Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
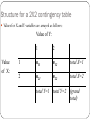
Sociology 601 Lecture 11: October 6, 2009 No office hours Oct. 15, but available all day Oct. 16 Homework Contingency Tables for Categorical Variables (8.1) some useful probabilities and hypothesis tests based on contingency tables independence redefined. The Chi-Squared Test (8.2) [Thursday] When to use Chi-squared tests (8.3) [Thursday] chi-squared residuals Homework Stata ttests: means and proportions – using categorical, dummy, interval/continuous variables P values with the T table: t=3, n=9, what is P? # 30 – industrial plant – part C # 52 – random number generator Small sample significance test # 54 – e is incorrect 3 Definitions for a 2X2 contingency table Let X and Y denote two categorical variables Variable X (Explanatory/Independent variable) can have one of two values: X = 1 or X = 2 Variable Y (Response/Dependent variable) can have one of two values:Y = 1 or Y = 2 nij denotes the count of responses in a cell in a table Structure for a 2X2 contingency table Values for X and Y variables are arrayed as follows: Value of Y: Value of X: 1 2 1 n11 n12 total X=1 2 n21 n22 total X=2 total Y=1 total Y=2 (grand total) Some useful definitions The unconditional probability P(Y = 1): = (n11 + n21 )/ (n11 + n12 + n21 + n22 ) = the marginal probability that Y equals 1 The conditional probability P(Y = 1, given X = 1): = n11 / (n11 + n12) = P ((Y = 1) | (X = 1)) The joint probability P(Y = 1 and X = 1): = n11 / (n11 + n12 + n21 + n22 ) = P ((Y = 1) (X = 1)) = the cell probability for cell (1,1) Example: Support health care spending? Yes No Tot Support Law Enforcement? Yes No 292 25 14 9 306 34 Tot 317 23 340 What is the unconditional probability of favoring increased spending on law enforcement? What is the conditional probability of favoring increased spending on law enforcement for respondents who opposed increased spending on health? What is the joint probability of favoring increased spending on law enforcement and opposing increased spending on health? Hypothesis tests based on contingency tables: Usually we ask: is the distribution of Y when X=1 different than the distribution ofY when X=2? Null Hypothesis: the conditional distributions of Y, given X, are equal. Ho: P ((Y = 1) | (X = 1)) – P((Y = 1) | (X = 2)) = 0 alternatively, Ho: Y|X=1 - Y|X=2 = 0 This type of question often comes up because of its causal implications. For example: “Are childless adults more likely to vote for school funding than parents?” A confusing new definition for independence Previously we used the term independence to refer to groups of observations. “White and hispanic respondents were sampled independently.” In this chapter, we use independence to refer to a property of variables, not observations. “Political orientation is independently distributed with respect to ethnicity” Two categorical variables are independent if the conditional distributions of one variable are identical at each category of the other variable. Democrat Independent Republican Total white 440 140 420 1000 black hispanic Total 44 110 594 14 35 189 42 105 567 100 250 1350 Contingency tables in STATA The 1991 General Social Survey Contains data on Party Identification and Gender for 980 respondents. See Table 8.1, page 250 in A&F Here is a program for inputting the data into STATA interactively: input str10 gender str12 party number female democrat 279 male democrat 165 female independent 73 male independent 47 female republican 225 male republican 191 end Contingency tables in STATA Here is a command to create a contingency table, and its output . tabulate gender party [freq=number] | party gender | democrat independe republica | Total -----------+---------------------------------+---------female | 279 73 225 | 577 male | 165 47 191 | 403 -----------+---------------------------------+---------Total | 444 120 416 | 980 The following slide adds row, column, and cell % . tabulate gender party [freq=number], row column cell +-------------------+ | Key | |-------------------| | frequency | | row percentage | | column percentage | | cell percentage | +-------------------+ | party gender | democrat independe republica | Total -----------+---------------------------------+---------female | 279 73 225 | 577 | 48.35 12.65 38.99 | 100.00 | 62.84 60.83 54.09 | 58.88 | 28.47 7.45 22.96 | 58.88 -----------+---------------------------------+---------male | 165 47 191 | 403 | 40.94 11.66 47.39 | 100.00 | 37.16 39.17 45.91 | 41.12 | 16.84 4.80 19.49 | 41.12 -----------+---------------------------------+---------Total | 444 120 416 | 980 | 45.31 12.24 42.45 | 100.00 | 100.00 100.00 100.00 | 100.00 | 45.31 12.24 42.45 | 100.00 8.2 Developing a new statistical significance test for contingency tables. support environment? Yes No Tot support tax reform? Yes No 150 100 200 50 350 150 Tot 250 250 500 “Is the level of support for the environment dependent on the level of support for tax reform.” If so, these two measures are likely to have some causal link worth investigating. With a 2x2 table, we can use a t-test for independent-sample proportions. . prtesti 250 .6 250 .8 Two-sample test of proportion x: Number of obs = 250 y: Number of obs = 250 -----------------------------------------------------------------------------Variable | Mean Std. Err. z P>|z| [95% Conf. Interval] -------------+---------------------------------------------------------------x | .6 .0309839 .5392727 .6607273 y | .8 .0252982 .7504164 .8495836 -------------+---------------------------------------------------------------diff | -.2 .04 -.2783986 -.1216014 | under Ho: .0409878 -4.88 0.000 -----------------------------------------------------------------------------diff = prop(x) - prop(y) z = -4.8795 Ho: diff = 0 Ha: diff < 0 Pr(Z < z) = 0.0000 Ha: diff != 0 Pr(|Z| < |z|) = 0.0000 Ha: diff > 0 Pr(Z > z) = 1.0000 Moving beyond 2x2 tables: Comparing conditional probabilities is fine when there are only two comparisons and two possible outcomes for each comparison. The Chi-Square (2) test is a new technique for making comparisons more flexible. 2 is like a null hypothesis that every cell should have the frequency you would expect if the variables were independently distributed. fe is the expected count for each cell. fe = total N * unconditional row probability * unconditional column probability A test for the whole table will combine tests for fe for every cell.