Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
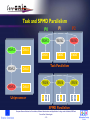
Knowledge and Data Management in Grids (or using Grids to climb data mountains and find knowledge nuggets) Domenico Talia CoreGRID / University of Calabria www.coregrid.net [email protected] CereGRID Summer School – Budapest – 3-7 September, 2007 AGENDA • Introduction • Objectives • Some Data Grid Projects • Distributed Data Mining • The KDM Institute • Conclusions European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -2- Introduction (1) • Data and knowledge management is becoming key element in GRIDs as or more than high performance delivery. Distributed Knowledge and Data Management Dealing with issues concerning representation, storing, querying, mining, exchanging and integration of data (and resulting knowledge) in dynamic distributed environments. • Those issues are today addressed by exploiting features offered by Grid/P2P/GC/UC (Distributed) Technologies. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -3- Introduction (2) • Many activities all over the word on – GRID/P2P databases and distributed repositories – Distributed metadata management – Pervasive information systems – GRID-based digital libraries – Distributed data streaming management – Distributed knowledge management – Data-oriented services • A more important role is expected in the near future. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -4- Introduction (3) • Today the information stored in digital data archives is enormous and its size is still growing very rapidly. The world has created 161 exabytes (161 billion gigabytes) of digital information in 2006. (source: IDC) European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -5- Introduction (4) • Lots of data collected and warehoused. – Data collected and stored at enormous speeds in local databases, from remote sources, from the environment and from the sky. – Traditional techniques are infeasible for large raw data. • Scientific simulations generating terabytes of data. – Huge data sets are hard to understand. – Most data will never be examined by humans; it is analyzed and summarized by computers. • Storage costs are currently decreasing faster than computing costs: this trend makes things worse. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -6- Introduction (5) Whereas until some decades ago the main problem was the shortage of information, the challenge now seems to be – the very large volume of information to deal with and – the associated complexity to process it and to extract significant and useful parts or summaries. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -7- Data Management in Science • Data intensive applications are those that explore, query, analyze, visualize, and in general, process very large-scale data sets. • Computational science is evolving toward data intensive applications that include data integration and analysis, information management, and knowledge discovery. • Data intensive applications in science help scientists in hypothesis formation companies to provide better, customized services and support decision making. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -8- Evolution of Science Methods Jim Gray's formulation of the evolution of science methodologies: – Thousand years ago: science was empirical, describing natural phenomena. – Few hundred years: theoretical branch, using models, generalizations. – Last few decades: a computational branch, simulating complex phenomena. – Today: data exploration (eScience) - unify theory, experiment, and simulation. (Data captured by instruments, or generated by simulator; processed by software; information/knowledge stored in computer; scientist analyzes database/files, using data management and statistics.) European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies -9- GRIDS: From Computing to Data (1) • The use of computers is changing our way to make discoveries and is improving both speed and quality of the scientific discovery processes. • In this scenario the Grid provides an effective computational support for distributed data intensive application and for knowledge discovery from large and distributed data sets. • Grid services can be the basic element for composing software and data elements, and executing complex applications on Grid and Web systems. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 10 - GRIDS: From Computing to Data (2) • The Grid allows to federate and share heterogeneous resources and services such as software, computers, storage, data, networks in a dynamic way. • Today the Gris is not just compute cycles, but it is also a distributed data management infrastructure. Integrating those two features with “smart” algorithms we can obtain a knowledge-intensive platform. • In the latest years many significant Grid-based data intensive applications and infrastructures have been implemented. • The service-based approach is allowing the integration of Grid and Web for handling with data. