Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
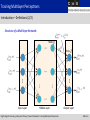
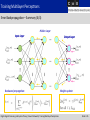
Neural Networks – Training Multilayer Perceptrons Mohamed Krini Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory Contents of the Lecture Entire Semester Introduction Pre-Processing and Feature Extraction Threshold Logic Units – Single Perceptrons Multilayer Perceptrons Training Multilayer Perceptrons Radial Basis Function Networks Learning Vector Quantization Kohonen Self-Organizing Maps Hopfield and Recurrent Networks Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-2 Contents of this Part Training Multilayer Perceptrons Introduction Gradient Descent Error Backpropagation Simulations Variants of Gradient Descent Sensitivity Analysis Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-3 Training Multilayer Perceptrons Introduction – Motivation Gradient Descent: Logistic regressions is only applicable for a two layer perceptron. A more common approach is the gradient descent. Visualization of the gradient using a real-valued function at a point . The gradient is determined as: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-4 Training Multilayer Perceptrons Introduction – Definitions (1/2) Definitions and Properties: A popular learning algorithm for multilayer network is the so-called backpropagation algorithm. The backpropagation algorithm is searching for the minimum of the error function in weight space using the method of gradient descent. The solution of the learning problem is the combination of weights that minimizes the error function. The continuity and differentiability of the error function must be guaranteed, since the learning method requires computation of the gradient of the error function at each iteration step. The chosen activation function should be continuous and differentiable to guarantee a continuous and differentiable error function. One of the more popular activation functions is the sigmoide function. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-5 Training Multilayer Perceptrons Introduction – Definitions (2/2) Structure of a Multilayer Network: Node Node Input Layer Hidden Layer Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Output Layer Slide V-6 Training Multilayer Perceptrons Gradient Descent – Formal Approach (1/10) Definitions for Training: Consider a feed-forward network with Given is a training set consisting of input and output units: pairs of input and output patterns: Input vector: Output vector: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-7 Training Multilayer Perceptrons Gradient Descent – Formal Approach (2/10) Error Function: Goal: The output and the desired output should be identical for using a learning algorithm. This is achieved by minimizing the error function of the network: We need to calculate the partial derivatives of the error with respect to the weights to determine the direction of the correction step: Bias value included Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-8 Training Multilayer Perceptrons Gradient Descent – Formal Approach (3/10) Error Function (continued): The error of the multilayer perceptron is the sum of individual errors over the training patterns: Individual error depends on weights through the network input: . Using the chain rule we obtain: (Extended) input vector at -neuron Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-9 Training Multilayer Perceptrons Gradient Descent – Formal Approach (4/10) Error Function (continued): • The individual error at the output can be computed as follows: Considering that only the output function The abbreviation of a neuron is depending on the network input of a neuron , the derivative can be solved according to: will take an important rule in the following. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-10 Training Multilayer Perceptrons Gradient Descent – Formal Approach (5/10) Derivation of Update Rules: To solve the sum of the errors two cases have to be distinguished: 1. The neuron is an output neuron with 2. The neuron is a hidden neuron with Second case: Neuron in hidden layer First case: Neuron in output layer Input Layer Hidden Layer Output Layer Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-11 Training Multilayer Perceptrons Gradient Descent – Formal Approach (6/10) Derivation of Update Rules – First Case: Now we consider the first case where the neuron with is an output neuron Node Node Node Input Layer Hidden Layer Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Output Layer Slide V-12 Training Multilayer Perceptrons Gradient Descent – Formal Approach (7/10) Update Rule – First Case: For the first case, the sum the input for The gradient can be simplified since the output is independent of : can finally be computed as follows: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-13 Training Multilayer Perceptrons Gradient Descent – Formal Approach (8/10) Update Rule – First Case (continued): The network weights are updated in the negative gradient direction. The learning constant defines the step length of the correction. The corrections of the weights are given by: Often the weight corrections are performed sequentially after each pattern presentation (called on-line training). For batch training (also called offline training) the weight corrections are computed over all training patterns. Afterwards, the sum of the corrections is used for the update. