Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
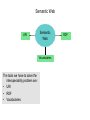
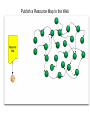
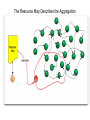
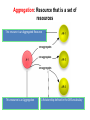
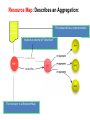
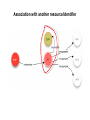
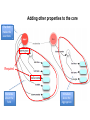
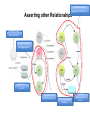
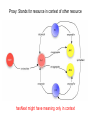
A Web-Based Resource Model for eScience: Object Reuse & Exchange 2008 Microsoft eScience Conference Indianapolis, December 8, 2008 OAI-ORE Editors • • • • • • Carl Lagoze o Cornell University Herbert Van de Sompel o Los Alamos National Laboratory Pete Johnston o Eduserv Foundation Michael Nelson o Old Dominion University Rob Sanderson o University of Liverpool Simeon Warner o Cornell University Joint work with … ORE Technica l Committee Chris Bizer Les Carr Tim DiLauro Leigh Dodds David Fulker Tony Hamm ond Pete Johnston Richard Jones Carl Lagoze Peter Murra y Michael Nelson Ray Plante Rob Sanderson Herbert Van de Sompel Sim eon Warner Jeff Young Freie UniversitŠt Berli n University of Sout hampton Johns Hopkins University Ingenta UCAR Nature Publi shing Group Eduser v Foundation HP Labs Cornell University OhioLINK Old Domi nion University NCSA and National Virtual Observatory University of Liverpool Los Alamos National Laboratory Cornell University OCLC ORE Liaison G roup Leonardo Candela Tim Cole Juli e Alli nson Jane Hunter Savas Parastatidis Sandy Payette Thomas Place Andy Powell Robert Tansley Consigli o Nazionale dell e Ricerche - DRIVER University of Illi nois Urbana-Champaign - Aquifer JISC University of Queensland - DEST Microsoft Corporation Fedora Comm ons University of Til burg - DARE Eduser v Foundation - DCMI Google, Inc. - DSpace OAI Object Reuse and Exchange: Support • • • • • The Andrew W. Mellon Foundation The Coalition for Networked Information Joint Information Systems Committee Microsoft Corporation The National Science Foundation OAI Object Reuse and Exchange Subject: Aggregations of Web resources Approach: Publish Resource Maps to the Web that Instantiate, Describe, and Identify Aggregations Aggregations Instantiate, Describe, and Identify Aggregations Aggregations At one time it was possible to convey all scientific information about a topic in a single “convenient” medium. Babylonian Astronomical Catalogue Aggregations But quickly the limitations of that medium became obvious. 1857 Astrophysics paper text data Aggregations Those limitations seem to live on. Aggregations “Solving” the problem with ad hoc methods. 1890 Astrophysics paper Photo plate kept separate from text (digitized version of original plate shown) text Aggregations 2006 Astrophysics paper Objects of interest in eScience are by nature compound. X-MM-Newton X-ray observation Vilspa, Spain Chandra X-ray observation Cambridge, MA A1795 Basic object information Strasbourg, France text Hubble optical observation Baltimore, MD Splash page Aggregations! Formats Relationships Identifiers Versions http://arxiv.org/abs/astro-ph/0611775 Object Reuse and Exchange: A Web-Centric Approach • • • • • The Web Architecture as the platform for interoperability De-facto integration with existing Web applications Potential of adoption by other communities Potential of tools created by other communities Incorporating the “social web” (Web 2.0) in eScience Foundations of OAI-ORE o o o o Web Architecture - <http://www.w3.org/TR/webarch/> Semantic Web, RDF - <http://www.w3.org/TR/rdf-primer/> Linked Data - <http://linkeddata.org/> - <http://www4.wiwiss.fu-berlin.de/bizer/pub/LinkedDataTutorial/> Cool URIs for the Semantic Web - <http://www.w3.org/TR/cooluris> W3C Web Architecture Representation 2 URI Represents Identifies Resource The tools we have to solve the interoperability problem are: • Resource • URI • Representation Content Negotiation Represents Representation 1 Semantic Web URI Semantic Web Vocabularies The tools we have to solve the interoperability problem are: • URI • RDF • Vocabularies RDF Linked Data • Linked Data principles: 1. Use URIs as names for things. 2. Use HTTP URIs so that people can look up those names. 3. When someone looks up a URI, provide useful information. 