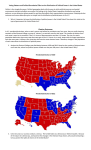
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Optimal Campaigning in Presidential Elections: The Probability of Being Florida David Strömberg∗ IIES, Stockholm University December 8, 2002 Abstract This paper delivers a precise recommendation for how presidential candidates should allocate their resources to maximize the probability of gaining a majority in the Electoral College. A two-candidate, probabilistic-voting model reveals that more resources should be devoted to states which are likely to be decisive in the electoral college and, at the same time, have very close state elections. The optimal strategies are empirically estimated using state-level opinion-polls available in September of the election year. The model’s recommended campaign strategies closely resemble those used in actual campaigns. The paper also analyses the policy effects of electoral reform. It finds that resources will be more equally distributed under Direct Vote than under the Electoral College system, and that both systems discipline presidents from extracting political rents to an equal extent. ∗ [email protected], IIES, Stockholm University, S-106 91 Stockholm. I thank Steven Brams, Steve Coate, Antonio Merlo, Torsten Persson, Gerard Roland, Tom Romer, Howard Rosenthal, Jim Snyder, Jörgen Weibull, and seminar participants at UC Berkeley, Columbia University, Cornell University, the CEPR/IMOP Conference in Hydra, Georgetown University, the Harvard / MIT Seminar on Positive Political Economy, IIES, New York University, Stanford University, University of Pennsylvania, Princeton University, and the Wallis Conference in Rochester. Previous versions have been circulated under the titles: ”The Lindbeck-Weibull model in the Federal US Structure”, and, ”The Electoral College and Presidential Resource Allocation”s. JEL-classification, D72, C50, C72, H50, M37. Keywords: elections, political campaigns, public expenditures 1. Introduction The President of the United States is arguably the worlds most powerful political leader, and the incentives created by his electoral procedure are important. In consequence, it is not surprising that the Electoral College system1 has been under constant debate. According to federal historians, there have been more proposals for constitutional amendments to alter or abolish the Electoral College than on any other subject. The issue was further put in focus by the 2000 election featuring a razor thin victory and a president elect who lost the popular vote. Still, the effects of the Electoral College system are not well understood and academic research on the topic is underdeveloped. This paper attempts to fill this void by providing the first empirically reasonable, fullfledged game-theoretic model of political competition under the Electoral College system. Moreover, it uses the model to provide precise answers to a range of questions: what would resource allocations look like if candidates try to maximize the probability of winning, are they doing this, who would gain and who would lose if the president was instead elected through a direct national vote, which system creates a more equal distribution of resources, which system will better protect voters from political rent-seeking? A major difference between this paper and earlier work is the complete integration of theory and empirics, tying together theoretical insights with empirical results on actual campaigns. This is done by constructing a probabilistic-voting model that can both be explicitly solved, and directly estimated. The explicit solution draws on use of a Central Limit Theorem approximation, while the possibility of direct estimation draws on a careful modelling of political preferences and election uncertainty. The uncertainty, which makes the voting-model probabilistic, is estimated by using the errors of a vote forecast. The most closely related theoretical work is Snyder’s (1989) model of two-party competition for legislative seats. Although the equilibrium of this model is not explicitly solved, some important qualitative features are characterized. Snyder (1989) finds that equilibrium campaign allocations are higher in districts with close to 50-50 vote shares. Further, if the goal of the parties is to maximize the probability of winning a majority of seats, then allocations are also higher in districts which are more likely to be pivotal. Finally, more resources will be spent in safe districts of the advantaged party than in the safe districts of the other party. Snyder’s paper studies one-member districts and therefore does not allow for variation in size necessary for the analysis of the Electoral College. Size effects are instead included in Brams and Davis’ (1974) study of presidential campaigning. On the other hand, they abstract from differences in vote-shares by assuming that votes in each state are cast with equal probability for each candidate. Brams and Davis (1974) find that presidential candidates should allocate resources disproportionately in favor of large states. Their result is disputed by Colantoni, Levesque and Ordeshook (1975) who instead argue that a proportional rule, modified to take into account the closeness of the state election, predicts actual campaign allocations better. Inspired by these results, Nagler and Leighley (1992) empirically investigate state-by-state campaign expenditures on 1 In this system, a direct vote election is held in each state and the winner of the vote is supposed to get all of that state’s electoral votes. Then all the electoral votes are counted, and the candidate who receives most votes wins the election. (The fact that Maine and Nebraska organize their presidential elections by congressional district is disregarded in this paper.) 2 non-network advertising in 1972 and find these to be higher in states with closer elections and more electoral votes. A separate theoretical literature has analyzed the policy effects of plurality versus proportional representation election systems. For example, Persson and Tabellini (1999), and Lizzeri and Persico (2001), find that under plurality rule governments tend to overprovide redistributive spending, relative to public goods, because its benefits can be more easily targeted. The model finally reveals a link between all of the above literature and the literature concerning ”voting power”, that is, the probability that a vote is decisive in an election. The statistical properties of voting power have been analyzed extensively; see Banzaf (1968), Chamberlain and Rothschild (1988), Gelman and Katz (2001), Gelman, King and Boscardin (1998)), and Merrill (1978). The "voting power" analyzed in this paper is slightly different since it is conditional on the candidates’ equilibrium strategies. The estimable probabilistic-voting model developed in this paper is quite general. It can be used to analyze a range of resource allocation problems in a variety of electoral settings. As shown in this paper, it can be used to analyze the allocation of campaign resources as well as redistributive spending and political rents under the Electoral and Direct Vote systems. With a minor adjustment, it may also be used to analyze the allocational strategies of parties trying to win a majority of one-member districts, in, say, US Congressional elections. In Strömberg (2002b), the model is adapted to analyze endogenous voter turnout. Section 2 develops the theoretical model. The probability distribution for election outcomes suggested by the model is empirically estimated in Section 3. These estimates are used to confront the model’s predictions with actual campaign efforts in Section 4. Section 5 interprets the equilibrium. Section 6 addresses the effects of a change to a Direct Vote system. Finally, Section 7 discusses the results and concludes. 2. Model Two presidential candidates, indexed by superscript R and D, try to maximize their expected probability of winning the election by selecting the number of days, ds , to campaign in each state s, subject to the constraint S X s=1 dJs ≤ I, J = R, D. In each state s, there is an election. The candidate who receives a majority of the votes in a state gets all the es electoral votes of that state. After elections have been held in all states, the electoral votes are counted, and the candidate who gets more than half those votes wins the election. There is a continuum of voters, indexed by subscript i, a mass vs of which live in state s. Campaigning in a state increases the popularity of the campaigning candidate ¡ J ¢ among voters in that state, as captured by the increasing and concave function u ds .2 The 2 This paper does not address the question of why campaigning matters. This is an interesting question in its own right, with many similarities to the question of why advertisements affect consumer choice. 3 voters also care about some fixed characteristics of the candidates, captured by parameters Ri , η s , and η. The parameter Ri represents an individual-specific ideological preference in favor of candidate R, and η s and η represent the general popularity of candidate R in state s and nation, respectively. The voters may vote for candidate R or candidate D, and voter i in state s will vote for D if ¡ ¢ ¡ R¢ ∆us = u dD (2.1) s − u ds ≥ Ri + η s + η. At the time when the campaign strategies are chosen, there is uncertainty about the popularity of the candidates on election day. This uncertainty is captured by the random variables η s and η. The candidates know that the S state level popularity parameters, η s , and the national popularity parameter, η, are independently drawn from cumulative distribution functions Gs = N(0, σ 2s ), and H = N (0, σ 2 ) respectively, but they do not know the realized values. of voters’ ideological preferences, Ri , within each state is Fs = ¡The 2distribution ¢ N µs , σ f s , a normal distribution with mean µs and variance σ 2f s . The means of the states’ ideological distributions may shift over time, but the variance is assumed to remain constant. The share of votes that candidate D receives in state s is Fs (∆us − η s − η). This candidate wins the state if 1 Fs (∆us − η s − η) ≥ , 2 or, equivalently, if η s ≤ ∆us − µs − η. The probability of this event, conditional on the aggregate popularity η, and the campaign R visits, dD s , and ds , is Gs (∆us − µs − η) . (2.2) Let es be the number of votes of state s in the Electoral College. Define stochastic variables, Ds , indicating whether D wins state s Ds = 1, with probability Gs (·) , Ds = 0, with probability 1 − Gs (·) . The probability that D wins the election is then # " X X 1 P D (∆us , η) = Pr Ds es > es . 