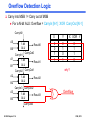
Overflow Detection Logic
Carry into MSB ! = Carry out of MSB
For a N-bit ALU: Overflow = CarryIn [N-1] XOR CarryOut [N-1]
CarryIn0
A0
1-bit
ALU
B0
CarryIn1
A1
CarryOut0
1-bit
ALU
B1
CarryIn2
A2
Result1
CarryOut1
1-bit
ALU
B2
Result0
X
Y
X XOR Y
0
0
1
1
0
1
0
1
0
1
1
0
why?
Result2
CarryIn3 CarryOut2
A3
B3
1-bit
ALU
Result3
Overflow
CarryOut3
EI 209 Chapter 3.16
CSE, 2013
Multiply
Binary multiplication is just a bunch of right shifts and
adds
n
multiplicand
multiplier
partial
product
array
n
can be formed in parallel
and added in parallel for
faster multiplication
double precision product
2n
EI 209 Chapter 3.17
CSE, 2013
Multiplication
More complicated than addition
Can be accomplished via shifting and adding
0010 (multiplicand)
x_1011 (multiplier)
0010
0010
(partial product
0000
array)
0010
00010110 (product)
In every step
• multiplicand is shifted
• next bit of multiplier is examined (also a shifting step)
• if this bit is 1, shifted multiplicand is added to the product
EI 209 Chapter 3.18
CSE, 2013
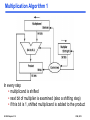
Multiplication Algorithm 1
In every step
• multiplicand is shifted
• next bit of multiplier is examined (also a shifting step)
• if this bit is 1, shifted multiplicand is added to the product
EI 209 Chapter 3.19
CSE, 2013
EI 209 Chapter 3.20
CSE, 2013
Comments on Multiplicand Algorithm 1
Performance
Three basic steps for each bit
It requires 100 clock cycles to multiply two
32-bit numbers If each step took a clock
cycle,
How to improve it?
Motivation (Performing the operations in
parallel):
Putting multiplier and the product together
Shift them together
EI 209 Chapter 3.21
CSE, 2013
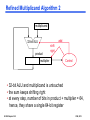
Refined Multiplicand Algorithm 2
multiplicand
add
32-bit ALU
product
multiplier
shift
right
Control
• 32-bit ALU and multiplicand is untouched
• the sum keeps shifting right
• at every step, number of bits in product + multiplier = 64,
hence, they share a single 64-bit register
EI 209 Chapter 3.22
CSE, 2013
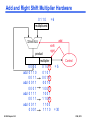
Add and Right Shift Multiplier Hardware
0110
=6
multiplicand
add
32-bit ALU
product
shift
right
multiplier
add
add
add
add
EI 209 Chapter 3.23
0000
0110
0011
0011
0001
0111
0011
0011
0001
0101
0101
0010
0010
1001
1001
1100
1100
1110
Control
=5
= 30
CSE, 2013
Exercise
Using 4-bit numbers to save space, multiply 2ten*3ten, or
0010two * 0011two
EI 209 Chapter 3.24
CSE, 2013
Division
Division is just a bunch of quotient digit guesses and left
shifts and subtracts
dividend = quotient x divisor + remainder
n
quotient
n
0 0 0
dividend
divisor
0
partial
remainder
array
0
0
remainder
n
EI 209 Chapter 3.25
CSE, 2013
Division
Divisor
1000ten
1001ten
| 1001010ten
-1000
10
101
1010
-1000
10ten
Quotient
Dividend
Remainder
At every step,
• shift divisor right and compare it with current dividend
• if divisor is larger, shift 0 as the next bit of the quotient
• if divisor is smaller, subtract to get new dividend and shift 1
as the next bit of the quotient
EI 209 Chapter 3.26
CSE, 2013
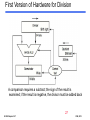
First Version of Hardware for Division
A comparison requires a subtract; the sign of the result is
examined; if the result is negative, the divisor must be added back
27
EI 209 Chapter 3.27
CSE, 2013
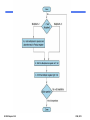
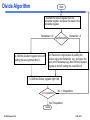
Divide Algorithm
Start
1. Subtract the Divisor register from the
Remainder register, and place the result in the
Remainder register.
