Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Go (programming language) wikipedia , lookup
Computer cluster wikipedia , lookup
C Sharp syntax wikipedia , lookup
Name mangling wikipedia , lookup
Join-pattern wikipedia , lookup
Supercomputer architecture wikipedia , lookup
Java (programming language) wikipedia , lookup
Java performance wikipedia , lookup
A Tutorial on X10 and its Implementation
David Grove
IBM TJ Watson Research Center
This material is based upon work supported in part by the
Defense Advanced Research Projects Agency under its Agreement No. HR0011-07-9-0002
© 2009 IBM Corporation
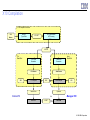
X10 Genesis: DARPA HPCS Program (2004)
Central Challenge: Productive Programming of Large Scale Supercomputers
– Clustered systems
• 1000’s of SMP Nodes connected by high-performance interconnect
• Large aggregate memory, disk storage, etc.
Massively Parallel Processor
Systems
SMP Clusters
SMP Node
SMP Node
PEs,
PEs,
...
PEs,
PEs,
...
Memory
...
Memory
Interconnect
IBM Blue Gene
© 2009 IBM Corporation
Flash forward a few years… Big Data and Commercial HPC
Central Challenge: Productive programming of large commodity clusters
– Clustered systems
• 100’s to 1000’s of SMP Nodes connected by high-performance network
• Large aggregate memory, disk storage, etc.
SMP Clusters
SMP Node
SMP Node
PEs,
PEs,
...
PEs,
PEs,
...
Memory
...
Memory
Network
Commodity cluster != MPP system
but the programming model problem is highly similar
© 2009 IBM Corporation
X10 Performance and Productivity at Scale
An evolution of Java for concurrency, scale out, and heterogeneity
– Language focuses on high productivity and high performance
– Bring productivity gains from commercial world to HPC developers
The X10 language provides:
– Java-like language (statically typed, object oriented, garbage-collected)
– Ability to specify scale-out computations (multiple places, exploit modern networks)
– Ability to specify fine-grained concurrency (exploit multi-core)
– Single programming model for computation offload and heterogeneity (exploit GPUs)
– Migration path
• X10 concurrency/distribution idioms can be realized in other languages via library
APIs that wrap the X10 runtime
• X10 interoperability with Java and C/C++ enables reuse of existing libraries
© 2009 IBM Corporation
Outline
X10 concepts and language overview
X10 Implementation
What’s new in X10 since X10’11?
© 2009 IBM Corporation
Partitioned Global Address Space (PGAS) Languages
In clustered systems, memory is only accessible to the CPUs on its node
Managing local vs. remote memory is a key programming task
PGAS combines a single logical global address with locality awareness
– PGAS Languages: Titanium, UPC, CAF, X10, Chapel
© 2009 IBM Corporation
X10 combines PGAS with asynchrony (APGAS)
Global Reference
Local
Heap
…
…
…
…
Local
Heap
…
…
…
…
Activities
Activities
Place 0
Fine grained concurrency
• async S
Place-shifting operations
…
Place N
Sequencing
• finish S
Atomicity
• at (P) S
• when (c) S
• at (P) { e }
• atomic S
© 2009 IBM Corporation
Hello Whole World
1/class HelloWholeWorld {
2/ public static def main(args:Rail[String]) {
3/
finish
4/
for (p in Place.places())
5/
at (p)
6/
async
7/
Console.OUT.println(p+" says " +args(0));
8/ }
9/}
% x10c++ HelloWholeWorld.x10
% X10_NPLACES=4; ./a.out hello
Place 0 says hello
Place 2 says hello
("
Place 3 says hello
Place 1 says hello
© 2009 IBM Corporation
Sequential Monty Pi
import x10.io.Console;
import x10.util.Random;
class MontyPi {
public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));
val r = new Random();
var result:Double = 0;
for (1..N) {
val x = r.nextDouble();
val y = r.nextDouble();
if (x*x + y*y <= 1) result++;
}
val pi = 4*result/N;
Console.OUT.println(“The value of pi is “ + pi);
}
}
© 2009 IBM Corporation
Concurrent Monty Pi
import x10.io.Console;
import x10.util.Random;
class MontyPi {
public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));
val P = Int.parse(args(1));
val result = new Cell[Double](0);
finish for (1..P) async {
val r = new Random();
var myResult:Double = 0;
for (1..(N/P)) {
val x = r.nextDouble();
val y = r.nextDouble();
if (x*x + y*y <= 1) myResult++;
}
atomic result() += myResult;
}
val pi = 4*(result())/N;
Console.OUT.println(“The value of pi is “ + pi);
}
}
© 2009 IBM Corporation
Concurrent Monty Pi (Collecting Finish)
import x10.io.Console;
import x10.util.Random;
class MontyPi {
public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));
val P = Int.parse(args(1));
val result = finish (Reducible.SumReducer[Double]())
