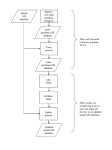
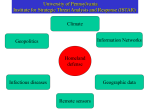
Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
INCO-CT2006-032539 CAMINAR Catchment Management and Mining Impacts in Arid and Semi-Arid South America Instrument: Specific Targeted Research Project Thematic Priority: A.2.3 Managing arid and semi-arid ecosystems Deliverable D7 GIS environment database and report Due date of deliverable: Month 12 Actual submission date: Month 14 Start date of project: 1 February 2007 Duration: 36 months Organisation name of lead contractor for this deliverable: Instituto Superior Técnico - IST (final) Project co-funded by the European Commission within the Sixth Framework Programme (2002-2006) Dissemination Level PU PP RE CO Public Restricted to other programme participants (including the Commission Services) Restricted to a group specified by the consortium (including the Commission Services) Confidential, only for members of the consortium (including the Commission Services) X European Commission Sixth Framework Programme Specific International Scientific Cooperation Activities (INCO) Activity Area: A. Developing countries A2. RATIONAL USE OF NATURAL RESOURCES A.2.3. Managing arid and semi-arid ecosystems Specific Targeted Research or Innovation Project CAMINAR Contract No. INCO-CT2006-032539 Catchment Management and Mining Impacts in Arid and Semi-Arid South America D7 GIS environment database and report January 2008 Authors: Luis Ribeiro, Ana Buxo Instituto Superior Técnico - IST Lisbon, Portugal IST – Instituto Superior Técnico – Avenida Rovisco Pais, 1049-001 Lisboa, Portugal – www.ist.utl.pt [email protected]; [email protected] GIS environment database and report EXECUTIVE SUMMARY The focus of the CAMINAR project is the sustainable use of water resources and the associated ecosystems under a specific context, where ecological, climatic, social and economic factors have to be accounted for. This implicates an increased complexity and quantity of information necessary for the water management process. The growth and advances of information technologies and databases have provided the ability to access and effectively manage large volumes of information, thus increasing the quality of managerial decision-support. To assure that the decision making process is practical, usable and reliable, it is necessary that the whole data set concerning each basin, may they be about ecology, topography, climate or social-economic factors, can be analysed together. The use of Geographic Information Systems and relational Database Management System adds value to the original data sets, by migrating and converting them into a normalized database that can simultaneously accommodate both geographic and alphanumeric data. This process enhances data quality through the application of validation procedures that detect and correct inconsistencies, on individual elements or entire data sets, and by imposing a framework for structuring the information, according to pre-defined topologic/geometric and alphanumeric criteria. Consequently, in this first year of the CAMINAR project, the activities of Workpackage 6 Decision Support Tools were focused on the development of a spatial database that integrates both geographic and non-geographical data. The present version of the GIS environment database is the cumulated work of the teams from Workpackages 2-4, responsible for the data collection, and of the team from Workpackage 6 responsible for the definition and implementation of the necessary procedures to generate a database to support decision making more effectively. Many types of information were collected by teams from South America, generating a very significant volume of files and paper documents, which could be potentially used. This data was then analysed, revised, processed and integrated into the database, using the productivity and analytical tools of Geographic Information Systems. By the end of the first year of the project, structured data repository has been created, with the necessary quality and quantity of data required to proceed to the following stage, were this data can be used to feed specialized modelling and hydrological analysis tools. This spatial database is more easily managed than the scattered original data sets and can be easily used to promote continuous updates and upgrades of the information, thus improving the decision process by the use of the most actual and reliable information. Also, the use of standard formats and systems allows this data repository to interact with a variety of other applications, namely hydrologic and hydraulic modelling packages, such as the various possibilities that will be tested and evaluated during the second year of the CAMINAR project. Finally, but not less important, the work has been developed taking into consideration the necessary transfer of this database, and the facts that are behind it, to the final users. Therefore, standard formats, public domain data models and well documented procedures have been used, aiming to generate reproducible results. i GIS environment database and report Index EXECUTIVE SUMMARY.......................................................................................................I INDEX ...................................................................................................................................... II ACRONYMS AND ABBREVIATIONS ..............................................................................III LIST OF FIGURES ...............................................................................................................IV LIST OF TABLES .................................................................................................................VI LIST OF ANNEXES ............................................................................................................ VII 1 2 INTRODUCTION............................................................................................................. 1 1.1 Objectives .................................................................................................................... 1 1.2 Geographic Information Systems versus Decision Support Systems.......................... 1 DECISION SUPPORT TOOLS....................................................................................... 4 2.1 Building the database................................................................................................... 4 2.1.1 Data Collection ........................................................................................................ 4 2.1.2 Data modelling......................................................................................................... 7 2.1.3 The ArcHydro data model ..................................................................................... 10 2.1.4 Data processing...................................................................................................... 14 2.1.5 Database implementation....................................................................................... 27 3 CONCLUSIONS ............................................................................................................. 41 4 REFERENCES................................................................................................................ 42 ANNEX I – Data Collection Guidelines ..………………………………………………… 44 ANNEX II – Basic Archydro Data Model Framework………………………………….. 56 ii GIS environment database and report Acronyms and Abbreviations DBMS DEM DSS GIS ODBC OLE RDBMS SDSS TIN WP Database Management System Digital Elevation Model Decision Support System Geographic Information System Open Database Connectivity Object Linking and Embedding Relational Database Management System Spatial Decision Support System Triangular Irregular Network Workpackage iii GIS environment database and report List of figures Figure 1: Conceptual SDSS for watershed management and evaluation of environmental impacts from mines ...............................................................................................2 Figure 2: View of the metadatabase form for file retrieval...............................................6 Figure 3: Example of data retrieval using the metadatabase: queries for all documents and files related to a chosen category....................................................................7 Figure 4: Data Model Based on Inventory ......................................................................10 Figure 5: Integrating Data Inventory using a Behavioural Model ..................................11 Figure 6: Components of the ArcHydro data model. ......................................................13 Figure 7: Geodatabase view of ArcHydro data model....................................................13 Figure 8: Example of Bolivia, Lake Poopó: data processing of hydrography data. .......18 Figure 9: Example of Peru / Chili basin: The original river cartography base. ..............19 Figure 10: Example of the original river’s cartography for the Chili River, before processing. ...........................................................................................................19 Figure 11: Example of the original river’s cartography for the Chili River, after processing. ...........................................................................................................20 Figure 12: Examples of some of the files and tables containing data for time series integration............................................................................................................22 Figure 13: Example of the aspect of formatted time series table in ArcHydro data model22 Figure 14: Aspect of the official website of the GLCN Land Cover Topic Centre, and the software available to assist in classification and normalization of land cover themes..................................................................................................................24 Figure 15: Example of cross-population: layer “Superficies_riego_elqui231205” and layer “Panos_cultivados_elqui” contained different types of information about the same feature (land parcels) ............................................................................26 Figure 16: The resulting layer contains the aggregated data from both data sources. ....26 Figure 17: Digital elevation model generated for the Elqui basin, with overlaying river network ................................................................................................................30 Figure 18: Derived DEM information for Elqui river basin: slope grid (left) and aspect grid (right). ..........................................................................................................31 Figure 19: Digital elevation model generated for the Chili river basin, with overlaying river network .......................................................................................................32 Figure 20: Derived DEM information for Chili river basin: slope grid (left) and aspect grid (right). ..........................................................................................................32 Figure 21: Base data: contour lines for the Lake Poopó area and overlaying hydrographic network..........................................................................................33 Figure 22: Surface Reconditioning by the AGREE method (Hellweger, 1997).............34 Figure 23: Comparison of the flow accumulation grid and the river network for the Chili river basin (Peru) .................................................................................................35 iv GIS environment database and report Figure 24: Comparison of the flow accumulation grid and the river network for the Elqui river basin (Chile) ......................................................................................35 Figure 25: Catchment areas and watershed areas for the Chile river basin (Peru). ........36 Figure 26: Catchment areas and watershed areas for the Elqui river basin (Chile). .......36 Figure 27: Examples of network analyses: selecting lines upstream or downstream of a certain point. ........................................................................................................38 Figure 28: Connecting MonitoringPoints to the river network. ......................................40 Figure 29: Geodatabase view of the connection between river network, monitoring station and temporal data.....................................................................................40 v GIS environment database and report List of tables Table 1: General data collection statistics.........................................................................5 Table 2: Data collection statistics: types of formats in which original data was received15 Table 3: Coordinates systems identified in the original layers and used in the final database for each basin........................................................................................17 Table 4: Chile – Elqui River DEM statistics...................................................................30 Table 5: Peru – Chili River DEM statistics.....................................................................31 Table 6: River network statistics for the three basin areas.............................................. 38 vi GIS environment database and report List of annexes Annex I Data collection guidelines Annex II Basic ArcHydro data model framework vii GIS environment database and report 1 1.1 INTRODUCTION Objectives The objective of Workpackage 6 (WP6) in the CAMINAR project is the development of decision support tools to support participatory water management planning in 3 demonstration river-basins: Chili River, in Peru, Elqui River, in Chile and Lake Poopó in Bolivia. During this first year of project CAMINAR, main activities related to the “River-basin case studies data collection” task, for the three study areas. It involved the completion of the following objectives: o Development of a consistent format for lead partners of WP2-4 to use to pass hydrological, sediment transport and hydrochemical data from three demonstration river basins o Reception, quality-checking and database entry of data provided by lead partners of WP2-4, and presentation in a GIS environment. o Obtain and process relevant remote sensing data for study river-basin (directly and/or from partners as appropriate) and manipulate onto same GIS platform. 