Remainder >=0
2a. Shift the Quotient register to the left
setting the new rightmost bit to 1.
Test Remainder
Remainder < 0
2b. Restore the original value by adding the
Divisor reg to the Remainder reg and place the
sum in the Remainder reg. Also shift the Quotient
register to the left, setting the new LSB to 0
3. Shift the Divisor register right1 bit.
33rd repetition?
No: < 33repetitions
Yes: 33repetitions
Done
EI 209 Chapter 3.28
CSE, 2013
Divide Example
• Divide 7ten (0000 0111two) by 2ten (0010two)
Iter
0
Step
Quot
Divisor
Remainder
Initial values
1
2
3
4
5
29
EI 209 Chapter 3.29
CSE, 2013
Divide Example
• Divide 7ten (0000 0111two) by 2ten (0010two)
Iter
Step
Quot
Divisor
Remainder
0
Initial values
0000
0010 0000
0000 0111
1
Rem = Rem – Div
Rem < 0 +Div, shift 0 into Q
Shift Div right
0000
0000
0000
0010 0000
0010 0000
0001 0000
1110 0111
0000 0111
0000 0111
2
Same steps as 1
0000
0000
0000
0001 0000
0001 0000
0000 1000
1111 0111
0000 0111
0000 0111
3
Same steps as 1
0000
0000 0100
0000 0111
4
Rem = Rem – Div
Rem >= 0 shift 1 into Q
Shift Div right
0000
0001
0001
0000 0100
0000 0100
0000 0010
0000 0011
0000 0011
0000 0011
5
Same steps as 4
0011
0000 0001
0000 0001
EI 209 Chapter 3.30
CSE, 2013
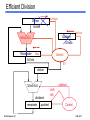
Efficient Division
Shift Right
Divisor
64 bits
Shift Left
Quotient
32 bits
64-bit ALU
Remainder
64 bits
Write
Control
31
divisor
subtract
32-bit ALU
dividend
remainder
EI 209 Chapter 3.31
quotient
shift
left
Control
CSE, 2013
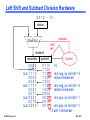
Left Shift and Subtract Division Hardware
0010
=2
divisor
subtract
32-bit ALU
dividend
remainder
sub
sub
sub
sub
EI 209 Chapter 3.32
0000
0000
1110
0000
0001
1111
0001
0011
0001
0010
0000
quotient
shift
left
Control
0110 =6
1100
1100
rem neg, so ‘ient bit = 0
1100
restore remainder
1000
1100
rem neg, so ‘ient bit = 0
1000
restore remainder
0000
rem pos, so ‘ient bit = 1
0001
0010
rem pos, so ‘ient bit = 1
0011
= 3 with 0 remainder
CSE, 2013
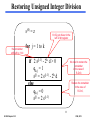
Restoring Unsigned Integer Division
s(0) = z
the remainder
shift left by 1 bit
K=32, put divisor in the
left 32 bit register
for j = 1 to k
if 2 s(j-1) - 2k d > 0
qk-j = 1
s(j) = 2 s(j-1) - 2k d
else
qk-j = 0
s(j) = 2 s(j-1)
No need to restore the
remainder
in the case of
R-D>0,
Restore the remainder
In the case of
R-D<0,
33
EI 209 Chapter 3.33
CSE, 2013
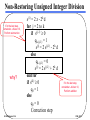
Non-Restoring Unsigned Integer Division
If in the last step,
remainder –divisor >0,
Perform subtraction
why?
s(1) = 2 z - 2k d
for j = 2 to k
if s(j-1) 0
qk-(j-1) = 1
s(j) = 2 s(j-1) - 2k d
else
qk-(j-1) = 0
s(j) = 2 s(j-1) + 2k d
end for
if s(k) 0
q0 = 1
else
q0 = 0
If in the last step,
remainder –divisor <0,
Perform addition
Correction step
EI 209 Chapter 3.34
CSE, 2013
s(0)
=z
for j = 1 to k
if 2 s(j-1) - 2k d > 0
qk-j = 1
s(j) = 2 s(j-1) - 2k d
else
qk-j = 0
s(j) = 2 s(j-1)
Restoring Unsigned Integer
Division
s(1) = 2 z - 2k d
for j = 2 to k
if s(j-1) 0
qk-(j-1) = 1
equal
s(j) = 2 s(j-1) - 2k d
else
qk-(j-1) = 0
Why?
