Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
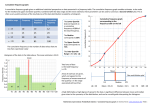
Notes Organizing and Describing Data Univariate Data Bivariate/Multivariate Data Qualitative Data (Categorical) Quantitative Data (Numerical) 2 types of Quantitative Data 1. Discrete – 2. Continuous – Frequency vs. Relative Frequency Types of Displays See other handout: Bar Graphs, Pie Charts, Dotplots, Stemplots, Histograms, Time Plots, Boxplots, Scatterplots, Ogives Describing the overall pattern of a distribution 1. Center 2. Unusual Features 3. Shape 4. Spread Dotplots A dotplot is created by using a portion of a horizontal real number line (WELL LABELLED) – no vertical axis Each data value is represented in the graph by a single dot above the line at its value If the same value appears more than once, the dots should be stacked such that stacks with the same number of “dots” are the same height Dotplots work best for small discrete data sets with a moderately small spread. Example: Test Scores 95, 96, 90, 95, 88, 95, 97, 89, 92, 95, 94, 94, 96, 95, 94, 93, 94 Stemplots Also called a stem-and-leaf plot Formed by separating each data value into two parts: one called the stem and the other, the leaf. Stems may consist of more than one digit while leaves always consist of a single digit. The leaf is always the last place value digit used from the original data (data is sometimes rounded to minimize the number of stems). To construct a stemplot, the stems (and any “missing” values in the interval of the stems) are arranged vertically, with the smallest stem at the top and the largest at the bottom. Leaves are placed to the right of the corresponding stem: they should be arranged in order from smallest to largest with no commas between leaves. Generally, you want to have between 5 and 10 stems (including stems with no leaves). If you have too many, you can round your data to shorten the number of stems; too few, you can “split” your stems (will see in example…). Stems should always be split so that they each hold an equal range of values [i.e. if one stem holds GPAs of 3.0 to 3.3 (4 possible values), you can’t have another stem holding GPAs of 3.4 to 3.6 (3 possible values)]. You must also be sure to include a “legend” with your stemplot which indicates what your original values looked like (ex. where 6 | 2 represents 62 inches). Like all other graphical displays, be sure to give your overall graph a descriptive title. Example: Scores on a Psychological Test 154, 109, 137, 115, 152, 140, 154, 178, 200, 103, 126, 126, 137, 165, 165, 129, 200, 148 Histograms A histogram strongly resembles a bar graph, with important differences. Important terminology involving histograms: Class: An interval containing data observations. Each observation from the data set must fall in one and only one class. Class boundaries: Endpoints or limits for each class – defined to one additional decimal place than the largest number of decimal places in the data set. Class width: Distance between the class boundaries of a class. Frequency of a class: The number of values from a data set that fall within a specific class. The sum of the frequencies of all the classes should equal the number of values in the original data set. Relative Frequency of a class: Equals the class frequency for that class divided by the number of values in the data set. Shows the proportion of the whole data set contained within the class. Cumulative Frequency: The sum of the frequencies for the current class and all preceding classes. Cumulative Relative Frequency: The sum of the relative frequencies for the current class and all preceding classes. To create a histogram: 1. Identify the smallest value in the data set (Xmin) and largest value in the data set (Xmax). You may wish to round data values what aren’t whole numbers. 2. Determine the number of classes you will use for your histogram. The rule of thumb we will use to find the desired number of classes is as follows: The number of classes (k) to be used in constructing a histogram for sample data is the smallest integer value of k such that 2k n, where n is the size of the data set. For example, n k 8 or less 3 9 – 16 4 17 – 32 5 33 – 64 6 3. Decide on class endpoints so that each class has the same width and every observation can be classified uniquely in exactly one class. An appropriate class width can be found using the formula: X max X min Class width = k This value is bumped-up (not rounded!) to the next integer value. This value is how wide each class (bar) is. 4. Create a frequency table: First column – class limits Second column – class boundaries, which are expanded class limits, so the bars touch. Third column –frequency Fourth column – relative frequencies Fifth column – cumulative frequency Sixth column – cumulative relative frequency 5. To actually create the histogram, do the following – (a) On the x-axis, use class boundaries. Start at the left edge of the graph, even if the left side of your class is negative. (b) On the y-axis, mark either frequencies or relative frequencies, depending on what the problems asks you to do. (c) Label both axes and title your graph!This is one of the most important aspects of graphing data. (d) Draw your classes (bars), based on the frequencies or relative frequencies obtained in the frequency table.Since your data is univariate (one category), the classes should touch. On a categorical graph, bars are separate because the categories aren’t the same. Creating a Frequency Table and a Histogram One way Commuting Distances in Miles for 60 workers in Downtown Dallas 13 7 12 6 34 14 47 25 45 2 13 26 10 8 1 14 41 10 3 21 8 13 28 24 16 19 4 7 36 37 20 15 16 15 17 31 17 3 11 46 24 8 40 17 18 12 27 16 4 14 23 9 29 12 2 6 12 18 9 16 Number of Classes: __________________ Width of class limits: Max - Min Number of classes (then bump up!) ________________ Create a Frequency Distribution for the above: Class Limits Class Boundaries Frequency Draw the histogram and then CUSS and BS it! Relative Frequency Cumulative Frequency Cumulative Relative Freq. Ogives The last two columns on the frequency table deal with what is happening on a cumulative basis. Either one of the last two columns can be used to make an ogive (although cumulative relative frequency proves to be more useful). Class boundaries are placed on the horizontal axis in the same manner as with a histogram, while either cumulative or (most likely) cumulative relative