1.2 Geographic Information Systems versus Decision Support Systems Traditionally geographic information was managed by cartographic systems, that later developed into Geographic Information Systems (GIS). A GIS differs from a mapping or cartographic software, as it will have a database of geographic data, allowing linkages between different types of data and the ability to query this spatial data. Also, alphanumeric attributes can be handled easily using an integrated database management system (DBMS). An increasing number of examples indicate that an integrated decision making process can provide the ability of delivering more realistic approaches in arid zone ecosystems management. This is achieved by the use of assessment tools that can examine the consequences of alternative management. Systems such as DSS (Decision Support Systems) focus on specific decisions and on supporting rather than replacing the user's decision making processes. Definitions of DSS emphasise the need to support semi-structured and unstructured decisions. Many widely accepted definitions of Decision Support Systems (DSS) identify the need for a combination of a database, an interface and a model component directed at a specific problem. In terms of these definitions, a GIS would not be regarded as a DSS as it lacks support for the use of specific models. However, there are today many techniques allowing data to be shared and/or transferred between computer applications. The growth and advances of information technologies and databases have provided the ability to access and effectively manage large volumes of information, thus increasing the quality of managerial decision-support. As in so many other problems dealt with by DSS, and in particularly in those related to natural resources, water management is dependent on information that has a spatial component. Events do not occur in an independent way of their geographic location and the concepts of vicinity, proximity and connectivity are inherent to the understanding of the hydrologic system. Based on these aspects and since the dependency 1 GIS environment database and report of such a system on geographic data is of such dimension, we can refer to such as system as a Spatial Decision Support System (SDSS). In a SDSS, the GIS component is employed as a basic conceptual framework for the representation of the territorial domain, as well as interface with end-users. In some areas where specific modelling and simulation are needed to fully support the decision, the use of GIS can make use of techniques for interaction between software packages such as object linking and embedding (OLE), dynamic data exchange, and open database connectivity (ODBC), acting as the basic medium for sharing data between applications or modules. In such work environment, GIS and DSS definition converge, as we can find that in both cases the interface, the database and model components required to fully support decisions, are present. To assure that the decision making process is practical, usable and reliable, it is necessary that the whole data set concerning each basin, may they be about ecology, topography, climate or social-economic factors, can be analysed together. The use of GIS and relational DBMS adds value to the original data sets, by migrating and converting them into a normalized database that can simultaneously accommodate both geographic and alphanumeric data. This process enhances data quality through the application of validation procedures that detect and correct inconsistencies, on individual elements or entire data sets, and by imposing a framework for structuring the information, according to pre-defined topologic/geometric and alphanumeric criteria. Presently, as the cost of technology decreases and the field of applications for GIS spreads, many of the management science models used are being incorporated into the GIS environment. Data Collection MODELS Surface Water GIS Groundwater Database: Spatial and non-Spatial Information Water Quality Analysis and data access tools for pre and post processing Data management Risks appraisal Vulnerability Alternatives analysis User Interface Maps Reports Graphics Statistics Tables Scenarios Decision making Figure 1: Conceptual SDSS for watershed management and evaluation of environmental impacts from mines Geographic information systems are capable of integrating geographical data with other data from various sources to provide the necessary information for effective decision making in a watershed management system. 2 GIS environment database and report Typically a GIS system serves both as a tool box and as a database. As a tool box, GIS allows planners to perform spatial analysis using its geoprocessing or cartographic functions such as data retrieval, map overlay and connectivity. Decision makers can also extract data from the GIS’s database and input it to other modelling and analysis programs, together with data from other databases or specially conducted surveys. An example of the use of such GIS capabilities for hydrologic analysis would be a set of GIS tools, capable to manage and analyse vector or raster based data sets, in order to determine hydrologic elements and connectivity, to perform calculations of drainage parameters and prepare the input files for modelling/simulation applications. These tools allow automated model setup significantly faster, leading to reproducible results. Another important aspect in the use of GIS as a DSS generator is related to the data acquisition process. It is of major importance in developing DSS projects, the impact of the data. The quality of the decision making process depends on the availability and reliability of information. Decisions based on the DSS are as good and reliable as the data stored in the system’s database. In this sense, the traditional role of GIS as a tool for speeding up data acquisition process and the processing of spatial data is also of great importance. GIS was initially used as a mean for the completion of activities which contributed directly to productivity, dealing with the greater complexity of spatial information, with resourceconsuming procedures and validation and error checking automation. Normally, one of the main obstacles to the development of successful and usable DSS, as well as GIS, is the access to data in such formats that can be combined in an integrated database. But there are other constraints beyond the availability of pertinent data. These projects have been hindered by difficulties such as the cost of accessing such data, the complicate technical procedures necessary to process geographic information and the large volume of data that imply significant employment of time and human resources. 3 GIS environment database and report 2 DECISION SUPPORT TOOLS Building decision tools for watershed data management requires a repository of valid, reliable data that can be used to assist in the decision process. Our focus is therefore on enhancing the population of DSS with reliable ecological, environmental, climatic or socio-technical information. As in many similar situations, a DSS (or a spatial DSS) does not start from scratch. We benefit from being able to access some data sets or being able to establish contacts and partnerships, with a variety of local data providers, using the expertise and previous work done by the teams from WP2-4. However this data is dispersed and it is stored in repositories of several entities, in many different formats, with distinct requisites and technical specification. To being able to develop a DSS, we have to build a consistent, integrated data repository. Due to the previous evaluation of the variability of formats, the volume of data and the geographic and non-geographic nature of it, it was considered that GIS applications associated with relational data management systems, would be the most convenient tools for manipulation of this data sets, as they simplifies and aid in productive generation of structured information. 2.1 Building the database 2.1.1 Data Collection The initial work of WP6 was to define some lines of development and procedures related to the data collection task. The objective was to specify some criteria for the data collection that could be used by teams from WP2-4 in their participation on this task. In view of this objective, a document named “Data Collection Guideline” (see Annex 1), was produced and sent to every one of the three teams from South America. This document defined some of the tasks to be preformed, such as identifying possible data sources, as well as capacitating the teams in doing some pre-analysis of the data. The purpose was that, before being sent to WP6, there could be some type of pre-screening of the files and paper documents, which could detect more obvious problems. Examples of this pre-analysis could be the detection of problems of informatics nature (e.g. files that could not be opened). Also, it was asked if some type of additional information required for GIS integration could be added (e.g. projection systems, classification systems, topologic aspects, unique ID or specific user codes for cross-data analysis, etc.). 4 GIS environment database and report Teams from WP2-4 have done an extensive data compilation, from different sources, internal and external to their work groups. It includes pre-existing GIS layers in several formats, reports and articles, raw data in tables or lists, satellite images, photographs and general data, both in paper and digital media. Files and other documents were then sent to team from WP6, for evaluation and database integration. To facilitate the data transference, different platforms were made available, depending on the choice of each team, the technological capabilities locally installed and the nature of the data involved. Data can be sent by courier, using CD-ROM or DVD media, as well as e-mail, FTP or directly delivered to the team of WP6 during its visits to the project’s locations on South America. From all the platforms available, the FTP as proven to be the most effective and faster, as long as each team has access to the internet, and a sufficient band width, enabling to transfer data packages as they becomes available. In some circumstances, large volumes of information can be sent, making response time very fast. Also, in some occasions, FTP was used as a communication tools, in situations such as when the help of local teams was important in the evaluation, completion or validation of certain data sets, since it can de used in both directions (send and receive) by teams from WP2-4 and WP6. In the future FTP will have an increasing importance in the development of the database, since it can be used to sent to the teams of WP2-4 revised database versions and updates, for their use, analysis, validation and completion, resulting in a interactive process of data refinement and allowing to adjust the final product to the requirement of the potential final users. As a result of such work, a significantly large volume of data was gathered. By the end of January, 2008 the following volumes of information were received: ≈ 3.2 Gbytes of information 4 543 files or documents delivered 760 geographic layers or themes 27 different formats ≈ 18 000 Km2 Basin area for Bolivia (Lake Poopó) Basin area for Chile (Elqui river + ≈ 10 096 Km2 Quebrada Chacay + Pan de Azúcar) 2 ≈ 14 475 Km Basin area for Peru (Chili river + Colca) Table 1: General data collection statistics Each file received is catalogued in a metadatabase. The metadatabase contains information about the data. Each file or paper document received is classified according to attributes such as: 5 GIS environment database and report o o o o o o o o o Basin / case study Data of reception, Media of delivery (FTP, CD, E-Mail, etc) Name Location on the computer Type Format Category and general description and/or observation Figure 2: View of the metadatabase form for file retrieval. The generation of such a database was necessary due to volume of files and documents involved. The objectives of this metadatabase were in first place to keep track of all the information received and rapidly accessing it. It as also proven to be an efficient method of internally manage the flux of information, since it allows for potential users of such files and document to find all the elements related to a certain subject or basin. 6 GIS environment database and report Figure 3: Example of data retrieval using the metadatabase: queries for all documents and files related to a chosen category. Furthermore, it is used as one of the method applied for data completion and validation, by the cross analysis of documents and files related to the same theme. If more than one data source for a certain theme can be can be compared, it is possible to detect inconsistencies in the data or in other cases, by cross-populating of the datasets, more rich information is obtained. 2.1.2 Data modelling Data modelling is the process by which a standard architecture for the project’s database is defined and thus used to organize, manage and access information. Basic goals of data modelling are: o Simplifying the process of projects implementation. Database model is a complex technique and one which has a significant impact on the success of the project’s implementation and adherence to the objectives. Major risks in developing data models are oversimplification that could truncate futures analytical capabilities required by the system, and over complexity that can direct the project to dead-ends and never-ending tasks, loosing track of the real purpose. This occurs because the data model must take into account all the phases of development of the database: the nature of the problem, the industries or scientific disciplines involved, the type and formats of data available, the data acquisition and integration processes, as well as the end-users interface with the information and the generations of final products (maps, reports or statistics). 7 GIS environment database and report This means that data modelling some time occurs before many of the necessary information is yet available and many aspects still remained to be specified, namely by the end-users. In these sense, previous experience in similar project becomes a significant plus, as it allows for a faster project’s development by the existence of a starting point. o Promote and support standards to bring consistency and synergy between similar systems More and more, GIS and spatial databases are used by projects and organizations as a corporative system. This means that the information served by the spatial database is used transversally inside organizations, by different groups of users, with various interests but that share the same data. This also means that the information gathered in the spatial database is not only used inside the graphical and cartographical environment of the GIS, but also by other applications and software. To do so, more standard and formal data modelling is required, since each system or application needs to recognize the data contained in the database management system, and needs to know what each attribute, each value, each classification system means, in order to adapted it to its own specifications. However, the choice of a data model should not be such that it won’t allow the integration of case-specific design situations. Therefore it needs to be extensible, flexible, and adaptable to the user requirements o To facilitate the transmission of both knowledge and technology, by the use of well documented processes. The development of systems such as GIS or DSS has to deal with the existence of different modules and components (database, models and interface), the large volume of data processed and the distinct profiles of potential users involved. The successful use of the end-products depends also on the capacity of describing and justifying its production process and the technological and/or data constraints associated with its development. This means, that when the system is finally concluded, all process, procedures, and requirements have to be documented. This is an important step since these documents will be the bases for end-users to understand its content, how it works, what are the limitations, how it can be expanded, what functionalities are available, etc. 8 GIS environment database and report The generation of a spatial database according to a well defined, standard data model, allows for a more extensive and clear