Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
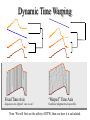
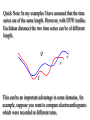
Indexing and Mining Time Series Data Dr Eamonn Keogh Computer Science & Engineering Department University of California - Riverside Riverside,CA 92521 [email protected] 25.1750 25.2250 25.2500 25.2500 25.2750 25.3250 25.3500 25.3500 25.4000 25.4000 25.3250 25.2250 25.2000 25.1750 .. .. 24.6250 24.6750 24.6750 24.6250 24.6250 24.6250 24.6750 24.7500 What are Time Series? A time series is a collection of observations made sequentially in time. 29 28 27 26 25 24 23 0 50 100 150 200 250 300 350 400 450 500 Note that virtually all similarity measurements, indexing and dimensionality reduction techniques discussed in this tutorial can be used with other data types. Time Series are Ubiquitous! I People measure things... • The presidents popularity rating. • Their blood pressure. • The annual rainfall in Brazil. • The value of their Yahoo stock. • The number of web hits per second. … and things change over time. Thus time series occur in virtually every medical, scientific and businesses domain. Time Series are Ubiquitous! II A random sample of 4,000 graphics from 15 of the world’s newspapers published from 1974 to 1989 found that more than 75% of all graphics were time series (Tufte, 1983). Time Series are Everywhere… Bioinformatics: Aach, J. and Robotics: Schmill, M., Oates, T. & Church, G. (2001). Aligning gene expression time series with time warping algorithms. Bioinformatics. Volume 17, pp 495-508. Cohen, P. (1999). Learned models for continuous planning. In 7th International Workshop on Artificial Intelligence and Statistics. Medicine: Caiani, E.G., et. al. (1998) Warped-average template technique to track on a cycle-by-cycle basis the cardiac filling phases on left ventricular volume. IEEE Computers in Cardiology. Gesture Recognition: Gavrila, D. M. & Davis,L. S.(1995). Towards 3-d model-based tracking and recognition of human movement: a multi-view approach. In IEEE IWAFGR Chemistry: Gollmer, K., & Posten, C. (1995) Detection of distorted pattern using dynamic time warping algorithm and application for supervision of bioprocesses. IFAC CHEMFAS-4 Meteorology/ Tracking/ Biometrics / Astronomy / Finance / Manufacturing … Why is Working With Time Series so Difficult? Part I Answer: How do we work with very large databases? 1 Hour of EKG data: 1 Gigabyte. Typical Weblog: 5 Gigabytes per week. Space Shuttle Database: 158 Gigabytes and growing. Macho Database: 2 Terabytes, updated with 3 gigabytes a day. Since most of the data lives on disk (or tape), we need a representation of the data we can efficiently manipulate. Why is Working With Time Series so Difficult? Part II Answer: We are dealing with subjectivity The definition of similarity depends on the user, the domain and the task at hand. We need to be able to handle this subjectivity. Why is working with time series so difficult? Part III Answer: Miscellaneous data handling problems. • Differing data formats. • Differing sampling rates. • Noise, missing values, etc. We will not focus on these issues in this tutorial. Two Motivating Datasets Cylinder-Bell-Funnel Electrocardiogram (ECGs) c(t) = (6+) X[a,b](t) + (t) b(t) = (6+) X[a,b](t) (t-a)/(b-a) + (t) f(t) = (6+) X[a,b](t) (b-a)/(b-t) + (t) X[a,b] = { 1, if a t b, else 0 } Where and (t) are drawn from a standard normal distribution N(0,1), a is an integer drawn uniformly from the range [16,32] and (b-a) is an integer drawn uniformly from the range [32, 96]. Kadous 1999; Manganaris,1997; Saito 1994; Rodriguez 2000; Geurts 2001 Cylinder Funnel Bell Here is a simple motivation for the first half of the tutorial. You go to the doctor because of chest pains. Your ECG looks strange… You doctor wants to search a database to find similar ECG, in the hope that they will offer clues about your condition... Two questions: • How do we define similar? • How do we search quickly? Why do Time Series Similarity Matching? Defining the similarity between two time series is at the heart of most time series data mining applications/tasks Clustering Classification Rule Discovery Query by Content 10 s = 0.5 c = 0.3 Anomaly Detection Motif Discovery A 0 B 500 1000 C 1500 2000 A B C 2500 0 20 40 60 80 100 120 The similarity matching problem can come in two flavors I Query Q (template) 1 6 2 7 3 8 4 9 5 10 1: Whole Matching C6 is the best match. Database C Given a Query Q, a reference database C and a distance measure, find the Ci that best matches Q. The similarity matching problem can come in two flavors II Query Q (template) 2: Subsequence Matching Database C The best matching subsection. Given a Query Q, a reference database C and a distance measure, find the location that best matches Q. Note that we can always convert subsequence matching to whole matching by sliding a window across the long sequence, and copying the window contents. The Minkowski Metrics DQ, C qi ci n p p C i 1 Q p = 1 Manhattan (Rectilinear, City Block) p = 2 Euclidean p = Max (Supremum, “sup”) D(Q,C) Euclidean Distance