Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
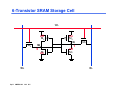
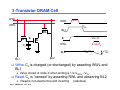
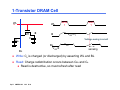
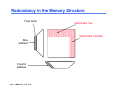
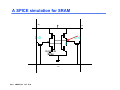
CMPEN 411 VLSI Digital Circuits Spring 2011 Lecture 23: Memory Cell Designs SRAM, DRAM [Adapted from Rabaey’s Digital Integrated Circuits, Second Edition, ©2003 J. Rabaey, A. Chandrakasan, B. Nikolic] Sp11 CMPEN 411 L23 S.1 Heads-up IBM Kerry Bernstein’s talk Thursday 4 PM, IST 333 To make up last cancelled lecture: To prepare for his talk, go to ANGEL system, find the file “New dimensions in performance”, under “interesting reading materials” Kerry Bernstein’s talk – “Microarchitecture’s Race for Performance and Power”, PSU talk, 11/2004, Slides and Videos are online in ANGEL system “Interesting Reading Materials” DAC Young Student Scholarship www.dac.com Sp11 CMPEN 411 L23 S.2 Review: Basic Building Blocks Datapath Execution units - Adder, multiplier, divider, shifter, etc. Control Finite state machines (PLA, ROM, random logic) Interconnect Register file and pipeline registers Multiplexers, decoders Switches, arbiters, buses Memory ROM, Caches (SRAMs), CAM, DRAMs, buffers Sp11 CMPEN 411 L23 S.3 2D 4x4 SRAM Memory Bank read precharge enable bit line precharge WL[0] !BL BL A1 WL[1] A2 WL[2] WL[3] 2 bit words clocking and control A0 Column Decoder sense amplifiers BLi Sp11 CMPEN 411 L23 S.4 BLi+1 write circuitry 6-Transistor SRAM Storage Cell WL off M2 on M4 Q M5 !BL Sp11 CMPEN 411 L23 S.5 1 !Q 0 M6 M1 on off M3 BL SRAM Cell Analysis (Read) WL=1 M4 M5 !Q=0 Q=1 M6 M1 Cbit Cbit !BL=2.5V → 0 BL=2.5V Read-disturb (read-upset): must limit the voltage rise on !Q to prevent read-upsets from occurring while simultaneously maintaining acceptable circuit speed and area M1 must be stronger than M5 when storing a 1 (as shown) M3 must be stronger than M6 when storing a 0 Sp11 CMPEN 411 L23 S.6 Read Voltage Ratios where CR is the Cell Ratio = (W1/L1)/(W5/L5) VDD = 2.5V VTn = 0.4V 1.2 Keep cell size minimal while maintaining read stability 1 0.8 Make M1 minimum size and increase the L of M5 (to make it weaker) 0.6 - increases load on WL V o ltag e R ise o n !Q ≥ 1.2 0.4 0.2 0 0 0.5 1 1.5 Cell Ratio (CR) Sp11 CMPEN 411 L23 S.7 2 2.5 3 Make M5 minimum size and increase the W of M1 (to make it stronger) Similar constraints on (W3/L3)/(W6/L6) when storing a 0 SRAM Cell Analysis (Write) WL=1 M4 M5 !Q=0 M1 Q=1 →0 M6 Cbit Cbit !BL=2.5V BL=0V The !Q side of the cell cannot be pulled high enough to ensure writing of 0 (because M1 is on and sized to protect against read upset). So, the new value of the cell has to be written through M6. M6 must be able to overpower M4 when storing a 1 and writing a 0 M5 must be able to overpower M2 when storing a 0 and writing a 1 Sp11 CMPEN 411 L23 S.8 Write Voltage Ratios where PR is the Pull-up Ratio = (W4/L4)/(W6/L6) ≤ 1.8 VDD = 2.5V |VTp| = 0.4V µp/µn = 0.5 0.5 Keep cell size minimal while allowing writes W rite V o ltag e (V Q ) 0.4 0.3 0.2 0.1 0 0 0.5 1 Pullup Ratio (PR) Sp11 CMPEN 411 L23 S.9 1.5 2 Make M4 and M6 minimum size Cell Sizing and Performance Keeping cell size minimal is critical for large SRAMs Minimum sized pull down fets (M1 and M3) - Requires longer than minimum channel length, L, pass transistors (M5 and M6) to ensure proper CR - But up-sizing L of the pass transistors increases capacitive load on the word lines and