documentation. Another important aspect of the documentation process is giving the final users the knowledge that will allow them to reproduce the process, if necessary, by identifying the main steps and by clearly describing the why and how of each procedure. Taking into to account all these items, it was decided to use a pre-defined, third-party data model named ArcHydro. This data model was jointly developed by the Centre for Research in Water Resources of the University of Texas at Austin, and ESRI (Environmental Systems Research Institute, Inc.). It was designed taking into account the different needs of several types of potential users dealing with surface and groundwater issues, from scientists dealing with natural resources to engineers as well as planners and managers. ArcHydro is a geospatial and temporal data model developed for the analysis and management of water resources. It consists of two sub-models, one for surface water and another for groundwater, allowing for integrated analysis of many subjects related to hydrology. In the development of ArcHydro, the question regarding the integration between a spatial database and hydrologic simulation models was considered in a very efficient way. ArcHydro is not in it self a simulation model but has associated with the model, a set of tools that allow for the definition of the framework of generic elements (hydrofeatures), the way features from different data layers interconnect as well as tools for populating the database with the parameters used by a significant number of hydrologic models. ArcHydro represents a basic data model that, if necessary, can be modified, by adding other data layers, new attributes to the existing features, more complex relations between elements, new rules or domains to the behaviour of elements, in order to adjust it to particular projects or applications. One of the reasons for this choice was the fact that ArcHydro is already a standard, uniform data model with an extensive base of users, allowing it to be repeatedly tested, corrected and improved over time. A large number of articles, books and internet sites, have abundant information about the concepts, the templates, the implementation procedures and examples of applications that can help end-users understand the principles behind its use. There are also some discussion groups and forums which users can consult to solve particular questions regarding their individual project, sharing their experience and knowledge with an enlarged base of experienced users. In addition, there is a clear tendency to transform the GIS work environment into a formal DSS, by the direct integration of analysis tools and simulation model into the GIS interface. 9 GIS environment database and report Pairing with this tendency, some broadly used hydrologic model are using ArcHydro data model as their data models and for others, pre-processors that link these external application to the ArcHydro model already exist and are freely available. 2.1.3 The ArcHydro data model Traditionally, data model design used in GIS was, as what it can described, an inventory data model. This consisted on a set or a list of geographic layers, each representing a specific theme and group of elements. Each data layer was then stored in individual files or set of files, that existed by itself. In these type of data model, the relations between individual elements or distinct layers are only deduced by the analysis that the user makes of the data, since the user can observe the geographic relations, the proximity, the vicinity and through the use of basic GIS operations such as unions, intersections, buffering, can identify and quantify these relations. Point of interest in the hydrographic system Line features in the hydrographic system Surface features in the hydrographic system Makes an inventory of all features of a given type in the region Pump Dam What is it? Where is it? Bridge Figure 4: Data Model Based on Inventory However, our perception of a natural hydrologic system is quiet different. The elements that we can recognize are connected and we can even describe the relations between them. Thus our perception is more like a model based on behaviour: a drop of rain that falls at a certain location will go downhill through the line of major slope, into a nearby stream that by its turn is connected no the next reach downstream and so one, until it reaches the sea. ArcHydro uses then an approach were the inventory data model is integrated using a behavioural model. 10 GIS environment database and report Relationships between objects linked by tracing path of water movement Figure 5: Integrating Data Inventory using a Behavioural Model In this case, the data model will not only store the data layers but also the relations between the elements (that represent the movement of a drop of water) and defined rules. To do so, it uses the advantages of a special spatial data structure in Relational Database Management Systems (an RDBMS-based GIS System): the geodatabase model. Conceptually, it is a combination of GIS objects enhanced with the capabilities of a relational database to allow for relationships, topologies, and geometric networks to be stored in the same place. ArcHydro data model is then a geodatabase data model. Geodatabase is an object-oriented data model that allows both physical objects and behaviours to be stored in the same scheme. o A geodatabase can define general and arbitrary relationships between objects and features; o A geodatabase can enforce the integrity of attributes through domains and validation rules; o A geodatabase can present multiple versions so that many users can edit the same data; o A geodatabase can model topologically complex sets of features such as networks. A geodatabase stores both geographic objects and non-geographic data in a commercial relational database: 11 GIS environment database and report o A uniform repository of data where all of geographic and non-geographic data can be stored and centrally managed in one database file; o This means that we can use the advantage of improved performance of spatial analysis by use of topological rules as well as all the advantage of data management, retrieving and analysis associated with relational databases; o Many application need to extract information from the spatial database but not to display or geographically process the data. Since geodatabases are implemented using standard DBMS these applications can access the data using standard languages, protocols or technologies. From the hydrologic point of view, the ArcHydro data model divides water resources into five different components. Each component is organized in the geodatabase as a feature data set, meaning a group of interdependent geographic layers. The five components of the complete ArcHydro data model are: o Hydrography It is the base data from topographic maps and tabular data inventories. It includes layers such as monitoring stations, structures of relevant impact in the hydrologic system (dams, bridges, water discharge points, etc.) and well as other elements that are relevant to the complete description of water related features; o Drainage It includes features like drainage areas (such as catchments or watersheds), outlet points and stream lines. These features describe the process by which water moves from the point where it falls onto the landscape down to a stream, then to a river and finally to the sea; o Network Network is a set of lines and relevant points that define the path of water flow; o Channel A set of lines, transverse or parallel to the river network that defines the river shape; o Time series Set of tabular data that describe the temporal variation of certain water property related with a hydrofeature. The description of each of these components, from the geodatabase point of view is presented in Annex II. 12 GIS environment database and report Drainage Network Flow Time Series hydrofeatures Time Channel Hydrography Figure 6: Components of the ArcHydro data model. Figure 7: Geodatabase view of ArcHydro data model 13 GIS environment database and report 2.1.4 Data processing Once we’ve defined how we want our database to look like, and some data is already available, we have to start considering how we are going to migrate, convert or import the original data set into the chosen data model. Since original data was produced by multiple data providers, with different purposes, taking into account distinct technical specifications, the obvious starting situation that we have to be prepared is to deal with a huge diversity of formats, standards, files and disperse elements. Due to this expectable diversity in the original documents and the predictable large volume of data, we have locally installed the capability to process, integrate and edit many types of data collected by teams from WP2-4. This phase of work is designated as data processing. Data processing consist on a series of operations, editions and manipulation of the original data in view of it’s preparation for integration in the defined data model. Also, the diversity of formats for both geographic and alphanumeric data has implied that each single file of set of files had to be individually evaluated in order to define the necessary procedures towards its integration in the database. Next we will present a series of examples of data processing issues, and how they were applied to the some practical situations. o Format conversion One of the major aspects that we had to deal with was the diversity of formats in which data was available. As a first level, we had to deal with the possibility of having data not only in digital formats, allowing for more automated processing, but also data only available in paper documents. Fortunately, most of the data available was already in digital formats, thus potentially more “easy” to integrate. However, data available only in paper formats has proven to be of major importance and with relevance for the type and complexity of the simulation models that could be applied in the next stage of the project. This was because most of the data available on paper corresponds to temporal data, such as climatic series or historical data from hydrochemical monitoring campaigns, which are essential for use in such model where they need to be applied to calibrate these models. The more detailed and more extensive temporal data we have, the more reliable the simulation results potentially become. 14 GIS environment database and report Also, in a certain number of cases, more tabular data was found to be stored in digital formats not compatible with a straightforward process of integration in the database. These situations occurred when tabular data was stored in static formats such as TIF images, Corel Draw files, pictures pasted into Word documents, pdf’s, etc. In such situations as well as the case of paper documents, the use of semi-automatic procedures was applied to convert data into usable formats. Applications such as OCR (Optical Character Recognition) were used and with some additional manual error checking, most of the information could be recovered into digital format. Although very time consuming, the fact that this tabular information was, in some cases, more detailed than the available digital information, indicates that the resources used in this process are well justified. Format Digital formats Adobe Reader ArcInfo Coverage ArcView legend ArcView Presentation ASCII AutoCAD DWG AutoCAD DXF Compress file RAR Compressed file ZIP Corel Draw Drawing DBASE table Image BMP Image IMG (ArcGis) Image JPEG Image MrSID Image TIF Image WMF Mapinfo (at least .MAP+.TAB) MsAccess MsExcel MsPowerPoint MsVisio MsWord Print file Shapefile (at least .shp+.shx+.dbf) TIN (ArcGis) Hardcopy – Paper: Reports/Thesis/Articles Unidentified / Incomplete data sets Extension pdf avl apr dwg dxf rar zip cdr dbf bmp img jpg sid tif wmf mdb xls ppt vsd doc prt Nº of files 4 445 9 201 8 28 10 63 10 1 7 4 59 2 4 161 187 23 14 425 1 60 1 8 196 30 2 924 9 21 77 Table 2: Data collection statistics: types of formats in which original data was received 15 GIS environment database and report For the other digital data, of geographic or alphanumeric nature, multiple platforms were made available: GIS applications, tools for translating and transforming geographic data, spreadsheets, CAD, image processors, etc. That way, each file could be effectively open and analysed. After, and if necessary, the procedures necessary for converting it into the appropriate format for database integration would be specified. o Projection system conversion As the name Geographic Information System indicates, the information associated with these systems has a geographic component. It is this geographic information that distinguishes cartographic data and maps, from simple draws or schematic representation. Geographic information means that for each element, there is a pair or group of coordinates that uniquely position’s it in the earth surface. Geographic coordinates are referenced to a certain projection system. Projection systems are systematic transformations of the spheroid shape of the earth so that the curved, irregular, three-dimensional shape of a geographic area on the earth can be represented in two dimensions, as x,y coordinates. Since the heterogeneous shape of the Earth can not be exactly measured, a series of approximations and models define the parameters to be considered, such as the Earth major and minor radius of the spheroid, the angles, etc. These parameters are then used in the mathematical expressions that convert data from a geographical location - latitude and longitude - on the Earth’s spheroid to a representative location on a flat surface of a map. The definition of the projection system is of relevance whenever working in a project in which data from different sources is involved. This occurs, because if we want the spatial database to integrate and jointly analyse all these layers, they have to be in the same projections systems so that we can overlay them. A specific situation in which the correct definition of the projection system is essential is the calculation of length and area related values, as it is the case on many variables used in hydrologic modelling. Another important aspect is when working with complex topologic features such as a hydrographic network. In this case, the GIS uses the coordinates to analysis the connectivity of the elements. So, one of the first tasks was to identify what were the projections systems in which the original data layers were sent and then, convert each data set into the project’s projection system. 