2 s s (2.3) However, it is difficult to find strategies which maximizes the expectation of the above probability of winning. The reason is that it is a sum of the probabilities of all possible combinations of state election outcomes which would result in D winning. The number of such combinations is of the order of 251 , for each of the infinitely many realizations of η. 4 A way to cut this Gordian knot, and to get a simple analytical solution to this problem, is to assume that the candidates are considering their approximate probabilities of winning. Since the η s are independent, so are the Ds . Therefore by the Central Limit Theorem of Liapounov, P s Ds es − µ σE where X µ = µ (∆us , η) = es Gs (∆us − µs − η) , (2.4) s and σ 2E = σ 2E (∆us , η) = X s e2s Gs (·) (1 − Gs (·)) , (2.5) is asymptotically distributed as a standard normal. The mean, µ, is the expected number of electoral votes. That is, the sum of the electoral votes of each state, multiplied by the probability of winning that state. The variance, σ 2E , is the sum of the variances of the state outcomes, which is the e2s multiplied by the usual expression for the variance of a Bernoulli variable. Using the asymptotic distribution, the approximate probability of D winning the election, conditional on η, is ¶ µ1 P e − µ s s D 2 . (2.6) Pe (∆us , η) = 1 − Φ σE The approximate probability of winning the election is Z D P (∆us ) = PeD (∆us , η) h (η) dη.3 (2.7) Let the set of allowable campaign visits be ( ) S X X = d ∈ <S+ : ds ≤ I . s=1 ¡ ¢ The Nash Equilibrium strategies dD∗ , dR∗ in the competition between the two candidates are characterized by ¡ ¢ ¡ ¢ ¡ ¢ P D dD∗ , dR ≥ P D dD∗ , dR∗ ≥ P D dD , dR∗ for all dD , dR ∈ X. This game has a unique interior pure-strategy equilibrium characterized by the proposition below. ¡ ¢ Proposition 1. The unique pair of strategies for the candidates dD , dR that constitute an interior NE in the game of maximizing the expected probability of winning the election must satisfy dD = dR = d∗ , and, for all s and for some λ > 0, Qs u0 (d∗s ) = λ, (2.8) 3 The error made from using the approximate probability of winning is discussed in Section 5. For further discussion, see Appendix 6.8 of Stromberg (2002). 5 where ∂P D . ∂∆us Qs = (2.9) Proof: See Appendix 8.1. Proposition 1 says that presidential candidates, trying to maximize their probability of winning the election, should spend more time in states with high values of Qs . This follows since u0 (d∗s ) is decreasing in d∗s . Note that Qs can be decomposed into two additively separable parts: (2.10) Qs = Qsµ + Qsσ Z 1 = es ϕ (x (η)) gs (−µs − η) h (η) dη σE ¶ µ Z e2s 1 − Gs (−µs − η) gs (−µs − η) h (η) dη, + 2 ϕ (x (η)) x (η) σE 2 where 1 2 P s es −µ . σE One arises because the candidates have an incentive to influence the expected number of electoral votes won by D, that is the mean of the normal distribution. The other arises because the candidates have an incentive to influence the variance in the number of electoral votes. To evaluate Qs , I now use the structure of the model to estimate the probability distribution for election outcomes. x (η) = 3. Estimation This estimation provides the link between the theoretical probabilistic-voting model above and the empirical applications discussed below. In equilibrium, both candidates choose the same allocation, so that ∆us = 0 in all states. The Democratic vote-share in state s at time t equals ¶ µ −µst − η st − η t yst = Fst (−η st − η t ) = Φ , (3.1) σf s where Φ (·) is the standard normal distribution, or equivalently, Φ−1 (yst ) = γ st = − 1 (µ + η st + η t ) . σ f s st (3.2) For now, assume that all states have the same variance of preferences, σ2f s = 1, and the same variance in state-specific shocks, σ 2s .4 The former assumption implies that the marginal voter density, conditional on the state election being tied, is the same in all 4 These assumptions will be removed in Section 6. However, the estimates become imprecise if separate values of µst , σ f s , and σ s are estimated for each state using only 14 observations per state. Therefore, the more restrictive specification will be used for most of the paper. 6 states. Further assume that the mean of the preference distribution, µst , depends on a set of observable variables Xst . Then we get the following estimable equation, γ st = − (Xst β + η st + η t ) . (3.3) The parameters β, σ s and σ are estimated using a standard maximum-likelihood estimation of the above random-effects model.5 The variables in Xst are basically those used in Campbell (1992). The nation-wide variables are: the Democratic vote share of the two-party vote share in trial-heat polls from mid September (all vote-share variables x are transformed by Φ−1 (x)); second quarter economic growth; incumbency; and incumbent president running for re-election. The state-wide variables for 1948-1984 are: lagged and twice lagged difference from the national mean of the Democratic two-party vote share; the first quarter state economic growth; the average ADA-scores of each state’s Congress members the year before the election; the Democratic vote-share of the two-party vote in the midterm state legislative election; the home state of the president; the home state of the vice president; and dummy variables described in Campbell (1992). After 1984, state-level opinion-polls were available. For this period, the state-wide variables are: lagged difference from the national mean of the Democratic vote share of the two-party vote share; the average ADA-scores of each state’s Congress members the year before the election; and the difference between the state and national polls. Other state-wide variables were insignificant when state polls were included. The coefficients β and the variance of the state-level popularity shocks, σ2s , are allowed to differ when opinion polls were available and when they were not. Estimates of equation (3.3) yields forecasts by mid September of the election year. The data-set contains state elections for the 50 states 1948-2000, except Hawaii and Alaska which began voting in the 1960 election. During this period there were a total of 694 state-level presidential election results. Four elections in Alaska and Hawaii were excluded because there were no lagged vote returns. Nine elections are omitted because of idiosyncrasies in Presidential voting in Alabama in 1948, and 1964, and in Mississippi in 1960; see Campbell (1992). This leaves a total of 681 observations. The estimation results are shown in Table 1. The estimated standard deviation of the state level shocks after 1984 , σ bs , equals 0.077, or about 3% in vote shares. This is more than twice as large as that of the national shocks, σ b = 0.033. The estimated state-preference means are b µ bst = Xst β. The average absolute error in state-election vote-forecasts, Φ (b µst ), is 3.0 percent and the wrong winner is predicted in 14 percent of the state elections. This precision is comparable to the best state-level election-forecast models (Campbell, 1992; Gelman and King, 1993; 5 The model has been extended to include regional swings, see Appendix 6.4 of Strömberg (2002). In this specification, the democratic vote-share in state s equals yst = Fst (η st + ηrt + ηt ) , where ηrt denotes independent popularity shocks in the Northeast, Midewest, West, and South. However, taking into account the information of September state-level opinon polls, there are no significant regional swings. Therefore, the simpler specification without regional swings is used below. 7 Holbrook and DeSart, 1999; Rosenstone, 1983). Given µ bst , σ bs and σ b, Qs can be calculated using equation 2.10. 4. Relation between Qs and actual campaigns This section compare the equilibrium campaign strategies, based on the above estimates, to actual campaign strategies. The first sub-section will investigate presidential candidate visits to states in last three months of the 2000 election, and also more loosely discuss visits during the 1988-1996 elections. The second sub-section will study the allocation of campaign advertisements across media markets in last three months of the 2000 campaign. 4.1. Campaign visits If one assumes that u (ds ) is of log form, then the optimal allocation, based on equation (2.8) is, Q d∗ Ps ∗ = P s , (4.1) ds Qs and the number of days spent in each state should be proportional to Qs . The Bush and Gore campaigns were very similar to the model-predicted equilibrium campaign based on September opinion polls. The actual number of year 2000 campaign visits, after the party conventions, and Qs , are shown in Figure 4.1.6 Campaign visits by vice presidential candidates are coded as 0.5 visits. The model and the candidates’ actual campaigns agree on 8 of the 10 states which should receive most attention. Notable differences between theory and practice are found in Iowa, Illinois and Maine, which received more campaign visits than predicted, and Colorado, which received less. Perhaps extra attention was devoted to Maine since its (and Nebraska’s) electoral votes are split according to district vote outcomes. Other differences could be because the campaigns had access to information of later date than mid September, and because aspects not dealt with in this paper matter for the allocation. The raw correlation between campaign visits and Qs is 0.91. For Republican visits the correlation is 0.90 and for Democratic visits, 0.88. A tougher comparison is that of campaign visits per electoral vote, ds /es , with Qs /es . The correlation between ds /es and Qs /es was 0.81 in 2000. Finally, I look at the 1996, 1992, and 1988 campaigns. For these campaigns, only presidential visits are available. The correlation between visits and Qs during those years are 0.85, 0.64, and 0.76, respectively. But this is mainly a result of presidential candidates spending more time in large states. For the 1996, 1992, and 1998 elections, the correlation between ds /es and Qs /es was 0.12, 0.58, and 0.25 respectively. An explanation for the poor fit in 1996 and 1988 may be that these elections were, ex ante, very uneven. The expected Democratic vote shares in September of 1996, 1992, and 1988 were 56, 50, and 46 percent. In uneven races, perhaps the candidates have other concerns, such as affecting the congressional election outcome, rather than maximizing the probability of winning the presidential election. 