Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
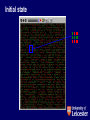
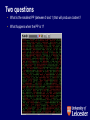
DEPARTMENT OF SOCIOLOGY Agent-Based Modelling and Microsimulation: Ne’er the Twain Shall Meet? Edmund Chattoe-Brown ([email protected]) http://www.le.ac.uk/sociology/staff/ecb18.html Introduction • Always a tricky business comparing approaches “in general terms”: Your mileage may vary as the Americans put it. • A number of concerns or questions based around a simple example of Agent-Based Modelling. Agent-Based Simulation • A very simple example: Not realistic but the point will quickly become clear. • Q: How do we explain urban residential segregation between ethnic groups? The Schelling model • Agents live on a square grid so each site has eight neighbour sites. • There are two “types” of agents (red and green) and some sites in the grid are unoccupied. Initially agents and empty sites are distributed randomly. • Each agent decides what to do in the same very simple way. • Each agent has a preferred proportion (PP) of neighbours of its own kind (0.5 PP means that you want at least half your neighbours to be your own kind. Fractions are used so empty sites “don’t count” for satisfaction.) • If an agent is in a position that satisfies its PP then it does nothing. • If it is in a position that does not satisfy its PP then it moves to an unoccupied position chosen at random. • Each time period is defined to allow each agent (chosen in random order) to “take a turn” at deciding and maybe moving. Initial state Two questions • What is the smallest PP (between 0 and 1) that will produce clusters? • What happens when the PP is 1? Two (surprising?) answers • PP about 0.3. People don’t have to be “xenophobic” to generate residential clusters. If you had seen the clusters in real data would you have “assumed” xenophobia? • As people get more “xenophobic”, clustering gets “stronger” (clusters get more separate and have less contact being “buffered” by empty sites) but at some point, the clusters break down and with PP=1, the system looks no different from the random starting position. Simple individuals but complex system Individual Desires and Collective Outcomes % Similar Achieved (Social) 120 100 80 60 % similar % unhappy 40 20 0 0 50 100 -20 % Similar Wanted (Individual) 150 What about data? • Individual data likely to be collected by qualitative methods (ethnography, interviews, perhaps experiments). This forms a testable set of hypotheses. • Aggregate data likely to be collected quantitatively (surveys, GIS). The simulated outcome of the individual actions is falsified against similarity between simulated and real data. Important aspects • No “fiddle factors” or “fitting”. • No theory constructs. • No “noise”. • Simulation generates not just residential clusters but other independent (?) patterns on which it may be falsified like move histories, behavioural clusters (on PP) and so on. • Unambiguously causal claims. Important cautions • Degrees of fit? • Not mistaking criticisms of the whole scientific approach for criticisms of specific methods: If each agent makes decisions in a unique way then not just all modelling but all social science must give up. Debate is about when (and to what extent) different patterns exist to be found. What about microsimulation? • Very broadly speaking, social science seems to divide into research on attributes (and their relations: age, gender) and research on practices (and their meanings). Microsimulation leans towards the attribute approach. • This can be seen not just in practices like reweighting and uprating but also in processes for “producing” data like matching/imputation. “Evidence” • Definition provided in Williamson Int. J. Microsim, 1(1), 2007, p. 1. • Worry: It isn’t the case that ABM and microsimulation will naturally “meet in the middle” because behaviours aren’t just another “attribute” like gender or age. (In fact, sociologists might argue that gender isn’t an attribute either but a negotiated achievement.) Avoiding missing the point • Beyond a certain point there is no point in trying to adjudicate definitively between different methods. At best one can: • Seek domains of application for different approaches. (Most current methods don’t do this, ABM included.) “Instructions on the can”. • Explore consequences of particular methods. • Recall constantly that each method is an “article of faith”. Concern 1: Explanation versus prediction • Prediction is problematic in social science because “pure” prediction may involve no generalisation. Without explanation we can’t tell. • Prediction gets limited credit when tuneable parameters exist. Has a system “tuned” to predict simply matched some output patterns without tapping into underlying behaviour? • ABM uses comparison (rather than straight prediction) as its test of explanation. Concern 2: Power and prediction • In simple statistical models, the power of a test is relatively well defined. • In complex microsimulation