16 GIS environment database and report This was not always an easy task, because the projection system of many layers was not known, and by overlaying them, it was clear that several systems were present. By the analysis of the totally of the geographic layers sent, it was possible to identify those were the projection system was indicated and by comparison with the remaining, it was possible to deduct this information for the rest. For the future, the problem of identification of the projection system will be simple since the geodatabase format stores this information. Basin Bolivia Peru Chile Coordinates systems found in original data GCS WGS84 UTM Zone 19S WGS84 GCS WGS84 UTM Zone 18S WGS84 UTM Zone 19S WGS84 UTM Zone 19S WGS84 UTM Zone 19S PSAD 1956 Geographic Projected Geographic Projected Projected Projected Projected Coordinate system for ArcHydro database UTM Zone 19S WGS84 UTM Zone 18S WGS84 UTM Zone 19S WGS84 Table 3: Coordinates systems identified in the original layers and used in the final database for each basin. Also, in the GIS environment, it will be possible to easily convert data from one projection system to another, because it can be done by data sets and not individually, layer by layer, as in other GIS formats. o Geometric / Topologic correction Topology can be viewed as a spatial data structure used primarily to ensure that the associated data forms a consistent and clean geometric fabric. In geodatabases, the concept has evolved and considers an approach where topology is a set of governing rules applied to feature classes that explicitly define the spatial relationships that must exist between features. Examples of the topologic and geometric corrections necessary to assure the consistency with the conceptual definition of a certain feature and its geometric representation are: • For an area to be considerer a polygonal feature, the line defining its surrounding boundaries must be a perfectly closed line; • The common boundary between two adjacent areas must be defined by lines that are perfectly overmatching • When two lines, like for instance, two streams intersect, the lines representing them must be broken at the exact point of intersection. Other situations where topologic and/or geometric corrections are necessary are when features are represented by a certain geometry that does not comply with the specification of the selected data model. Examples of this situation are: 17 GIS environment database and report • • Depending on the objectives, the original geometric precision and the graphical display, some times a feature like a lake may be represented by a simple line (not necessarily closed) that defines its banks. However, in the ArcHydro data model, features such as lakes, swamps or water reservoirs are represented as polygons; Many time, to facilitate better and more presentable printouts, features such as climatic station, gauge stations or production wells are represented as small circular areas, when in fact in the ArcHydro data model, they must be converted into points. As can be observed in the figure presented below, from Lake Poopó, in Bolivia, in the hydrography original data file, all the elements were represented by simple lines. There were elements such as rivers, river banks, lakes, water reservoirs and water springs. Each line was after classified and separated into different thematic layers; lines representing water reservoirs and lakes were also corrected to form perfectly closed areas. Figure 8: Example of Bolivia, Lake Poopó: data processing of hydrography data. Apart from these corrections and adjustments of topology, there also was also a very frequent situation where adjacent features and individual elements were present in multiple, geographically adjacent files, which had to be “collated” together. In these cases, some necessary procedures might be the merging of adjacent, equivalent areas, or the elimination of pseudo-breaks in lines segments that represent the same element. 18 GIS environment database and report Figure 9, presents the original data for the rivers and streams features that were available in the case of Chili River (Peru). The 11 distinct files were collated together into a single, homogenous base and pseudo-nodes were eliminated. Figure 9: Example of Peru / Chili basin: The original river cartography base. Also, since in this case, cartographic data was generated for map production and printing, there were no intersections created at where different river segments meet. Those intersections had to be added to the lines. Figure 10: Example of the original river’s cartography for the Chili River, before processing. 19 GIS environment database and report And finally, each line was geometrically corrected to ensure that the digitizing directions would match water flow directions. Figure 11: Example of the original river’s cartography for the Chili River, after processing. Topologic and geometric conformity of features to the data model is absolutely required for database implementation. Therefore, all the elements of the data layers integrated in the project’s database were systematically analysed and all the necessary correction were made. In terms of priorities in data processing, and due to its obvious importance to the construction of each basin’s database, the main efforts regarding geographic data processing were focused in all files regarding themes such as river network, lakes, shore lines, water reservoirs, irrigation channels, pipelines and other water transport structures, water withdrawal and water discharge point, monitoring stations, drainage features and topography (contour lines and spot heights). o Table reformatting Along with the geographic data representing the spatial distribution of features, there are other types of information that are essential in a DSS for water resources management. One of such cases is times series, temporal and/or historical data of flow and water quality measurements taken at gauges or monitoring stations, as well as climatic variables. Some of this data is measured and archived at regular intervals, such as annual, monthly or daily series; others are collected at irregular intervals, like for instance, water quality samples, that are collected occasionally. One of the main aspects of working with temporal data is being capable of creating a database that can be accessible to other independent water resources models. 20 GIS environment database and report Even if GIS interface and graphic capabilities have significantly improved, in most cases, the best work environment to analyse temporal data, still remain more usable and friendly applications such as spreadsheets or specifically designed applications. So, the TimeSeries component of the ArcHydro model is clearly a component that is not so much direct to the GIS but to the more technical analysis that can be obtained by hydrologic/hydraulic simulation models. The main difficulties when working with time series results from the fact that we are often dealing with very voluminous information. Also, frequently there might be some problems related to data formats, such as units, data precision, detection limits and date and time representation. On the other hand, hydrologic models also use their own internal formats to work with temporal data. So, the ArcHydro proposes a basic structure to store undifferentiated time series into a unified system. In the ArcHydro data model each value stored in the table represents three dimensions: (i) the date/time at which the measurement was made; (ii) the type of variable being measured and (iii) the spatial feature or location at where it was measured. In contrast with this very simple structure, the original data files that contain the values to be migrated are normally present in many distinct formats. In the case of the three basins considered, temporal data could be found in tables inserted into reports, paper documents, in plain ASCII files or more structured MsExcel files, in row oriented or column oriented tables, with a clear indication of the station name or code at which the measurements were made or at locations that had to be interpreted in order to relate them to the monitoring stations geographic location, etc. The work involved an initial analysis of many type of documents, to identify which reports, which tables or which individual files contained this type of data. Then, all the different tables, structured and organized differently, were systematically imported into the ArcHydro’s time series tables, resulting in a uniform format for all data, regardless of their origin, data provider or original format. The automation of the procedures, when possible, was limited to groups of tables with similar formats. 21 GIS environment database and report Figure 12: Examples of some of the files and tables containing data for time series integration. In this process of reformatting and integrating original tabular data into the standard format, were of course, also included the files resulting from the paper-to-digital conversion by the use of character recognition applications. Figure 13: Example of the aspect of formatted time series table in ArcHydro data model 22 GIS environment database and report o Attributes normalization and data reclassification As in many other projects of this type, the possible data providers can be of very distinct nature. Apart from some data generated by previous projects participated by the teams from CAMINAR, it was also possible to collect data produced by universities, consultant companies and public entities such as institutes related to agriculture, water management, cartography, among others. Each of these entities had a specific purpose and the information they produce uses criteria, data management systems and classification systems that are specific for their own objectives. It is common that a rivers and streams map produced by an entity related to cartography and map production looks very different from a map produced by an entity related to water management. Also, many times, classification systems are very specific of a certain regional area and needs to be worked so that it can be generalised and more easily integrated in hydrologic simulation models that, one their hand, use their own data classes and scales. This type of questions is frequent when dealing with thematic information such as soils, land use, land cover, geology, ecology, climatic regions, vegetation and others. In many cases, although named differently, some data layers presented overlapping objectives, but not uniform classification. Such themes were produced with very varying spatial resolutions as well as using classification systems that depended on the particular objectives and the nature of the project they derived from and sometimes, with very specific local to regional approaches. Considering the future use of these types of information in hydraulic/hydrologic modelling, some reviewing had to be done, so that we can achieve values and classes that have more meaningful and clear definition. This type of work is currently undergoing study and some normalization systems are being analysed. The objective is to find some type of standard, well documented, practical systems that could be applied to the data. An example being focused is the case of the thematic layers such as land cover, land use and vegetation. From the preliminary analysis made to documents and files of these data categories, we’ve concluded that the definitions and classes are unclear and mixed. For this particular situation, the definition of land use and land cover could be revised using some standard systematization like, for instance, that proposed by FAO. This 23 GIS environment database and report organization has available on their website a guide (“Land Cover Classification System Classification concepts and user manual Software version”) and a freely available software that aids the application of the proposed classification system. Figure 14: Aspect of the official website of the GLCN Land Cover Topic Centre, and the software available to assist in classification and normalization of land cover themes. Other standard classification systems could also be analysed, such as the CORINE Land Cover project. Also in this case, the proposed system is well described in public documents, available through the internet, presenting the framework, objectives and methodology. The use of classes that can be easily be related to FAO’s or CORINE’s systems is frequent in modelling applications. So, since the ArcHydro data model, is flexible in the type of additional attributes associated with each feature, we could have a multidimensional vision of such thematic layers, mixing local classification systems along with more clear standard classifications. Nevertheless, at this moment, this reclassification requires more detailed work, in documenting and understanding the definitions of the classes originally applied, so that correct correspondences can be made. Also, proposed reclassification needs to be extensively discussed and validated by local teams from WP2-4, using their knowledge of local reality to critically review every option. Another step in this data processing task is the data attributes normalization. This step is intended to revise the original data structure applied in data production that was not always adapted to the environment of relational databases. 24 GIS environment database and report Examples of this situation are when classes of a certain thematic layers were described by very long text attributes, directly associated with geographic elements. In this situation what happens is the a lot of database space is allocated to store this information, which does not present a problem when dealing with small scale projects, but has to be avoid in medium-to-large scale projects. Using relational database functions, the geodatabase model resolves this situation by the use of domains. Attribute domains are rules that describe the legal values of a certain field of the database and are used to constrain the values allowed in any particular attribute for a table, feature class, or subtype. Thus, the information regarding classes is not stored in the feature’s table but in other tables, accessible through relational functionalities, significantly reducing the size of the database and improving the time for data access. Domains can simultaneously act as a legend and a validation tool for certain features since only values registered in the feature’s domain will be accepted. Another aspect in which this process of attribute normalization will be notice is in the clearness of the information. Since many of the information were stored in long text type attributes, there were many variation in the orthography, punctuation, abbreviation and in the use of accents. The use of a domain values for identifying these thematic features will eliminate the variability and errors in its description. o Cross-Populating - Mixing different sources When building a spatial database using as a starting point a multiplicity of data layers and files from different sources, it is probable that, in some cases, there will be more than one file or layer about the same related subject. Sometimes, these multiple files can be analysed together so that inconsistencies can be detected and resolved. Other times, and since these data sets were produced by distinct data providers, they contain different views of the same subject. They can than be combined to form a much more rich view of the theme. When such situations occurred for a certain theme or layer, it was possible to compensate some more incomplete data sets with additional information from other geographic layers or related tabular data. In the example presented in figures 15 and 16, two data layers containing information about land parcels where combined: one of the layers contained information about owners and the other layer contained information about agricultural production. Cross-population can be achieved by the use of common codes or unique identification attributes, or by spatial analysis. 25 GIS environment database and report Figure 15: Example of cross-population: layer “Superficies_riego_elqui231205” and layer “Panos_cultivados_elqui” contained different types of information about the same feature (land parcels) Figure 16: The resulting layer contains the aggregated data from both data sources. 