Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
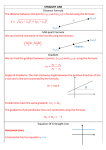
Nearest neighbour algorithm
From Wikipedia, the free encyclopedia
Jump to: navigation, search
This article is about an approximation algorithm to solve the travelling salesman
problem. For other uses, see nearest neighbor.
The nearest neighbour algorithm was one of the first algorithms used to determine a
solution to the travelling salesman problem. It quickly yields a short tour, but usually not
the optimal one.
Below is the application of nearest neighbour algorithm on TSP
These are the steps of the algorithm:
1. stand on an arbitrary vertex as current vertex.
2. find out the lightest edge connecting current vertex and an unvisited vertex V.
3. set current vertex to V.
4. mark V as visited.
5. if all the vertices in domain are visited, then terminate.
6. Go to step 2.
The sequence of the visited vertices is the output of the algorithm.
The nearest neighbour algorithm is easy to implement and executes quickly, but it can
sometimes miss shorter routes which are easily noticed with human insight, due to its
"greedy" nature. As a general guide, if the last few stages of the tour are comparable in
length to the first stages, then the tour is reasonable; if they are much greater, then it is
likely that there are much better tours. Another check is to use an algorithm such as the
lower bound algorithm to estimate if this tour is good enough.
In the worst case, the algorithm results in a tour that is much longer than the optimal tour.
To be precise, for every constant r there is an instance of the traveling salesman problem
such that the length of the tour length computed by the nearest neighbour algorithm is
greater than r times the length of the optimal tour. Moreover, for each number of cities
there is an assignment of distances between the cities for which the nearest neighbor
heuristic produces the unique worst possible tour[1].
_________________
Confidence in an association rule
The confidence of an association rule is a percentage value that shows how frequently the rule head
occurs among all the groups containing the rule body. The confidence value indicates how reliable this
rule is. The higher the value, the more often this set of items is associated together.
Thus, the confidence of a rule is the percentage equivalent of m/n, where the values are:
m
The number of groups containing the joined rule head and rule body
n
The number of groups containing the rule body
As in the case of the support factor, you can specify that only rules that achieve a certain
minimum level of confidence are included in your mining model. This ensures a definitive result,
and it is, again, one of the ways in which you can control the number of rules that are created.
You set minimum confidence as part of defining mining settings.
_________________________________
Squashing functions and reduced domains
Squashing functions are functions used to reduce the size of domain of constraint
languages. A squashing function is defined in terms of a partition of the domain and a
representative element for each set in the partition. The squashing function maps all
elements of a set in the partition to the representative element of that set. For such a
function being a squashing function it is also necessary that appying the function to all
elements of a tuple of a relation in the language produces another tuple in the relation.
The partition is assumed to contain at least a set of size greater than one.
Formally, given a partition of the domain D containing at least a set of size greater than
one, a squashing function is a function such that s(x) = s(y) for every x,y in the same
partition, and for every tuple , it holds .
For constraint problems on a constraint language has a squashing function, the domain
can be reduced via the squashing function. Indeed, every element in a set in the partition
can be replaced with the result of applying the squashing function to it, as this result is
guaranteed to satisfy at least all constraints that were satisfied by the element. As a result,
all non-representative elements can be removed from the constraint language.
Constraint languages for which no squashing function exist are called reduced languages;
equivalently, these are languages on which all reductions via squashing functions have
been applied.
[edit] The necessary condition for tractability
The necessary condition for tractability based on the universal gadget holds for reduced
languages. Such a language is tractable if the universal gadget has a solution that, when
viewed as a function in the way specified above, is either a constant function, a majority
function, an idempotent binary function, an affine function, or a semi-projection.
Datalog
From Wikipedia, the free encyclopedia
Jump to: navigation, search
Datalog is a query and rule language for deductive databases that syntactically is a subset
of Prolog. Its origins date back to the beginning of logic programming, but it became
prominent as a separate area around 1978 when Hervé Gallaire and Jack Minker
organized a workshop on logic and databases. The term Datalog was coined in the mid
1980s by a group of researchers interested in database theory.
edit] Features, limitations and extensions
Query evaluation with Datalog is sound and complete and can be done efficiently even
for large databases. Query evaluation is usually done using bottom-up strategies.
In contrast to Prolog, it
1. disallows complex terms as arguments of predicates, e.g. p(1, 2) is admissible but
not p(f1(1), 2),
2. imposes certain stratification restrictions on the use of negation and recursion, and
3. only allows range restricted variables, i.e. each variable in the conclusion of a rule
must also appear in a not negated clause in the premise of this rule.
Datalog was popular in academic database research but never succeeded in becoming part
of a commercial database system, despite its advantages (compared to other database
languages such as SQL) such as recursive queries and clean semantics. Even so, some
widely used database systems include ideas and algorithms developed for Datalog. For
example, the SQL:1999 standard includes recursive queries, and the Magic Sets
algorithm (initially developed for the faster evaluation of Datalog queries) is
implemented in IBM's DB2.
Two extensions that have been made to Datalog include an extension to allow objectoriented programming and an extension to allow disjunctions as heads of clauses. Both
extensions have major impacts on the definition of Datalog's semantics and on the
implementation of a corresponding Datalog interpreter.
[edit] Example
Example Datalog program:
parent(bill,mary).
parent(mary,john).
These two lines define two facts, i.e. things that always hold. They can be intuitively
understood as: the parent of bill is mary and the parent of mary is john.
ancestor(X,Y) :- parent(X,Y).
ancestor(X,Y) :- ancestor(X,Z),ancestor(Z,Y).