for (1..P) async {
val r = new Random();
var myResult:Double = 0;
for (1..(N/P)) {
val x = r.nextDouble();
val y = r.nextDouble();
if (x*x + y*y <= 1) myResult++;
}
offer myResult;
};
val pi = 4*result/N;
Console.OUT.println(“The value of pi is “ + pi);
}
}
© 2009 IBM Corporation
Distributed Monty Pi (Collecting Finish)
import x10.io.Console;
import x10.util.Random;
class MontyPi {
public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));
val result = finish (Reducible.SumReducer[Double]())
for (p in Place.places()) at (p) async {
val r = new Random();
var myResult:Double = 0;
for (1..(N/Place.MAX_PLACES)) {
val x = r.nextDouble();
val y = r.nextDouble();
if (x*x + y*y <= 1) myResult++;
}
offer myResult;
};
val pi = 4*result/N;
Console.OUT.println(“The value of pi is “ + pi);
}
}
© 2009 IBM Corporation
Distributed Monty Pi (GloablRef)
import x10.io.Console;
import x10.util.Random;
class MontyPi {
public static def main(args:Array[String](1)) {
val N = Int.parse(args(0));
val result = GlobalRef[Cell[Double]](new Cell[Double](0));
finish for (p in Place.places()) at (p) async {
val r = new Random();
var myResult:Double = 0;
for (1..(N/Place.MAX_PLACES)) {
val x = r.nextDouble();
val y = r.nextDouble();
if (x*x + y*y <= 1) myResult++;
}
at (result) atomic result()() += myResult;
}
val pi = 4*(result()())/N;
Console.OUT.println(“The value of pi is “ + pi);
}
}
© 2009 IBM Corporation
X10 Target Environments
High-end large HPC clusters
– BlueGene/P (since 2010); BlueGene/Q (in progress)
– Power7IH (aka PERCS machine)
– x86 + InfiniBand, Power + InfiniBand
– Goal: deliver scalable performance competitive with C+MPI
Medium-scale commodity systems
– ~100 nodes (~1000 core and ~1 terabyte main memory)
– Goal: deliver main-memory performance with simple programming model (accessible to
Java programmers)
Developer laptops
– Linux, Mac OSX, Windows. Eclipse-based IDE, debugger, etc
– Goal: support developer productivity
© 2009 IBM Corporation
X10 Implementation Summary
X10 Implementations
– C++ based (“Native X10”)
• Multi-process (one place per process; multi-node)
• Linux, AIX, MacOS, Cygwin, BlueGene
• x86, x86_64, PowerPC
– JVM based (“Managed X10”)
• Multi-process (one place per JVM process; multi-node)
• Limitation on Windows to single process (single place)
• Runs on any Java 6 JVM
X10DT (X10 IDE) available for Windows, Linux, Mac OS X
– Based on Eclipse 3.7
– Supports many core development tasks including remote build/execute facilities
IBM Parallel Debugger for X10 Programming
– Adds X10 language support to IBM Parallel Debugger
– Available on IBM developerWorks (Native X10 on Linux only)
© 2009 IBM Corporation
X10 Compilation
X10 Compiler Front-End
Parsing /
Type Check
X10
Source
X10 AST
AST Optimizations
AST Lowering
X10 AST
C++
Back-End
XRC
C++ Code
Generation
Java Code
Generation
C++ Source
Java Source
C++ Compiler
XRX
Java Compiler
Native Code
XRJ
Bytecode
Native X10
Managed X10
JNI
Native Env
Java
Back-End
X10RT
Java VMs
© 2009 IBM Corporation
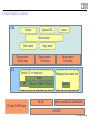
X10 Runtime Software Stack
X10 Runtime
X10 Application Program
X10 Core
Class Libraries
XRX (X10 Runtime in X10)
– APGAS functionality
•Concurrency: async/finish (workstealing)
•Distribution: Places/at
– Written in X10; compiled to C++ or Java
XRX Runtime
X10 Language Native Runtime
X10RT
PAMI
DCMF
MPI
Core Class Libraries
– Fundamental classes & primitives, Arrays,
core I/O, collections, etc
– Written in X10; compiled to C++ or Java
TCP/IP
X10 Language Native Runtime
– Runtime support for core sequential X10
language features
– Two versions: C++ and Java
X10RT
– Active messages, collectives, bulk data
transfer
– Implemented in C
– Abstracts/unifies network layers (PAMI,
DCMF, MPI, etc) to enable X10 on a range of
transports
© 2009 IBM Corporation
X10 Highlights since X10’11
Two major releases: 2.2.1, 2.2.2
– Maintained backwards compatibility with X10 2.2.0 (June 2011)
– Backwards compatibility with 2.2.0 will be maintained in future releases
Java interoperability
– Tech preview in 2.2.2, fully documented/supported in next release
Managed X10 Improvements
– Complete rework of serialization protocol; significant performance improvements
– Implementation of Generics (paper today)
– Distributed GC (paper today)
Application work at IBM
– M3R: Main Memory Map Reduce (talk today)
– Global Matrix Library (open sourced Oct 2011; available in x10 svn)
– SatX10
– HPC benchmarks (for PERCS) (x10 svn: benchmarks/trunk/PERCS)
Active & growing X10 community!