Metric Given two time series Q = q1…qn and C = c1…cn their Euclidean distance is defined as: DQ, C qi ci n 2 C Q i 1 Ninety percent of all work on time series uses the Euclidean distance measure. D(Q,C) Optimizing the Euclidean Distance Calculation DQ, C qi ci n 2 Instead of using the Euclidean distance we can use the Squared Euclidean distance i 1 Dsquared Q, C qi ci n 2 i 1 Euclidean distance and Squared Euclidean distance are equivalent in the sense that they return the same rankings, clusterings and classifications. This optimization helps with CPU time, but most problems are I/O bound. Preprocessing the data before distance calculations If we naively try to measure the distance between two “raw” time series, we may get very unintuitive results. This is because Euclidean distance is very sensitive to some distortions in the data. For most problems these distortions are not meaningful, and thus we can and should remove them. In the next 4 slides I will discuss the 4 most common distortions, and how to remove them. • Offset Translation • Amplitude Scaling • Linear Trend • Noise Transformation I: Offset Translation 3 3 2.5 2.5 2 2 1.5 1.5 1 1 0.5 0.5 0 0 50 100 150 200 250 300 0 D(Q,C) 0 50 100 150 200 250 300 Q = Q - mean(Q) C = C - mean(C) D(Q,C) 0 0 50 100 150 200 250 300 50 100 150 200 250 300 Transformation II: Amplitude Scaling 0 100 200 300 400 500 600 700 800 900 1000 0 100 200 300 400 500 600 700 800 900 1000 Q = (Q - mean(Q)) / std(Q) C = (C - mean(C)) / std(C) D(Q,C) Transformation III: Linear Trend 5 4 Removed offset translation 3 2 Removed amplitude scaling 1 0 12 -1 10 -2 8 -3 0 20 40 60 80 100 120 140 160 180 200 6 4 2 0 5 -2 -4 0 4 20 40 60 80 100 120 140 160 180 200 Removed linear trend 3 2 The intuition behind removing linear trend is this. Removed offset translation 1 0 Removed amplitude scaling -1 Fit the best fitting straight line to the time series, then subtract that line from the time series. -2 -3 0 20 40 60 80 100 120 140 160 180 200 Transformation IIII: Noise 8 8 6 6 4 4 2 2 0 0 -2 -2 -4 0 20 40 60 80 100 120 140 -4 0 20 40 60 Q = smooth(Q) The intuition behind removing noise is this. Average each datapoints value with its neighbors. C = smooth(C) D(Q,C) 80 100 120 140 A Quick Experiment to Demonstrate the Utility of Preprocessing the Data 3 2 9 6 Clustered using Euclidean distance on the raw data. 8 5 7 4 1 9 8 7 Instances from Cylinder-Bell-Funnel with small, random amounts of trend, offset and scaling added. 5 6 4 3 2 1 Clustered using Euclidean distance on the raw data, after removing noise, linear trend, offset translation and amplitude scaling. Summary of Preprocessing The “raw” time series may have distortions which we should remove before clustering, classification etc. Of course, sometimes the distortions are the most interesting thing about the data, the above is only a general rule. We should keep in mind these problems as we consider the high level representations of time series which we will encounter later (Fourier transforms, Wavelets etc). Since these representations often allow us to handle distortions in elegant ways. Weighted Distance Measures I Intuition: For some queries different parts of the sequence are more important. Weighting features is a well known technique in the machine learning community to improve classification and the quality of clustering. Weighted Distance Measures II DQ, C DQ, C ,W qi ci n D(Q,C) 2 i 1 wi qi ci n 2 D(Q,C,W) i 1 The height of this histogram indicates the relative importance of that part of the query W Weighted Distance Measures III How do we set the weights? One Possibility: Relevance Feedback Definition: Relevance Feedback is the reformulation of a search query in response to feedback provided by the user for the results of previous versions of the query. Term Vector Term Weights [Jordan , Cow, Bull, River] [ 1 , 1 , 1 , 1 ] Search Display Results Gather Feedback Term Vector [Jordan , Cow, Bull, River] Term Weights [ 1.1 , 1.7 , 0.3 , 0.9 ] Update Weights Relevance Feedback for Time Series The original query The weigh vector. Initially, all weighs are the same. Note: In this example we are using a piecewise linear approximation of the data. We will learn more about this representation later. The initial query is executed, and the five best matches are shown (in the dendrogram) One by one the 5 best matching sequences will appear, and the user will rank them from between very bad (-3) to very good (+3) Based on the user feedback, both the shape and the weigh vector of the query are changed. The new query can be executed. The hope is that the query shape and weights will converge to the optimal query. Other Distance Measures for Time Series Other Distance Measures for Time Series In the past decade, there have been dozens of alternative distance measures for time series introduce into the literature. They are all a complete waste of time! Subjective Evaluation of Similarity Measures Euclidean Distance I believe that one of the best (subjective) ways to evaluate a proposed similarity measure is to use it to create a dendrogram