Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Mining the FIRST Astronomical Survey
Imola K. Fodor and Chandrika Kamath
Center for Applied Scientific Computing
Lawrence Livermore National Laboratory
IPAM Workshop
January, 2002
Faint Images of the Radio Sky at TwentyCentimeters (FIRST)
On-going sky survey, started in 1993
2
When completed, will cover more than 10,000 deg to a
flux density limit of 1.0 mJy (milli-Jansky)
Current coverage is about 8,000 deg 2
– more than 32,000 two-million pixel images
There are about 90 radio sources/deg2
Data available at http://sundog.stsci.edu
NRAO Very Large Array (VLA)
CASC
Sapphire/IKF 2
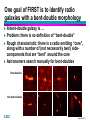
One goal of FIRST is to identify radio
galaxies with a bent-double morphology
A bent-double galaxy is …
Problem: there is no definition of “bent-double”
Rough characteristic: there is a radio emitting “core”,
along with a number of (not necessarily two!) sidecomponents that are “bent” around the core
Astronomers search manually for bent-doubles
Bent-doubles
Non bent-doubles
CASC
Sapphire/IKF 3
Sapphire: use data mining to enhance the
visual search for bent-doubles
Use galaxies classified by astronomers to model the
binary response variable Y
Y {bent, non bent}
Find features X and model f(X) with desired accuracy
?X & ? f : f ( X ) Yˆ Y
Aim: 10% misclassification error, as manual
classification is not more accurate
FIRST
images
Pre-processing
Denoising
Feature extraction
Dimension reduction
CASC
“Good”
features
Pattern recognition
Bent/nonbent
coordinates
Classification
Sapphire/IKF 4
The FIRST catalog is based on fitting 2D
elliptical Gaussians to denoised images
Image Map
1150
pixels
Catalog
720K entries
1550 pixels
32K image maps, 7.1MB each
Catalog entry
(CE)
Radio source
(RS)
CASC
64 pixels
RA
DEC
Peak Flux Major Axis Minor Axis Position Angle
(mJy/bm) (arcsec)
(arcsec)
(degrees)
00 56 25
-01 15 43
25.38
7.39
2.23
37.9
00 56 26
-01 15 57
5.50
18.30
14.29
94.2
00 56 24
-01 16 31
6.44
19.34
10.19
39.8
Sapphire/IKF 5
A first pre-processing step is to identify
potential features to discriminate bents
For the FIRST data, we extracted various features
based on
– radio intensities, angles, distances, …
For galaxies with 3 entries
– a total of 103 features
– three sets of single features, three pairs of
double features, and the triple features
– possible redundancies
Reduce dimension using
– domain knowledge
– EDA
– PCA
– GLM step-wise model selection
CASC
Sapphire/IKF 6
Triple features for three catalog entries
P
M
A
N
c
B
b
a
C
CASC
Sapphire/IKF 7
Using exploratory data analysis (EDA),
we reduced the number of features to 25
Use EDA techniques such as
– box-plots
– multivariate plots
– parallel-coordinate plots
– correlation matrix
to
– explore the data
– find unusual observations
– eliminate correlations among the features
Call these EDA features
CASC
Sapphire/IKF 8
Example parallel coordinate plot: nine
variables split by bentness category
x
3/2 sky regions for
bent/non-bent
x
x
x
x
X : unusual
large negative
correlation
CASC
Bent
Non-bent
Sapphire/IKF 9
Principal component analysis (PCA) finds
linear combinations of variables
Suppose we have p features
X ( X , ..., X )' , E[X] 0, E[XX' ] Ψ,
and we want a linear combination U with max. variance
U a' X, a , a' a 1.
By the spectral decomposition theorem,
Ψ V Λ V', V ( V , ..., V ), orthogonal, Λ diag ( ,..., ),
the first PC, U V X, has maximal variance, and
var(U ) var( V1' X ) ... var(U p ) var(Vp' X ) p .
The total variance is preserved,
1
p
p
pxp
1
p
1
p
'
1
1
1
1
var( X ) var(U ).
2
total
p
i 1
p
i
i 1
i
Dimension reduction: use first k PCs as new “features”
CASC
Sapphire/IKF 10
We used PCA differently to reduce the
number of original features to 20
The first 20 PCs explain 90% of the variance
PCs are hard to interpret – instead of using 20 PCs,
keep 20 of the original variables
Multivariate Analysis (Mardia, Kent, Bibby)
– consider the last PC, with the smallest variance
p
'
U p Vp X i1Vi , p X i
– find the largest (in abs value) coefficient V j , p , and
discard the corresponding original variable X j
– repeat the procedure w/ the second-to-last PC,
and iterate until only 20 variables remain
Call these PCA features
CASC
Sapphire/IKF 11
We also used step-wise model selection
to reduce the number of variables
Binary response: Y = {bent, non-bent}
Explanatory variables: X i features
Logistic regression, step-wise model selection with
the AIC as a measure of goodness (minimize -loglikelihood, with a penalty term for large models)
Cannot use all 103 features because of correlations
We identified the features selected by EDA or PCA
– stepwise model selection => GLM 2 features (25)
We identified the features selected by EDA and PCA
– stepwise model selection => GLM 3 features (10)
– stepwise model selection, including second-order
interactions => GLM 4 features (9, +5 interactions)
CASC
Sapphire/IKF 12
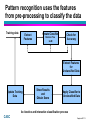
Pattern recognition uses the features
from pre-processing to classify the data
Training data
Extract
Features
Create Classifier
Decision Tree
GLM
Check for
Accuracy
Extract Features
for
Unclassified Data
Update Training
Data
Show Results
and
Obtain Score
Apply Classifier to
Unclassified Data
An iterative and interactive classification process
CASC
Sapphire/IKF 13
We use decision trees to classify the radio
sources into bents and non-bents
Use information gain to split
T : set of n examples at a node
k : number of classes
S {TL , TR }: split T into two
Li , Ri : number of class i in TL , TR
radius > a?