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 11 - The EUROPEAN DATA GRID The LHC generates 1GB/sec or 10PB/year Applications: particle physics, earth observation, bioinformatics & medical http://cern.ch/eu-datagrid/ European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 12 - NASA INFORMATION POWER GRID First “production quality” Grid Linking NASA & academic supercomputing sites at 10 sites Applications: computational fluid dynamics, meteorological data mining, Grid benchmarking http://www.ipg.nasa.gov/ European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 13 - TERAGRID Linking supercomputers through a high-speed network 4x 10GBps between SDSC, Caltech, Argonne & NCSA Compute and data services for science applications & users http://www.teragrid.org/ European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 14 - GOOGLE & NASA Source: Charlie Catlett blog – Jan 2007 European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 15 - TerraService.NET • A photo of the United States – 1 meter resolution (photographic/topographic) – USGS data – Some demographic data (BestPlaces.net) – Home sales data – Linked to Encarta Encyclopedia 15 TB raw, 6 TB cooked (grows 10GB/w) • Offered as a Web Service to many applications (business, public administrations, scientits) European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 16 - OPEN SCIENCE GRID • The Open Science Grid links storage and computing resources at more than 30 sites across the United States • Support a variety of services and applications, many concerned with large-scale data analysis. • Thousands of computers and tens of terabytes of storage European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 17 - myExperiment "Scientists would rather share their toothbrush than their data" Mike Ashburn, University of Cambridge • myExperiment is a collaborative research environment which enables scientists to share, re-use and repurpose experiments. • myExperiment has been influenced by social networking programs such as Wired and Flickr, and is based on the mySpace infrastructure. • myExperiment creates an environment for scientists to adopt Grid technologies, where they can define, when they share data, with whom they share it and how much of it can be accessed. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 18 - DATA MINING ON GRIDS European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 19 - Data Mining and Computational Needs • Is not uncommon to have sequential data mining applications that require some days or weeks to complete their task. • Parallel computing can bring significant benefits in the implementation of data mining and knowledge discovery applications by means of the exploitation of inherent parallelism of data mining algorithms. Main goals: performance improvements of existing techniques, implementation of new (parallel) techniques and algorithms, concurrent analysis with different data mining techniques and result integration to get a more accurate model → Ensemble Learning European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 20 - Data Mining and Computational Needs • Today many data is distributed geographically or locally. • When – large data sets are coupled with – geographic distribution of data, users, and systems, it is necessary to combine different technologies for implementing high-performance distributed knowledge discovery systems. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 21 - Parallel and Distributed DATA MINING – Parallel data mining • • • • Task or control parallelism Independent parallelism SPMD parallelism Hybrid parallelism Can be a component of – Distributed data mining • Voting • Meta-learning, ensemble learning etc. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 22 - Parallel and Distributed DATA MINING Three main strategies in the exploitation of parallelism in data mining algorithms: independent parallelism control parallelism SPMD parallelism. • • • Independent parallelism: processes are executed in parallel in an independent way; generally each process has access to the whole data set. Control parallelism (or Task parallelism): each process executes different operations on (a different partition of) a data set. SPMD parallelism: a set of processes execute in parallel the same algorithm on different partitions of a data set; processes exchange partial results. D. Talia, "Parallelism in Knowledge Discovery Techniques", Proc. Sixth Int. Conference on Applied Parallel Computing, Helsinki, LNCS 2367, pp. 127-136, June 2002. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 23 - Task and SPMD Parallelism Work1 Work2 Work3 P0 P1 P2 Work1 Work2 Work3 Data1 Data2 Data3 Data1 Task Parallelism Data2 Data3 Uniprocessor Work Work Data i Data i Work Data i SPMD Parallelism European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 24 - Parallel DM Strategies • These three basic strategies are not necessarily alternative for parallelizing data mining algorithms. • They can be combined to improve both performance, scalability and accuracy of results. • With parallel strategies different data partition strategies can be used • sequential partitioning • separate partitions without overlapping • cover-based partitioning • some data can be replicated on different partitions • range-based query partitions based on some queries that select data according to attribute values. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 25 - Parallel in DATA MINING Techniques • Parallel Decision Trees tree construction in parallel ( processes subtrees ) • Discovery of Association Rules in Parallel rule and/or data partitioning on different processors • Parallel Neural Networks parallelism exploitation: training, layers, neurons, weights • Parallel Rough Set mining Parallel computing of reducts (construction of the rows of the discernibility matrix) • Parallel Cluster Analysis different clustering in parallel, data partitioning, computing similarity matrix in parallel. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 26 - Parallel Decision Trees Classification: assigning new items to predefined classes. Tree leaves represent classes and tree nodes represents attribute values. Task parallel approach One process is associated to each sub-tree. – The search occurs in parallel in each sub-tree. – The degree of parallelism P is equal to the number of active processes at a given time. P1 P3 P2 European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 27 - Parallel Decision Trees SPMD approach Each process classifies the items of a subset of data. – The P processes search in parallel on the whole tree using a partition of the data set D/P. – The global result is obtained by exchanging partial results. P1 P2 P3 – The data set partitioning can be operated: • partitioning the tuples of the data set: (D/P) per processor. • partitioning the N attributes of each tuple: D tuples of (N/P) attributes per processor. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 28 - Parallel Cluster Analysis SPMD approach : Each processor executes the same algorithm on a different partition of the data set to compute partial clustering results. Local results are then exchanged among all the processors to get global values on every processor. The global values are used in all processors to start the next clustering step until a convergence is reached or a certain number of steps are executed. The SPMD strategy can be also used to implement clustering algorithms where each processor generates a local approximation of a model (classification) that at each iteration can be passed to the other processors that can use it to improve their clustering model. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 29 - Parallel Cluster Analysis The SPMD approach has been used in P-AutoClass. Execution times European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 30 - Parallel Cluster Analysis The SPMD approach has been used in P-AutoClass. Speedup European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 31 - Towards Data and Knowledge Services • This objective can be achieved through – development of techniques and tools for supporting data mining applications and – integration of Data and Computation Grids with Knowledge Grids. to support the process of unification of data management and knowledge discovery systems with Grid technologies for providing knowledge-based Grid services. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 32 - Parallel & Distributed KDD on Grids The basic principles that motivate the architecture design of the Grid-aware KDD systems Data heterogeneity and large data size management Algorithm integration and independence Grid awareness Openness Scalability Security and data privacy. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 33 - What The Grid Offers • Grid tools, such as the Globus Toolkit, Legion and UNICORE, provide basic services that can be effectively exploited in the development of distributed data and knowledge management applications. • Data Grid middleware (e.g. Globus RSL, RFT, …) implements data management architectures based on two main services: storage system and metadata management. • Additional services are needed. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 34 - Parallel & Distributed KDD on Grids • By exploting a service-oriented approach, knowledge discovery applications can be developed on Grids to deliver high performance and manage data and knowledge distribution • Efforts are on going for the development of – Data access and management – knowledge discovery tools and services on the Grid. Examples: - OGSA-DAI, OGSA-DQP, Discovery Net, KNOWLEDGE GRID, Data Cutter, GDIS, … European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 35 - KDD PROJECTS and PROTOTYPES KNOWLEDGE GRID University of Calabria Discovery Net Imperial College (e-Science) DataMiningGrid FP6 EU project ADaM University of Alabama Terra Wide Data Mining Testbed University of Illinois at Chicago Grid Miner University of Vienna Data Cutter University of Maryland Weka4WS University of Calabria European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 36 - COREGRID KDM INSTITUTE European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 37 - CoreGRID KDM Institute • The KDM Institute is providing a collaborative environment for 13 research teams working on: – Distributed storage management on GRIDs – Data Access and Semantic GRID techniques and tools for supporting data intensive applications – Knowledge discovery and data mining in GRIDs. • With focus also on – Service Level Agreement Negotiation and – Security Requirements for Data Management European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 38 - Objectives for the Institute (1) MAIN OBJECTIVE: • Strengthen joint activities of European research groups and promoting larger leading teams, operating as a Research Institute working on models and tools for KNOWLEDGE and DATA MANAGEMENT in GRIDs and P2P SYSTEMS. • Consolidate the research activities carried out till now by partners in the KDM Institute and among the CoreGRID Institutes. • Establish cooperation with future partners and look for interaction with other players in the area of KDM. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 39 - Objectives • Discuss R&D issues in Data Management in Grids scenarios. • Identify: – Missing Solutions in Distributed Data Management – Research Challenges in Global Data Management – Potential Overlaps and Gaps in current Research Activities – Common vision of Data Management and research interests – Industrial needs and transfer – Synergies and future common work European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 40 - Partners and Tasks Partners • JPA: three tasks in the areas 1. Distributed Storage Management • Storage Infrastructure • Storage Management Mechanisms • Specifying Management Policies 2. Information and Knowledge Management CETIC Belgium CNR-ISTI Italy ICS-FORTH Greece INFN Italy PSNC Poland STFC-RAL UK SZTAKI Hungary University of Calabria Italy • Semantic Modeling Cyprus University of Cyprus • Semantic Representation UK University of • Standardization and Manchester Integration University of Newcastle • Data Integration andresearchers Query More than 50 active and PhD students are involved UK reformulation in OGSA European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Italy CNR-ICAR Peer-to-Peer Technologies Grids - 41 - Institute Roadmap (1) • The research tasks that compose KDM Institute give a unified vision of the data and knowledge management in Grids through a layered approach that starts from efficient data storage techniques (Task 2.1) up to information management (Task 2.2) and knowledge representation and discovery (Task 2.3). • The main vision of this Institute is based on common models and frameworks that can integrate the research results of the involved partners and result in common activities that advance the present results and systems. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 42 - Institute Roadmap (2) • We started with Phase 1: “Exchanging partner information, experiences, and knowledge about techniques, tools and systems for Data and Knowledge Grids.” • Then moved to Phase 2: “Sharing and integration of common goals, research results, projects and system prototypes of Environments and Services for Data and Knowledge-based Grids.” • Now we are in Phase 3: Use of the results of the previous phases for providing a set of solutions in the KDM area and for envisioning a unified framework for handling data, information and knowledge on GRIDs. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 43 - KDM Research Groups • The Joint Research Groups are working on: 1. GRID Data Storage Access and Management Architecture • Partners: FORTH, PSNC, SZTAKI, UCY, INFN 2. Storage security • Partners: INFN, FORTH, STFC 3. GRID Data Integration Models and Architectures • Partners: UNICAL, UoM 4. Methods for Deriving GRID Trust and Security Policies for Managing VOs • Partners: CETIC, STFC 5. Distributed Data Mining in GRIDs and P2P Systems • Partners: UNICAL, ISTI-CNR, UCY 6. Adaptivity in Distributed Query and Workflow • Partners: UoM, UNCL European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 44 - Achievements – KDM Research Work • The KDM Institute developed new research results on: – Grid Services for distributed data mining (WekaxWS, Knowledge Grid) – Dynamic loading of services: extensions to support loading at different granularities (DYNASOAR) – Data integration and query reformulation in Grids (GDIS on OGSA-DQP) – A methodology for deriving Grid Trust and Security Policies for VOs – A distributed storage virtualization architecture – Adaptive scalable data mining algorithms (Frequent Itemsets Mining - FIM) – A model for self-configuring Storage Area Networks (Conductor) – The design of an ontology for Grid scheduling – Scalable information services for large-scale Grids European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 45 - Cooperation With Other Institutes • Semantic support for Meta-scheduling in Grids (University of Manchester & Fraunhofer SCAI & JUELICH) WP2-WP6 • P2P Models for Resource Discovery, Data Management and Reliable Grid Services (University of Calabria & SICS & KTH) WP2-WP4 • Grid Scheduling for data-intensive applications (University of Dortmund & University of Calabria ) WP2-WP6 • Dynamic adjustment of block size for minimum data transfer cost in Data Grids (University of Cyprus & University of Manchester) WP2-WP4 • Trust management in Grids WP2-WP4 (STFC, University of Coimbra) • Public resource computing for Data Management (University of Calabria & University of South Wales) European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 46 - WP2-WP7 Joint publications • Many joint papers and technical reports on the KDM topics have been published in journals and conferences by KDM researchers in the second year of activities. • A book has been published in the SPRINGER CoreGRID series as a Post proceedings of the First Workshop on Knowledge and Data Management • The post-proceedings of the First CoreGrid Middleware workshop have been published by Springer in the LNCS series. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 47 - Conclusions (1) • Science and industry must be able to handle very large data sources (archives, databases, flat files). • Data management and knowledge discovery tools are necessary to find what is interesting in them. • Grids may be used as a distributed infrastructure for service-based data intensive applications. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 48 - Conclusions (2) • We are much more able to store data than to extract knowledge from it. • The integration of knowledge discovery and Grid technologies can help in this task. • Future Applications in Science and Business: Internet-scale distributed computing integrating data and knowledge services + computing services • Collection of world-wide Grid/Web services implementing complex applications. European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 49 - THANKS www.coregrid.net European Research Network on Foundations, Software Infrastructures and Applications for large scale distributed, GRID and Peer-to-Peer Technologies - 50 -