6 I am grateful to Daron Shaw for providing me with the campaign data. 8 0 2 4 6 percent 8 10 Florida Michigan Pennsylvania California Ohio Missouri Tennessee Wisconsin Washington Louisiana Oregon Illinois Iowa Kentucky Arkansas Colorado North Carolina New Mexico Georgia New Hampshire Arizona Nevada Minnesota New Jersey Delaware Connecticut Mississippi Virginia Qs ∑ Qs West Virginia Indiana Maryland Actual campaign visits Wyoming Maine Montana North Dakota South Dakota Alabama Alaska South Carolina Vermont New York Hawaii (Utah, Texas, Rhode Island, Oklahoma, Texas, Nebraska, Massachusetts, Kansas, Idaho) ≈ 0 for both series. Figure 4.1: Actual and equilibrium campaign visits 2000 9 12 4.2. Campaign advertisements Appendix 8.3 models the decision of presidential candidates to allocate advertisements across Designated Market Areas (DMAs).7 In that model, two presidential candidates have a fixed advertising budget I a to spend on am ads in each media market m subject to M X m=1 pm aJm ≤ I a , J = R, D, where pm is the price of an advertisement. Media market m contains a mass vms of voters in state s. Voters are now also affected by campaign advertisements as captured by the increasing and concave function w(am ). A voter i in media market m in state s will vote for D if ¡ D¢ ¡ R¢ ¡ R¢ ¡ ¢ u dD s + w am − u ds − w am ≥ Ri + η s + η. The equilibrium number of visits is still characterized by equation (2.8). In equilibrium, both candidates choose the same advertising strategy. Advertising in media market m is increasing in Qpmm , where S X nms Qm = Qs . ns s=1 Qm is the sum of the Qs of the states in the media market weighted by the share of the population of state s that lives in media market m. The advertisement data is from the 2000 election and was provided by the Brennan Center.8 It contains the number and cost of all advertisements relating to the presidential election, aired in the 75 major media markets between September 1 and Election Day. The data is disaggregated by whether it supported the Republican, Democrat, or independent candidate, and by whether it was paid for by the candidate, the party or an independent group. The cost estimates, pm , are average prices per unit charged in each particular media market. The estimates are made by the Campaign Media Analysis Group. Advertisements were aired in 71 markets, where the data set records a total of 174 851 advertisements, for a total cost of $118 million, making an average price of $680. The Democrats spent $51 million, while Republicans spent $67 million. To measure total campaign efforts, I sum together the advertisements by the candidates, the parties and independent groups supporting the Democratic or Republican candidate. Figure 4.2 illustrates the predicted and actual advertising. The model and the data agree on the two media markets where most ads should be aired (Albuquerque - Santa Fe, and Portland, Oregon). These two markets have the highest effect on the win probability per advertising dollar. In third place the model puts, Orlando - Daytona Beach - Melbourne, while the data has Detroit (number four in the model). The correlation 7 A DMA is defined by Nielsen Media Research as all counties whose largest viewing share is given to stations of that same market area. Non-overlapping DMAs cover the entire continental United States, Hawaii and parts of Alaska. 8 The Brennan Center began compiling this type of data for the 1998 elections. According to them, no such data exists elsewhere for any other election. This is a new and unique database. 10 Portland, Oregon 7620 Total advertisements Albuquerque - Santa Fe Lexington 0 Denver 0 7620 Qm/pm Figure 4.2: Total number of advertisements Sept. 1 to election day and Qm /pm , for the 75 largest media markets between actual campaign advertisement and equilibrium advertisement is 0.75. That few advertisements were aired in Denver is consistent with the few candidate visits to Colorado (recall Figure 4.1). The few advertisements in Lexington are more surprising, since candidate visits to Kentucky were close to the equilibrium number. To see why Albuquerque - Santa Fe gives a large effect per advertising dollar, note that we can decompose Qpmm into four terms: Qm X nms es Qs 1 = . pm nm ns es pm /nm s |{z} |{z}|{z}| {z } (o) (i) (ii) (4.2) (iii) = (o) 95 percent of the population of Albuquerque - Santa Fe live in New Mexico ( nnms m 0.95), and 5 percent in Colorado. (i) Since New Mexico is a small state with only 1.8 million inhabitants, it had a high number of electoral votes per capita. (ii) Since New Mexico had a forecasted Democratic vote-share of 51.8%, it had a very high value of Qs per electoral vote. This relationship will be discussed in Section 5, see Figure 5.3 for a preview. (iii) At the same time, the average cost of an ad per million inhabitants in the media market is only $209, compared to the average media-market cost, which is $270. In comparison, the Detroit media market lies entirely in Michigan which had the highest value of Qs per electoral vote. However, being a fairly large state, Michigan only has 1.8 electoral votes per million inhabitants. Further, the average cost of an ad in Detroit is higher than in Albuquerque - Santa Fe. Therefore, the marginal impact on the probability of winning per dollar is lower than in Albuquerque - Santa Fe. Finally, one can note that since the correlation between price and market size is close to one (0.92), there is no significant relationship between market size and the number of ads.Via the price, the size is instead captured in the costs. Assuming log utility, equilibrium expenditures, pm a∗m , are proportional to Qm . Empirically, the simple correlation between advertisement costs, pm am , and Qm is 0.88. 11 5. Interpretation This section discusses what Qs measures and why it varies across states. A qualified guess is that Qs is approximately the joint ”likelihood” that a state is actually decisive in the Electoral College and, at the same time, has a very close election. I will call states who are ex post decisive in the Electoral College and have tied state elections decisive swing states. In the 2000 election, Florida was a decisive swing state. In contrast, neither New Mexico nor Wyoming were decisive swing states. While New Mexico was a swing state with a very close state-election outcome, it was not decisive in the Electoral College since Bush would have won with or without the votes of New Mexico. While Wyoming was decisive in the Electoral College, since Gore would have won the election, had he won Wyoming, it was not a swing state. The above guess is based on the fact that the probability of being a decisive swing state replaces Qs in the equilibrium condition of the model without the Central Limit approximation. Further, Appendix 8.2 shows heuristically, why the analytical expression for Qs approximates the probability of being a decisive swing state. In this Appendix, Qs is also shown to approximately equal the "voting power" of state s, multiplied by the marginal voter density conditional on the state election being tied. To investigate whether Qs is indeed an almost exact approximation of the probability of being a decisive swing state, one million electoral vote outcomes were simulated for each election 1988-2000 by using the estimated state-preference means, and drawing state and national popularity-shocks from their estimated distributions.9 Then, the share of elections where a state was decisive in the Electoral College and at the same time had a state election outcome between 49 and 51 percent was recorded. This provides an estimate which should be roughly equal to Qs , up to a scaling factor, see Appendix 8.2. Figure 5.1 contains the simulated shares on the y-axis and values computed from the scaled, analytic expression of Qs , on the x-axis. Large states are trivially more likely to be decisive. To check that the correlation between Qs and the simulated values is not just a matter of size, the graph on the right contains the same series divided by the state’s number of electoral votes. The simple correlation in the diagram to the right is 0.997. So the two variables are interchangeable, for practical purposes. The 0.003 difference could result on the Qs -side from using the approximate probability of winning the election, and on the simulation-side from using a finite number of simulations and recording state election results between 49 and 51 percent, whereas theoretically it should be exactly 50 percent. To illustrate how Qs varies across states, I will use the year 2000 election, see Figure 5.2. Based on polls available in mid September, 2000, Florida, Michigan, Pennsylvania, California, and Ohio were the states most likely to be decisive in the Electoral College and at the same time have a state election margin of less than 2 percent. This happened in 2.2 percent of the simulated elections in Ohio and 3.4 percent of the simulations in Florida. In comparison, the scaled, analytic expression for Qs equals 3.5 percent for Florida. (Using Qs , the probability that Florida would be decisive in the Electoral College and have a 9 Replace bst in equation (3.1), and draw ηst and ηt from their estimated distri³ µst by ´ the estimated ³ ´ µ 2 2 butions N 0, σ bs and N 0, σ b , respectively to generate election outcomes yst . 12 .002 0 Pivotal and close per electoral vote Simulated share pivotal and close elections .047 0 Qs .055 0 0 Qs per electoral vote .002 Figure 5.1: Qs and simulated probability of being a decisive swing state state margin of victory of 1000 votes may also be calculated. This probability is 1.5 in 10 000. The probability that this would happen in any state is .44 percent.) The analytic expression for Qs explains exactly why some states are more likely to be decisive swing states. First, Qs is roughly proportional to the number of electoral votes.10 While Qsµ and, Qsσ are proportional to electoral votes and electoral votes squared, respectively, see equation (2.10), Qsσ is generally considerably smaller than Qsµ . This implies that candidates should, on average, spend more time in large states. However, for states of equal size there is considerable variation. To explain differences relative to size, we next study Qs /es . In Figure 5.3, the circular dots show the share of the simulated elections where a state was decisive in the Electoral College and at the same time had a state-election outcome between 49 and 51 percent, per electoral vote. The solid line shows Qsµ /es . Its normal form arises because the candidates try to affect the expected number of electoral votes, see equation (2.10). This part of Qs /es accounts for most of the variation in the simulated values. It explains why states like New York and Texas in a million simulated elections are never decisive in the Electoral College and at the same time have close state elections. But in Florida, Michigan, Pennsylvania, and Ohio this happens quite frequently. The solid line is in fact a normal distribution, multiplied by a constant. It is characterized by three features: its amplitude, its mean, and its variance. The amplitude of Qsµ /es is trivially higher when the national election is expected to be close. This affects all states in a single election in the same way. It explains why the average Qsµ varies between elections. 11 10 This can be contrasted to the finding that ”voting power”, that is, the probability that a vote is pivotal in the election is more than proportional to size (Banzaf 1967, Brams and Davis 1974). ”Voting power” is roughly proportional to Qs , and thus roughly proportional to size. The difference results from all voters being equally likely to vote for one candidate or the other in their models, while voters preferences for the candidates in my model are heterogenous and subject to aggregate popularity shocks, see Chamberlain and Rothschild (1981) for a theoretical discussion and Gelman and Katz (2001) for empirical results. 11 Formally, define e ηt P to be the national popularity-swing which would give equal expected Electoral Vote shares, µ (e η) = 12 s es . Then Qsµ is larger when e ηt is close to zero; See equation (8.6) in the Appendix. 