26 GIS environment database and report 2.1.5 Database implementation Database implementation is a stage of the work through which data from different sources and formats is put together in a single, uniform database structure, according to a predefined data model and specified relations (geometric or alphanumeric) between the different hydro features. Through this stage of work, the final data repository is generated and prepared for its future use associated with several possible hydrologic modelling systems, under analysis. The choice of which type or what particular hydrologic model can be used, is now possible in an informed way, since we can effectively see if the required amount of data and parameters are available for proper model implementation and calibration. It is after this stage, that we can establish a second phase of work together with teams from WP2-4, in order to focus on model development according to their needs and expectations. Next we will describe some of the most important items that were focused at this implementation stage. o The HydroID concept The HydroID is an integer value that uniquely identifies every single feature in the ArcHydro geodatabase. Like normally used in RDBMS, each object is uniquely identified in the table it is stored, by a code (generally numeric), that identifies, in an unequivocal way, each object in the moment it is created. In the ArcHydro data model this concept is extended in such a way that each element in the geodatabase is uniquely identified by a numeric code that in unique through out the whole database. This mean, that even if distinct hydrofeatures are stored in separate tables, the HydroID of an element is never repeated in the database. Because of the importance of this attribute within ArcHydro, it has to be managed very carefully, through a pair of tables – the LayerKeyTable and the HydroIDTable. Using the ArcHydro’s “Assign HydroID Tool”, each time a new element is created, a new HydroID is assigned to it and the counter is updated so that this same code will never be assigned to another element. This unique feature code is used along the geoprocessing to identify the relationships between elements, using parallel attributes. Here are some examples of this use of a relational structure: a) When the relations between distinct catchment areas are defined the attribute NextDownID identifies, for each catchment, the HydroID of the next downstream catchment; 27 GIS environment database and report b) In the HydroNetwork feature the NextDownID attribute indicates the HydroID of the river segment that is downstream of the element, thus storing the direction of water flow into the database itself; o Drainage analysis using digital elevation models As rain fall on the Earth surface, the part that either does not infiltrate into the soil or doesn’t evaporate, runs off the land surface, from the higher land areas down to a stream, then into a river and finally to the sea. The physiographic parameters of the Earth’s shapes directs the flow of water to the valleys and, in its turn, is modelled by the erosive power of running water. This intimate relation between the shape of the landscape and the stream network is expressed by the drainage features. So, traditionally, drainage feature, such as dividing lines, are obtained by different forms of analysis of topographic information. In the ArcHydro data model, drainage areas are divided in three levels of representation: a) Catchments – are elementary drainage areas directly derived by the application of physical rules to the topographic model; b) Watersheds – area division of the basin into drainage areas defined by particular purposes, and where the outlet of a watershed is not necessarily coincident with a catchment outlet point. These watersheds are generally water management units; c) Basin – is a set of drainage areas, that can be approximately defined as the study area, since its geographic definition is used a basic water management unit. The interest of using different definitions of drainage system is directly related to the interaction of ArcHydro with external modelling applications. The concept of catchment as the elementary drainage unit is easy to apprehend due to its direct relation to the landscape shape and parameters. Nevertheless, the use of hydrologic models for water management and planning requires a different geographical unit. In this situation hydrologic processes and water resources issues are commonly analysed by the use of distributed watershed models. The watershed models require physiographic information such as configuration of channel network, location of drainage divides, channel length and slope, subcatchments geometry and properties, etc. Thus, the ArcHydro data models, is adapted to multiple situations, since it already takes into account different geographic basic units for modelling and analysis. 28 GIS environment database and report To be able to generate automated and reproducible drainages areas, digital elevation models (DEM) are used. To produce these models, topographic information is required, such as contour lines, spot heights, natural sinks and sources, break lines, and others. Although digital elevation models can be modelled using a irregular triangular network (TIN), in what concerns hydrologic analysis, it is more common to use models formed by altitude values placed at regular spaced interval, that define a grid or a raster format. To generate these models, some basic data is required, generally files produced for topographic or cartographic purposes. Normally this type of data is very voluminous, especially if we consider the average area of the three basins being studied in this project. The stating point is a file or set of files (representing adjacent map sheets of topographic data that are merged together) that are edited in order to remove identifiable and/or systematic errors. This situation is very common, since the enormous amount of contour lines makes it very probable to contain errors, sometimes only identifiable after the production of the DEM. One important parameter to define when building raster DEM is the grid cell size. In the vector data formed by the contour lines, the vertical interval between contour lines is generally directly related to the map scale and data’s geometric precision. When converting the vector data into raster data, the question of the geometric precision is transpose into the grid cell size. Nevertheless, we can’t say that there is a unique relation between original map scale, contour lines interval and grid cell size. Some other factor may affect this transformation and must be considered. Some literature review regarding the generation of digital elevation models, presents some analysis of the impact of the original topographic data, and the purpose for which the DEM is intended, in describing some of the constraints related to DEM spatial resolution. However, is very difficult to find literature that clearly proposes some kind of statistics or parameters that indicate the best grid cell size (or grid resolution) to be used. Authors like Hengl (2006), propose some method for defining grid cell size depending on the spatial resolution and nature of original data, but also on the morphology and complexity of the terrain itself, which is interesting. Other authors, like for instance Maidment & Djokic (2000) or Wechsler (2006) refer some grid cell size most suited for DEM resolution but only from the hydrologic analysis point of view, don’t taking into account that sometimes high resolution, reliable data is very difficult to obtain or too expensive for some types of projects. 29 GIS environment database and report Nevertheless, there some empirical methods that can be used. One possibility is to generate several DEM with different grid cell sizes, and then reverse the process, generating contour lines from these DEM and comparing them with the original data. At some point it is possible to generate a DEM that is not too coarse to produce low resolution analysis, which would have a significant impact is the identification of major drainage lines, neither a DEM that is so fine, that altitude values are extrapolated and became unrealistic. For the three basin considered for analysis, several type of topographic data was available. For instance, in the case of the Rio Elqui basin (Chile), there was already a previous existing TIN model, that was further extended to the Pan de Azúcar and Chacay areas, by the inclusion of contour lines. The contour interval for this base information was, in average, 50 meters, and there weren’t any other type of topographic data available. The resulting DEM was produced with a 50 meters resolution, which, after several essays proved to be the best possible achieved resolution. CHILE – Elqui River DEM Original topographic data Contour lines Contour lines vertical interval 50 meters (some minor areas with 25 meters interval) DEM cell size (x,y) 50 x 50 meters DEM columns and rows 3012, 2578 DEM Min value 0 meters DEM Max Value 6200 meters Uncompress file size 29.62 MB Table 4: Chile – Elqui River DEM statistics Figure 17: Digital elevation model generated for the Elqui basin, with overlaying river network 30 GIS environment database and report Figure 18: Derived DEM information for Elqui river basin: slope grid (left) and aspect grid (right). In the case of the Peru study area, on the Chili river basin, the original topographic data, was obtained from the national geographic institute, and had very good resolution. It consisted of 17 files, of adjacent maps sheets and themes, containing contour lines and 21 files with spot heights information. Due to this good quality data, it was possible to generate a DEM with grid cell size of 30 meters. This high resolution topographic model was very important for the subsequent phases of work, namely the definition of drainage features from the DEM, because the Peru area has a very complex topography, with very abrupt and narrow valleys, which could only be imprinted into the model using a smaller cell size. PERU – Chili River DEM Original topographic data Contour lines and spot heights Contour lines vertical interval 50 meters (some minor areas with 25 meters interval) DEM cell size (x,y) 30 x 30 meters DEM columns and rows 7215, 5700 DEM Min value 0 meters DEM Max Value 6283.55 meters Uncompress file size 156.88 MB Table 5: Peru – Chili River DEM statistics 31 GIS environment database and report Figure 19: Digital elevation model generated for the Chili river basin, with overlaying river network Figure 20: Derived DEM information for Chili river basin: slope grid (left) and aspect grid (right). In the case of Lake Poopó, in Bolivia, some topographic data, namely contour lines, was obtained. Currently the hypothesis of obtaining new topographic data for a wider area is being attempted, because this way it would be possible to generate a DEM for an area overlaying the total geographic extension of the hydrographic network, and thus, making possible the production of overmatching drainage statistics. 32 GIS environment database and report Figure 21: Base data: contour lines for the Lake Poopó area and overlaying hydrographic network. After producing the DEM for each basin, we can use this newly generated data layer to produce other derived information layers, such as slope and aspect grids and to obtain physiographic parameters for the landscape. But we also need to use these layers to generate information and parameters about the drainage system, both qualitatively as well as quantitatively. In the hydrologic analysis of a certain area, we want to use DEM to generate other types of information such as: a) Flow direction grids: that indicate for each cell in the grid model, the direction of the water flow along the direction of steepest descent; b) Flow accumulation grid: a grid that records the number of cells that drain into a particular cell, thus representing the area of accumulated flow at each point. c) Stream definition: a grid that defines the individual streams that are obtained considering that a drainage line converts into a stream when the area of contributing drainage accumulation exceeds a threshold. However, to obtain realistic results in the generation of such grids, sometimes the digital elevation model generated solely by the input of topographic data must be modified. This process that may be described as the generation of a Hydro DEM (DEM for hydrologic analysis). Due to particular configuration of the input data or unidentified errors, it is common that non realistic features will appear the DEM, thus affecting derived drainage feature. 33 GIS environment database and report An example of this situation is the generation of artificial sinks (closed depressions on the terrain) that have no real existence. Consequently, the drainage features generated from these DEM, would contain many endorheic drainage systems. One type of processing of the original DEM towards a hydro DEM is then filling these artificial sinks. This procedure can be done in a semi-automated way, by the initial identification of these features on the original DEM, and posterior filling of the artificial depressions on the landscape. Another type of processing normally applied to the generation of DEM for hydrologic analysis is to force the imprinting of the river network onto the DEM. Factors such as the positional quality of the topographic data, the spatial resolution and the complexity of the landscape, can produce DEM than when processed to generate the streams grid (major drainage lines), presents poor results when compared to the vector river cartography. This situation can be solved by the use of methods such as the AGREE method (Hellweger, 1997) included in the ArcHydro Tools. This method forces the effect of the river network in the drainage system by exaggerating the aspect of the river valleys in the DEM. In result, this “excavated” DEM maximizes the slope defined by the modified river channels, making drainage features to converge to the actual river network. Figure 22: Surface Reconditioning by the AGREE method (Hellweger, 1997) This type of processing produces very good results in areas where the resolution of the DEM is unable to identify the river valley and also in flat areas, where the major drainage lines are barely identified by the elevation models. 