Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Getting started with
Weka
The HIV Data Management and
Data Mining Workshop.
December, 13-16th 2004
Durban, South Africa
Contents
1.
2.
3.
4.
5.
What is Weka and why use it?
First view on the Weka explorer
Importing a data set in Weka
Preprocess-tab
Visualize-tab
What is Weka?
• “Waikato Environment for
Knowledge Analysis”
• Weka is a collection of
machine learning
algorithms for data mining
• Open Source Machine
Learning Software in Java
http://www.cs.waikato.ac.nz/ml/weka/
Why use Weka?
• It contains tools for a whole range of data
mining tasks:
– Data pre-processing
– Classification
– Regression
– Clustering
– Association
– Visualization
• You can download it for free!
Launching Weka
• We will only make
use of the
‘Explorer’ user
interface
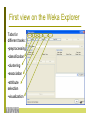
First view on the Weka Explorer
Tabs for
different tasks:
•preprocessing
•classification
•clustering
•association
•attribute
selection
•visualization
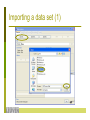
Importing a data set (1)
Importing a data set (2)
• Format of your data:
– ARFF-format: special Weka format
– CSV format (can be exported from Excell)
Importing a data set (3)
• ARFF-format:
@RELATION stanford_data
@ATTRIBUTE Subtype { "D", "K", "F1", "C", "A1", "B", "A2", "G", ""}
@ATTRIBUTE Bootstrap numeric
@ATTRIBUTE eNFV { "n", "y"}
@ATTRIBUTE SeqId { "NDK_198301", "SE554_199808", "SE474_199808", …,
"KDR_pat152_200101", "IL210_200104"}
@ATTRIBUTE PR2 { "Q", "K", "R", "H", "*", "E"}
…
@ATTRIBUTE PR99 { "F", "N", "Y", "L"}
@DATA
"D", "38.0", "n", "NDK_198301", "Q", "I", "T", "L", "W", "Q", "R", "P", "L", "V", "T", …, "F"
"F1", "50.0", "n", "CDC7944_199501", "Q", "I", "T", "L", "W", "Q", "R", "P", "L", "V", …, "F"
Importing a data set (4)
• CSV format:
can be
exported
from Excel
eNFV,subtype,bootstrap,seqid,PR2,PR3,PR4, …,PR97,PR98,PR99
n,D,44,NDK_198301,Q,I,T,…,L,N,F
n,C,95,BRP2139_200208,Q,I,P,…,L,N,F
y,C,97,TCDD13_200103, ,I,T,…,L,N,F
Preprocess-tab
Preprocess-tab
gives
information
about the
loaded data
and allows you
to preprocess it
further
Preprocess-tab
Filters can be applied
to preprocess the data
Preprocess-tab
describes the current
relation:
• nb of instances
• nb of attributes
Preprocess-tab
list of all attributes
allows you to
remove selected
attributes
Preprocess-tab
gives info about
attribute selected
from list
for nominal attributes:
possible values and
number of times each
value occurs
Preprocess-tab
for numeric attributes:
minimum, maximum,
mean, standard
deviation
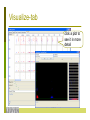
Preprocess-tab
visualizes the
selected attribute
with colours
according to
selected class
attribute
D
N
V
Preprocess-tab
visualizes the
selected attribute
with colours
according to
selected class
attribute
instances without
therapy experience
instances with
therapy experience
Visualize-tab
• Preprocess-tab allows you to look at
interactions between two different
attributes (eg. PR30 and eNFV)
• Visualize-tab allows you to look at
interactions between three different
attributes (eg. PR90, PR30 and eNFV)
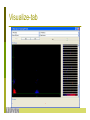
Visualize-tab
plot matrix of all
attributes plotted
against each other
increase the
PlotSize, PointSize
and Jitter
click update!
select the target
attribute eNFV for
the colouring
Visualize-tab
click a plot to
see it in more
detail
Visualize-tab
Practice
•
Import the data set and play with the
visualization tools
1. Do these visualizations agree with all
the IAS mutations for Nelfinavir? (30N,
36I, 46I, 63P, 71V, 77I, 84V, 88D, 90M)
2. Do you see any other protease
positions that seem to correlate with
therapy experience?