13 0 0,5 1 1,5 percent 2 2,5 3 3,5 Florida Michigan Pennsylvania California Ohio Missouri Tennessee Wisconsin Washington Louisiana Oregon Illinois Iowa Kentucky Arkansas Colorado North Carolina New Mexico Georgia New Hampshire Arizona Nevada Minnesota New Jersey Delaware Connecticut Mississippi Virginia West Virginia Indiana Maryland Wyoming Maine Montana North Dakota South Dakota Alabama Alaska South Carolina Vermont New York (Utah, Texas, Rhode Island, Oklahoma, Texas, Nebraska, Massachusetts, Kansas, Idaho) = 0 Hawaii Figure 5.2: Joint probability of being pivotal and having a state margin of victory less than two percent, based on September 2000 opinion polls. 14 Michigan (18) Simulated values, pivotal and close /es .0015 Qsµ /es Ohio .001 .0005 Pennsylvania California Wyoming Texas New York 0 30 40 50 60 70 µ ∗s Forecasted democratic vote share Figure 5.3: Probability of being a decisive swing state per electoral vote. The mean of Qsµ /es in Figure 5.3 is located slightly above 50%. This position is the result of a trade-off between average, and timely, influence on state election outcomes. To get the intuition, suppose that the Democrats are ahead by 60-40 in the national forecasts. In states with 50-50 forecasts, a candidate’s visit is more likely to influence the state election outcome. However, states where the Democrats are ahead 60-40 are likely to have close state elections exactly when the national election is close. Although the candidates are less likely to influence the state outcome, they are more likely to do so when it matters. The mean of Qsµ /es will always lie between 50-50 and the national forecast (60-40). Consider the example of the 1996 election. In September, Clinton was ahead by 60-40 in the national forecasts, as well as in Pennsylvania, whereas the forecasted outcome in Texas was 50-50. A visit to Texas was therefore more likely to affect the state outcome than a visit to Pennsylvania. However, if Texas was a 50-50 state on election day, then Clinton was probably winning by a landslide, and the electoral votes of Texas were probably not decisive in the electoral college. On the other hand, in the unlikely event that Pennsylvania was a 50-50 state on election day, the national election is likely to be close, and the electoral votes of Pennsylvania were likely to be decisive in the electoral college. Visits only matter if the state is a 50-50 state on election day, and the candidates must condition their visits on this circumstance. The model shows how to strike a balance between high average and timely influence. The less correlated the state election outcomes, the more time should be spent in 50-50 states like Texas. The reason is that without national swings, the state outcomes are not correlated, and a state being a swing state on election day carries no information about the outcomes in the other states. In my estimates maximum attention should typically be given to states in the middle, 55-45 in this example. In September of 2000, Gore was ahead by 1.3 percentage points. The maximum Qsµ /es was obtained for states where the expected outcome was a Democratic vote share of 50.8 percent, as illustrated in Figure 15 5.3.12 The variance in Qsµ /es depends on the uncertainty about the election outcome. Better state-level forecasts lead to a more unequal allocation of campaign resources as the variance of the normal-shaped distribution of Figure 5.3 decreases. States with forecasted vote shares close to the center of that distribution would gain while states far from the center would lose. Better national-level forecasts has a similar effect.14 Note that Wyoming and two other states to the left of the center are noticeably above the normal-shaped curve. The reason is that I could not find state-level opinion-poll data for these states, and the forecasts for these states are more uncertain. These states actually lie on a normal-shaped curve with a higher variance than that drawn in Figure 5.3. These observations illustrate one effect of improved forecasting on the allocation of resources. In Figure 5.3, note also that around its peak, the normal-shaped curve is far from the simulated probabilities of being a decisive swing state per electoral vote. States to the right of µ∗s , like Michigan and Pennsylvania, generally lie above the curve, while states on the left, like Ohio, generally lie below. The difference between the simulated values and Qsµ /es arises because the candidates also have incentives to influence the variance of the electoral vote distribution, even if this means decreasing the expected number of electoral votes, see Qsσ in equation (2.10). To get the intuition of why such behavior is rational, consider the following example from the world of ice-hockey. One team is trailing by one goal and there is only one minute left of the game. To increase the probability of scoring an equalizer, the trailing team pulls out the goalie and puts in an extra offensive player. Most frequently, the result is that the leading team scores. But the trailing team does not care about this, since they are losing the game anyway. They only care about increasing the probability that they score an equalizing goal, which is higher with an extra offensive player. Therefore, it is 12 These points are evident from the analytical form of the mean of equation (5.1), derived in Appendix 8.2. The mean equals σ2 µ∗st = − ηt , (5.1) 2e σ 2 + (σ E /a) where ¡ ¢ σ 2E = σ 2E dD = dR , η t = e ηt , X at = es gs (−µst − e η t ) .13 s The mean always lies between a pro-Republican state bias of µst = 0, which corresponds to a 50% forecasted Democratic vote share, and µst = −e η t , which approximately corresponds to the forecasted national Democratic vote share. (If the Democrats are ahead by 60-40 nationally, then a pro-Republican swing e η t , corresponding to about 10%, is needed to draw the election. Therefore µst = −e ηt corresponds to 10% pro-democrat bias in a state, that is, a vote share of 60-40.) The smaller the variance of the national popularity-swings, σ 2 , the closer is the mean to 50-50. In the extreme case where this variance equals zero, then µ∗s = 0. In the extreme case that σ approaches infinity, µ∗s approaches −e η. 14 The variance of the normal-form distribution, σ e2 = σ 2s + ³ 1 1 σ2 + 1 (σ E /a)2 ´, depends on the variance in the state, and national, level popularity shocks, see Appendix 8.2. 16 Variance effect, Qsσ/vs .0002 Michigan Pennsylvania .0001 0 Ohio -.0001 30 40 50 60 70 Forecasted democratic vote shares Figure 5.4: Incentive to influence variance better to increase the variance in goals, even though this decreases net expected goals. In contrast, if they were allowed, the leading team would like to pull out an offensive player and put in an extra goalie. Similarly, a presidential candidates who is behind should try to increase variance in the election outcome. He can do that by spending more time in large states where he is behind (putting in an extra offensive player), and less time in states where he is ahead (pulling the goalie). A candidate who is ahead should instead try to decrease variance in electoral votes, thus securing his lead, by spending more time in large states where he is ahead (putting in an extra goalie), and less time in states where he is behind (pulling out an offensive player). Both candidates thus spend more time in large states where the expected winner is leading. To formally see why a trailing candidate increases the variance by spending more time in states with many electoral votes where he is behind, consider equation (2.5) showing the variance, conditional on a national shock. The variance in the number of electoral votes from a state is proportional to these votes squared. Therefore, the effect on the total variance, per electoral vote, is larger in large states. Further, the variance in a state outcome is higher the closer the expected result is to a tie. By visiting a state where the leading candidate is ahead, the trailing candidate moves the expected result closer to a tie, and increases the variance in election outcome. Similarly, decreasing the number of visits to a state where the lagging candidate is leading increases the variance Figure 5.4 illustrates this effect in the year 2000 election. It plots the values of the analytical expression for Qsσ /es . The lagging candidate (Bush) should put in extra offensive visits in states like Michigan and Pennsylvania, at the cost of weakening the defense of states like Ohio. The leading candidate (Gore) should increase his defense of states like Michigan and Pennsylvania, at the cost of offensive visits to Ohio. This resounds with the result by Snyder (1989) that parties will spend more in safe districts of the advantaged party than in safe districts of disadvantaged party. Another way to use the model is to calculate the best-response to the other candidate’s actual strategy, even though it differs from the equilibrium. According to the model, 17 either candidate could have increased their probability of winning by about 2 percent compared to their actual strategies.15 The most important feature of the best responses is that Bush should spend more than the equilibrium time in California, which the Gore campaign left unguarded with very few visits. The expected democratic vote-share in California was 56 percent. Fewer visits by Gore moves the expected democratic voteshare closer to 50.8 percent, evaluated at Bush’s equilibrium strategy. This increases the probability of California being a decisive swing state, which increases Bush’s incentives to visit California. In fact, Bush spent more than the equilibrium amount of time in California. This, on the other hand, moves the expected democratic vote-share closer to 50.8 percent, evaluated at Gore’s equilibrium strategy, increasing Gore’s incentives to visit California. However, Gore visited California less than the equilibrium number of times. Roughly speaking, more visits is a best response to more offensive visits (Bush in California) or fewer defensive visits (Gore in California) by the opponent. Fewer visits is a best response to fewer offensive visits or more defensive visits by the opponent. 