of several time series from the domain of interest. A novel distance measure introduced into the literature 8 8 6 6 7 4 5 3 4 2 3 7 2 5 1 1 Results: Classification Error Rates Approach Cylinder-Bell-F’ Control-Chart Euclidean Distance 0.003 0.013 Aligned Subsequence 0.451 0.623 Piecewise Normalization 0.130 0.321 Autocorrelation Functions 0.380 0.116 Cepstrum 0.570 0.458 String (Suffix Tree) 0.206 0.578 Important Points 0.387 0.478 Edit Distance 0.603 0.622 String Signature 0.444 0.695 Cosine Wavelets 0.130 0.371 Hölder 0.331 0.593 Piecewise Probabilistic 0.202 0.321 Dynamic Time Warping Fixed Time Axis “Warped” Time Axis Sequences are aligned “one to one”. Nonlinear alignments are possible. Note: We will first see the utility of DTW, then see how it is calculated. Utility of Dynamic Time Warping: Example I, Machine Learning Cylinder-Bell-Funnel c(t) = (6+) • X[a,b](t) + (t) b(t) = (6+) • X[a,b](t) • (t-a)/(b-a) + (t) f(t) = (6+) • X[a,b](t) • (b-a)/(b-t) + (t) Where and (t) are drawn from a standard normal distribution N(0,1), a is an integer drawn uniformly from the range [16,32] and (b-a) is an integer drawn uniformly from the range [32, 96]. This dataset has been studied in a machine leaning context by many researchers. Kadous 1999; Manganaris,1997; Saito 1994; Rodriguez 2000; Geurts 2001; Recall that by definition, the instances of Cylinder-Bell-Funnel are warped in the time axis. Classification experiment on Cylinder-Bell-Funnel dataset • Training data consists of 10 exemplars from each class. • (One) Nearest Neighbor Algorithm. • “Leaving-one-out” evaluation, averaged over 100 runs. • Error rate using Euclidean Distance • Error rate using Dynamic Time Warping 26.10% 2.87% • Time to classify one instance using Euclidean Distance 1 sec • Time to classify one instance using Dynamic Time Warping 4,320 sec Dynamic time warping can reduce the error rate by an order of magnitude! Its classification accuracy is competitive with sophisticated approaches like Decision Trees, Boosting, Neural Networks, and Bayesian Techniques. But it is slow... Utility of Dynamic Time Warping: Example II, Data Mining Power-Demand Time Series. Each sequence corresponds to a week’s demand for power in a Dutch research facility in 1997 [van Selow 1999]. Wednesday was a national holiday For both dendrograms the two 5-day weeks are correctly grouped. Note however, that for Euclidean distance the three 4-day weeks are not clustered together. and the two 3-day weeks are also not clustered together. In contrast, Dynamic Time Warping clusters the three 4-day weeks together, and the two 3-day weeks together. Euclidean Dynamic Time Warping Time taken to create hierarchical clustering of power-demand time series. • Time to create dendrogram using Euclidean Distance 1.2 seconds • Time to create dendrogram using Dynamic Time Warping 3.40 hours Quick Note: In my examples I have assumed that the time series are of the same length. However, with DTW (unlike Euclidean distance) the two time series can be of different length. Q |n| |p| C This can be an important advantage in some domains, for example, suppose you want to compare electrocardiograms which were recorded at different rates. How is DTW Calculated? I We create a matrix the size of |Q| by |C|, then fill it in with the distance between every pair of point in our two time series. C Q C Q How is DTW Calculated? II Every possible warping between two time series, is a path though the matrix. We want the best one… DTW (Q, C ) min C Q C Q Warping path w K k 1 wk K How is DTW Calculated? III This recursive function gives use the minimum cost path. (i,j) = d(qi,cj) + min{ (i-1,j-1) , (i-1,j ) , (i,j-1) } C Q C Q Warping path w recursive function gives use the How is DTW This minimum cost path. Calculated? IIII (i,j) = d(qi,cj) + min{ (i-1,j-1) , (i-1,j ) , (i,j-1) } C (i,j) = d(qi,cj) + min{ (i-1,j-1) (i-1,j ) (i,j-1) } Let us visualize the cumulative matrix on a real world problem I This example shows 2 one-week periods from the power demand time series. Note that although they both describe 4-day work weeks, the blue sequence had Monday as a holiday, and the red sequence had Wednesday as a holiday. Let us visualize the cumulative matrix on a real world problem II What we have seen so far… • Dynamic time warping gives much better results than Euclidean distance on virtually all problems (recall the classification example, and the clustering example) • Dynamic time warping is very very slow to calculate! Is there anything we can do to speed up similarity search under DTW? Fast Approximations to Dynamic Time Warp Distance I C Q C Q Simple Idea: Approximate the time series with some compressed or downsampled representation, and do DTW on the new representation. How well does this work... Fast Approximations to Dynamic Time Warp Distance II 22.7 sec 1.3 sec .. strong visual evidence to suggests it works well. Good experimental evidence the utility of the approach on clustering, classification and query by content problems also has been demonstrated. Lower Bounding We can speed up similarity search under DTW by using a lower bounding function. Intuition Try to use a cheap lower bounding calculation as often as possible. Only do the expensive, full calculations when it is absolutely necessary. Algorithm Lower_Bounding_Sequential_Scan(Q) 1. best_so_far = infinity; 2. for all sequences in database 3. LB_dist = lower_bound_distance( Ci, Q); if LB_dist < best_so_far 4. 