s(j) = 2 s(j-1) + 2k d
end for
if s(k) 0
q0 = 1
else
q0 = 0
Correction step
Non-Restoring Unsigned
Integer Division
2x-y= 2(x-y)+y
EI 209 Chapter 3.35
considering two consequent
steps j-1 and j, in particular
2s(j-2) - 2k d <0
In the j-1 step, Restoring
Algorithm computes
qk-j = 0
s(j-1) = 2 s(j-2)
In the subsequent j step,
Restoring Algorithm
computes
2 s(j-1) - 2k d
== 2*2 s(j-2) - 2k d
Non-Restoring Algorithm
s(j-1) = 2 s(j-2) - 2k d
In the subsequent j step, nonRestoring Algorithm
computes
2 s(j-1) + 2k d
= 2*2 s(j-2) - 2*2k d +2k d
= 2*2 s(j-2) - 2k d
CSE, 2013
Non-restoring algorithm
set subtract_bit true
1: If subtract bit true:
Subtract the Divisor register from the Remainder and place the result
in the remainder register
else
Add the Divisor register to the Remainder and place the result in the
remainder register
2:If Remainder >= 0
Shift the Quotient register to the left, setting rightmost bit to 1
else
Set subtract bit to false
3: Shift the Divisor register right 1 bit
if < 33rd rep
goto 1
else
Add Divisor register to remainder and place in Remainder register
exit
EI 209 Chapter 3.36
CSE, 2013
Example:
Perform n + 1 iterations for n bits
Remainder 0000 1011
Divisor 00110000
----------------------------------Iteration 1:
(subtract)
Rem 1101 1011
Quotient 0
Divisor 0001 1000
----------------------------------Iteration 2:
(add)
Rem 11110011
Q00
Divisor 0000 1100
----------------------------------Iteration 3:
(add)
Rem 11111111
Q000
Divisor 0000 0110
EI 209 Chapter 3.37
----------------------------------Iteration 4:
(add)
Rem 0000 0101
Q0001
Divisor 0000 0011
----------------------------------Iteration 5:
(subtract)
Rem 0000 0010
Q 00011
Divisor 0000 0001
Since reminder is positive, done.
Q = 0011 and Rem = 0010
CSE, 2013
Exercise
Calculate A divided by B using restoring and non-restoring
division. A=26, B=5
EI 209 Chapter 3.38
CSE, 2013
MIPS Divide Instruction
Divide (div and divu) generates the reminder in hi
and the quotient in lo
div
$s0, $s1
# lo = $s0 / $s1
# hi = $s0 mod $s1
0
16
17
0
0
0x1A
Instructions mfhi rd and mflo rd are provided to move
the quotient and reminder to (user accessible) registers in the
register file
As with multiply, divide ignores overflow so software
must determine if the quotient is too large. Software
must also check the divisor to avoid division by 0.