6. Electoral reform This section will explore the effects of a hotly debated institutional reform, namely, the change to a direct vote for president. According to federal historians, over 700 proposals have been introduced in Congress in the last 200 years to reform or eliminate the system. Indeed, there have been more proposals for constitutional amendments to alter or abolish the Electoral College than on any other subject. The debate intensified as the 2000 presidential election awarded George W. Bush the White House by a razor-thin victory, despite his losing the popular vote by a 337,000-vote margin. In consequence, a Washington Post/ABC News poll performed shortly after the election suggested that about 6 in 10 Americans would prefer to abandon the Electoral College and switch to a direct popular vote. The effects of reform on campaigning and economic policy have also been debated. Small states have voiced fear that, without the Electoral College, candidates might change their campaign patterns and shun them altogether. Others have argued that the Electoral College system creates a bias favoring small states. Finally, Lizzeri and Persico (2001), and Persson and Tabellini (1999), have argued that under the Electoral College, the distribution of targeted programs will be more concentrated, while political rents, and public goods provision will be lower than under Direct Vote. To discuss these issues, the model will first be modified to discuss economic policy formation under the Electoral College, and then further modified to discuss policy formation under Direct Vote. Economic policy Section 4 shows that politicians understand the incentives created by the Electoral College system. This section explores the consequences if policy is also influenced by election concerns. To analyze economic policy, one could just re-interpret the model of Section 4 as describing the incentives to make policy promises to states 15 This result depends on the functional form assumed for u (ds ) . I can not use log form since this is not defined for zero visits. Instead I use the exponential function u (ds ) = 0.018 ∗ d0.34 , where the two s constants were estimated in Strömberg (2002). 18 during the campaign. If a state is important for the election outcome, not only should the candidates visit that state, they should also make favorable policy promises to that state. However, the route taken in this section is to analyze the incentives of incumbent presidents to set policy for re-election concerns. Suppose each voter in state s receives utility from policy us = υ (zs ) − r +θ n where zs is redistributive spending per capita, nr is political rents per capita, and θ is the incumbent’s competence which is drawn from a known normal distribution with mean zero. The function υ is increasing and concave. Political rents describe a conflict of interest between the president and the voters. It could entail party financing, extra salaries, low effort and waste or outright corruption. The voter observes his total utility from policy, but not its separate components. So, the voter does not know whether utility from a government program is high because per capita spending is high, because the political rents are low, or competence is high. The incumbent president’s preferences are described by P + (r) where P is the approximate probability of re-election, defined below, and is an increasing and concave function. The timing is the following. First the incumbent sets policy. Then his competence and popularity shocks are realized. Next, the incumbent president runs against an opponent with unknown competence. After the election, the winner selects a fixed policy and the utility of the voters is determined by competence, ideology, and popularity. In this setting, voter i in state s will re-elect the (without loss of generality) democratic incumbent if E [θ] ≥ Ri + η s + η 0 . The voters observe us and form expectations, E [θ] = us − (υ (zs∗ ) − r∗ ) , where zs∗ and r∗ denote equilibrium policy. Therefore, the above equation becomes ∆us = υ (zs ) − r − (υ (zs∗ ) − r∗ ) ≥ Ri + η s + η. where η = η 0 − θ. The above equation has exactly the same structure as equation (2.1). The same distributional assumptions are now made regarding the exogenous parameters Ri , η s , and η, and the approximate probability of winning, P , is again defined by equations (2.4), (2.5), (2.6), and (2.7). The incumbent chooses economic policy to max P + (r) subject to a fixed budget constraint X ns zs = I. s Proposition 2. The incumbent strategy (z ∗ , r∗ ) that maximizes P + for all s and for some λ > 0, Qs 0 ∗ υ (zs ) = λ, ns 19 (r) must satisfy, (6.1) 0 (r∗ ) = where Qs = 1X Qs . n s (6.2) ∂P ∂∆us is defined by equations (2.9), (2.4) and (2.5). In equilibrium, the voters policy expectations are correct and ∆us = 0. Incumbent presidents will provide higher per capita Predistributive spending to states with high Qs . Political rents are lower the larger is s Qs , which measures the fall in re-election probability due to a small decrease in the utility of all voters. The estimated Qs will in general be different from those relevant for campaigning decisions. The reason is that decisions regarding economic policy must be taken earlier than September the election year. The incumbent president must make his policy decisions before the September opinion poll results are known. Therefore, Qs used for evaluating the effects on policy will be estimated without opinion poll data.16 Direct Vote Next, suppose the president is elected by a direct national vote. The number of Democratic votes in state s is then equal to vs Fs (∆us − η − η s ). The Democratic candidate wins the election if he receives more than half of the popular votes: X 1X vs Fs (∆us − η − η s ) ≥ vs . 2 s s The number of votes won by candidate D is asymptotically normally distributed with mean and variance X ∆us − µs − η vs Φ q µv = , (6.3) σ 2s + σ 2f s s σ 2v = σ 2v (∆us , η) . See Appendix 8.4 for the explicit expression for σ 2v . The probability of a Democratic victory is ¶ Z µ1 P s vs − µv D 2 P =1− Φ dη. σv The incumbent allocates spending and sets political rents to maximize P D + following proposition characterizes the equilibrium allocation. 16 (r). The This version of the model has been used in Strömberg (2002a), where it is found that federal civilian employment is higher when Qs is higher, even using time and state fixed effects and controlling for other determinants of employment. 20 ME Estimated marginal voter density .12 MA .1 OK LA FLNE SC GANY AL WV KY .08 SD NC PA MD AZ MS RI NJ NH CT MI OH KS AR UTTXMN VA IN IL MO WI TN CO DE WY IA VT WA ND NV ORNM MT ID CA .06 20 30 40 50 60 Share independents 1976-88 (Erikson, Wright and McIver) Figure 6.1: Marginal voter density and share independents Proposition 3. The incumbent strategy (z, r) that maximizes P D + for all s and for some λ > 0, QDV s υ 0 (zs ) = λ, ns X 0 (r) = QDV s . (r) must satisfy, (6.4) (6.5) s measures the likelihood of a draw in the national election, multiplied The variable QDV s by the expected marginal voter density, conditional on the national election being tied, multiplied by the number of voters in the state; see Appendix 8.4. Since the likelihood of a draw in the national election is the same in all states, QDV varies across states only s because of differences in the share of marginal voters and the number of voters. The allocation under Direct Vote depends crucially on the share of marginal voters, which in turn depends on the estimated variance in the preference distribution, σ2f s . Therefore, the restriction σ f s = 1 is removed in the maximum likelihood estimation of equation (3.2), as well as the assumption that σs is the same for all states. However, the empirical identification of σ f s and σ s is not trivial. If the election outcome in a certain state varies a lot over time, is this because the state has many marginal voters or is it because the state has been hit by unusually large shocks shifting voter preferences? The model solves this problem by identifying σ f s by the response in vote shares to changes that are common to all states, and observable changes in economic growth at national and state level, incumbency variables, home state of the president and vice president. States where the vote share outcome covary strongly with economic growth, etc., are thus estimated to have many marginal voters. Maine is estimated to have the largest share of marginal voters while California has the smallest. The estimated share of marginal voters is positively correlated with the share of independent voters as measured by Erikson, Wright and McIver (1993), as illustrated in Figure 6.1. The variance in the state popularity-shocks, σ 2s , is on average larger in southern states and smaller states. Spending We can now discuss the allocation of spending under the Electoral College (EC) and Direct Vote (DV ) systems. To structure the discussion, assume log utility so 21 that equilibrium per capita spending under DV equals zsDV = QDV s ns 1 n P QDV s I , n whereas the analogous expression for spending under EC is given by just substituting Qs for QDV s . The effect of reform is shown in Figure 6.2. The series are 1948-2000 averages, scaled so that 1 denotes equal per capita spending. States above 1 on the y-axis receive higher than average per capita spending under under the Electoral College system, whereas states to the right of 1 on the x-axis have higher than average per capita spending under under the Direct Vote system. Thus, states below the dashed 45 degree line would gain from reform, those above would lose. Some states, like Maine and New Hampshire, are well off under both systems while Mississippi is disadvantaged under both. Other states, like Nevada are among the winners in the present system but among the losers under Direct Vote. The opposite is true for Rhode Island and Kansas. The reasons why certain states would gain or lose can be separated into variation in (i) electoral size per capita and (ii) influence relative to electoral size. EC : Qs es Qs = , ns ns es |{z}|{z} (i) DV : (ii) vs QDV QDV s s = . ns ns vs |{z}| {z } (i) (ii) Figure 6.3 plots the 1948-2000 averages of, (i), electoral votes per capita million and voter turnout to the left, and, (ii), the probability of being a pivotal swing state per electoral vote and the share of marginal voters to the right. The latter have been scaled so that 1 denotes equal per capita influence relative to size. Nevada and Delaware would lose from reform primarily because of their heavy endowment of electoral votes relative to popular votes, while Ohio would lose primarily because it is likely to be a pivotal swing state, but does not have many marginal voters. On the winning side, Rhode Island and Massachusetts would gain because of their many marginal voters, while Kansas and Nebraska would gain because of their low probabilities of being decisive swing states in the present system. Small states have not, on average, been advantaged by the Electoral College system. Although small states are over-represented in terms of electoral votes, they have more often had lop-sided elections and have larger state-level uncertainty, σ 2s . On net, Qs /ns is not correlated with size.17 It is also the case that QDV s /ns is uncorrelated with state size. So small states, as a group, neither gain nor lose from electoral reform. Which political system creates a more unequal distribution of resources? The extreme variation in the probability of being a pivotal swing state per electoral vote creates very strong incentives for unequal distribution under the EC. The average probability that 17 I thank Andrew Gelman for pointing this out to me. 22 DE NV 2.5 Electoral College OHVT MT 2 NM NH ME MI WY WA IL CT MO WI NJ SD MD HI IA NY KY WV AK CO OR ND MN VA AL OK ID TN UT CA TX FL NC RI MA