Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Data analysis wikipedia , lookup
Entity–attribute–value model wikipedia , lookup
Clusterpoint wikipedia , lookup
Database model wikipedia , lookup
3D optical data storage wikipedia , lookup
Data vault modeling wikipedia , lookup
Resource Description Framework wikipedia , lookup
Information privacy law wikipedia , lookup
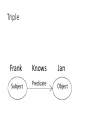
Vocabularies and Linked Data IST 653 Benefits of Subject Headings • Improves Resource Discovery • Users can retrieve meaningful sets of digital objects • Retrieve by: • • • • Type: Audio, Moving Image, Document Format: .wav, .tif, .pdf Place: Albany County (N.Y.) Person: Cuomo, Mario M., 1932-2015 • Consistent terms are used for Names and Subjects • There are many authorities • Ontology and authority are used interchangeably Authority control or Controlled Vocabularies • Organizes bibliographic information • Dictates what you can put in the metadata field • Uses one distinct spelling • Names of people, places, things, and concepts are authorized • Facilitates browsing • Subject and Name authorities were the only option for searching before the rise of computerized search indexes • Decades long, tried and true method for organizing information Metadata, Vocabularies, Content, Format • Metadata Standard: structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use or manage an information resource ex. MARC, Dublin Core, EAD • Content Standard: is a set of rules for describing information DACS, RDA, AACR2 • Controlled Format: rules concerning the allowable data types and formatting of information ISO ex. 2017-04-07 • Controlled Vocabulary: standardized list of terms that been selected for consistent use in describing information LCSH, SKOS, Inconsistent Values for Resource Type • No consistency without control • Creating unique entries • Human users can make read it, but computers cannot logically • Computers very literal • Nearly impossible to sustain or migrate metadata into the future Equivalence relationship Handles Hierarchy of terms • A stricter form of vocabulary is a Thesaurus • Broader terms • Narrower terms Spectrum of Controlled Vocabularies Handles for Ambiguity & Disambiguation • Bank: • (Financial Institution ) • (Container) • (A mound of dirt) Rise of Search • Founded by Larry Page and Sergey Brin • Many server farms • Each composed of thousands of low-cost computers running stripped-down versions of Linux • Google does not give out specifics on how their process works • Estimated more than 450,000 servers around the world Google’s Search • Google knows the web is unstructured. • Takes messy web, and creates orderly indexs • Crawls web creates PageRank • PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites • Search, until now, is dominated by this paradigm. Linked Data or Semantic Web • Coined by Tim Berners-Lee and part of his original plan for the World Wide Web • Uses XML standard called Resource Description Framework or RDF • We are using XML, so isn’t the web already understandable by computers? • The Semantic Web was laid out in a famous article published 2001 in Scientific American by Tim Berners-Lee, James Hendler, and Ora Lassila But, we have XML • XML marked up web information and structured it • Computers could read XML documents, and restructure data, manipulate, update and delete and send over the web safely • XML allowed computers to “talk” to each other via serialization. • Before that, most documents were binary meaning that each document needed the specific program to run read the document • For example, a Word document needed MS Word to read it Before Linked Data • The web is linked together • Lots of relationships • Great for humans, • We can link to images, charts, other documents • But, computers don’t understand the relationships like humans do Linked Data • Explicitly express things and relationships, like names, birthdays, places, friend, parent, etc. • Links to a name, like Frank in a website to another person, Jan on another website etc. • Frank knows Jan and she is parent of Tim • Express it in a common format, using RDFa or JSON-LD • How do we do it: • Authorities • URIs • Triples Resource Description Framework in Attributes (RDFa) • XML based standard • is a W3C Recommendation that adds a set of attribute-level extensions to HTML, XHTML and various XML-based document types for embedding rich metadata within Web documents. • XML /serialization is the physical format of data, while the RDFa is a data model so that we can represent the book's inherent meaning. JSON for Linking Data • JSON, or JavaScript Object Notation, is a minimal, readable format for structuring data. It is used primarily to transmit data between a server and web application, as an alternative to XML. • JSON-LD, or JavaScript Object Notation for Linked Data, is a method of encoding Linked Data using JSON Triples • Subject — The resource that’s being described. Book, person, LCSH, website, function, anything that can be described can be a subject. This is always a URI (uniform resource identifier) of some kind. That could be a URL. It could also be another kind of identifier, such as an ISBN.2 • Predicate — Also known as a “property,” this is a URI which fulfills the role of the database field name or the name of an XML tag. It declares what’s going to be declared about an object. A very simple example would be <dc:title> in XML. In RDF, this would be the equivalent of <http://purl.org/dc/terms/title>, although it may sometimes even be written as dc:title (see “Serialization” below) • Object — The value of a statement. This can be a URI, like the other two, or it can be what’s called a “Literal,” meaning a string, a number, or a date, enclosed in quotation marks. Strings are what we normally think of as text. We can get more specific about what this Literal is with datatype and language modifiers (see “Datatype and Language Modifiers“). Triple Frank Knows Jan Google Knowledge Graph • We have auto complete, but that is using older indexing technology • Knowledge graph is using Linked Data to answer questions for the user. • https://www.google.com/