limits the current discharged on the bit lines both of which can adversely affect the speed of the read cycle Minimum width and length pass transistors - Boost the width of the pull downs (M1 and M3) - Reduces the loading on the word lines and increases the storage capacitance in the cell – both are good! – but cell size may be slightly larger Performance is determined by the read operation To accelerate the read time, SRAMs use sense amplifiers (so that the bit line doesn’t have to make a full swing) Sp11 CMPEN 411 L23 S.10 6-T SRAM Layout VDD M2 M4 M1 M3 GND M5 BL Sp11 CMPEN 411 L23 S.11 M6 BL WL signal routing and connections to two bit lines, a word line, and both supply rails Area is dominated by the wiring and contacts Other alternatives to the 6-T cell include the resistive load 4-T cell and the TFT cell neither of which are available in a standard CMOS logic process Q Q Simple and reliable, but big Multiple Read/Write Port Storage Cell WL2 WL1 M2 M5 M4 !Q Q M7 M8 M1 !BL2 !BL1 M6 M3 BL1 BL2 To avoid read upset, the widths of M1 and M3 will have to be sized up by a factor equal to the number of simultaneously open read ports Sp11 CMPEN 411 L23 S.12 Resistance-load SRAM Cell WL V DD RL M3 BL Sp11 CMPEN 411 L23 S.13 RL Q Q M1 M2 M4 BL Remove R WL M3 BL Sp11 CMPEN 411 L23 S.14 M4 M1 M2 BL Remove R WL M3 M4 M2 Further remove one transistor Sp11 CMPEN 411 L23 S.15 3-Transistor DRAM Cell WWL WWL RWL VDD BL1 M3 M1 X M2 Cs X VDD-VT RWL read BL2 ∆V Write: Cs is charged (or discharged) by asserting WWL and BL1 VDD-VT BL2 BL1 write Value stored at node X when writing a 1 is VWWL - VTn Read: Cs is “sensed” by asserting RWL and observing BL2 Read is non-destructive and inverting Sp11 CMPEN 411 L23 S.16 (ratioless) 3-Transistor DRAM Cell WWL WWL RWL VDD BL1 M3 M1 X M2 Cs X VDD-VT RWL read BL2 BL1 write VDD-VT BL2 Refresh: read stored data, put its inverse on BL1 and assert WWL (need to do this every 1 to 4 msec) Note Vt drop at x: how to fix it? Sp11 CMPEN 411 L23 S.17 ∆V 3-T DRAM Layout BL2 BL1 Fewer contacts & wires Total cell area is 576 λ2 (compared to 1,092 λ2 for the 6-T SRAM cell) No special processing steps are needed (so compatible with logic CMOS process) Can use bootstrapping (raise VWWL to a value higher than VDD) to eliminate threshold drop when storing a “1” GND RWL M3 M2 WWL M1 Sp11 CMPEN 411 L23 S.18 1-Transistor DRAM Cell WL WL M1 CBL X X write 1 read 1 VDD-VT Cs BL Voltage swing is small BL VDD/2 VDD sensing Write: Cs is charged (or discharged) by asserting WL and BL Read: Charge redistribution occurs between CBL and Cs Read is destructive, so must refresh after read Sp11 CMPEN 411 L23 S.19 Sense Amp Operation V BL V(1) V PRE V(0) Sense amp activated Word line activated Sp11 CMPEN 411 L23 S.20 t 1-T DRAM Cell Observations Cell is single ended (complicates the design of the sense amp) Cell requires a sense amp for each bit line due to charge redistribution based read BL’s precharged to VDD/2 (not VDD as with SRAM design) all previous designs used SAs for speed, not functionality Cell read is destructive; refresh must follow to restore data Cell requires an extra capacitor (CS) that must be explicitly included in the design May not compatible with logic CMOS process A threshold voltage is lost when writing a 1 (can be circumvented by bootstrapping the word lines to a higher value than VDD) Sp11 CMPEN 411 L23 S.21 1-T DRAM (3-D capacitor) Non-CMOS Sp11 CMPEN 411 L23 S.22 Source: IBM Peripheral Memory