EI 209 Chapter 3.39
CSE, 2013
Lecture 1
EI 209 Chapter 3.40
CSE, 2013
Goals for Floating Point
Standard arithmetic for reals for all computers
Like two’s complement
Keep as much precision as possible in formats
Help programmer with errors in real arithmetic
+∞, -∞, Not-A-Number (NaN), exponent overflow,
exponent underflow
Keep encoding that is somewhat compatible with two’s
complement
E.g., 0 in Fl. Pt. is 0 in two’s complement
Make it possible to sort without needing to do floating
point comparison
EI 209 Chapter 3.42
CSE, 2013
Scientific Notation (e.g., Base 10)
Normalized scientific notation (aka standard form or exponential
notation):
r x Ei, E is exponent (usually 10), i is a positive or negative
integer, r is a real number ≥ 1.0, < 10
Normalized => No leading 0s
61 is 6.10 x 102, 0.000061 is 6.10 x10-5
EI 209 Chapter 3.43
CSE, 2013
Scientific Notation (e.g., Base 10)
(r x ei) x (s x ej) = (r x s) x ei+j
(1.999 x 102) x (5.5 x 103) = (1.999 x 5.5) x 105
= 10.9945 x 105
= 1.09945 x 106
(r x ei) / (s x ej) = (r / s) x ei-j
(1.999 x 102) / (5.5 x 103) = 0.3634545… x 10-1
= 3.634545… x 10-2
For addition/subtraction, you first must align:
(1.999 x 102) + (5.5 x 103)
= (.1999 x 103) + (5.5 x 103) = 5.6999 x 103
EI 209 Chapter 3.44
CSE, 2013
Floating Point:
Representing Very Small Numbers
Zero: Bit pattern of all 0s is encoding for 0.000
But 0 in exponent should mean most negative
exponent (want 0 to be next to smallest real)
Can’t use two’s complement (1000 0000two)
Bias notation: subtract bias from exponent
Single precision uses bias of 127; DP uses 1023
0 uses
0000 0000two => 0-127 =
∞, NaN uses 1111 1111two => 255-127 = +128
-127;
Smallest SP real can represent: 1.00…00 x 2-126
Largest SP real can represent: 1.11…11 x 2+127
EI 209 Chapter 3.45
CSE, 2013
Bias Notation (+127)
How it is interpreted
How it is encoded
∞, NaN
Getting
closer to
zero
Zero
EI 209 Chapter 3.46
CSE, 2013
What About Real Numbers in Base 2?
x Ei, E where exponent is (2), i is a positive or
negative integer, r is a real number ≥ 1.0, < 2
r
Computers
version of normalized scientific notation
called Floating Point notation
EI 209 Chapter 3.47
CSE, 2013
Floating Point Numbers
32-bit word has 232 patterns, so must be approximation of real
numbers ≥ 1.0, < 2
IEEE 754 Floating Point Standard:
1 bit for sign (s) of floating point number
8 bits for exponent (E)
23 bits for fraction (F)
(get 1 extra bit of precision if leading 1 is implicit)
(-1)s x (1 + F) x 2E
Can represent from 2.0 x 10-38 to 2.0 x 1038
EI 209 Chapter 3.48
CSE, 2013
Floating Point Numbers
What about bigger or smaller numbers?
IEEE 754 Floating Point Standard:
Double Precision (64 bits)
1 bit for sign (s) of floating point number
11 bits for exponent (E)
52 bits for fraction (F)
(get 1 extra bit of precision if leading 1 is implicit)
(-1)s x (1 + F) x 2E
Can represent from 2.0 x 10-308 to 2.0 x 10308
32 bit format called Single Precision
EI 209 Chapter 3.49
CSE, 2013
Representing Big (and Small) Numbers
What if we want to encode the approx. age of the earth?
4,600,000,000
or
4.6 x 109
or the weight in kg of one a.m.u. (atomic mass unit)
0.0000000000000000000000000166
or 1.6 x 10-27
There is no way we can encode either of the above in a
32-bit integer.
Floating point representation
(-1)sign x F x 2E
Still have to fit everything in 32 bits (single precision)
s E (exponent)
1 bit
8 bits
F (fraction)
23 bits
The base (2, not 10) is hardwired in the design of the FPALU
More bits in the fraction (F) or the exponent (E) is a trade-off
between precision (accuracy of the number) and range (size of
the number)
EI 209 Chapter 3.50
CSE, 2013
Exception Events in Floating Point
Overflow (floating point) happens when a positive
exponent becomes too large to fit in the exponent field
Underflow (floating point) happens when a negative
exponent becomes too large to fit in the exponent field
-∞
+∞
- largestE -smallestF
+ largestE -largestF
- largestE +smallestF
+ largestE +largestF
One way to reduce the chance of underflow or overflow
is to offer another format that has a larger exponent field
Double precision – takes two MIPS words
s E (exponent)
1 bit
F (fraction)
11 bits
20 bits
F (fraction continued)
32 bits
EI 209 Chapter 3.51
CSE, 2013
“Father” of the Floating point standard
IEEE Standard 754
for Binary FloatingPoint Arithmetic.
1989
ACM Turing
Award Winner!