5. true_dist = DTW(Ci, Q); if true_dist < best_so_far 6. 7. best_so_far = true_dist; 8. index_of_best_match = i; endif 9. endif 10. 11. endfor Global Constraints • Slightly speed up the calculations • Prevent pathological warpings C Q C Q Sakoe-Chiba Band Itakura Parallelogram A global constraint constrains the indices of the warping path wk = (i,j)k such that j-r i j+r Where r is a term defining allowed range of warping for a given point in a sequence. r= Sakoe-Chiba Band Itakura Parallelogram Lower Bound of Yi et. al. max(Q) min(Q) LB_Yi Yi, B, Jagadish, H & Faloutsos, C. Efficient retrieval of similar time sequences under time warping. ICDE 98, pp 23-27. The sum of the squared length of gray lines represent the minimum the corresponding points contribution to the overall DTW distance, and thus can be returned as the lower bounding measure Lower Bound of Kim et al C A D LB_Kim Kim, S, Park, S, & Chu, W. An index-based approach for similarity search supporting time warping in large sequence databases. ICDE 01, pp 607-614 B The squared difference between the two sequence’s first (A), last (D), minimum (B) and maximum points (C) is returned as the lower bound A Novel Lower Bounding Technique I Q C U Sakoe-Chiba Band Ui = max(qi-r : qi+r) Li = min(qi-r : qi+r) L Q Q C U Q Itakura Parallelogram L A Novel Lower Bounding Technique II C C Q U Sakoe-Chiba Band (ci U i ) 2 if ci U i n LB _ Keogh(Q, C ) (ci Li ) 2 if ci Li i 1 0 otherwise L Q C Q C Itakura Parallelogram U LB_Keogh Q L The tightness of the lower bound for each technique is proportional to the length of gray lines used in the illustrations LB_Kim LB_Yi LB_Keogh Sakoe-Chiba LB_Keogh Itakura Let us empirically evaluate the quality of the proposed lowering bounding technique. Let us use an implementation free measure of quality. First we must discuss our experimental philosophy… Experimental Philosophy • We tested on 32 datasets from such diverse fields as finance, medicine, biometrics, chemistry, astronomy, robotics, networking and industry. The datasets cover the complete spectrum of stationary/ non-stationary, noisy/ smooth, cyclical/ non-cyclical, symmetric/ asymmetric etc • Our experiments are completely reproducible. We saved every random number, every setting and all data. • To ensure true randomness, we use random numbers created by a quantum mechanical process. • We test with the Sakoe-Chiba Band, which is the worst case for us (the Itakura Parallelogram would give us much better results). Tightness of Lower Bound Experiment • We measured T T Lower Bound Estimateof Dynamic Time W arp Distance True Dynamic Time W arp Distance 0T1 • For each dataset, we randomly extracted 50 sequences of length 256. We compared each sequence to the 49 others. The larger the better Query length of 256 is about the mean in the literature. • For each dataset we report T as average ratio from the 1,225 (50*49/2) comparisons made. LB_Keogh LB_Yi LB_Kim 1.0 0.8 0.6 0.4 0.2 0 1 17 18 2 19 3 20 4 21 5 22 6 7 23 8 24 9 25 10 26 11 27 12 28 13 29 14 15 30 16 31 32 Lower bounding is a very useful idea Motivating example revisited You go to the doctor because of chest pains. Your ECG looks strange… You doctor wants to search a database to find similar ECG, in the hope that they will offer clues about your condition... Two questions: • How do we define similar? • How do we search quickly? Indexing Time Series We have seen techniques for assessing the similarity of two time series. However we have not addressed the problem of finding the best match to a query in a large database... Query Q The obvious solution, to retrieve and examine every item (sequential scanning), simply does not scale to large datasets. 1 6 2 7 3 8 4 9 5 10 Database C We need some way to index the data... We can project time series of length n into ndimension space. The first value in C is the X-axis, the second value in C is the Y-axis etc. One advantage of doing this is that we have abstracted away the details of “time series”, now all query processing can be imagined as finding points in space... …we can project the query time series Q into the same n-dimension space and simply look for the nearest points. Q Interesting Sidebar The Minkowski Metrics have simple geometric interoperations... Euclidean Weighted Euclidean Manhattan Max …the problem is that we have to look at every point to find the nearest neighbor.. We can group clusters of datapoints with “boxes”, called Minimum Bounding Rectangles (MBR). R1 R2 R4 R5 R3 R6 R9 R7 R8 We can further recursively group MBRs into larger MBRs…. …these nested MBRs are organized as a tree (called a spatial access tree or a multidimensional tree). Examples include R-tree, Hybrid-Tree