34 GIS environment database and report Figure 23: Comparison of the flow accumulation grid and the river network for the Chili river basin (Peru) Figure 24: Comparison of the flow accumulation grid and the river network for the Elqui river basin (Chile) This type of processing of the original DEM results in more accurate mapping of drainage features and brings consistency to the various layers of information regarding the hydrologic system. Using this Hydro DEM grid, many drainage features can be derived from the landscape model, and some parameters can be quantified: Catchment areas Drainage outlets and major drainage lines Watersheds Length of longest flow path inside each watershed Slope along major flow path Etc. 35 GIS environment database and report These are some of the features and values required as input by many hydrologic and hydraulic simulation models. Figure 25: Catchment areas and watershed areas for the Chile river basin (Peru). Figure 26: Catchment areas and watershed areas for the Elqui river basin (Chile). o Hydrographic network One the path of the evolution of the GIS to more elaborated data models, it has become possible to use topological network in these systems. A network is a system of interconnected elements, such as lines connecting points. Examples of networks include highways connecting cities, streets interconnected to each other at street intersections, sewer and water lines that connect to houses, and also a river network, with river segments connecting to each other in a sequential order. In a hydrographic network there are two types of elements: edges and junctions. The edges are the elements through which the water flows (river segments). Junctions are points that connect the edges (river intersections) or other points along the system with particular impact in the movement of the water along the network (may be water pumps, bridges, a water discharge stations, a hydrometric monitoring station, etc.) 36 GIS environment database and report In the geodatabase view of ArcHydro’s structure, these features are respectively named HydroEdge and HydroJunction. Connectivity is an inherent property, as it defines how the flow travels over the network. Network elements, such as edges and junctions, must then be interconnected to allow navigation over the network. Additionally, these elements have properties that control navigation on the network. One of such properties is, in the case of a river network, is the flow direction. Unlike a street network, water only flows in one direction: downhill. So, this information must be added to the elements, for instance, by defining that the digitizing direction of lines is the same as the flow direction. The river network is the backbone of the system, describing the motion of the water through the landscape. It connects catchments with their stream channels, describes the connectivity of points along rivers and determines the ordering of flow as it passes from one river reach to the next. As previously mentioned, in the case of a geometric network features, topologic and geometric conformity of the elements to the data model is absolutely required. This means that, when building the river network for the three river basins under study, each element of original files was corrected in order to resolve situation such as: - Gaps (lines not exactly connected at intersections) - Overshoots (small lime segments that overpass the intersection point with another river segment) - Loops (lines that form loops, crossing itself, thus generating circular, undetermined flow patterns) The original source data used to build these networks was very heterogeneous. In the case of the Elqui river basin (Chile), there was only one file, with some considerable degree of preprocessing, that practically had eliminated most of the edition errors, and most of the lines already built with the digitizing direction parallel to the water flow. In the case of the Chili River (Peru), original data consisted of 11 files, each correspondent to a map sheet, produced by the geographical national institute. Those eleven files had to be collated together. Also, since this information was produced for printing purposes, the cartographic base had to be integrally edited in order to remove all the pseudo nodes at map sheets boundary, to correct gaps and overshoots, to create intersection at where different line segments met and to adjust the digitizing direction according to the water movement. In the case of Lake Poopó, in Bolivia, original data contained a mixed of different line types, from rivers, lake boundaries, river banks, water springs, water reservoir boundaries, irrigation channels, among others. So, each line had to be associated with its type, and the remaining base, containing only river lines, was then processed in a way similar to the Chili’s case. 37 GIS environment database and report River network statistics Number of edges in the Elqui river (Chile) network 937 Cumulated length of the Elqui river (Chile) network 3 484 Km Number of edges in the Chili river (Peru) network 3 906 Cumulated length of the Chili river (Peru) network 9 898 Km Number of edges in the Lake Poopó (Bolivia) network 1 091* Cumulated length of the Lake Poopó (Bolivia) network 4 930 Km* * - provisional version Table 6: River network statistics for the three basin areas. When the network has been built, many types of specific analysis can be performed. In first place, we can perform some analytical operation that graphically displays the underlying topological relations that are associated with it. For instance, we can “navigate” in this network and, and for a given point in the network we can identify which segments are upstream or downstream of a certain location: Figure 27: Examples of network analyses: selecting lines upstream or downstream of a certain point. The advantages of using network analysis are not only limited to displaying the interconnectivity of the elements on the screen. The results of this type of analysis can also be stored in the database and used as an input for other type of applications. In the HydroEdge feature, an attribute such as NextDownID stores, directly in the database, the unique code of the connected downstream element. Other attributes present consolidated analysis, such as cumulated length of upstream or downstream segments, average slope of a certain portion of the hydrographic network or others. 38 GIS environment database and report o Monitoring stations and temporal data In the ArcHydro data models there is a group of features generically named HydroPoints. These HydroPoints are distributed by 7 types or classes. a) In first place, three of these classes are Dams, Bridges and generic Structures. They represent man-made or natural features whose presence affects the natural movement of water. b) In second place, we have the WaterWithdrawal and the WaterDischarge types. They represent points on the river network where water is removed or added to the system. c) Thirdly we have the MonitoringPoints, which are location on the network where the water flow or quality is measured. d) Finally we have the UserPoints, to accommodate for relevant points in the river network, that don’t fit any of the other classes, but are important for hydrologic or purely cartographic use. They can be for instance, a point where the river crosses an aquifer boundary. So, we find in the HydroPoints features, a way to integrate our tabular, temporal data, and associate it with a specific location on the hydrologic system. And this is obtained by relating the times series tables of the ArcHydro data model with the MonitoringPoints. As in all the structure of ArcHydro, the relationship between a particular monitoring station and the historical values measured at that particular location is made by the use of the HydroID unique code. For instance, the flow values measured at a particular hydrometric station is characterized in the TimeSeries table by the FeatureID attribute that, on its hand, corresponds to the same HydroID code of the geographic element representing the monitoring station. So, this particular location and the correspondent set of flow values, represent the quantity of water that passes at a specific point of the river network. However, there is a particular aspect to this situation. In almost all GIS cases, when we plot a map with the location of monitoring stations and the river network, we can verify that these points aren’t generally placed on the centre of the streams. This common situation occurs because of two factors: a) Due to the fact that the coordinates used to locate the monitoring station, for instance a gauge station, represents the location of the infrastructure or building in which the equipment is installed. So, these devices are installed on the river banks; b) Also, in other cases, there could be different geometric precision of the cartographic layers containing gauge positions and river lines. Thus, it’s unlikely that they would match. In many projects, one of the possibilities applied to overcome this setback was to displace the monitoring point from their original location, to a position on top of the river network. 39 GIS environment database and report The ArcHydro data model, proposes another approach. And this is done by the use of relational properties of the database and by the possibility of permanently storing theses relations into the database itself. This is obtained by the use of the HydroJunctions features of the river network. As described before, these junctions are points along the river network that identify particular features or events in the hydrologic system. So, we can add a particular junction to our network, to identify the presence of a nearby monitoring station. That way, we can maintain the MonitoringPoints at their original position, and use a related features (HydroJunction) to account for it’s presence in the overall water movement. JunctionID Relationship HydroID Figure 28: Connecting MonitoringPoints to the river network. Network Hydrography Figure 29: Geodatabase view of the connection between river network, monitoring station and temporal data. 40 GIS environment database and report 3 CONCLUSIONS The present version of the GIS environment database is the cumulated work of teams from WP2-4, responsible for the data collection task and team from WP6 with the definition and implementation of the necessary procedures to generate a database to support decision making more effectively. Even though there was a considerable amount of supporting data about each of the three basins under study, the original data sets were in an enormous variety of formats, media, standards, that made it very difficult to have a global view of each case. To assure that the decision making process is practical, usable and reliable, it is necessary that the whole data sets concerning each basin, may they be about ecology, topography, climate or social-economic factors, can be analysed together. The use of GIS and relational DBMS adds value to the original data sets, by migrating and converting them into a normalized database that can simultaneously accommodate both geographic and alphanumeric data. This process enhances data quality through the application of validation procedures that detect and correct inconsistencies, on individual elements or entire data sets, and by imposing a framework for structuring the information, according to pre-defined topologic/geometric and alphanumeric criteria. This spatial database is more easily managed than the scattered original data sets and can be easily used to promote continuous updates and upgrades of the information, thus improving the decision process by the use of the most actual and reliable information. Also, the use of standard formats and systems allows this data repository to interact with a variety of other applications, namely hydrologic and hydraulic modelling packages, such as the various possibilities that will be tested and evaluated for during the second stage of our work within the CAMINAR project. Finally, but not less important, the work has been developed taking into consideration the necessary transfer of this database, and the facts that are behind it, to the final users. Therefore, standard formats, public domain data models and well documented procedures have been used, aiming to generate reproducible results. 41 GIS environment database and report 4 REFERENCES Felicísimo, Angel M - 1994 - “Modelos Digitales del Terreno: Introducción y aplicaciones en las ciencias ambientales”. Pentalfa Ediciones, 122 pp. Hellweger, F. - 1997 – “AGREE - DEM Surface Reconditioning System”. University of Texas, Website: http://www.ce.utexas.edu/prof/maidment/GISHYDRO/ferdi/research/agree/agree.html Hengl, Tomislav - 2006 – “Finding the right pixel size”. Computers & Geosciences 32, 1283– 1298 Keenan, P. – 2004 - "Using a GIS as a DSS Generator". DSSResources.COM. Maidment, D., Djokic, D (ed.) - 2000 – “Hydrologic and hydraulic modelling support with geographic information systems”. ESRI Press, 216 pp. Maidment, D. (ed.) - 2002 – “Arc Hydro: GIS for water resources”. ESRI, Redlands, CA Wechsler, S. – 2006 – “Uncertainties associated with digital elevation models for hydrologic applications: a review”. Hydrology and Earth System Sciences Discussions 3, 2343–2384 42 GIS environment database and report ANNEX I DATA COLLECTION GUIDELINES 1 OBJECTIVE The purpose of this document is to define some guideline to the collection of data and the way to make data transfer between teams more efficient and clear. In this initial phase of the project the objectives are to: Identify the types of information required to build a GIS database Identify possible data sources for each type of information; Characterize and evaluate the data quality and availability Identify the procedures necessary to integrate data from multiple types and sources in a structured architecture. In order to assess the various aspects of data quality and availability, the various data collected, in the form of paper maps, existing databases, digital cartography, lists, etc, should be accompanied by a description of parameters that will help in the evaluation of its content and the steps and procedures necessary for its integration in the GIS. In order to do so, a METADATA file should be filled as completely as possible for each document collected. The type of information necessary to fill the metadata file is described in the present document. The Metadata File (template) for each data type collect is presented in chapter 7 of the present document. 2 SUMMARY The first step to start building the database is to collect and obtain as much information as possible for all the natural or man induced factors that can affect or be affected by the hydrologic systems, for superficial or groundwater, and to allows an extensive characterization of the river basin, natural process that define the way the water system works and the man-made interventions that might alter the natural processes and/or be affect by those changes. Following data collection, the second step is to use this information to build a database, using a GIS (geographical information system) to integrate, validate and analyze many different subjects, and layers of information, in a structured architecture. Later, the information gathered and organized in the database, can be used in simulation models that will assist in the evaluation of parameters such as water resources, uses and quality and the way different practices and factors will influence water availability for natural or human use. Annex 1 – Data Collection Guidelines Page 1 of Annex I GIS environment database and report 3 DATA TYPES Helpful information for defining a database for watershed management may come from very specific and well located in time and space sources, such as a time series for water quality analysis collected at a monitoring station or from information of more general type, but yet useful for the characterization of the system, such as a geological report containing pertinent information on the structural geology or a synthetic statistical analysis of the climate characterization for the basin. Nevertheless, the more detailed and rich the information is, the more realistic approach can be obtained in the simulation models. 