LA AR AZ IN SC GA MS NE KS PA 1.5 1 .5 0 0 .5 1 1.5 2 2.5 Direct Vote Figure 6.2: Redistributive spending per capita, relative to national average, under the Electoral College and Direct Vote (ii) WY 8 2.5 NV AK Qs/es : Pr(decisive swing state)/es Electoral votes per capita million (i) VT 6 DE ND MT NH SD ID DC HI 4 AR SC 2 .3 MS GA TN NC VA ALTXLA FL AZ NM KY MD RI ME UT NEWV KS IA OK CO OR CT MN WI WA MO MA PA OH NJ MI INIL NY CA .5 Voter turnout OH 2 PA 1.5 NM MT CA OR NV 1 .5 MS 0 .5 .7 ND ID AK IL WA MO WI MI CT DE NY MD KY NH IA VA FL AL CO TX WV VT HI TN LA NC MN SD OK AR SCGA IN WY AZ UT NJ ME MA RI KS NE 1 QsDV/vs : Marginal voter density 1.5 Figure 6.3: Variables affecting distribution under Electoral College and Direct Vote 23 Ohio is a pivotal swing state is more than twenty times that of Kansas. By comparison, Maine has only twice as high marginal voter density as California. To make things worse, the variation in electoral votes per capita is also higher than the variation in voter turnout. While Wyoming has four times as many electoral votes per capita as California, Minnesota has less than twice times the voter turnout of Hawaii. Given this, it is not surprising that the equilibrium allocation of redistributive expenditures is much less equal under EC. The Lorenz-curve of spending under EC is strictly below that of spending under the DV . This finding is consistent with Persson, and Tabellini (2000) and Lizzeri and Persico (2001) who conclude that spending will be more narrowly targeted under majoritarian elections. Persson and Tabellini (2000) analyze electoral competition in an election with three electoral districts. Their result is driven by the assumption that the district with the highest marginal voter density is always decisive in the electoral college (majoritarian election), while under proportional elections candidates internalize marginal voter density across all states, which is more equally distributed. Lizzeri and Persico (2001) use a very different framework, assuming no uncertainty about the election outcome, given candidate strategies. In consequence, candidates use completely mixed strategies and all states receive equal expected treatment. Political rents First a theoretical point: there is no a priori reason to believe that political rents would depend on the size or number of states. Rents are decreasing in X ∂P D X X es Qs = Qs = vs , ∂∆us vs es s s s which measures how the probability of re-election falls when the utility of all voters is decreased marginally. If Qs was more than proportionally increasing in the number of electoral votes, as suggested by Brams and Davis (1974), larger states would contribute more than proportionally to keeping rents low and the best electoral system would be to have just one state of maximum size (Direct Vote). However, Qs is roughly proportional to the number of electoral votes, see equation (2.10) and Figure (5.3), so all states contribute proportionally and there is no a priori reason to believe that size and number of states matter. Empirically, the ability to discipline politicians and Pkeep political P rents low is about the same for both electoral systems. Figure 6.4 plots s Qs and s QDV s , multiplied by an increase in political rents ∆r causing an average 5 percent fall in vote support.18 This fall is trivially higher in elections which are ex ante close. Therefore, equilibrium political rents are lower in 2000 than in 1984, under both electoral systems. Further, the average fall is about the same for the two systems and politicians would be disciplined to an equal extent. This depends on two factors, how the probability of re-election depends on a uniform fall in voter support across all states, and how the fall is likely to be distributed across states. First, the fall in the probability of being elected from a uniform loss of 5 percent ∆r = 0.05/average ϕ(·) σ f s . The figure describes the marginal incentives for political rents. As a measure of the probability of losing the election, there is an approximation error since Qs and QDV measure s marginal changes. 18 24 Electoral College .6 1988 1976 1960 2000 1952 .5 .4 1968 .3 1956 1992 1948 1996 .2 1964 .1 1980 1984 1972 1940 1944 .1 .2 .3 .4 .5 .6 Direct Vote Figure 6.4: Probability that an incumbent would loose the election because of a corruption scandal (5 percent fall in support) under EC and DV support in all states is around 33 percent both under EC and DV .19 This similarity is far from obvious since the frequency of quite different events are measured: that the incumbent loses by less than 5 percent in any state that is decisive in the electoral college; and that the incumbent loses the national election by less than 5 percent. Appendix 8.4 shows that this response is proportional to average "voting power", that is, the probability that one randomly drawn voter decides the election. The result is therefore consistent with the finding of Gelman and Katz (2001) that average voting power is about the same under EC and DV . However, the fall in support will not be uniform, it will be higher in states with many marginal voters. If the fall is larger in states (like Florida, Michigan, and Pennsylvania in 2000) who are likely to be decisive swing states, then the outcome under EC will be more sensitive to the corruption scandal than under DV . This turns out not to be true empirically, as these two variables are uncorrelated. A more direct measure of the share of marginal voters, the share of independent voters in Erikson, Wright and McIver (1993), is also not related to the likelihood of being a decisive swing state. In contrast, Persson and Tabellini (1999) conclude that there will be more corruption under Direct Vote than if the electorate is divided into three districts, a separate vote is held in each district, and the candidate with the most districts wins the election. They reach their conclusion by assuming that there are more marginal voters in the one district that is always decisive. This assumption, translated to our framework, is not valid in the case of the US as there are not more marginal voters in states more likely to be decisive swing states. Election statistics Finally, some argue that razor-thin victories, and presidents without a majority of the popular vote are unattractive features of an electoral system. The model can be used to estimate the probability of these events. Given that the elections 1948-2000 are representative of future elections, this can be done by simulating elections 19 This is estimated by simulations. 25 and recording event frequencies. The likelihood of a winning margin less than 1000 votes is about 50 times higher under the Electoral College system (0.4 percent compared to 0.008 percent under Direct Vote). The reason is that a margin of victory of, say, one percent, is equally likely in the two systems, but, since there are 50 states, one percent contains on average 50 times more voters under Direct Vote. This is consistent with equal average voting power under both systems. Every time a single voter is pivotal under DV , then all voters in the nation are pivotal. Every time a single voter is decisive under EC, then all voters in that state are decisive. The latter event occurs 50 times more often but involves 1/50 as many voters, so average voting power is the same. The probability of electing a president without a majority of the popular vote is about 4 percent. This implies that we should expect this outcome about once in every hundred years. Historically, this event has happened around three (perhaps four) times in the last 200 years: 1824 (perhaps), 1876, 1888, and 2000. Arguably, however, the outcomes in 1824 and 1876 had to do with peculiarities in the aggregation of votes.20 The above results support a reform of the Electoral College system in favor of Direct Vote. Such a reform would decrease political incentives to allocate resources unequally across states for electoral reasons. It would also decrease the probability of razor thin winning margins and, of course, the probability of electing presidents without support of a majority of the popular votes. There would be no cost in terms of less discipline on politicians. Also, small states need not fear reform. As a group, they are neither advantaged or disadvantaged by the present system, nor will they be under Direct Vote. 7. Conclusion and discussion This paper develops a game-theoretic model of how presidential candidates should allocate resources across states in order to get a majority of the electoral votes. After applying it empirically to the US, a large set of questions have been answered. What would resource allocations look like if candidates try to maximize the probability of winning a majority in the electoral college? Some theoretical results deserves mentioning. First, more resources should be devoted to states who are likely to be decisive swing states, that is, states who are decisive in the electoral college and, at the same time, have tied state elections. Second, the probability of being a decisive swing state equals the "voting power" in the state, multiplied by the marginal voter density conditional on the state election being tied. Third, the probability of being a decisive swing state is roughly proportional to the number of electoral votes. Fourth, this probability per electoral vote is highest for states who have a forecasted state election outcome which lies between a draw and the forecasted national election outcome. Fifth, more precise state-election forecasts make the optimal allocation of resources more concentrated. Sixth, the presidential candidates who is lagging behind should try to increase variance in electoral votes. This is done by spending more time in large states where this candidate is behind, and less time in large states where this candidate is ahead. 