Prof. Kahan
www.cs.berkeley.edu/~wkahan/
…/ieee754status/754story.html
EI 209 Chapter 3.52
CSE, 2013
IEEE 754 FP Standard
Most (all?) computers these days conform to the IEEE 754
floating point standard
(-1)sign x (1+F) x 2E-bias
Formats for both single and double precision
F is stored in normalized format where the msb in F is 1 (so there
is no need to store it!) – called the hidden bit
To simplify sorting FP numbers, E comes before F in the word and
E is represented in excess (biased) notation where the bias is -127
(-1023 for double precision) so the most negative is 00000001 =
21-127 = 2-126 and the most positive is 11111110 = 2254-127 = 2+127
Examples (in normalized format)
Smallest+: 0 00000001 1.00000000000000000000000 = 1 x 21-127
Zero:
0 00000000 00000000000000000000000 = true 0
Largest+: 0 11111110 1.11111111111111111111111 =
2-2-23 x 2254-127
1.02 x 2-1 = 0 01111110 1.00000000000000000000000
0.7510 x 24 = 0 10000010 1.10000000000000000000000
EI 209 Chapter 3.54
CSE, 2013
Ex: Converting Binary FP to Decimal
BEE00000H is the hex. Rep. Of an IEEE 754 SP FP number
10111 1101 110 0000 0000 0000 0000 0000
(-1)S x (1 + Significand) x 2(Exponent-127)
°Sign: 1 => negative
°Exponent:
• 0111 1101two = 125ten
• Bias adjustment: 125 - 127 = -2
°Significand:
1 + 1x2-1+ 1x2-2 + 0x2-3 + 0x2-4 + 0x2-5 +...
=1+2-1 +2-2 = 1+0.5 +0.25 = 1.75
°Represents: -1.75tenx2-2 = -0.4375 (= -4.375x10-1 )
EI 209 Chapter 3.55
CSE, 2013
Ex: Converting Decimal to FP
-1.275 x 101
1. Denormalize: -12. 75
2. Convert integer part:
12 = 8 + 4 = 11002
3. Convert fractional part:
.75 = .5 + .25 = .112
4. Put parts together and normalize:
1100.11 = 1.10011 x 23
5. Convert exponent: 127 + 3 = 128 + 2 = 1000 00102
11000 0010 100 1100 0000 0000 0000 0000
The Hex rep. is C14C0000H
EI 209 Chapter 3.56
CSE, 2013
Representation for 0
How to represent 0?
exponent: all zeros
significand: all zeros
What about sign? Both cases valid.
+0: 0 00000000 00000000000000000000000
-0: 1 00000000 00000000000000000000000
EI 209 Chapter 3.57
CSE, 2013
Representation for +∞/-∞
∞ :infinity
How to represent +∞/-∞?
• Exponent : all ones (11111111B = 255)
• Significand: all zeros
+∞ : 0 11111111 00000000000000000000000
-∞ : 1 11111111 00000000000000000000000
Operations
5 / 0 = +∞,
5+(+∞) = +∞,
5 - (+∞) = -∞,
EI 209 Chapter 3.58
-5 / 0 = -∞
(+∞)+(+∞) = +∞
(-∞) - (+∞) = -∞
etc
CSE, 2013
Representation for “Not a Number”
Sqrt (- 4.0) = ?
0/0 = ?
Called Not a Number (NaN) - “非数”
How to represent NaN
Exponent = 255
Significand: nonzero
NaNs can help with debugging
Operations
sqrt (-4.0) = NaN
op (NaN,x) = NaN
+∞- (+∞) = NaN
etc.
EI 209 Chapter 3.59
0/0 = NaN
+∞+(-∞) = NaN
∞/∞ = NaN
CSE, 2013
Representation for Denorms(非规格化数)
What have we defined so far? (for SP)
Exponent
Significand
Object
0
0
+/-0
0
nonzero
Denorms
1-254
anything
implicit leading 1
Norms
255
0
+/- infinity
255
nonzero
NaN
EI 209 Chapter 3.60
Used to represent
Denormalized
numbers
CSE, 2013
Group Discussion 1: Questions about IEEE 754
Four students form a group and discuss the following
question.