etc. R10 R11 R10 R11 R12 R1 R2 R3 R12 R4 R5 R6 R7 R8 R9 Data nodes containing points We can define a function, MINDIST(point, MBR), which tells us the minimum possible distance between any point and any MBR, at any level of the tree. MINDIST(point, MBR) = 5 MINDIST(point, MBR) = 0 We can use the MINDIST(point, MBR), to do fast search.. R10 R11 R10 R11 R12 R1 R2 R3 R12 R4 R5 R6 R7 R8 R9 Data nodes containing points If we project a query into ndimensional space, how many additional (nonempty) MBRs must we examine before we are guaranteed to find the best match? For the one dimensional case, the answer is clearly 2... If we project a query into ndimensional space, how many additional (nonempty) MBRs must we examine before we are guaranteed to find the best match? For the one dimensional case, the answer is clearly 2... For the two dimensional case, the answer is 8... If we project a query into ndimensional space, how many additional (nonempty) MBRs must we examine before we are guaranteed to find the best match? For the one dimensional case, the answer is clearly 2... For the three dimensional case, the answer is 26... More generally, in n-dimension space n For the two we must examine 3 -1 MBRs dimensional n = 21 10,460,353,201 MBRs case, the answer is 8... This is known as the curse of dimensionality Spatial Access Methods We can use Spatial Access Methods like the R-Tree to index our data, but… The performance of R-Trees degrade exponentially with the number of dimensions. Somewhere above 6-20 dimensions the RTree degrades to linear scanning. Often we want to index time series with hundreds, perhaps even thousands of features…. GEMINI GEneric Multimedia INdexIng {Christos Faloutsos} Establish a distance metric from a domain expert. Produce a dimensionality reduction technique that reduces the dimensionality of the data from n to N, where N can be efficiently handled by your favorite SAM. Produce a distance measure defined on the N dimensional representation of the data, and prove that it obeys Dindexspace(A,B) Dtrue(A,B). i.e. The lower bounding lemma. Plug into an off-the-shelve SAM. We have 6 objects in 3-D space. We issue a query to find all objects within 1 unit of the point (-3, 0, -2)... A 3 2.5 2 1.5 C 1 B 0.5 F 0 -0.5 -1 3 2 D 1 0 E -1 0 -1 -2 -2 -3 -3 -4 3 2 1 Consider what would happen if we issued the same query after reducing the dimensionality to 2, assuming the dimensionality technique obeys the lower bounding lemma... The query successfully finds the object E. A 3 2 C 1 B F 0 -1 3 2 D 1 0 E -1 0 -1 -2 -2 -3 -3 -4 3 2 1 Example of a dimensionality reduction technique in which the lower bounding lemma is satisfied Informally, it’s OK if objects appear closer in the dimensionality reduced space, than in the true space. Note that because of the dimensionality reduction, object F appears to less than one unit from the query (it is a false alarm). 3 2.5 A 2 1.5 C F 1 0.5 0 B -0.5 -1 D E -4 -3 -2 -1 0 1 2 3 This is OK so long as it does not happen too much, since we can always retrieve it, then test it in the true, 3-dimensional space. This would leave us with just E , the correct answer. Example of a dimensionality reduction technique in which the lower bounding lemma is not satisfied Informally, some objects appear further apart in the dimensionality reduced space than in the true space. 3 2.5 Note that because of the dimensionality reduction, object E appears to be more than one unit from the query (it is a false dismissal). A 2 E 1.5 1 C 0.5 This is unacceptable. 0 F -0.5 B D -1 -4 -3 -2 -1 0 1 2 3 We have failed to find the true answer set to our query. GEMINI GEneric Multimedia INdexIng {Christos Faloutsos} Establish a distance metric from a domain expert. Produce a dimensionality reduction technique that reduces the dimensionality of the data from n to N, where N can be efficiently handled by your favorite SAM. Produce a distance measure defined on the N dimensional representation of the data, and prove that it obeys Dindexspace(A,B) Dtrue(A,B). i.e. The lower bounding lemma. Plug into an off-the-shelve SAM. The examples on the previous slides illustrate why the lower bounding lemma is so important. Now all we have to do is to find a dimensionality reduction technique that obeys the lower bounding lemma, and we can index our time series! Notation for Dimensionality Reduction For the future discussion of dimensionality reduction we will assume that M is the number time series in our database. n is the original dimensionality of the data. (i.e. the length of the time series) N is the reduced dimensionality of the data. CRatio = N/n is the compression ratio. An Example of a Dimensionality Reduction Technique I C 0 20 40 60 80 n = 128 100 120 140 Raw Data 0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 … The graphic shows a time series with 128 points. The raw data used to produce the graphic is also reproduced as a column of numbers (just the first 30 or so points are shown). An Example of a Dimensionality Reduction Technique II C 0 20 40 60 80 100 120 .............. 