20 In 1824, six of the twenty four States at the time still chose their Electors in the State legislature, so the popular vote outcome is not known. In the chaotic election of 1876, each State delivered to Congress two slates of electors and a special commission accepted slates favoring of the popular vote loser. See "A Brief History of the Electoral College" in http://www.fec.gov/elections.html. 26 The second, fourth and fifth points are new, to the best of my knowledge. The first point shows more precisely what people have conjectured or partly demonstrated earlier, see, for example, Snyder (1989). The third point has not previously been shown theoretically, although (because of the second point) it is closely related to the empirical finding of Gelman and Katz (2001) that "voting power" is proportional to size under reasonable assumptions. The sixth point makes more precise the statement of Snyder (1989) that more resources will be spent in safe districts of the advantaged party than in the safe districts of the other party. More importantly, this paper quantifies these effects and shows that presidential candidates’ actual strategies very closely resemble the optimal strategies. The model is applied to presidential campaign visits across states during the 1988-2000 presidential elections, and to presidential campaign advertisements across media markets in the 2000 election. The actual allocation of these resources closely resembles the optimal allocation in the model. In the 2000 election, the correlation between optimal and actual visits by state is 0.91, and the correlation between optimal and actual advertisement expenditures by advertising market is 0.88. Who would gain and who would lose if the president was instead elected through a direct national vote? The gainers and losers from reform are identified as displayed in Figure 6.2. States like Kansas and Nebraska, would gain, while Nevada and Delaware would lose. Small states are, as a group, not favored by the Electoral College system. The distribution of redistributive spending is much more unequal under the Electoral College than under Direct Vote. This is basically because the probability of being a decisive swing state is extremely unevenly distributed. The same conclusion was reached by Lizzeri and Persico (2001) and Persson, and Tabellini (2000), but for different reasons. Third, unlike Persson and Tabellini (1999), this paper finds that both systems are about equally fit to discipline politicians from corruption or other activities which benefit them but hurt the voters. The main difference between this paper and the earlier work is the complete integration of theory and empirics, tying together theoretical insights with empirical results. Since the modelling framework is quite general, this integration can be carried over to the study of other resource allocation problems in other electoral settings. 27 References [1] Anderson, Gary M. and Robert D. Tollison, 1991, “Congressional Influence and Patterns of New Deal Spending, 1933-1939”, Journal of Law and Economics, 34, 161-175. [2] Banzhaf, John R., 1968, ”One Man, 3.312 Votes: A Mathematical Analysis of the Electoral College”, Villanova Law Review 13, 304-332. [3] Brams, Steven J. and Morton D. Davis, 1974, ”The 3/2 Rule in Presidential Campaigning.” American Political Science Review, 68(1), 113-34. [4] Campbell, James E., 1992, Forecasting the Presidential Vote in the States. American Journal of Political Science, 36, 386-407. [5] Chamberlain, Gary and Michael Rothchild, 1981, ”A Note on the Probability of Casting a Decisive Vote”, Journal of Economic Theory 25, 152-162. [6] Cohen, Jeffrey E., 1998, ”State-Level Public Opinion Polls as Predictors of Presidential Election Results”, American Politics Quarterly, Vol. 26 Issue 2, 139. [7] Colantoni, Claude S., Terrence J. Levesque, and Peter C. Ordeshook, 1975, ”Campaign Resource Allocation under the Electoral College (with discussion)”, American Political Science Review 69, 141-161. [8] Erikson, Robert S., Gerald C. Wright and John P. McIver, 1993, "Statehouse Democracy", Cambridge University Press. [9] Gelman, Andrew, and Jonathan N. Katz, 2001, ”How Much Does a Vote Count? Voting Power, Coalitions, and the Electoral College”, Social Science Working Paper 1121, California Institute of Technology. [10] Gelman, Andrew, and Gary King, 1993, ”Why are American Presidential Election Campaign Polls so Variable when Votes are so Predictable?”, British Journal of Political Science, 23, 409-451. [11] Gelman, Andrew, Gary King, and W. John Boscardin, 1998, ”Estimating the Probability of Events that have Never Occurred: when is your vote decisive?”, Journal of the American Statistical Association, 93(441), 1-9. [12] Hobrook, Thomas M. and Jay A. DeSart, 1999, ”Using State Polls to Forecast Presidential Election Outcomes in the American States”, International Journal of Forecasting, 15, 137-142. [13] Lindbeck, Assar and Jörgen W. Weibull, 1987, ”Balanced-Budget Redistribution as the Outcome of Political Competition”, Public Choice, 52, 273-97. [14] Lizzeri, Allesandro and Nicola Persico, 2001, "The Provision of Public Goods under Alternative Electoral Incentives", American Economic Review, 91(1), 225-239. 28 [15] Merrill, Samuel III, 1978, ”Citizen Voting Power Under the Electoral College: A Stochastic Voting Model Based on State Voting Patterns”, SIAM Journal on Applied Mathematics, 34(2), 376-390. [16] Nagler, Jonathan, and Jan Leighley 1992, ”Presidential Campaign Expenditures: Evidence on Allocations and Effects”, Public Choice 72„ 319-333. [17] Persson, Torsten and Guido Tabellini, 1999, ”The Size and Scope of Government: Comparative Politics with Rational Politicians,” European Economic Review 43, 699-735. [18] Persson, Torsten, and Guido Tabellini, 2000, Political Economics: Explaining Economic Policy, MIT Press. [19] Rosenstone, Steven J., 1983, ”Forecasting Presidential Elections”, New Haven: Yale University Press. [20] Shachar, Ron and Barry Nalebuff, 1999, ”Follow the Leader: Theory and Evidence on Political Participation”, American Economic Review 89(3), 525-547. [21] Shaw, Daron R., 1999, ”The Effect of TV Ads and Candidate Appearances on Statewide Presidential Votes, 1988-96, American Political Science Review 93(2), 345361. [22] Strömberg, David, 2002, ”Optimal Campaigning in Presidential Elections: The Probability of Being Florida”, IIES working paper 706. [23] Strömberg, David, 2002a, ”The Electoral College and the Distribution of Federal Employment”, Stockholm university, in preparation. [24] Strömberg, David, 2002b, ”Follow the Leader 2.0: Theory and Evidence on Political Participation in Presidential Elections”, Stockholm university, in preparation. [25] Snyder, James M., 1989, ”Election Goals and the Allocation of Campaign Resources”, Econometrica 57(3), 637-660. [26] Wallis, John J., 1996, “What Determines the Allocation of National Government Grants to the States?”, NBER Historical Paper 90. [27] Wright, Gavin, 1974, ”The Political Economy of New Deal Spending: An Econometric Analysis”, Review of Economics and Statistics 56, 30-38. 29 8. Appendix 8.1. Proof of Proposition 1 ¡ ¢ Since P D dD∗ , dR is continuous and differentiable, a necessary condition for an interior NE is ¡ ¢ ¡ ¢ ∂P D dD∗ , dR∗ = Qs u0 dD∗ (8.1) = λD , s D ∂ds ¡ ¢ ¡ R∗ ¢ ∂P D dD∗ , dR∗ 0 = Q u (8.2) ds = λR . s R ∂ds Therefore, ¡ ¢ u0 dD∗ λD s = R, (8.3) u0 (dR∗ λ s ) R∗ for all s. Suppose that dD∗ 6= dR∗ . This means that dD∗ s < ds for some s, implying that λD > λR by equation (8.3). Because of the budget constraint, it must be the case that D R∗ 0 dD∗ < λR , a contradiction. Therefore, λD = λR , s0 > ds0 for some s , which implies λ D∗ R∗ which implies ds = ds for all s. Uniqueness: Suppose there are two equilibria with equilibrium strategies d and d0 corresponding to λ > λ0 . The condition on the Lagrange multipliers implies ds > d0s for all s, which violates the budget constraint. Therefore, the only possibility is λ = λ0 , which implies ds = d0s for all s. 8.2. Derivation and interpretation of Qs To see, heuristically, why the analytical expression for Qs approximates the joint probability of a state being decisive in the electoral college at the same time as having a tied election, note that state s can only be decisive if the margin of victory in the electoral college is less than its electoral votes, es . To a second order approximation, this happens with probability µ1 P ¶ µ1 P ¶ s0 es0 + es − µ s0 es0 − es − µ 2 2 Φ −Φ σE σE ¶¶ µ µ 2 es 1 es = 2pECD (η) , + ϕ (x (η)) x (η) Gs (·) − ≈ 2 ϕ (x (η)) σ E σ 2E 2 where the last equality defines pECD (η). However, s is only decisive when D wins nationally and in state s, or R wins nationally and in state s. This happens about half of the times the margin of victory is less than es , so the probability that a state is Electoral College Decisive is approximately half the above expression. Second, given a national shock, η, the state outcome is a tie if Fs (−η s − η) = 12 which happens with likelihood gs (−µs − η) . Conditional on the national shock, the joint likelihood of being decisive and having a tied election is thus roughly pECD (η) gs (−µs − η), and the unconditional probability approximately Qs .21 21 A stricter, and longer, version of this argument can be made. Please contact the author for details. 30 To compare Qs with simulated frequencies of being EC decisive and having a state election margin of less than two percent, Qs must be scaled. The probability of a winning margin of less than x percent equals 1 1 x x − ≤ Fs (−η s − η) ≤ + . 2 200 2 200 The probability that the state-level shock falls in this region is approximately gs (−µs − η) σf s x . ϕ (0) 100 The unconditional probability of being pivotal and having a state-election margin of x percent is therefore approximately Qs σf s x . ϕ (0) 100 The scaled values of Qs are very similar to the simulated frequencies of the corresponding events. In 3.4 percent of the 1 million simulated elections, Florida was decisive in the Electoral College and had a state margin of victory of less than 2 percent. The scaled Qs for Florida was 3.5 percent. To get the probability that the state margin of σf s victory is within, say 1000, votes, Qs should be scaled by 1000 . Using this formula, vs ϕ(0) the probability of a state being decisive in the Electoral College, and at the same time having an election result with a state margin of victory less than 1000 was 0.00015 in Florida in the 2000 election. The probability that this would happen in any state was .0044. The probability of a victory margin of one vote in Florida is 0.15 per million, and the probability of this happening in any state is 4.4 per million. The state where one vote is most likely to be decisive is Delaware, where it is decisive .4 times in a million elections. It is important to understand how the scaling of Qs relates to its interpretation. 1 Qs = 0.02 µ ¶ ϕ (0) σf s . Qs 0.02 ϕ (0) σf s {z } | | {z } Pr(EC decisive and marginal voter density, margin of two percent) conditional on tied state election (8.4) or, similarly, µ ¶ ϕ (0) σf s 1 . Qs = vs Qs ϕ (0) vs σf s {z } | | {z } ”voting marginal voter density, power" conditional on tied state election (8.5) When all states are assumed to have the same variance of preferences σ f s (until Section 6), Qs is proportional to the probability of being EC decisive and having a state margin of victory of less than two percent. 31 tfi pfi .014273 .000531 -.027613 .101768 nytt Figure 8.1: To simplify the analytical form of Qsµ , do a first order Taylor expansion of theP mean of the expected number of electoral votes µ (η) around η = e η for which µ (e η ) = 12 s es , that is the value of the national shock which makes the expected outcome a draw. With this approximation µ (η) = X s es Gs (−µs − η) ≈ a= X s 1X es − a (η − e η) , 2 s es gs (−µs − e η) . Since the mean of the electoral votes, µ (η) , is much more sensitive to national shocks than is the variance σ E (η), the latter is assumed fixed X e2s Gs (−µs − e η ) (1 − Gs (−µs − e η )) . σ 2E (η) = σ 2E = s Then 1 ϕ σ E (η) µ1 P 2 −µ σ E (η) s es ¶ ¶ µ 1 η −e η ≈ . ϕ σE σ E /a This approximation is very good. Figure 8.1 shows the true, tfi, and the approximated functions, pfi. The values are calculated for an interval of four standard deviations centered around e η in the 2000 presidential election. We now have ¶ Z µ 1 η−e η gs (−µs − η) h (η) dη. Qsµ ≈ es ϕ σE σ E /a Integrating over η, Qsµ where ! à ω η 2 + (σ E /a)2 µ2s + σ 2 (e η + µs )2 1 σ 2s e ≈ es exp − 2π 2 σ 2s σ 2 + (σ E /a)2 σ 2 + (σ E /a)2 σ 2s 2 ω = µ 1 1 1 2 + 2 + 2 σs σ (σ E /a) 32 ¶−1 . (8.6) Qsµ is larger when e η is close to zero. This effects all states in the same way, but varies across elections. To clarify the differences between states with different µs , rewrite ! à ω 1 c + (µs − µ∗s )2 , Qsµ ≈ es exp − 2π 2 σ e2 where µ∗s = − and σ2 e η, σ 2 + (σ E /a)2 σ e2 = σ 2s + ³ 1 1 σ2 + 1 (σ E /a)2 Qsσ is calculated using numerical integration. ´. 