4 DATA SUPPORTS Data collected can be obtained both in paper or digital media. Depending on the nature of the data contained in each media, it can later be converted or integrated in the GIS database, or used as general parameters in the simulation models. Examples of data collected in paper formats are: Reports containing pertinent information for watershed management, such as a geological report or information regarding statistics for water use in the basin; Maps that do not exist in digital format and that can later be digitized for integration in the GIS; List of values, for instance, climate time series or water quality analyses that don’t exist in digital format. Whenever possible, documents that only exist in paper formats should be converted to digital supports, locally. This is particularly critical for paper maps, which are difficult to copy and greatly loose quality from copy to copy. If possible, maps existing originally in paper should be converted to vector maps or, if such hypothesis is excluded, to images obtained by large scale and good resolution scanners. Examples of data in digital formats can range from very well structured data, already integrated in existing information systems, such as existing GIS or database, to tables of values, digital reports, text files, with diversified formats and structures. Examples of data collected in digital formats can be: GIS layers/themes containing both geographical and alphanumerical information; MsExcel files with list of values, for instance data collect at water wells; Database files, such as MsAccess or Dbase; Computer assisted Design (CAD) files, containing cartographic information; Bellow is presented a list of possible data formats that can be used for future integration in the project’s database: Paper documents Reports, thesis, articles, etc. Maps Lists Annex 1 – Data Collection Guidelines Page 2 of Annex I GIS environment database and report Digital Documents For data containing geographical and non-geographical information CAD files such as AutoCAD (*.dwg, *.dxf), Microstation 2D or 3D (*.dgn) GIS formats such as ArcInfo coverage (*.e00), ArcView shapefiles (*.shp), ArcGis personal geodatabases (*.mdb), Mapinfo (MIF/MID), etc. Databases such as MsAccess (*.mdb) or Dbase (*.dbf) Tabular data containing X,Y coordinates associated with other values and information such as MsExcel files (*.xls, *.csv), ASCII files (*.txt, *.prn), GPS files, etc. Satellite images or orthophotomaps (*.Tiff, *.Tiff with World File, GeoTiff, *.ECW, *.Sid, BIL, BIC) For other data without information related to it’s geographical location ASCII lists, MsExcel files, MsAccess or Dbase database files, etc. Other lists or tabular data contained in reports or articles in digital format. 5 DATA DOCUMENTATION In order to be able to integrate each type of information in the database’s system, some additional information on the nature, type and source of the data may be required. That way, is necessary that each document, layers or file collect, should have a complete description and characterization to its origin and the nature of its content. In a general way, the additional information about the data collect can be synthesized in the following main topic: a. Data Source It is fundamental to know where each type of information or document came from, who produced it, when and for what purpose. For instance, a report with information regarding water quality produced by an agriculture institute, would have a different approach in comparison to a water quality study made to determine drinking water requirements. Both source can have important information from a watershed management system point of view, but must be evaluated and processed differently in order to its integration into a unique structured database for the whole basin. Also, the date from when the information was produced can be of relevance too. An example would be a very out-dated map for land use, where, for instance, the areas of agricultural activities would be much less than the present day situation. It is important to know that in the modelling environment, in order to account for some underestimation of impacts from agricultural use. b. Data Content Each file or document may contain different type of information with different uses in the database’s structure. So, the content of each file should be described as completely as possible so that the necessary steps for its integration in the system can be correctly evaluated. For instance, a Digital Elevation Model produced in a GIS, should be accompanied by a brief description of its source, who produced it, when, using what kind of base information Annex 1 – Data Collection Guidelines Page 3 of Annex I GIS environment database and report (contour lines, radar information, etc.), an indication of its format, of the software version, of the cells resolution, etc. An MsExcel file, containing a list of values describing the times series of values collected at a meteorological station, should be accompanied by a description of the number of columns present in the file and the name of each column. A CAD files should preferably be accompanied by a description of its content, name and number of layers present, content of each layer, scale or resolution, version of the software, source or producer, type and format of the information presented in each layers, etc. c. Software versions Files produced using the same software but with different version may need different procedures in order to be integrated in the database. So, it is very helpful to know in each case, the version of the software used. For instance, a Microstation (CAD) file of 3D type or 2D type needs to be processed differently in the GIS; a personal geodatabase (*.mdb) produced with ArcGis 8.3 or ArcGis 9, have substantial differences in their structure, therefore requiring a different approaches. So, whenever possible, software version should be indicated for every kind of digital theme. d. Geographical Information Since most of the information required to build a database for watershed management is dependent on the spatial position of each phenomena, most of the information required to build the system comes from documents, both in paper or digital support, that contain the geographical position of information. Such documents can be paper maps, GPS files with data collected in the field, lists of data associated with its X,Y coordinates, digital maps in GIS or CAD formats, etc. X,Y information has its own standards, so a Projection System or Coordinate System must be defined for the geographical database. Since, the coordinate or projection system may not be used universally between different data producers it should be considered the possibility that the information gathered for the basin may be presented in different coordinates systems and requires a subsequent conversion into a unique system. To do that, the original coordinate system used in the production of digital maps and list of X,Y must be documented. So, for each type of information containing geographical information, the original Coordinate system should be described. Things that need to be answered are: Are coordinates presented in rectangular (Cartesian X,Y) or geographical values (Latitude, Longitude, in decimal values or in degrees)? Annex 1 – Data Collection Guidelines Page 4 of Annex I GIS environment database and report What’s the projection system? What are the parameters for the projection system datum, projection name, ellipsoid, major, minor axes, false easting or false northing, etc? e. Alphanumeric Information One can expect that many different file containing dispersed information will be required to get a rich characterization of the hydrologic system. Each file or document, can be produced from different sources, for different purposes, at a wide range of dates. So, we must be prepared for an enormous diversity of ways to represent the information. In many of these files, tables, list and documents, measurements and values are presented in ways that are clear in a certain context, but may be difficult to interpret at a certain distance. Also, in many cases, people tend to work with short names, alias or abbreviations, normally more friendly and simple to use. Therefore, if a table, a list of values or the columns of a database associated with a geographical theme is collect, a complete description of the columns or heading name and its meaning should be obtained as often as possible. f. Data formats and units For some kinds of data, some additional information may prevent further misinterpretation or misreading, due to ambiguities. For instance, the way dates are written can vary greatly, so each file or document containing dates should indicate its format, for example: Day-Month-Year or Year-Month-Day, or others. In the case of numeric values, it is also possible that even the same parameter can be present in more than one unit or measurement system depending on purpose, analytical technique, time of data collection, etc. So, whenever possible, numerical fields or values present in lists, tables or databases should have indicated the units that apply to each case. g. Data classes, data codes. legends and data ranges For may type of information it is common to used information classified according to some kind of coding system. In many cases, such classification can use some type of standard classification, well documented and easily accessible, but in others, locally defined classes are used. In the first case we can use as an example, the land use classification defined by FAO, that can be applied in many different area of the world in a uniform and standardized manner. In the second case, can be, for instance, the lithological or stratigraphic classification used in geological maps, dependent on legends developed independently by different countries. So, in cases where information on a particular aspect of the study area is represented by a classification system, by a pre-defined set of numeric or alphanumeric codes, by classes Annex 1 – Data Collection Guidelines Page 5 of Annex I GIS environment database and report ranges or by a particular legend, such information should be delivered along with the documents or files regarding it. Also, a description of the methodology or criteria used to define each class or code is of importance. Annex 1 – Data Collection Guidelines Page 6 of Annex I GIS environment database and report 6 DATA CATEGORIES The following list in not intended to be an exhaustive list of all the data to be collect and integrated in the project’s database. It is a list of all the main categories of data that can be used to get a more realistic description and characterization of the basin’s model. So, the list of categories and associated theme should be looked as: “finding the most of information related to….” each one of these subjects. Depending on each basin’s data availability, up-to-date, readiness, quality, etc, adaptations will have to be made to account to local reality. Topography Contour lines Spot Height Digital Elevation Models in raster (grid) format Digital Elevation Model in TIN format 3D lines, 2D lines with associated elevation texts 3D points, 2D points with associated elevation texts, 2D texts, etc. With information on the methodology used in its production and cells size resolution and vertical scale (if applied) With information on the methodology used in its production and vertical scale (if applied) Administrative boundaries, Territory administration Administrative units or political Polygon delimitation of “Provincias”, “Regions”, etc. boundaries Urban areas Main urban areas delimitation as polygons or points of approximate location for main urban areas and respective identification (Ciudades, Localidades, pueblos, etc) Demography Demographic information Geographic distribution of people associated with the basin’s area, the administrative units or the urban areas. Basin Basin delimitation If exists, polygon delimitation of the basin Sub-basin delimitation If exists, polygon delimitation of sub-basins. Geology Geological maps Digital geological maps with associated legend and class description; paper geological maps and related documents, such as lithological and structural description of the area Soils maps Soils maps Digital or paper maps of soils, with associated legend, and class’s description, characterization and properties or other parameters such as thickness, texture, composition, etc. Annex 1 – Data Collection Guidelines Page 7 of Annex I GIS environment database and report Land Use / Land Cover Land Use Land Cover Digital or paper maps describing arrangements, activities and inputs people undertake on the basin’s area with associated legend, type of classification used and classes description, characterization and properties Digital or paper maps of the observed biophysical cover of the territory in the basin’s area, with associated legend, type of classification used and classes description, characterization and properties Climate Meteorological stations location Meteorological time series General meteorological data Precipitation grids or estimations Ecology, environment and natural heritage Natural parks and reserves Protected habitats and/or landscapes Economic activities Agriculture Infrastructures Agriculture practices Industry Mining activities Energy Sources Surface hydrology Streams network Water surfaces Digital or paper maps or X,Y list with meteorological station location Meteorological time series of data collected in meteorological station with or without known location (rainfall, temperature, evaporation, etc) General parameters or statistical records for meteorological characterization of the basin’s area, for example, cumulative precipitation on the basin area for past years and others, temperature information, actual or potential evaporation, etc Models for average precipitation along basin area that might have been produced with information on model’s generation. Polygon delimitation of natural parks Delimitation of areas of special interest for natural preservation, protected habitats, endangered species, etc. Irrigation areas and perimeters; irrigation channels Crop types and agriculture practices Location of main industrial area with potential effect on dispersed contamination of soils and water, and possible list of components being discharged; Location of isolated industries such as heavy industries, chemical industries and other industrial activities with known pollutant discharges Concession or permit area; mine’s plant or main features, water discharge points or areas, minerals extracted, etc. Hydro electric, thermal or other power stations Streams line network for the water system in the basin Lakes, natural or man-made water reservoirs, damns, broad rivers banks with associated information such as name, water volume (measure at a certain date or maximum capacity), water level (measured at a certain date or maximum Annex 1 – Data Collection Guidelines Page 8 of Annex I GIS environment database and report Costal or shore line Infrastructures Water quality monitoring stations River gauging / monitoring stations Water supply systems level), etc. Shore line Bridges, dams, channels, pipelines; Other associated information such as historical values of water discharges at each dam, volumes of water by use, etc. With associated values measured at each location and if possible, with historical values (time series) for chemical and physical parameters. With associated information such as mean annual level, minimum and maximum values and dates, river flow measurements, etc. Intakes, volume, use, etc. Groundwater Aquifers delimitation Aquifers geometry