140 Raw Data Fourier Coefficients 0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 … 1.5698 1.0485 0.7160 0.8406 0.3709 0.4670 0.2667 0.1928 0.1635 0.1602 0.0992 0.1282 0.1438 0.1416 0.1400 0.1412 0.1530 0.0795 0.1013 0.1150 0.1801 0.1082 0.0812 0.0347 0.0052 0.0017 0.0002 ... We can decompose the data into 64 pure sine waves using the Discrete Fourier Transform (just the first few sine waves are shown). The Fourier Coefficients are reproduced as a column of numbers (just the first 30 or so coefficients are shown). Note that at this stage we have not done dimensionality reduction, we have merely changed the representation... An Example of a Dimensionality Reduction Technique III C C’ 0 20 40 60 80 100 We have discarded 15 16 of the data. 120 140 Raw Data 0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 … Truncated Fourier Fourier Coefficients Coefficients 1.5698 1.0485 0.7160 0.8406 0.3709 0.4670 0.2667 0.1928 0.1635 0.1602 0.0992 0.1282 0.1438 0.1416 0.1400 0.1412 0.1530 0.0795 0.1013 0.1150 0.1801 0.1082 0.0812 0.0347 0.0052 0.0017 0.0002 ... 1.5698 1.0485 0.7160 0.8406 0.3709 0.4670 0.2667 0.1928 n = 128 N=8 Cratio = 1/16 … however, note that the first few sine waves tend to be the largest (equivalently, the magnitude of the Fourier coefficients tend to decrease as you move down the column). We can therefore truncate most of the small coefficients with little effect. An Example of a Dimensionality Reduction Technique IIII C C’ 0 20 40 60 80 100 120 140 Raw Data 0.4995 0.5264 0.5523 0.5761 0.5973 0.6153 0.6301 0.6420 0.6515 0.6596 0.6672 0.6751 0.6843 0.6954 0.7086 0.7240 0.7412 0.7595 0.7780 0.7956 0.8115 0.8247 0.8345 0.8407 0.8431 0.8423 0.8387 … Sorted Truncated Fourier Fourier Coefficients Coefficients 1.5698 1.0485 0.7160 0.8406 0.3709 0.1670 0.4667 0.1928 0.1635 0.1302 0.0992 0.1282 0.2438 0.2316 0.1400 0.1412 0.1530 0.0795 0.1013 0.1150 0.1801 0.1082 0.0812 0.0347 0.0052 0.0017 0.0002 ... 1.5698 1.0485 0.7160 0.8406 0.2667 0.1928 0.1438 0.1416 Instead of taking the first few coefficients, we could take the best coefficients This can help greatly in terms of approximation quality, but makes indexing hard (impossible?). Note this applies also to Wavelets aabbbccb 0 20 40 60 80 100 120 0 20 40 60 80 100 120 0 20 40 60 80 100 120 0 20 40 60 80 100 120 0 20 40 60 80 100120 0 20 40 60 80 100 120 0 20 40 60 80 100 120 a DFT DWT SVD APCA PAA PLA a b b b c c SYM b Discrete Fourier Transform I X Basic Idea: Represent the time series as a linear combination of sines and cosines, but keep only the first n/2 coefficients. X' 0 20 40 60 80 100 120 140 Why n/2 coefficients? Because each sine wave requires 2 numbers, for the phase (w) and amplitude (A,B). Jean Fourier 0 1768-1830 1 2 3 4 n C (t ) ( Ak cos( 2wk t ) Bk sin( 2wk t )) k 1 5 6 7 8 9 Excellent free Fourier Primer Hagit Shatkay, The Fourier Transform - a Primer'', Technical Report CS95-37, Department of Computer Science, Brown University, 1995. http://www.ncbi.nlm.nih.gov/CBBresearch/Postdocs/Shatkay/ Discrete Fourier Transform II X X' 0 20 40 60 80 100 120 140 Pros and Cons of DFT as a time series representation. • Good ability to compress most natural signals. • Fast, off the shelf DFT algorithms exist. O(nlog(n)). • (Weakly) able to support time warped queries. 0 1 2 3 • Difficult to deal with sequences of different lengths. • Cannot support weighted distance measures. 4 5 6 7 8 9 Note: The related transform DCT, uses only cosine basis functions. It does not seem to offer any particular advantages over DFT. Discrete Wavelet Transform I X Basic Idea: Represent the time series as a linear combination of Wavelet basis functions, but keep only the first N coefficients. X' DWT 0 20 40 60 80 100 120 140 Haar 0 Although there are many different types of wavelets, researchers in time series mining/indexing generally use Haar wavelets. Alfred Haar 1885-1933 Haar 1 Haar 2 Haar 3 Haar wavelets seem to be as powerful as the other wavelets for most problems and are very easy to code. Haar 4 Haar 5 Excellent free Wavelets Primer Haar 6 Haar 7 Stollnitz, E., DeRose, T., & Salesin, D. (1995). Wavelets for computer graphics A primer: IEEE Computer Graphics and Applications. Discrete Wavelet Transform II X X' DWT 0 20 40 60 80 100 120 Ingrid Daubechies 140 1954 - Haar 0 Haar 1 We have only considered one type of wavelet, there are many others. Are the other wavelets better for indexing? YES: I. Popivanov, R. Miller. Similarity Search Over Time Series Data Using Wavelets. ICDE 2002. NO: K. Chan and A. Fu. Efficient Time Series Matching by Wavelets. ICDE 1999 Later in this tutorial I will answer this question. Discrete Wavelet Transform III Pros and Cons of Wavelets as a time series representation. X X' DWT 0 20 40 60 80 100 120 140 • Good ability to compress stationary signals. • Fast linear time algorithms for DWT exist. • Able to support some interesting non-Euclidean similarity measures. Haar 0 Haar 1 Haar 2 Haar 3 Haar 4 Haar 5 Haar 6 Haar 7 • Signals must have a length n = 2some_integer • Works best if N is = 2some_integer. Otherwise wavelets approximate the left side