frequencies are placed on the vertical axis. Points are graphed above the upper class boundariesand are then connected with line segments. Points/lines are used to show how much of the total data set has been “accumulated” at the end of each class. Note: When cumulative relative frequencies are used to create an ogive, the ogive can quickly provide accurate estimates of a percentile values, which is the data value at which that percent of values occurs before the stated value. Quartiles are located every 25% of the data. The first quartile (Q1) is the 25thpercentile, the second quartile (Q2 or Median) is the 50th percentile while the third quartile (Q3) is the 75th percentile. Interquartile range (IQR) is found by subtracting Q1 from Q3. IQR = Q3 – Q1. Ex. Draw an ogive of One way Commuting Distances in Miles for 60 workers in Downtown Dallas. Use the ogive to estimate the middle of the data set. The following cumulative relative frequency plot shows the time (in minutes) that it took students to finish quiz 1. 2) How much time did it take the fastest 15% to finish their quiz? 3) How long did the slowest person take? 4) What percent of the students were finished after 15 minutes? 5) How many people were finished at the 22 minute mark? Cumulative relative frequency 1) What is the median time it took to complete quiz 1? 1 .9 .8 .7 .6 .5 .4 .3 .2 .1 5 10 15 20 25 Minutes 30 35 40 Measures of Center Mean Median Mode Resistance 1. Traumatic knee dislocation often requires surgery to repair ruptured ligaments. One measure of recovery is range of motion (measured by the angle formed when, starting with the leg straight, the knee is bent as far as possible). The article “Reconstruction of the Anterior and Posterior Cruciate Ligaments after Knee Dislocation” reported the following post surgical range of motion for a sample of 13 patients. 154 135 142 108 137 120 133 127 122 134 126 122 135 Find the mean, median and mode. 2. The paper “The Pedaling Technique of Elite Endurance Cyclists” reported the accompanying data on singleleg power at a high workload. 244 205 191 211 160 183 187 211 180 180 176 194 174 200 Find the mean, median and mode. Suppose the first observation had been 204, not 244. How would the mean and median change? Which measure would you say is nonresistant to outliers? Calculate a trimmed mean by eliminating the smallest and largest sample observations. 3. The results of an AP Biology Leaf Disk Lab are recorded in the table below Back to back, split-stem stemplot Making a boxplot Summarize Describe each distribution and compare Boxplots 5 number summary IQR Outliers Boxplot vs. Modified Boxplot Consumer Reports did a study of ice cream bars in their August 1989 issue. Twenty-seven bars having a taste-test rating of at least “fair” were listed, and calories per bar was included. Calories vary quite a bit partly because bars are not of uniform size. Just how many calories should an ice cream bar contain? 342 439 A) B) 377 111 319 201 353 182 295 197 234 209 294 147 286 190 377 151 Determine a 5-number summary for calories. Check for outliers. Construct a boxplot for these data. Describe the distribution. 182 131 310 151 Measures of Spread Range Variance Standard Deviation Variance and Standard Deviation In the Consumer’s Report April 2007 issue, the following gas mileage was reported in mixed driving for the following five brands of Subaru: Subaru B9 Tribeca 16 mpg Subaru Forester 22 mpg Subaru Impreza 23 mpg Subaru Legacy 18 mpg Subaru Outback 19 mpg Find the mean and median. Find the variance and standard deviation. Observations: xi variance: standard deviation: Deviations: xi x s2 b 1 xi x n 1 g 2 b Squared deviations xi x g 2 The following is a list of the number of calories for the 5 top rated brands of hotdogs (Consumers Report July 2007). Calculate the mean, variance and standard deviation. 150 170 120 120 90 Write the letter of the histogram next to the appropriate variable number in the table below. Explain briefly how you made your choice. Variable Mean Median St.Dev. 1 50 50 10 2 50 50 15 3 53 50 10 4 53 50 20 5 47 50 10 6 50 50 5 Consider the hypothetical exam scores presented below for three classes of students. Dotplots of the distributions are also presented. Do these dotplots reveal differences among the three distributions of exam scores? Explain briefly. Calculate the 5-number summaries of the three distributions. Create the modified boxplots of the three distributions. If you had not seen the actual data and had only been shown the boxplots, would you have been able to detect the differences in the three distributions? Describe what feature is difficult to determine from a boxplot. Match the following histograms to their corresponding boxplot. Editors of an Entertainment Weekly publication ranked every episode of Star Trek: The Next Generation from best (rank 1) to worst (rank 178), as shown in the table, separated according to the season of the show’s sevenyear run in which the episode aired. Overall, which season was the best? (careful!!!!!) Justify your choice. Which season was the worst? Justify your choice. The top 25% of which season was the highest ranked? Which two seasons seem to have the widest spread? Which season has the shortest interquartile range? List the top 3 seasons (from best to worst) based on their third quartiles. The bottom 50% of which two seasons has practically the same spread? Which season had the most episodes? Comparing distributions Side by side bar graphs Back to back stemplots Parallel Boxplots Teacher salaries in Katy ISD range from $45,000 to $70,000. If the board decides to increase all salaries by $1,000 for next year, how will that affect the mean and the median? The range and the standard deviation? Instead the board decides to go with a 3% increase. How will that affect the mean and median? The range and standard deviation? Effects of linear transformations Adding a constant value Multiplying by a constant Maria measures the lengths of 5 cockroaches that she finds at school. Here are her results (in inches): 1.4 2.2 1.1 1.6 1.2 a) Find the mean, median, range and standard deviation of Maria’s measurements b) Maria’s science teacher is furious to discover that she has measured the cockroach lengths in inches rather than centimeters. (There are 2.54 cm in 1 inch.) She gives Maria two minutes to report the mean and standard deviation of the 5 cockroaches in centimeters. Maria succeeded. Will you?