© 2009 IBM Corporation
Summary of X10/Java Interoperability Status
Managed X10 only
X10 Java
– use import statement to import a Java type into an X10 source file
– just use the type normally
• Create instances
• Call methods, access fields
• Implement it (if the imported type was an interface)
– Helper class to allow easy access to Java arrays
Java X10
– Officially supported in next release
• calling non-generic static X10 methods from Java (no escaping asyncs)
– Many other scenarios will work in practice, but not ready to freeze code-generation
strategy for generics yet (release-to-release compatibility)
© 2009 IBM Corporation
Global Matrix Library
GML
Vector
SparseCSC
Dense
Block matrix
Dupl. block
Distr. block
Dense matrix
BLAS wrap
X10
Native C/C++ back end
Team
MPI
Socket
PAMI
BLAS
3rd
Dense matrix
X10 driver
Sparse matrix
X10 driver
Managed Java back end
PGAS
Socket
Multi-thread BLAS (GotoBLAS)
party C-MPI library
LAPACK
© 2009 IBM Corporation
Using GML: Gaussian Non-Negative Matrix Multiplication
Key kernel for topic modeling
Involves factoring a large (D x W) matrix
D ~ 100M
Key decision is representation for matrix,
and its distribution.
Note: app code is polymorphic in this
choice.
W ~ 100K, but sparse (0.001)
Iterative algorithm, involves distributed sparse
matrix multiplication, cell-wise matrix
operations.
H
V
W
H
H
H
P0
P1
P2
Pn
for (1..iteration) {
H.cellMult(WV
.transMult(W,V,tW)
.cellDiv(WWH
.mult(WW.transMult(W,W),H)));
W.cellMult(VH
.multTrans(V,H)
.cellDiv(WHH
.mult(W,HH.multTrans(H,H))));
}
X10
© 2009 IBM Corporation
What are Parallel SAT solver based on?
Essentially based on a portfolio of SAT solvers (Diversity)
Mostly the same underlying baseline solver, but different
parameterization (e.g., restart frequency)
Exchange of discovered knowledge (Knowledge Sharing)
Learned clause sharing (normally restricted to some clause
length, e.g., Plingeling the currently best parallel solver shares
only unit clauses)
© 2009 IBM Corporation
What is SATX10?
Framework to combine sequential SAT solvers into a parallel portfolio
Interference with SAT solver code is minimal
Small (100s of lines) X10 program for communication/distribution
Allows parallel solver to run on a single machine with multiple cores
and across multiple machines, sharing information such as learned
clauses
Tools demonstration paper at SAT 2012
Open source release of SAT X10 later this month
© 2009 IBM Corporation
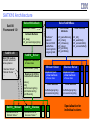
SATX10 Architecture
SatX10
Framework 1.0
SolverX10Callback
SolverSatX10Base *
SolverSatX10Base
Data Objects
Pure Virtual
Methods
Other Controls
Callback *
placeID
maxLenShrCl
outBufSize
incomingClsQ
outgoingClsQ
x10_parseDimacs()
x10_nVars()
x10_nClauses()
x10_solve()
x10_printSoln()
x10_printStats()
x10_kill()
x10_wasKilled()
x10_accessIncBuf()
x10_accessOutBuf()
Callback Methods
x10_step()
x10_processOutgoingCls()
SatX10.x10
Main X10 routines
to launch solvers at
various places:
Glucose::Solver *
Minisat::Solver *
…
SatX10__Solver
Implement callbacks
of base class
CallbackStats (data)
Routines for X10 to
interact with solvers
solve()
kill()
bufferIncomingCls()
printInstanceInfo()
printResults()
SatX10__Minisat
SatX10__Glucose
Specialized solver:
Specialized solver:
Minisat::Solver
* Confidential Glucose::Solver *
IBM
Minisat::Solver
Implement pure
virtual methods
of base class
Other Methods
bufferOutgoingCls()
processIncomgCls()
Glucose::Solver
Implement pure
virtual methods
of base class
Other Methods
bufferOutgoingCls()
processIncomgCls()
Specialization for
individual solvers
© 2009 IBM Corporation
Preliminary Empirical Results: Same Machine
Same machine, 8 cores, clause lengths=1 and 8
Time in Seconds
7000
6000
Length 1
5000
Length 8
4000
3000
2000
1000
0
0
5
10
15
20
Number of Instances Solved
25
30
Note: Promising but preliminary results; focus so far has been on
developing the framework, not on producing a highly competitive solver
© 2009 IBM Corporation
Preliminary Empirical Results: Multiple Machines
8 machine/8 cores vs 16 machines/64 cores, clause lengths=1 and 8
Time in seconds
Same executable as for single machine --- just different parameters!
5000
4500
4000
3500
3000
2500
2000
1500
1000
500
0
8 Places 8 Hosts Length 1
8 Places 8 Hosts Length 8
64 Places 16 Hosts Length 1
64 Places 16 Hosts Length 8
0
5
10
15
20
Number of Instances Solved
25
30
© 2009 IBM Corporation
Conclusions
Welcome to X10 2012!
© 2009 IBM Corporation