8.3. Campaign advertisements This Appendix analyses the decision of presidential candidates to allocate advertisements across media markets. Two presidential candidates: R and D, select the number of ads, am , in each media market m and the number of visits ds in each state s, subject to M X m=1 pm aJm ≤ I a , S X s=1 22 dJs ≤ I, J = R, D. Media market m contains a mass vms of voters in state s. Voters reactions to campaign advertisements are captured by the increasing and concave function w(am ). A voter i in media market m in state s will vote for D if ¡ ¢ ¡ R¢ ¡ D¢ ¡ R¢ ∆uwms = u dD s − u ds + w am − w am ≥ Ri + η s + η. In each media market m in state s, the individual specific preferences for candidates, Ri , are distributed with cumulative density function Fs . The state and national-level popularity-swings are drawn from the same distributions as before. The share D votes in media market m in state s equals Fs (∆uwms − η s − η). D wins the state if X m vms Fs (∆uwms − η s − η) ≥ 22 vs . 2 For simplicity, it is assumed that both parties have the same resources for buying advertisements. The asymmetric equilibrium with unequal resources can be characterized, theoretically and empirically, given assumptions about w (a), the effectiveness of advertisements in changing votes. 33 Define the total (state and national) swing which causes a draw in the state: ¡ ¢ X ¡ ¢ vs η s dD , aD , dR , aR : vms Fs (∆uwms − η s dD , aD , dR , aR ) = . 2 m (8.7) D wins state s if η s + η ≤ η s (·) . Conditional on the aggregate shock η, and the strategies, dD , aD , dR , aR , this happens with probability ¡ ¡ ¢ ¢ Gs η s dD , aD , dR , aR − η . The function η s (·) now plays the same role as ∆us − µs in Section 2, see equation (2.2). The rest of the analysis is in that section, only exchanging η s (·) for ∆us − µs . The best reply functions of D is characterized by ∂η (·) (8.8) Qs s D = λD , ∂ds S X s=1 Qs ∂η s (·) = µD pm . ∂aD m (8.9) Similarly, the best reply function of R is characterized by equations (8.8) and (8.9), replacing superscripts D by R. Because of the fixed budget and time constraints, the allocations must be symmetric so that λD = λR = λ, and µD = µR = µ. Differentiating equation (8.7), and evaluating it in equilibrium yields ¡ D¢ ∂η s (·) 0 = u ds , ∂dD s vms 0 ¡ D ¢ ∂η s (·) = w am . ∂aD vs m ¢ ¡ Proposition 4. A pair of strategies for the parties dD , dR , aD , aR that constitute a NE in the game of maximizing the expected probability of winning the election must satisfy dD = dR = d∗ , and aD = aR = a∗ , and for all s and for some λ, µ > 0 Qs u0 (d∗s ) = λ, (8.10) Qm w0 (a∗m ) = µpm , (8.11) where Qm = S X Qs s=1 vms . vs Qm is the sum of the Qs of the states in the media market weighted by the share of the voting population of state s that lives in media market m. Last, assuming that votes per capita vms = ts nms is the same for all media markets within each state, Qm = S X s=1 34 Qs nms . ns 8.4. Direct presidential vote First, the approximate probability of winning the election is derived under DV . Conditional on η, the expected vote share of D in state s is Z µvs (∆us , η) = Fs (∆us − η − η s )gs (η s ) dη s ∆us − η − µs = Φ q , 2 2 σs + σf s and the expected national vote of D is µv (∆us , η) = X vs µvs (∆us , η) . s Again conditional on η, the variance in D’s votes in state s is, ¶ ¶2 Z µ µ ∆us − η − η s − µs 2 2 − µvs (∆us , η) gs (η s ) dη s , σ vs = vs Φ σf s and the variance in the national votes of D is X σ 2vs . σ 2v = s The approximate probability of D winning the election is ¶ Z µ1 P s vs − µv D 2 h (η) dη. P (∆us ) = 1 − Φ σv The equilibrium strategies of Proposition 3 depend crucially on ∂P D ∂P D ∂µv ∂P D ∂σ v DV = QDV = + = QDV s sµ + Qsσ , ∂∆us ∂µv ∂∆us ∂σ v ∂∆us where QDV sµ = v q s σ v σ 2s + σ 2f s QDV sσ = Z ϕ Z µ µ1 P 2 ∂ Φ ∂σ v s vs − µv σv µ1 P 2 s ¶ ∆us − µs − η ϕ q h (η) dη, σ 2s + σ 2f s vs − µv σv ¶¶ (8.12) ∂σ v h (η) dη. ∂∆us DV DV DV Empirically, QDV sµ À Qsσ , the size of Qsσ is negligible compared to Qsµ . DV The interpretation of Qsµ is QDV sµ = vs (pdf of tied election) E [fs | election tied] . 35 (8.13) This follows since, conditional on η, the expected marginal voter density in state s is Z ∞ 1 ∆us − µs − η fs (∆us − η − η s )gs (η s ) dη s = q ϕ q . −∞ σ 2s + σ 2f s σ 2s + σ 2f s The probability density function of a tied national election, conditional on η, is ¶ µ1 P 1 s vs − µv 2 , ϕ σv σv and the unconditional pdf of tied election = Z 1 ϕ σv µ1 P 2 s vs − µv σv ¶ h (η) dη. (8.14) Therefore, the marginal voter density, conditional on a tied election, is (8.15) E [fs | election tied] ³1P ´ v −µ s Z ϕ 2 sσv v ∆us − µs − η q 1 ϕ q = h (η) dη. R ³ 12 P s vs −µv ´ 2 + σ2 2 + σ2 σ σ ϕ h (η) dη s s fs fs σv Inserting equations (8.14) and (8.15) into equation (8.13) yields equation (8.12). To see the relationship to "voting power" note that the probability of a national election margin of x votes or less equals ¶ µ1 P ¶ Z µ1 P x x s vs + 2 − µv s vs − 2 − µv DV 2 2 px −Φ h (η) dη (8.16) = Φ σv σv ¶ µ1 P Z 1 s vs − µv 2 ≈ x h (η) dη. ϕ σv σv DV Voting power is by definition pDV ≈ pdf of tied 1 . By equations (8.14) and (8.16), p1 election, therefore equation (8.13) may be written QDV sµ ≈ vs ("voting power") E [fs | election tied] . (8.17) This is the equivalent to equation (8.5) under the Electoral College. Rents The response in re-election probability to a uniform fall in vote share support across states is proportional to average "voting power". To see this, first define ∆uFs as the change in voter utility in state s necessary to induce a one percent fall in support: ∂F (∆us ) F ∆us = 1, ∂∆us or equivalently, ∆uFs = 36 1 . fs Next, define the response in the probability of winning representing an equal fall in vote shares as ∂P D Qs ∂P D = ∆uFs = F ∂∆us ∂∆us fs Under EC, voting power equals Qs , vs fs (0) ≈ pEC 1 see equation (8.5). Average voting power therefore equals the per capita response in re-election probability to a uniform one percent fall in vote share support X vs s v pEC ≈ 1 1 X ∂P . v s ∂∆uFs Similarly, under DV QDV 1 X ∂P 1X s ≈ pDV = 1 , v s ∂∆uFs v s E [fs | national election tied] DV since QDV sµ À Qsσ , and using equation (8.17). It is reasonable that 1000 votes decide the election about 50 times more often under the Electoral College. To see this, note that the probability of 1000 votes in any state deciding the election under EC and DV is approximately X 1000 µ ϕ (0) ¶ EC , p1000 ≈ Qs / v σ s f s s and pDV 1000 ≈ X s QDV s 1000 X vs / E [fs | national election tied] , v v s where the latter equation was derived by inserting pDV 1000 /1000 instead of (pdf tied election) into equation (8.13), summing over s, and solving for pDV 1000 . Assume that the marginal 1 and voter density is the same fs = 1 and that all states are of equal size, then vvs = 50 pDV 1000 = 1 EC p . 50 1000 Since Qs /vs is not strongly correlated with vs , the actual relation is not far from this. 8.5. Data definitions and sources • Dmvote: state Democratic percentage of the two-party presidential vote. Source: 1940-1944, ICPSR Study 0019; 1948-1988, Campbell; 1992, 1996, Statistical Abstract of the United States 2000; 2000, Federal Election Commission, 2000 OFFICIAL PRESIDENTIAL GENERAL ELECTION RESULTS. • Electoral votes won (by state). Source: National Archives and Records Administration. 37 • National trial-heat poll results. Source: 1948-1996, Campbell (2000); 2000, Gallup. • Second quarter national economic growth, multiplied by 1 if Democratic incumbent president and -1 if Republican incumbent president. Source: August or September election year issue of the Survey of Current Business, U.S. Department of Commerce, Bureau of Economic Analysis. • Growth in personal state’s total personal income between the prior year’s fourth quarter and the first quarter of the election year, standardized across states in each year, multiplied by 1 if Democratic incumbent president and -1 if Republican incumbent president. Source: Survey of Current Business, U.S. Department of Commerce, Bureau of Economic Analysis. • Incumbent: 1 if incumbent president Democrat, -1 if incumbent president Republican. • Presinc: 1 if incumbent Democratic president seeking re-election, -1 if incumbent Republican president seeking re-election. • President’s home state: 1 if Democratic president home state, -1 if Republican (0.5 and -0.5 for large states (New York, Illinois, California). Source: Campbell 19481988; 1992-2000: Dave Leip’s Atlas of U.S. Presidential Elections. • Vice president’s home state: 1 if Democratic president home state, -1 if Republican (0.5 and -0.5 for large states (New York, Illinois, California). Source: Campbell 1948-1988; 1992-2000: Dave Leip’s Atlas of U.S. Presidential Elections. • Average ADA-scores: Average ADA-scores of state’s members in Congress year before election. Source: Tim Groseclose (http://faculty-gsb.stanford.edu/groseclose/homepage.htm). • Legis: Partisan division of the lower chamber of the state legislature after the previous midterm election. Index is Democratic share of state legislative seats above the 50% mark. Two states, Nebraska and Minnesota, held nonpartisan state legislative elections for all (Nebraska) or part (Minnesota of the period under study. In the case of Nebraska, the state legislative division was estimated based on the ranking of states of Wright, Erikson, and McIver’s state partisan rankings based on public opinion data. Using this index, Nebraska was assigned the mean partisan division of the state most similar to it on the public opinion index, the nearly equally Republican state of North Dakota. The partisan division of the Minnesota legislature in its nonpartisan years (before 1972) is coded as the mean of its partisan division once it reformed to partisan elections (62% Democratic). Washington D.C. was as having the same partisan division as Maryland. Source: 1948-1988, Campbell; 1992-2000, Statistical Abstract of the United States. • State-level opinion polls. Democratic share of two party vote. Source: Pre-election issues of the Hotline (www.nationaljournal.com). 38 • Regional dummy variables, see Campbell. • Participation rate: 1948-1988, Shachar and Nalebuff (1999), voting age population 1992-2000, and votes cast 2000, Federal Election Commission, votes cast 1992, 1996, Statistical Abstract of the United States. 39