Circuitry Row and column decoders Read bit line precharge logic Speed Power consumption Area – pitch matching Sense amplifiers Timing and control Sp11 CMPEN 411 L23 S.23 2D 4x4 __RAM Memory read precharge enable bit line precharge WL[0] !BL BL A1 WL[1] A2 WL[2] WL[3] 2 bit words clocking and control A0 Column Decoder sense amplifiers BLi Sp11 CMPEN 411 L23 S.24 BLi+1 write circuitry 2D 4x4 ___RAM Memory read precharge enable bit line precharge WL[0] BL A1 WL[1] A2 WL[2] WL[3] 2 bit words sense amplifiers clocking, control, and refresh BL0 A0 Sp11 CMPEN 411 L23 S.25 BL1 BL2 Column Decoder BL3 write circuitry Row Decoders Collection of 2M complex logic gates organized in a regular, dense fashion (N)AND decoder for 8 address bits WL(0) = !A7 & !A6 & !A5 & !A4 & !A3 & !A2 & !A1 & !A0 R WL(255) = A7 & A6 & A5 & A4 & A3 & A2 & A1 & A0 NOR decoder for 8 address bits WL(0) = !(A7 | A6 | A5 | A4 | A3 | A2 | A1 | A0) R WL(255) = !(!A7 | !A6 | !A5 | !A4 | !A3 | !A2 | !A1 | !A0) Goals: Pitch matched, fast, low power Sp11 CMPEN 411 L23 S.26 Dynamic Decoders Precharge devices GND VDD GND WL 3 VDD WL3 WL2 WL 2 VDD WL1 WL 1 V DD WL0 WL 0 VDD φ A0 A0 A1 A1 2-input NOR decoder A0 A0 A1 A1 φ 2-input NAND decoder Which one is faster? Smaller? Low power? Sp11 CMPEN 411 L23 S.27 Pass Transistor Based Column Decoder A1 A0 2 input NOR decoder BL3 !BL3 BL2 !BL2 S3 S2 S1 S0 data_out BL1 !BL1 BL0 !BL0 !data_out Read: connect BLs to the Sense Amps (SA) drive one of the BLs low to write a 0 into the cell Writes: Fast since there is only one transistor in the signal path. However, there is a large transistor count ( (K+1)2K + 2 x 2K) For K = 2 → 3 x 22 (decoder) + 2 x 22 (PTs) = 12 + 8 = 20 Sp11 CMPEN 411 L23 S.28 Tree Based Column Decoder BL3 !BL3 BL2 !BL2 BL1 !BL1 data_out !data_out BL0 !BL0 A0 !A0 A1 !A1 Number of transistors = (2 x 2 x (2K -1)) for K = 2 → 2 x 2 x (22 – 1) = 4 x 3 = 12 Delay increases quadratically with the number of sections (K) (so prohibitive for large decoders) can fix with buffers, progressive sizing, combination of tree and pass transistor approaches Sp11 CMPEN 411 L23 S.29 Bit Line Precharge Logic First step of a Read cycle is to precharge (PC) the bit lines to VDD every differential signal in the memory must be equalized to the same voltage level before Read Turn off PC and enable the WL !PC the grounded PMOS load limits the bit line swing (speeding up the next precharge cycle) Sp11 CMPEN 411 L23 S.30 BL !BL equalization transistor - speeds up equalization of the two bit lines by allowing the capacitance and pull-up device of the nondischarged bit line to assist in precharging the discharged line Sense Amplifiers Amplification – resolves data with small bit line swings (in some DRAMs required for proper functionality) SA input output Delay reduction – compensates for the limited drive capability of the memory cell to accelerate BL transition small tp = ( C * ∆V ) / Iav large make ∆ V as small as possible Power reduction – eliminates a large part of the power dissipation due to charging and discharging bit lines Signal restoration – for DRAMs, need to drive the bit lines full swing after sensing (read) to do data refresh Sp11 CMPEN 411 L23 S.31 Differential Sense Amplifier VDD M3 M4 y M1 bit SE M2 Out bit M5 Directly applicable to SRAMs Sp11 CMPEN 411 L23 S.32 Differential Sensing ― SRAM V DD PC V DD BL BL EQ V DD y M3 WL i M1 x SE V DD M4 M2 2y 2x 2x x SE M5 SE SRAM cell i Diff. x Sense 2x Amp V DD Output