models, it isn’t clear if the quality of prediction relative to the quantity of data is impressive or inevitable given the number of degrees of freedom. • This would be a problem for ABM too except that predictive quality on a small number of “key” outputs isn’t the test of the model. Ideally, the simulated data should match all properties of the real data. Concern 3: Exogeneity • In econometrics, exogeneity is an empirically determined property of variable systems. • In ABM, the comparison requirement forces attention onto what can “legitimately” be treated as external to any given system. Getting it wrong means the model stops delivering effective comparisons. • Microsimulation appears to assume exogeneity, as when it treats a demographic process as a trend which will be “refitted” when ageing no longer works. Such beliefs are not falsifiable but may be harmful. Concern 4: Correlation and causation • Under what circumstances should we assume, for example, that missing data can be “filled in” on the basis of attribute patterns in existing data. It is done but can it be justified? If this (and other things like it) are done without justification, what do we do when prediction fails? • By comparison with ABM, to what extent are models calibrated (independent component measurement) rather than jointly fitted? Concern 5: Noise/randomness/error • The importance of distinguishing “behavioural” micro error (hand slipping) from “unmodelled” randomness. Again, econometrics specifies precisely the properties that noise/error terms must have. Such effects can’t just be “thrown in” like blur on an unflattering photograph. • Does too much randomness (of the “wrong” kind) allow one to predict anything? Concern 6: Linearity • As we can see from the Schelling example, even very simple systems can be non-linear. In these circumstances, there is a legitimate concern about “adding up” analyses of attributes which is broadly what microsimulation does. • Can we “split up” the whole cloth of social interaction along attribute lines and then expect the components to “add back up” to sensible outputs? Concern 7: Behaviour • Why “inherit” potentially problematic models, as from economics for example? • Sharper distinction needed between “accounting” microsimulation and “behavioural” microsimulation? In some sense AM is a “purely” technical challenge. Can behaviour be “bolted on” to a basically AM framework? (A revisit of the earlier worry about whether behaviour is “just another” attribute.) Drawing these concerns together • An individual based approach clearly ought to be better than a highly aggregated one (ABM and microsimulation agree on this). • BUT how do we make sure (using some combination of methodology and data) that complex individual level models don’t end up with too many degrees of freedom and pass the prediction test illegitimately? ABM is evolving ways to handle this issue. Is microsimulation? Constructive suggestion 1 • We can use ABM to discover “how often” it is safe to use what kinds of probabilistic models as “reductions” (Hendry) of a Data Generating Process. • Unfortunately, even with ABM much simpler than social behaviour is likely to be, the answer seems to be, not very often. Constructive suggestion 2 • There’s no reason, when “adding” behaviour to microsimulation, not to add “proper” ABM models. However, it is important to do this in a way that doesn’t destroy the social (rather than typically economic) assumptions built into them. Constructive suggestion 3 • Microsimulation takes data much more seriously than ABM does and this is admirable. • Serious attention must be given to getting “normal” ABM to track data, even approximately. • Unfortunately, this does reveal a lot we really don’t know. (Drunk and lamp-post story.) • As long as ABM isn’t bolted awkwardly onto microsimulation, it should be possible to get it to do the sorts of things that make microsimulation useful. (Politics!) Conclusions • The assumptions you don’t realise you are making are the ones that will do you in! • This discussion isn’t meant to imply that ABM has no faults, it has many (and not purely “technical” ones either) but that’s a different talk! Now read on? • Journal of Artificial Societies and Social Simulation (JASSS): • <http://jasss.soc.surrey.ac.uk/JASSS.html> • simsoc (email discussion group for the social simulation community): • <https://www.jiscmail.ac.uk/cgi-bin/webadmin?A0=SIMSOC> • Simulation for the Social Scientist, second edition, 2005, Gilbert and Troitzsch. • Simulation Innovation, A Node (Part of ESRC National Centre for Research Methods, conducting research, training and outreach in social simulation): • http://www.simian.ac.uk, http://www.ncrm.ac.uk • NetLogo (software used for these examples, free, works on Mac/PC/Unix and comes with standard library of example programmes): • <http://ccl.northwestern.edu/netlogo/> “Advertisement” • I’d like to take these ideas on in collaboration with a historian, with a view to funded research/a PhD award.