4. Include links to other URIs. So that they can discover more things. OAI Object Reuse and Exchange: The Approach Subject: Aggregations of Web resources Approach: Instantiate Aggregations as Resources with unique URIs on the Web Approach: Publish Resource Maps to the Web that Instantiate, Describe, and establish identity of Aggregations An Aggregation and the Web • Resources of an Aggregation are distinct URI-identified Web resources • Missing are: o The boundary that delineates the Aggregation in the Web o An identity (URI) for the Aggregation Publish a Resource Map to the Web The Resource Map Describes the Aggregation The Resource Map and the Aggregation integrate into the Web ORE Data Model ORE Data Model We want to have our cake and to eat it too (don't we all?): o o ORE should be simple and easy to use without deep understanding - Use simple tools and rules to create Atom Resource Maps ORE should have well crafted data model that enables interoperability through well defined semantics - Separate design from implementation - Future-proof ORE – today's technologies will be replaced (even HTTP?) - Don't need to understand Data Model fully to do ORE Aggregation: Resource that is a set of resources This resource is an Aggregated Resource This resource is an Aggregation A Relationship defined in the ORE vocabulary Resource Map: Describes an Aggregation: Resource Map Serialization The resource has a representation Implied as inverse of “describes” HTTP GET ore:isDescribedBy This resource is a Resource Map Recommend use if HTTP URIs • HTTP is technology of today's web • Want to be able to cite of refer to Aggregation but get Resource Map describing it o Follow Linked Data strategies to link: access URI-A, get redirected to URI-R (HTTP 303) or simple # URI o Provides notion of Authority Multiple Resource Maps o An Aggregation MAY be asserted and described by multiple Resource Maps o The purpose of multiple Resource Maps is to provide descriptions of the Aggregation in multiple serializations (e.g., Atom, RDF/XML, RDFa, etc.) o Each Resource Map MUST have only one representation Authority o o Authoritative Resource Maps o Get to Resource Map via Aggregation, usually created by same authority o Multiple: MUST be minimally equivalent (same Aggregated Resources and Proxies), SHOULD assert mutual existence Non-authoritative Resource Maps o Best practice is to not create them o Assert your own Aggregation instead o Use rdfs:seeAlso to assert relationship between two Aggregation Multiple Resource Maps RDF/XML ore:describes Atom Atom ore:describes RDFa These are non-authoritative Resource Maps These are authoritative Resource Maps Not much else Association with another resource/identifier Adding other properties to the core The ReM makes the assertions Required Metadata about the ReM Metadata about the Aggregation Assertions about Aggregated Resources. Asserting other Relationships The ReM makes the assertions Assertions about the Aggregation. Aggregation is a journal Aggregation has another version “A” “AR-3” is by Stephen Hawking Aggregated Resources are articles Limits of Assertions thus Far • The meaning of an RDF triple is independent of the context in which it is stated • Think of the difference: o Carl is a man o Carl is visiting Indianapolis • All the triples described thus far are context independent o Therefore they can have the URI of an aggregated resource as subject or object o But remember that is just the URI of the Resource and is not exclusive of it being an Aggregated Resource • Introduce proxy URI Proxy: Stands for resource in context of other resource hasNext might have meaning only in context lineage: “this came from” Reuse of data set AR-1 in Aggregation A-2. ore:lineage predicate expressed origin or provenance of data. Needs proxies because statement depends on contexts ORE Deployment arXiv.org: ORE possibilities arXiv is an e-print archive of 500k scholarly articles Express: • Structure of arXiv: archives, sub-categories, articles • Versioning: “article” (concept) and specific versions and formats • Articles by Joe Smith – somewhat like a result set • Constituents of an article (metadata, PDF, source, video, data, extracted references) • Describe internal and external components (e.g. external video associated with article but on Perimeter Institute server) • Use as part of workflow for ingest – assembly of components, possible combination with SWORD http://www.openarchives.org/oreChem/ SCOPE Architecture