of signal at the expense of the right side. • Cannot support weighted distance measures. Singular Value Decomposition I X Basic Idea: Represent the time series as a linear combination of eigenwaves but keep only the first N coefficients. X' SVD 0 20 40 60 80 100 120 140 eigenwave 0 eigenwave 1 SVD is similar to Fourier and Wavelet approaches is that we represent the data in terms of a linear combination of shapes (in this case eigenwaves). James Joseph Sylvester 1814-1897 eigenwave 2 eigenwave 3 SVD differs in that the eigenwaves are data dependent. Camille Jordan (1838--1921) eigenwave 4 eigenwave 5 eigenwave 6 eigenwave 7 SVD has been successfully used in the text processing community (where it is known as Latent Symantec Indexing ) for many years. Good free SVD Primer Singular Value Decomposition - A Primer. Sonia Leach Eugenio Beltrami 1835-1899 Singular Value Decomposition II How do we create the eigenwaves? We have previously seen that we can regard time series as points in high dimensional space. X X' SVD 0 20 40 60 80 100 120 140 We can rotate the axes such that axis 1 is aligned with the direction of maximum variance, axis 2 is aligned with the direction of maximum variance orthogonal to axis 1 etc. eigenwave 0 eigenwave 1 eigenwave 2 eigenwave 3 Since the first few eigenwaves contain most of the variance of the signal, the rest can be truncated with little loss. eigenwave 4 eigenwave 5 eigenwave 6 eigenwave 7 A UV T This process can be achieved by factoring a M by n matrix of time series into 3 other matrices, and truncating the new matrices at size N. Singular Value Decomposition III Pros and Cons of SVD as a time series representation. X X' SVD 0 20 40 60 80 100 120 140 • Optimal linear dimensionality reduction technique . • The eigenvalues tell us something about the underlying structure of the data. eigenwave 0 eigenwave 1 eigenwave 2 eigenwave 3 eigenwave 4 • Computationally very expensive. • Time: O(Mn2) • Space: O(Mn) • An insertion into the database requires recomputing the SVD. • Cannot support weighted distance measures or non Euclidean measures. eigenwave 5 eigenwave 6 eigenwave 7 Note: There has been some promising research into mitigating SVDs time and space complexity. Piecewise Linear Approximation I Basic Idea: Represent the time series as a sequence of straight lines. X Karl Friedrich Gauss X' 1777 - 1855 0 20 40 60 80 100 120 140 Lines could be connected, in which case we are allowed N/2 lines Each line segment has • length • left_height (right_height can be inferred by looking at the next segment) If lines are disconnected, we are allowed only N/3 lines Personal experience on dozens of datasets suggest disconnected is better. Also only disconnected allows a lower bounding Euclidean approximation Each line segment has • length • left_height • right_height How do we obtain the Piecewise Linear Approximation? Piecewise Linear Approximation II X X' 0 20 40 60 80 100 120 140 Optimal Solution is O(n2N), which is too slow for data mining. A vast body on work on faster heuristic solutions to the problem can be classified into the following classes: • Top-Down • Bottom-Up • Sliding Window • Other (genetic algorithms, randomized algorithms, Bspline wavelets, MDL etc) Recent extensive empirical evaluation of all approaches suggest that Bottom-Up is the best approach overall. Piecewise Linear Approximation III Pros and Cons of PLA as a time series representation. X X' 0 20 40 60 80 100 120 140 • Good ability to compress natural signals. • Fast linear time algorithms for PLA exist. • Able to support some interesting non-Euclidean similarity measures. Including weighted measures, relevance feedback, fuzzy queries… •Already widely accepted in some communities (ie, biomedical) • Not (currently) indexable by any data structure (but does allows fast sequential scanning). Basic Idea: Convert the time series into an alphabet of discrete symbols. Use string indexing techniques to manage the data. Symbolic Approximation I X X' a a b b b c c b 0 20 40 60 80 100 120 140 0 a Potentially an interesting idea, but all work thusfar are very ad hoc. Pros and Cons of Symbolic Approximation as a time series representation. 1 a b 2 b 3 4 b 5 c c • Potentially, we could take advantage of a wealth of techniques from the very mature field of string processing and bioinformatics. • It is not clear how we should discretize the times series (discretize the values, the slope, shapes? How big of an alphabet? etc) 6 b 7 •There is no known technique to allow the support of Euclidean queries. Breaking News!! Symbolic Approximation II X A new technique for creating a symbolic representation of time series will be published in IEEE ICDM 2002. X' a a b b b c c b 0 20 40 60 80 100 120 140 0 a This representation is the only symbolic representation of time series that allows lower bounding estimates of Euclidean distance to be calculated on symbolic strings. 