What about following type converting: will it output
true?
if ( i == (int) ((float) i) ) {
printf (“true”);
}
if ( f == (float) ((int) f) ) {
printf (“true”);
}
EI 209 Chapter 3.61
CSE, 2013
Question II about IEEE 754
How about FP add associative? (X+Y)+Z=X+(Y+Z)
x = – 1.5 x 1038, y = 1.5 x 1038,
z = 1.0
(x+y)+z = (–1.5x1038+1.5x1038 ) +1.0 = 1.0
x+(y+z) = –1.5x1038+ (1.5x1038+1.0) = 0.0
EI 209 Chapter 3.62
CSE, 2013
IEEE 754 FP Standard Encoding
Special encodings are used to represent unusual events
± infinity for division by zero
NAN (not a number) for the results of invalid operations such as
0/0
True zero is the bit string all zero
Single Precision
E (8)
F (23)
0000 0000
0
0000 0000
nonzero
0111 1111 to anything
+127,-126
1111 1111
+0
1111 1111
nonzero
EI 209 Chapter 3.63
Double Precision
Object
Represented
E (11)
F (52)
0000 … 0000
0
true zero (0)
0000 … 0000 nonzero ± denormalized
number
0111 …1111 to anything ± floating point
+1023,-1022
number
1111 … 1111
-0
± infinity
1111 … 1111
nonzero not a number
(NaN)
CSE, 2013
Support for Accurate Arithmetic
IEEE 754 FP rounding modes
Always round up (toward +∞)
Always round down (toward -∞)
Truncate
Round to nearest even (when the Guard || Round || Sticky are
100) – always creates a 0 in the least significant (kept) bit of F
Rounding (except for truncation) requires the hardware to
include extra F bits during calculations
Guard bit – used to provide one F bit when shifting left to normalize
a result (e.g., when normalizing F after division or subtraction)
Round bit – used to improve rounding accuracy
Sticky bit – used to support Round to nearest even; is set to a 1
whenever a 1 bit shifts (right) through it (e.g., when aligning F
during addition/subtraction)
F = 1 . xxxxxxxxxxxxxxxxxxxxxxx G R S
EI 209 Chapter 3.64
CSE, 2013
Floating Point Addition
Addition (and subtraction)
(F1 2E1) + (F2 2E2) = F3 2E3
Step 0: Restore the hidden bit in F1 and in F2
Step 1: Align fractions by right shifting F2 by E1 - E2 positions
(assuming E1 E2) keeping track of (three of) the bits shifted out
in G R and S
Step 2: Add the resulting F2 to F1 to form F3
Step 3: Normalize F3 (so it is in the form 1.XXXXX …)
- If F1 and F2 have the same sign F3 [1,4) 1 bit right shift F3
and increment E3 (check for overflow)
- If F1 and F2 have different signs F3 may require many left shifts
each time decrementing E3 (check for underflow)
Step 4: Round F3 and possibly normalize F3 again
Step 5: Rehide the most significant bit of F3 before storing the
result
EI 209 Chapter 3.65
CSE, 2013
Floating Point Addition Example
Add
(0.5 = 1.0000 2-1) + (-0.4375 = -1.1100 2-2)
Hidden bits restored in the representation above
Shift significand with the smaller exponent (1.1100) right
until its exponent matches the larger exponent (so once)
Step 0:
Step 1:
Step 2:
Step 3: Normalize the sum, checking for exponent over/underflow
0.001 x 2-1 = 0.010 x 2-2 = .. = 1.000 x 2-4
Step 4: The sum is already rounded, so we’re done
Step 5: Rehide the hidden bit before storing
EI 209 Chapter 3.67
Add significands
1.0000 + (-0.111) = 1.0000 – 0.111 = 0.001
CSE, 2013
Exercise
Given A=2.6125×101, B=4.150390625×10-1, Calculate
the sum of A and B by hand, assuming A and B are
stored by the following format, Assume 1 guard, 1 round
bit, and 1 sticky bit, and round to the nearest even. Show
all the steps.
Sign
1 bit
Exponent
5 bits
Fraction
10 bits
S
E
F
EI 209 Chapter 3.68
CSE, 2013
Solution:
a.
2.6125×101 + 4.150390625×10–1
2.6125×101 = 26.125 = 11010.001 = 1.1010001000×24
4.150390625×10–1 = .4150390625 = .011010100111
=1.1010100111×2–2
Shift binary point 6 to the left to align exponents,
GR
1.1010001000 00
+.0000011010 10 0111 (Guard = 1, Round = 0, Sticky = 1)
-------------------1.1010100010 10
In this case the extra bits (G,R,S) are more than half of the least significant bit
(0).