color?
color?
k
Entropy(T ) i1 pi log pi ,
pi ( Li Ri ) / n
| TL |
| TR |
Gain(T , S ) Entropy(T )
Entropy(TL )
Entropy(TR )
|T |
|T |
CASC
2
Sapphire/IKF 14
Decision tree created with all the
features: Tree 1
Leaf node w/ 11 non-bents
Leaf node w/ 4 bents
Leaf node w/ 145 items,
(145-4) bents, and
4 non-bents
Resubstitution error, train/test (90%) set: 2.8%
Cross-validation error, train/validate (10%) set: 5.3%
CASC
Sapphire/IKF 15
Decision tree created with the EDA and
PCA features: Tree 2
Resubstitution error: 1.7%
Cross-validation error: 5.3%
CASC
Sapphire/IKF 16
Decision tree created with the GLM 3
features: Tree 3
Resubstitution error: 2.8%
Cross-validation error: 0%
Using fewer, well-selected variables results in smaller
and more accurate trees
CASC
Sapphire/IKF 17
We also used generalized linear models
(GLMs) to classify the galaxies
Linear models explain response variables in terms of
linear combinations of explanatory variables
Y Xβ ε, E (ε ) 0, Cov(ε ) Σ
yi 0 1 X i ,1 p1 X i , p1 X iβ, E ( yi ) i , i 1,..., n
Least-squares estimate β̂ solves
βˆ arg min {( y Xβ)' Σ ( y Xβ)}
ˆ Xβˆ
No restrictions on the range of fitted values Y
GLMs allow such restrictions by modeling
g (i ) Xiβ, Var( yi ) V (i ),
where g() is a monotone increasing link function
1
CASC
Sapphire/IKF 18
Logistic regression is a special GLM
suitable for modeling binary responses
Y={0,1}
Logit link and variance functions
i
g ( i ) log(
)
1 i
V ( i ) i (1 i )
Likelihood non-linear in parameters, no closed-form
solution: iteratively reweighted least squares to find β̂
Given β̂ ,
exp{ X iβˆ }
ˆ i
, yˆ i I{ˆ p} ,
ˆ
i
1 exp{ X iβ}
where I{a} is {0,1} according to {a=False, a=True}, and
the fraction p is generally taken to be 0.5
CASC
Sapphire/IKF 19
GLM created with the GLM 2 features
CASC
Sapphire/IKF 20
GLM created with the GLM 3 features
CASC
Sapphire/IKF 21
GLM created with the GLM 4 features
CASC
Sapphire/IKF 22
Misclassification errors of best models
are below the desired 10% in training set
Careful selection of variables reduces error
Trees are less sensitive to input features than GLMs
GLM 4 has lowest misclassification errors
Tree 1
Tree 2
Tree 3
Mean
11.1%
9.5%
8.3%
SE
0.4%
0.4%
0.4%
GLM 2
GLM 3 GLM 4
Mean
18.74% 7.84%
4.00%
SE
4.34%
1.14%
0.91%
Misclassification errors based on 10 ten-fold cross-validations in the training set
CASC
Sapphire/IKF 23
Our methods identified the “interesting”
part of the FIRST dataset
15,059 three-entry radio sources in the 2000 catalog
2,577 labeled as bent by all six methods
Astronomers can start by exploring the smaller set
Tree1
Non-bent 5412
Bent
9647
Tree2
Tree3
GLM2
GLM3
GLM4
All 6
4628
5660
5118
11080
4340
637
10431
9399
9941
3979
10719
2577
Classification results for the entire 2000 catalog
Visually explore random samples to assess the
percentage of false positives and missed bents
CASC
Sapphire/IKF 24
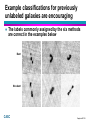
Example classifications for previously
unlabeled galaxies are encouraging
The labels commonly assigned by the six methods
are correct in the examples below
Bent
Non-bent
CASC
Sapphire/IKF 25
Summary
Described how data mining can help identify radio
galaxies with bent-double morphology
Illustrated specific data mining steps
– data pre-processing is very crucial
In our experience, data mining is semi-automatic
– interaction and feedback required at many stages
– domain knowledge is essential
Multi-disciplinary collaboration is challenging, but
rewarding
– astronomy - computer science - statistics
There is always room for improvement
– alternative techniques
– your feedback welcome!
CASC
Sapphire/IKF 26
The Sapphire team: supporting a multidisciplinary endeavor
Chandrika Kamath (Project Lead)
Erick Cantú-Paz
Imola K. Fodor
Nu A. Tang
www.llnl.gov/casc/sapphire
Thanks to the FIRST scientists: Robert Becker,
Michael Gregg, David Helfand, Sally LaurentMuehleisen, and Rick White
UCRL-JC-145672. This work was performed under the auspices of the U.S. Department of Energy by
University of California Lawrence Livermore National Laboratory under contract W-7405-Eng-48.
CASC
Sapphire/IKF 27