y SE Output (a) SRAM sensing scheme Sp11 CMPEN 411 L23 S.33 (b) two stage differential amplifier Reliability and Yield Memories operate under low signal-to-noise conditions word line to bit line coupling can vary substantially over the memory array - folded bit line architecture (routing BL and !BL next to each other ensures a closer match between parasitics and bit line capacitances) interwire bit line to bit line coupling - transposed (or twisted) bit line architecture (turn the noise into a common-mode signal for the SA) suffer from low yield due to high density and structural defects leakage (in DRAMs) requiring refresh operation increase yield by using error correction (e.g., parity bits) and redundancy and are susceptible to soft errors due to alpha particles and cosmic rays Sp11 CMPEN 411 L23 S.34 Redundancy in the Memory Structure Fuse bank Redundant row Redundant columns Row address Column address Sp11 CMPEN 411 L23 S.35 Row Redundancy Fused Repair Addresses == ? Redundant Wordline == ? Redundant Wordline Enable Normal Wordline Decoder Normal Wordline Normal Wordline Decoder Normal Wordline Functional Address Enable Fused Repair Addresses Page 4 Sp11 CMPEN 411 L23 S.36 == ? Redundant Wordline == ? Redundant Wordline Data 0 Page 5 Sp11 CMPEN 411 L23 S.37 Data 1 Data 2 Data 3 Data 4 Data 5 Fuse Fuse Fuse Fuse Fuse Fuse Fuse Fuse Data 6 Redundant Data Column Normal Data Column Normal Data Column Normal Data Column Normal Data Column Normal Data Column Normal Data Column Normal Data Column Normal Data Column Column Redundancy Data 7 Error-Correcting Codes Example: Hamming Codes e.g. If B3 flips 1 1 =3 0 2K>= m+k+1. m # data bit, k # check bit For 64 data bits, needs 7 check bits Sp11 CMPEN 411 L23 S.38 Performance and area overhead for ECC Sp11 CMPEN 411 L23 S.39 Redundancy and Error Correction Sp11 CMPEN 411 L23 S.40 Soft Errors Nonrecurrent and nonpermanent errors from alpha particles (from the packaging materials) neutrons from cosmic rays System FITS As feature size decreases, the charge stored at each node decreases (due to a lower node capacitance and lower VDD) and thus Qcritical (the charge necessary to cause a bit flip) decreases leading to an increase in the soft error rate (SER) Sp11 CMPEN 411 L23 S.41 From Semico Research Corp. 10000 1000 100 10 1 0.25 0.18 0.13 0.09 0.05 Process Technology From Actel MTBF (hours) .13 µm .09 µ m Ground-based 895 448 Civilian Avionics System 324 162 Military Avionics System 18 9 Scary Fact Avionics system in civilian aviation: altitude of 30,000 feet on a route crossing the north pole both cause increase in neutron flux. If avionics board uses four 1M 130nm SRAM-based FPGAs, it would be subject to 0.074 upsets per day = 324 hours between upsets or 3million FITs. Assume one such system on-board each commercial aircraft, 4,000 civilian flights per day, 3 hours average flight time. Nearly 37 aircraft will experience a neutron-induced SRAM-based FPGA configuration failure during the duration of their flight. Sp11 CMPEN 411 L23 S.42 Modeling of a particle strike Sp11 CMPEN 411 L23 S.43 A SPICE simulation for SRAM !BL BL 1->0 0->1 0 A particle strike WL Sp11 CMPEN 411 L23 S.44 On-chip Memory: ITRS roadmap Area Reused Logic Area New Logic Area Memory % Die utilization 100 80 60 40 20 Sp11 CMPEN 411 L23 S.45 14 11 35 nm /' /' 50 nm 08 m 70 n 10 0 nm /' /' 05 02 /' 0n m 13 18 0n m /' 99 0 State of Art Sp11 CMPEN 411 L23 S.46 State of Art Sp11 CMPEN 411 L23 S.47