Thus, the value is rounded up.
1.1010100011 × 24 = 11010.100011 × 20 = 26.546875
= 2.6546875 × 101
EI 209 Chapter 3.69
CSE, 2013
Floating Point Multiplication
Multiplication
(F1 2E1) x (F2 2E2) = F3 2E3
Step 0: Restore the hidden bit in F1 and in F2
Step 1: Add the two (biased) exponents and subtract the bias
from the sum, so E1 + E2 – 127 = E3
also determine the sign of the product (which depends on the
sign of the operands (most significant bits))
Step 2: Multiply F1 by F2 to form a double precision F3
Step 3: Normalize F3 (so it is in the form 1.XXXXX …)
- Since F1 and F2 come in normalized F3 [1,4) 1 bit right shift
F3 and increment E3
- Check for overflow/underflow
Step 4: Round F3 and possibly normalize F3 again
Step 5: Rehide the most significant bit of F3 before storing the
result
EI 209 Chapter 3.70
CSE, 2013
Floating Point Multiplication Example
Multiply
(0.5 = 1.0000 2-1) x (-0.4375 = -1.1100 2-2)
Step 0: Hidden bits restored in the representation above
Step 1: Add the exponents (not in bias would be -1 + (-2) = -3
and in bias would be (-1+127) + (-2+127) – 127 = (-1
-2) + (127+127-127) = -3 + 127 = 124
Step 2: Multiply the significands
1.0000 x 1.110 = 1.110000
Step 3: Normalized the product, checking for exp over/underflow
1.110000 x 2-3 is already normalized
Step 4: The product is already rounded, so we’re done
Step 5: Rehide the hidden bit before storing
EI 209 Chapter 3.72
CSE, 2013
MIPS Floating Point Instructions
MIPS has a separate Floating Point Register File
($f0, $f1, …, $f31) (whose registers are used in
pairs for double precision values) with special instructions
to load to and store from them
lwcl
$f1,54($s2)
#$f1 = Memory[$s2+54]
swcl
$f1,58($s4)
#Memory[$s4+58] = $f1
And supports IEEE 754 single
add.s $f2,$f4,$f6 #$f2 = $f4 + $f6
and double precision operations
add.d $f2,$f4,$f6 #$f2||$f3 =
$f4||$f5 + $f6||$f7
similarly for sub.s, sub.d, mul.s, mul.d, div.s,
div.d
EI 209 Chapter 3.73
CSE, 2013
MIPS Floating Point Instructions, Con’t
And floating point single precision comparison operations
c.x.s $f2,$f4
#if($f2 < $f4) cond=1;
else cond=0
where x may be eq, neq, lt, le, gt, ge
and double precision comparison operations
c.x.d $f2,$f4
#$f2||$f3 < $f4||$f5
cond=1; else cond=0
And floating point branch operations
bclt
25
#if(cond==1)
go to PC+4+25
bclf
25
#if(cond==0)
go to PC+4+25
EI 209 Chapter 3.74
CSE, 2013
Frequency of Common MIPS Instructions
Only included those with >3% and >1%
SPECint
SPECfp
SPECint
SPECfp
addu
5.2%
3.5%
add.d
0.0%
10.6%
addiu
9.0%
7.2%
sub.d
0.0%
4.9%
or
4.0%
1.2%
mul.d
0.0%
15.0%
sll
4.4%
1.9%
add.s
0.0%
1.5%
lui
3.3%
0.5%
sub.s
0.0%
1.8%
lw
18.6%
5.8%
mul.s
0.0%
2.4%
sw
7.6%
2.0%
l.d
0.0%
17.5%
lbu
3.7%
0.1%
s.d
0.0%
4.9%
beq
8.6%
2.2%
l.s
0.0%
4.2%
bne
8.4%
1.4%
s.s
0.0%
1.1%
slt
9.9%
2.3%
lhu
1.3%
0.0%
slti
3.1%
0.3%
sltu
3.4%
0.8%
EI 209 Chapter 3.75
CSE, 2013