1 a b 2 b 3 4 b 5 c c These means that time series researchers can now use tools, algorithms and data structures defined for discrete objects, such as • Markov Models • Suffix Trees • Hashing • Etc. 6 b 7 Patel, P., Keogh, E. Lin, J. & Lonardi, S. (2002). Mining motifs in massive time series databases. In the 2nd IEEE International Conference on Data Mining December 9 - 12, 2002. Maebashi City, Japan Piecewise Aggregate Approximation I Basic Idea: Represent the time series as a sequence of box basis functions. Note that each box is the same length. X X' 0 20 40 60 80 100 120 140 x1 x2 x3 x4 x5 xi Nn ni N x j j Nn ( i 1) 1 Given the reduced dimensionality representation we can calculate the approximate Euclidean distance as... DR ( X , Y ) n N 2 x y i1 i i N This measure is provably lower bounding. x6 x7 Independently introduced by two authors x8 Keogh, Chakrabarti, Pazzani & Mehrotra, KAIS (2000) Byoung-Kee Yi, Christos Faloutsos, VLDB (2000) Piecewise Aggregate Approximation II X X' 0 20 40 60 80 100 120 140 X1 Pros and Cons of PAA as a time series representation. • Extremely fast to calculate • As efficient as other approaches (empirically) • Support queries of arbitrary lengths • Can support any Minkowski metric • Supports non Euclidean measures • Supports weighted Euclidean distance • Simple! Intuitive! X2 X3 X4 X5 X6 X7 X8 • If visualized directly, looks ascetically unpleasing. Adaptive Piecewise Constant Approximation I Basic Idea: Generalize PAA to allow the piecewise constant segments to have arbitrary lengths. Note that we now need 2 coefficients to represent each segment, its value and its length. X Raw Data (Electrocardiogram) X Adaptive Representation (APCA) 0 20 40 60 80 100 120 Reconstruction Error 2.61 140 Haar Wavelet or PAA Reconstruction Error 3.27 <cv1,cr1> <cv2,cr2> DFT Reconstruction Error 3.11 <cv3,cr3> 0 <cv4,cr4> 50 100 150 200 250 The intuition is this, many signals have little detail in some places, and high detail in other places. APCA can adaptively fit itself to the data achieving better approximation. Adaptive Piecewise Constant Approximation II X X The high quality of the APCA had been noted by many researchers. However it was believed that the representation could not be indexed because some coefficients represent values, and some represent lengths. However an indexing method was discovered! (SIGMOD 2001 best paper award) 0 20 40 60 80 100 120 140 <cv1,cr1> <cv2,cr2> <cv3,cr3> <cv4,cr4> Unfortunately, it is non-trivial to understand and implement…. Adaptive Piecewise Constant Approximation III • Pros and Cons of APCA as a time series representation. X X 0 20 40 60 80 100 120 140 <cv1,cr1> • Fast to calculate O(n). • More efficient as other approaches (on some datasets). • Support queries of arbitrary lengths. • Supports non Euclidean measures. • Supports weighted Euclidean distance. • Support fast exact queries , and even faster approximate queries on the same data structure. <cv2,cr2> <cv3,cr3> <cv4,cr4> • Somewhat complex implementation. • If visualized directly, looks ascetically unpleasing. Natural Language • Pros and Cons of natural language as a time series representation. X rise, plateau, followed by a rounded peak 0 20 40 60 80 100 120 • The most intuitive representation! • Potentially a good representation for low bandwidth devices like text-messengers 140 • Difficult to evaluate. rise plateau followed by a rounded peak To the best of my knowledge only one group is working seriously on this representation. They are the University of Aberdeen SUMTIME group, headed by Prof. Jim Hunter. Comparison of all dimensionality reduction techniques • We can compare the time it takes to build the index, for different sizes of databases, and different query lengths. • We can compare the indexing efficiency. How long does it take to find the best answer to out query. It turns out that the fairest way to measure this is to measure the number of times we have to retrieve an item from disk. • We can simply compare features. Does approach X allow weighted queries, queries of arbitrary lengths, is it simple to implement… The time needed to build the index Black topped histogram bars (in SVD) indicate experiments abandoned at 1,000 seconds. The fraction of the data that must be retrieved from disk to answer a one nearest neighbor query SVD DWT DFT PAA 1 1 1 1 .5 .5 .5 .5 0 1024 512 256 128 64 0 0 16 20 18 14 12 10 8 1024 512 256 128 64 16 20 18 10 14 12 8 0 1024 512 256 128 64 20 18 16 10 14 12 Dataset is Stock Market Data 8 1024 512 256 128 64 20 14 18 16 12 10 8 The fraction of the data that must be retrieved from disk to answer a one nearest neighbor query 0.5 0.5 0.5 0.5 0.4 0.4 0.4 0.4 0.3 0.3 0.3 0.3 0.2 0.2 0.2 0.2 0.1 0.1 0.1 0.1 0 0 0 0 16 1024 32 512 256 64 DFT 16 1024 32 512 256 64 DWT 16 1024 32 512 256 PAA 64 16 1024 32 512 256 APCA Dataset is mixture of many “structured” datasets, like ECGs 64 Summary of Results On most datasets, it does not matter too much which representation you choose. Wavelets, PAA, DFT all seem to do about the same. However, on some datasets, in particular those datasets where the level of detail varies over time, APCA can do much better. Raw Data (Electrocardiogram) Haar Wavelet Adaptive Representation (APCA)