Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Discovering partial periodic
pattern on discrete spatiotemporal data
Huiping Cao
Sep. 26, 2003
1
Outline
Background
Problem definition
Solution
Experiments
Future work
References
2
Background
More spatio-temporal data are generated with
the development of moving computing
equipments
Most provided methods support queries on
such kind of data efficiently by making use of
index
We are trying to find some periodic patterns
from the data to facilitate the queries ([3]same
motivation).
3
Related Work
Partial period patterns discovered from
spatio-temporal data refer to those location
series that appear periodically and frequently.
Existing works on periodic pattern mining:
Either assume that the periods are given in
advance by the user
Or could not efficiently find the periods
automatically
4
Pre-handling of data
Continuous spatio-temporal data sequence is
converted to discrete symbol data sequence
Discrete data is defined in advance. E.g.,
some district name in the real world.
(x,y) sequence: (20,20),(21, 20) (21,21)
Discrete symbol sequence: A A B
Where A and B are predefined by the user
5
Problem definition
Given discrete value sequence: S = D1,
D2, ..., Dn where sampling rate is fixed.
Partial pattern s = s1 ... sp . Here, si is
defined over (2L-{}{*}) where L is
the underlying set of features and *
refers to the “don’t care” character.
6
Problem definition
|s|: pattern length
L-length of s: number of si which contains
letters from L.
Sub-pattern of a pattern s: a pattern s’ = s’1
... s’p such that |si| = |s’i| and s’i si for every
position i where s’i *.
E.g.: s = a*{a,c}de
|s|=5,
L-length is 4(also called 4-pattern)
a*{a,c}** and **cde are all its sub-patterns
7
Problem definition
A patterns s = s1 ... sp is true in some period
segment if
for each position i, either si is * or all the letters in si
occur in the ith set of the features in the segment.
E.g., Pattern “a*b” is true in segment “acb”, but not
true in “bcb”
frequency_count(s) in sequence S=D1, D2, ..., Dn
frequency_count(s) = |{i|0i<m, and string s is true in
Di|s|+1, Di|s|+s, ..., Di|s|+|s|}|.
8
Problem definition
support(s) = frequency_count(s)/m
m: maximum number of periods of length |s|
contained in the sequence.(m|s| n<(m+1)|s|).
E.g.: In a{b,c}baebaced, freq_count(a*b) =2,
sup(a*b) =2/3
frequent partial periodic pattern s:
sup(s) min_conf, which is a user specified
threshold
9
Problem definition
Input:
A discrete data sequence, S
min_support , min_sup
Time window, w
Goal:
Find the periods automatically in window w
Discover all the frequent patterns for one
period or some periods
10
Solution
Step1:
scans the sequence and constructs a memory
based structure, abbreviated list table, to find
the potential periods.
Create disk-based inverted lists for the typical
data points in the sequence
Step2:
Find all the frequent patterns taking advantage
of the disk-based inverted lists gotten from the
first step and the max sub-pattern tree
11
Step 1
Abbreviated list table
For each value v and each possible period
p(1p w), count the occurrences of v at
position 0, 1, ..., p-1
Example.
12
Example
E.g.:
S=ABAAACCAAE
min_sup =0.8
w=5
6
4
2
2
2
2
3
0
1
2
1
0
2
2
P=1 threshold= 8
P=2 threshold= 4
P=3 threshold= 8/3
P=4 threshold= 2
1
P=5 threshold= 1.6
13
Example(cont.)
Possible periods:
2,4,5
F1:
p=2: A*
p=4: A***, ***A
p=5: **A**, ***A*
14
Analysis on step1
Time complexity: O(n)
where n is the sequence length
Space: O(|D|w2)
Space: |D|w(w+1)/2
|D|: domain size
w: window
Suppose w = 1000, w2 is about 1M
absolute value is acceptable
15
Analysis on step1(cont.)
Compare with the circular autocorrelation method
generate F1 in the same time
n could be unknown in advance
avoid generating useless period
e.g.:
S = A*A*A**AA*
(* don’t care), min_sup=0.8
bitmap of A: 1010100110
f(0).f(4) = (1010100110).(0110101010)
= 3 > 2=10/4*0.8 frequent
However, p=4 is not frequent
16
Step 2
Construct max sub-pattern tree by scanning
the disk-based inverted list
access disk with less cost
E.g.,
Domain ={A,B,C,D,E,F,G,H}
The symbols that appear in F1 are A and C
Just need scan the inverted list of A and C but needn’t
access other symbols
Traverse max sub-pattern tree to get frequent
ones
17
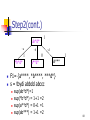
Step2(cont.)
1
ab*d*
~a
1
*b*d*
~d
~b
0
a**d*
1
ab***
F1= {a****, *b****, ***d*}
s = tbydi abbdd abccc
sup(ab*d*)=1
sup(*b*d*) = 1+1 =2
sup(a**d*) = 0+1 =1
sup(ab***) = 1+1 =2
18
Analysis
Advantages:
Find periods efficiently(Experiments)
compared with the circular autocorrelation
method
Mine frequent patterns more
efficiently(Experiments)
Disadvantage
Inverted list uses the same space as the
sequence
19
Experiments
data:24192 data points
min_sup=0.7
Varying window
Period finding(Exp.1)
2000
time(ms)
1500
Circular
Autocorrelation
1000
I-List
500
0
24
48
72
96
120
window
20
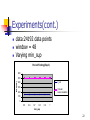
Experiments(cont.)
window=24
min_sup=0.7
Varying data volume
Period Finding(Exp.2)
5000
4000
time(ms)
3000
Circular
Autocorrelation
2000
I-List
1000
0
100
200
300
400
500
Data point(*672)
21
Experiments(cont.)
data:24192 data points
window = 48
Varying min_sup
Period Finding(Exp.3)
600
500
time(ms)
I_List
400
300
Circular
Autocorrelation
200
100
0
0.5
0.6
0.7
0.8
0.9
1
min_sup
22
Experiments(cont.)
window=24
min_sup=0.7
Varying data volume
Pattern Finding(Exp. 2.1)
1000
800
time(ms)
Max sub-pattern tree
600
I-List max sub-pattern
tree
400
200
0
100
200
300
400
500
data point(*672)
23
Experiments(cont.)
data: 67200 data points
min_sup=0.7
Varying window
Pattern Finding(Exp. 2.2)
200
time(ms)
150
Max sub-pattern tree
100
I-List max subpattern tree
50
0
24
48
72
96
120
Window
24
Experiments(cont.)
data: 67200 data points
window=48
Varying min_sup
Pattern Finding(Exp.2.3)
200
time(ms)
150
Max sub-pattern tree
100
I-List max subpattern tree
50
0
0.5
0.6
0.7
0.8
0.9
1
min_sup
25
Future work
Finding new kind of patterns
How to store patterns more efficiently
How to facilitate queries when using
patterns
26
References
1.
2.
3.
J. Han, G. Dong, Y. Yin. Efficient Mining of
Partial Periodic Patterns in Time Series
Database. In ICDE99.
C.Berberidis, I. Vlahavas, W. G. Aref. etc. On
the Discovery of Weak Periodicities in Large
Time Series. In PKDD02.
L.H. Yang, M. L. Lee, W. Hsu. Efficient
Mining of XML Query Patterns for Caching.
In VLDB04.
27
Suggestions & Questions
28





























![[edit] Use and importance of SNPs](http://s1.studyres.com/store/data/004266468_1-7f13e1f299772c229e6da154ec2770fe-150x150.png)