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-14 Training Multilayer Perceptrons Gradient Descent – Formal Approach (9/10) Update Rule – First Case (continued): The update equation depends on the chosen activation and output function (for -neuron). We consider a special case where a sigmoide function is used for activation and an identity function for the output. Using these assumptions we get: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-15 Training Multilayer Perceptrons Gradient Descent – Formal Approach (10/10) Update Rule – First Case (continued): The corrections The update of the weights are finally computed according to: rule for a weight vector is defined as follows (rule for on-line processing): Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-16 Training Multilayer Perceptrons Error Backpropagation (1/5) Derivation of Update Rules – Second Case: Now we consider the second case where the neuron with is a hidden neuron Node Input Layer Hidden Layer Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Output Layer Slide V-17 Training Multilayer Perceptrons Error Backpropagation (2/5) Update Rule – Second Case: The output (neuron ) is a function of the network input and of the network inputs of the successor neurons with (neuron ) Using the chain rule we obtain: Since both sums are limited they can be exchanged, thus: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-18 Training Multilayer Perceptrons Error Backpropagation (3/5) Update Rule – Second Case (continued): The network input can be written as a linear combination of the weights and the input values: The partial derivative of the network input with respect to can be solved according to : All terms in the sum with are set to zero. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-19 Training Multilayer Perceptrons Error Backpropagation (4/5) Update Rule – Second Case (continued): The result is a recursive equation called error backpropagation: The sum of the last equation can be seen as the error Using the recursive of a neuron in a hidden layer. equation, the update of the weighting coefficients is determined by: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-20 Training Multilayer Perceptrons Error Backpropagation (5/5) Update Rule – Second Case (continued): Again, let us consider a logistic function for the activation function as well as identity for the output function. As a result, a simplified update equation for the weighting coefficients is obtained: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-21 Training Multilayer Perceptrons Error Backpropagation – Summary (1/4) Hidden Layer Input Layer Output Layer Initialization: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-22 Training Multilayer Perceptrons Error Backpropagation – Summary (2/4) Hidden Layer Input Layer Forward propagation: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Output Layer Logistic function applied Slide V-23 Training Multilayer Perceptrons Error Backpropagation – Summary (3/4) Hidden Layer Input Layer Error term: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Output Layer Weight update: Slide V-24 Training Multilayer Perceptrons Error Backpropagation – Summary (4/4) Hidden Layer Input Layer Backward propagation: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Output Layer Weight update: Slide V-25 Training Multilayer Perceptrons Gradient Descent – Examples Gradient Descent – Examples Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-26 Training Multilayer Perceptrons Gradient Descent – Example (1/6) Training for the Negation: Output Layer Input Layer A two layer perceptron 1 1 0 is used for the negation. Two appropriate parameters The gradient 0 and of the network have to be found. descent approach is used to determine the weight Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons and the bias Slide V-27 Training Multilayer Perceptrons Gradient Descent – Example (2/6) Error Functions for the Negation: Squared error function for Squared error Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons function for Slide V-28 Training Multilayer Perceptrons Gradient Descent – Example (3/6) Sum of the Error Functions: The sum of the squared error functions in dependence of the weight and the bias is depicted on left. A sigmoide function is used as activation function. Since a sigmoide function is employed the squared error function is differentiable and a solution for the chosen weight and bias can be found. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-29 Training Multilayer Perceptrons Gradient Descent – Example (4/6) Gradient Descent for the Negation: Online Training Batch Training Weight Weight Every 10 epoch Learning rate: Bias Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Learning rate: Bias Slide V-30 Training Multilayer Perceptrons Gradient Descent – Example (5/6) 3-Dimensional Visualization of the Error: The characteristic of the gradient descent (with batch training) is included into the error surface function. Obviously, the training was successful. The error (black curve) decreases slowly and finally reaches the region with a very small error. Due to the properties of the logistic function, the error cannot vanish completely. The training is performed values of , learning rate of Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons with initial and a Slide V-31 Training Multilayer Perceptrons Gradient Descent – Example (6/6) Error Functions for Online and Batch Processing: With batch processing Error - Online processing - Batch processing the weight corrections are computed for each pattern. The sum of weight corrections are used for the weight adaptation. With online processing Every 10 epoch Epoch the weight corrections are made sequentially. Both curves converge towards the same error value. The curve for batch processing shows a slightly faster convergence behavior. The differences of these two processing types are much higher. However, in this experiment we used only a small data set for the training. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-32 Training Multilayer Perceptrons Variants of Gradient Descent Variants of Gradient Descent Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-33 Training Multilayer Perceptrons Variants of Gradient Descent – Part I Different Update Rules: The update rule for a weight at iteration The correction is defined according to: term for standard backpropagation (gradient descent) is defined as: Manhattan-Training considers only the sign of the gradient. Useful for error functions that have a flat characteristic behavior: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-34 Training Multilayer Perceptrons Variants of Gradient Descent – Part II Different Update Rules (continued): The momentum method uses an additional term (the last update term) to the gradient descent step. The training can be accelerated in regions where the error function is flat but decreases in an uniform direction: Self-adaptive error backpropagation: The learning constant is increased if the current and the previous gradients have the same sign. Whereas the learning constant is decreased if these gradients have different signs: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-35 Training Multilayer Perceptrons Variants of Gradient Descent – Part III Different Update Rules (continued): Resilient error backpropagation: Can be seen as a combination of the manhattan training and the self-adaptive error backpropagation. The update weight is determined depending on the current and the previous gradient: Appropriate values for the increment and decrement are: Resilient error backpropagation should be used only for batch training (online training may become instable). Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-36 Training Multilayer Perceptrons Variants of Gradient Descent – Part IV Error function Different Update Rules (continued): Quick propagation: Apex Error function is approximated by a parabola at current weight position. From the current and the previous gradient the apex of the parabola is determined. The corresponding weight to the apex is used as a new value. The weight update rule can be derived from the triangles: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-37 Training Multilayer Perceptrons Variants of Gradient Descent – Part V Weight decay: Large weighting coefficients of a neural network (determined by the training) are inappropriate. They have two disadvantages: 1. They simply reach the saturation region of the logistic function, thus a very low gradient results that almost stops the training. 2. Also the risk of overfitting is increased to special characteristics of the training data. To avoid a strong increase of the weights, the following improvement can be used (current weight updates are reduced by a small fraction of the last weights): An update term that penalizes large values can be derived from an extended error function: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-38 Training Multilayer Perceptrons Gradient Descent – Example Momentum (1/3) Gradient Descent with Momentum Term: Without Momentum Term With Momentum Term Weight Weight Every 10 epoch Learning rate: Bias Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Learning rate: Bias Slide V-39 Training Multilayer Perceptrons Gradient Descent – Example Momentum (2/3) 3-Dimensional Visualization of the Error: The characteristic of the gradient descent with momentum is included into the error surface function. Compared to prior experiments (using gradient descent without a momentum term), a faster convergence is achieved, i.e. the region with a very small error is achieved in a faster way. The training is performed with initial values of , , and a learning rate of . The factor for the momentum term is set by . Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-40 Training Multilayer Perceptrons Gradient Descent – Example Momentum (3/3) Error Function with Momentum Term: The error function without and with momentum for a two layer perceptron of the negation is depicted (batch processing was used). - With momentum - Without momentum Circles show the error position Error for every 10 epochs. The speed difference is even higher for larger networks with huge training data sets (training patterns). Using a momentum term the training Epoch can be accelerated about twice as fast. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-41 Training Multilayer Perceptrons Sensitivity Analysis Sensitivity Analysis Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-42 Training Multilayer Perceptrons Sensitivity Analysis (1/3) Motivation: A complex neural network can be seen as a black box. The difficulty of such a network system is to understand its knowledge after the training (a geometric interpretation usually is not possible). The so-called sensitivity analysis can be performed to analyze the importance of different inputs to the network. The derivative of the outputs with respect to the inputs (change of output relative to change of input) are added over all output neurons and learning patterns: Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-43 Training Multilayer Perceptrons Sensitivity Analysis (2/3) Derivation: Using the chain rule the derivative can be rewritten as: Assumption: Identity as output function The second term can also be formulated as: The recursion formula is given as follows : Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-44 Training Multilayer Perceptrons Sensitivity Analysis (3/3) Derivation (continued): For the first hidden layer or for a two layer perceptron, we obtain (this formula marks the start of the recursion): Using the identity and the logistic function for the output and the activation function, the recursion is simplified to: and the start of the recursion is (neuron in the first hidden layer ): Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons , Slide V-45 Training Multilayer Perceptrons Literature Further details can be found in: R. Rojas: Neural Networks – A Systematic Introduction (Chapter 7-8), Springer, Berlin, Germany, 1996. C. Borgelt, F. Klawonn, R. Kruse, D. Nauck: Neuro-Fuzzy-Systeme (Chapter 4), Vieweg Verlag, Wiesbaden, 2003 (in German). S. Haykin: Neural Networks and Learning Machines (Chapter 4), Prentice-Hall, 3rd edition, 2009. C. Bishop: Neural Networks for Pattern Recognition (Chapter 4), Oxford University Press, UK, 1996. Digital Signal Processing and System Theory| Neural Networks| Training Multilayer Perceptrons Slide V-46