Groundwater wells Groundwater sources Groundwater quality Water use activities, regulatory requirements Water quality / quantity Pollution sources Water treatment systems Cartographic delimitation of aquifers or geological formations associated with aquifers. Measured top and bottom of aquifers formations, estimations or models of aquifers geometry and information regarding model’s generation, aquifers thickness, lithological logs, etc. Municipal, industrial or agricultural boreholes with associated information , if available, such as aquifer name, rock formation, total depth, transmissivity, measured water levels, etc With associated information, if available, such as aquifer, geological formation of outcrop, flow, etc. Groundwater analysis or time series of analysis collected at groundwater well and sources, with information regarding various chemical and physical parameters. General or statistical information for water quality in the basin’s area or part of the area, if possible, classified according to potential use (irrigation, drinking, etc.); General or statistical information on water use in the basin’s area, with estimations of volumes used by economic sectors or geographical regions, etc. General or statistical information regarding diffuse or punctual pollution sources from industrial discharges, water treatment discharges, domestic discharges, agriculture runoff, chemical or effluent storage areas, etc For waste or clean water with information on capacity, mean or annual flow rates, etc. Annex 1 – Data Collection Guidelines Page 9 of Annex I GIS environment database and report 7 METADATA (an MsExcel file with Metadata’s structure will be delivered for use) Document Name / File Name: Data Title: Data Category: Data Summary Description: Data Source / Producer: Purpose: Year of production: Year of last update: Class of spatial representation: Product Format: ArcInfo (*.e00) AutoCAD (*.dxf) MsAccess (*.mdb) Choose one of the following NONE VECTOR TIN IMAGE GRID LIST w/ X,Y Choose one of the following ArcView (*.shp) AutoCAD (*.dwg) Dbase (*.dbf) TIFF Image (*.tif) Image w/ World file Other image format: ____________________________ Other file format:________________________________ Products format version: ArcGis (*.mdb) Microstation 2D (*.dgn) MsExcel workbook (*.xls) MapInfo (MIF/MID) Microstation 3D (*.dgn) MsExcel comma separated (*.csv) Image ErMapper (*:ecw) Image GeoTiff (*.tif) Other GIS Format:____________ ASCII file Image Mr.Sid (*.sid) Distributor:_________________________ Version (number or year) Scale / Spatial Resolution. Projection System Projection Name: Datum Projection parameters: Coordinate System Elipsóide: Ellipsoide parameters: Choose one of the following Annex 1 – Data Collection Guidelines Page 10 of Annex I GIS environment database and report Rectangular coordinates (X,Y) Themes or layers (for GIS or CAD files) Name Description Associated attributes (For GIS files, ASCII, MsExcel, MsAccess, Dbase or other lists and tabular data) Attribute Name Description Format Units Geographical coordinates (Lat / Long) Type of elements Class or Domain Annex 1 – Data Collection Guidelines Page 11 of Annex I GIS environment database and report 8 DATA SHARING A protocol for data transfer should be defined to minimize time for data accessibility, costs, and administrative procedures. FTP Easy and fast for digital data User’s access using authentication procedures (user name and password) Available all the time Limited to small to medium dimension files Dependent on the internet velocities available at each site As soon as all procedures necessary for establishing the ftp area on the server and the user’s names and passwords are defined, they will be communicate to each team’s responsible. CD-ROM or DVD For digital data of larger dimension, the use of FTP for data transfer may be too slow or even impossible. Large data files can be recorded using media such as CR-ROM or DVD PAPER DOCUMENTS 9 In those cases where digital conversion of paper documents (maps, reports, listings and other), is totally impossible to performed locally, paper documents, preferably good quality copies, can be also send, using normal courier services. PROPOSED SYSTEM ARCHITECTURE FOR BUILDING THE DATABASE In order to build the system’s database that will later interact with the modelling applications, a GIS will be used to assist in the different tasks. The proposed architecture containing all the required functions and tools required is presented in the following table: Software / Application ArcEditor Spatial Analyst Geostatistical Analyst ArcHydro for watershed management ArcHydro for groundwater management MsAccess Functionalities Building the database: data edition, conversion, integration, topological validation. Raster-based spatial modelling and analysis Analysis of data’s spatial correlation, global trends, prediction tools and surface creation Data processing and interface with basin analysis models Data processing and interface with groundwater models Licence mode Single-user Database management system Single-user (integrated in MsOffice professional or later version) Single-user (ArcGis extension) Single-user (ArcGis extension) Public domain Public domain Annex 1 – Data Collection Guidelines Page 12 of Annex I GIS environment database and report ANNEX II Basic ArcHydro data model framework Component: Hydrography Table: Bridge Feature geometry: Point Description: A bridge is a structure that allows passage over an obstacle. Name OBJECTID Shape HydroID HydroCode FType Name JunctionID Type Long Integer OLE Object Long Integer Text Text Text Long Integer Size 4 4 30 30 100 4 Domain - Table: Dam Feature geometry: Point Description: Is a structure that creates an artificial lake or reservoir, by blocking a river or stream. Name OBJECTID Shape HydroID HydroCode FType Name JunctionID Type Long Integer OLE Object Long Integer Text Text Text Long Integer Size 4 4 30 30 100 4 Domain - Table: HydroLine Feature geometry: Line Description: Line features important for cartographic representation, not contained in the Hydro Network feature. Name OBJECTID Shape HydroID HydroCode FType Name Shape_Length Type Long Integer OLE Object Long Integer Text Text Text Double Size 4 4 30 30 100 8 Domain - Annex I1 – ArcHydro data model framework Page 1 of Annex II GIS environment database and report Table: HydroResponseUnit Feature geometry: Polygon Description: Describes the response of the terrain (geology, soil, land cover, etc.), for surface water balance accounting. Name OBJECTID Shape HydroID HydroCode AreaSqKm Shape_Length Shape_Area Type Long Integer OLE Object Long Integer Text Double Double Double Size 4 4 30 8 8 8 Domain - Table: MonitoringPoint Feature geometry: Point Description: Location of stations that measure water quantity or quality. Name OBJECTID Shape HydroID HydroCode FType Name JunctionID Type Long Integer OLE Object Long Integer Text Text Text Long Integer Size 4 4 30 30 100 4 Domain - Table: Structure Feature geometry: Point Description: Point feature that might have significant impact in the water flow but aren't included in the bridge or dam classes (e.g. a waterfall). Name Type Size Domain OBJECTID Long Integer 4 Shape OLE Object HydroID Long Integer 4 HydroCode Text 30 FType Text 30 Name Text 100 JunctionID Long Integer 4 - Annex I1 – ArcHydro data model framework Page 2 of Annex II GIS environment database and report Table: UserPoint Feature geometry: Point Description: Point of particular interest to the user, not included in any other feature classes (may include locations where rivers cross aquifer or political or administrative boundaries). Name Type Size Domain OBJECTID Long Integer 4 Shape OLE Object HydroID Long Integer 4 HydroCode Text 30 FType Text 30 Name Text 100 JunctionID Long Integer 4 Table: Waterbody Feature geometry: Polygon Description: Represents water bodies such as lakes, bays and estuaries, water reservoirs, swaps, etc. Name OBJECTID Shape HydroID HydroCode FType Name AreaSqKm JunctionID Shape_Length Shape_Area Type Long Integer OLE Object Long Integer Text Text Text Double Long Integer Double Double Size 4 4 30 30 100 8 4 8 8 Domain - Table: WaterDischarge Feature geometry: Point Description: Points where flow is added to the stream network. Name OBJECTID Shape HydroID HydroCode FType Name JunctionID Type Long Integer OLE Object Long Integer Text Text Text Long Integer Size 4 4 30 30 100 4 Domain - Annex I1 – ArcHydro data model framework Page 3 of Annex II GIS environment database and report Table: WaterWithdrawal Feature geometry: Point Description: Points where flow is diverted or pumped from the stream network. Name OBJECTID Shape HydroID HydroCode FType Name JunctionID Type Long Integer OLE Object Long Integer Text Text Text Long Integer Size 4 4 30 30 100 4 Domain - Component: Drainage Table: Basin Feature geometry: Polygon Description: Packaging unit; administrative unit for drainage analysis; ≈ study area. Attribute Type Size Domain Long Integer OBJECTID 4 OLE Object Shape Long Integer HydroID 4 Text HydroCode 30 Long Integer DrainID 4 Double AreaSqKm 8 Long Integer JunctionID 4 Long Integer NextDownID 4 Double Shape_Length 8 Double Shape_Area 8 - Annex I1 – ArcHydro data model framework Page 4 of Annex II GIS environment database and report Table: Catchment Feature geometry: Polygon Description: Elementary drainage areas, defined by physical rules applied to the landscape’s configuration. Name Type Size Domain Long Integer OBJECTID 4 OLE Object Shape Long Integer HydroID 4 Text HydroCode 30 Long Integer DrainID 4 Double AreaSqKm 8 Long Integer JunctionID 4 Long Integer NextDownID 4 Double Shape_Length 8 Double Shape_Area 8 Table: DrainageLine Feature geometry: Line Description: Line of major accumulated flow for each catchment; drainage path. Name Type Size Domain OBJECTID Long Integer 4 Shape OLE Object HydroID Long Integer 4 HydroCode Text 30 DrainID Long Integer 4 Shape_Length Double 8 Table: DrainagePoint Feature geometry: Point Description: Point representing the most downstream location within a catchment; outlet of drainage area. Name Type Size Domain OBJECTID Long Integer 4 Shape OLE Object HydroID Long Integer 4 HydroCode Text 30 DrainID Long Integer 4 JunctionID Long Integer 4 - Annex I1 – ArcHydro data model framework Page 5 of Annex II GIS environment database and report Table: Watershed Feature geometry: Polygon Description: Drainage areas defined by subdivision of the landscape according to management criteria Name Type Size Domain Long Integer OBJECTID 4 OLE Object Shape Long Integer HydroID 4 Text HydroCode 30 Long Integer DrainID 4 Double AreaSqKm 8 Long Integer JunctionID 4 Long Integer NextDownID 4 Double Shape_Length 8 Double Shape_Area 8 - Component: Network Table: HydroEdge Feature geometry: Line Description: Lines representing water flow along the network. Name OBJECTID Shape Enabled HydroID HydroCode ReachCode Name LengthKm LengthDown FlowDir FType EdgeType Shape_Length Type Long Integer OLE Object Integer Long Integer Text Text Text Double Double Long Integer Text Long Integer Double Size Domain 4 2 4 30 30 100 8 8 4 HydroFlowDirections 30 4 HydroEdgeType 8 - Annex I1 – ArcHydro data model framework Page 6 of Annex II GIS environment database and report Domain: HydroFlowDirections Code Description 0 Uninitialized 1 WithDigitized 2 AgainstDigitized 3 Indeterminate Domain: HydroEdgeType Code Description 1 Flowline 2 Shoreline Table: HydroJunction Feature geometry: Point Description: Points representing important features in the network with impact in the water movement (dam, waterfall, etc.) or a particular event (monitoring point) Name Type Size Domain OBJECTID Long Integer 4 Shape OLE Object AncillaryRole Integer 2 AncillaryRoleDomain Enabled Integer 2 HydroID Long Integer 4 HydroCode Text 30 NextDownID Long Integer 4 LengthDown Double 8 DrainArea Double 8 FType Text 30 Domain: AncillaryRoleDomain Code Description 0 None 1 Source 2 Sink Annex I1 – ArcHydro data model framework Page 7 of Annex II GIS environment database and report Table: HydroNetwork_Junctions Feature geometry: Point Description: Generic junctions (points) in the network. Name OBJECTID SHAPE Enabled Type Long Integer OLE Object Integer Size 4 2 Domain - Table: SchematicLink Feature geometry: Line Description: Simplified version of the network, presenting the general connectivity among water features. Name OBJECTID Shape HydroID HydroCode FromNodeID ToNodeID Shape_Length Type Long Integer OLE Object Long Integer Text Long Integer Long Integer Double Size 4 4 30 4 4 8 Domain - Table: SchematicNode Feature geometry: Point Description: Nodes in the schematic network, representing connection between SchematicLinks and particular events or features (drainage outlets, catchments centroids, etc.) Name Type Size Domain OBJECTID Long Integer 4 Shape OLE Object HydroID Long Integer 4 HydroCode Text 30 FeatureID Long Integer 4 - Annex I1 – ArcHydro data model framework Page 8 of Annex II GIS environment database and report Component: Channel Table: CrossSection Feature geometry: Line Description: Is a 3D polyline feature, where each vertex in the line is defined by coordinates (x, y, z) Name OBJECTID Shape HydroID HydroCode ReachCode RiverCode CSCode JunctionID CSOrigin ProfileM Shape_Length Type Long Integer OLE Object Long Integer Text Text Text Text Long Integer Text Double Double Size 4 4 30 30 30 30 4 30 8 8 Domain - Table: ProfileLine Feature geometry: Description: Longitudinal view of a channel, using lines drawn parallel to the stream flow. Name OBJECTID Shape HydroID HydroCode ReachCode RiverCode FType ProfOrigin Shape_Length Type Long Integer OLE Object Long Integer Text Text Text Text Text Double Size 4 4 30 30 30 30 30 8 Domain ProfileLineType - Domain: ProfileLineType Code Description 1 Thalweg 2 Bankline 3 Streamline Annex I1 – ArcHydro data model framework Page 9 of Annex II GIS environment database and report Component: Time series Table: TimeSeries Feature geometry: NONE (Tabular) Description: Tabular data (values) resulting from temporal, historical data, measured at regular or irregular intervals. Attribute OBJECTID FeatureID TSTypeID TSDateTime TSValue Type Long Integer Long Integer Long Integer Date/Time Double Size 4 4 4 8 8 Domain - Table: TSType Feature geometry: NONE (Tabular) Description: Characterization of time series types by regularity, interval, units of measurement, etc. Attribute OBJECTID TSTypeID Variable Units IsRegular TSInterval DataType Origin Type Long Integer Long Integer Text Text Long Integer Long Integer Long Integer Long Integer Size Domain 4 4 30 30 4 4 TSIntervalType 4 TSDataType 4 TSOrigins Domain: TSDataType Code Description 1 Instantaneous 2 Cumulative 3 Incremental 4 Average 5 Maximum 6 Minimum Domain: TSOrigins Code Description 1 Recorded 2 Generated Annex I1 – ArcHydro data model framework Page 10 of Annex II GIS environment database and report Domain: TSIntervalType Code Description 1 1Minute 2 2Minute 3 3Minute 4 4Minute 5 5Minute 6 10Minute 7 15Minute 8 20Minute 9 30Minute 10 1Hour 11 2Hour 12 3Hour 13 4Hour 14 6Hour 15 8Hour 16 12Hour 17 1Day 18 1Week 19 1Month 20 1Year 99 Other HydroID Management Tables Table: LAYERKEYTABLE Feature geometry: NONE (Tabular) Attribute Type Size Long Integer OBJECTID 4 Text LAYERNAME 35 Text LAYERKEY 35 Domain - Table: HYDROIDTABLE Feature geometry: Attribute OBJECTID LAYERKEY HYDROID Domain - NONE (Tabular) Type Size Long Integer 4 Text 35 Double 8 Annex I1 – ArcHydro data model framework Page 11 of Annex II