These two lines describe the rules that define the ancestor relationship. A rule consists of
two main parts separated by the :- symbol. The part to the left of this symbol is the head,
the part to the right the body of the rule. A rule is read (and can be intuitively understood)
as <head> if it is known that <body>. Uppercase letters stand for variables. Hence in the
example the first rule can be read as X is the ancestor of Y if it is known that X is the
parent of Y. And the second rule as X is the ancestor of Y if it is known that X is the
ancestor of some Z and Z is the ancestor of Y. The ordering of the clauses is irrelevant in
Datalog in contrast to Prolog which depends on the ordering of clauses for computing the
result of the query call.
Datalog distinguishes between extensional and intensional predicate symbols. While
extensional predicate symbols are only defined by facts, intensional predicate symbols
are defined only by rules. In the example above ancestor is an intensional predicate
symbol, and parent is extensional. Predicates may also be defined by facts and rules and
therefore neither be purely extensional nor intensional, but any datalog program can be
rewritten into an equivalent program without such predicate symbols with duplicate roles.
?- ancestor(bill,X).
The query above asks for all ancestors of bill and would return mary and john when
posed against a Datalog system containing the facts and rules described above.
[edit] Systems implementing Datalog
Most implementations of Datalog stem from university projects.[1] Here is a short list of
systems that are either based on Datalog or provide a Datalog interpreter:
bddbddb, an implementation of Datalog done at Stanford University. It is mainly
used to query Java bytecode including points-to analysis on large Java programs.
ConceptBase, a deductive and object-oriented database system based on a Datalog
query evaluator. It is mainly used for conceptual modeling and meta-modeling.
IRIS, an open-source Datalog engine implemented in Java. IRIS extends Datalog
with function symbols, built-in predicates, locally stratified or un-stratified logic
programs (using the well-founded semantics), unsafe rules and XML schema data
types.
DES, an open-source implementation of Datalog to be used for teaching Datalog
in courses.
XSB, a logic programming and deductive database system for Unix and Windows.
.QL, an object-oriented variant of Datalog created by Semmle.
Datalog, a lightweight deductive database system written in Lua.
SecPAL a security policy language developed by Microsoft Research[2]
DLV is a Datalog extension that supports disjunctive head clauses.
Datalog for PLT Scheme, an implementation of Datalog for PLT Scheme.
Clojure Datalog, a contributed Clojure library implementing aspects of Datalog.
[edit] See also
Answer set programming
SWRL
D (data language specification)
D4 (programming language)
IBM DB2
GX Logic Modeler
The GX Logic Modeler is a type of Diagramming software used to build and
organize … The web-based software … diagram in an Oracle database . …
1 KB (175 words) - 16:41, 15 February 2009
Logic Works
Logic Works Inc. … Their flagship product was an IDEF1X modeling and
database design tool called ER win (ERwin) whose name is formed from …
1 KB (197 words) - 04:12, 9 April 2009
F-logic
F-logic (frame logic ) is a knowledge representation - and ontology language . …
predicate calculus stands to relational database programming. …
1 KB (140 words) - 20:36, 14 January 2009
SQL Problems Requiring Cursors
problem, cursor logic can often be converted into set-based SQL queries. …
Database optimizers have little trouble dividing such queries …
6 KB (857 words) - 08:48, 15 August 2008
Helix (database)
Helix is a pioneering database management system for the Apple Macintosh
platform … the first object-based, visual programming tool, and, …
10 KB (1700 words) - 08:44, 9 November 2008
Cirrus
Microsoft's internal code name for its Microsoft Jet Database Engine … Cirrus
Logic , a semiconductor manufacturer. based in Saarbrücken , Germany …
1 KB (178 words) - 15:59, 20 May 2009
Data model (section Database model)
Typical applications of data models include database model s, … relational model
for database management based on first-order predicate logic …
36 KB (5210 words) - 17:57, 8 May 2009
Omnis Studio
developers to create Enterprise level and Web-based applications for Windows ,
Linux … The business logic and database access in such a web …
6 KB (914 words) - 15:14, 9 April 2009
Database theory
Database theory encapsulates a broad range of topics related to the study and …
first-order logic (which are … powerful language based on logic …
2 KB (310 words) - 04:13, 24 August 2008
Conceptual graph
A conceptual graph (CG) is a notation for logic based on the existential graph s of
… represent the conceptual schema s used in database systems. …
5 KB (707 words) - 09:42, 20 March 2009
Separation of concerns
Layered designs in information systems are also often based on … presentation
layer, business logic layer, data access layer, database …
9 KB (1171 words) - 01:15, 2 May 2009
Closed world assumption (section Formalization in logic)
and 2) when the knowledge base is known to be incomplete but a " … example, if
a database contains the … article on Formal Logic is usually …
7 KB (1036 words) - 01:47, 1 January 2009
Database management system (redirect Data base management system)
A database management system (DBMS) is computer software that manages
database s. … pdf The origins of the data base concept: early DBMS …
26 KB (3480 words) - 00:31, 19 May 2009
Knowledge engineering
including database s, data mining , expert system s, decision … Knowledge
engineering is also related to mathematical logic , as well as …
6 KB (784 words) - 17:02, 20 May 2009
Dying to Win: The Strategic Logic of Suicide Terrorism
Dying to Win: The Strategic Logic of Suicide Terrorism (2005; ISBN 1-40006317-5) is … It is based on a database he has compiled at the …
13 KB (2010 words) - 05:46, 19 September 2008
RM
Relational Model , a database model based on predicate logic and set theory.
Resource Management , a service in Asynchronous Transfer Mode …
3 KB (430 words) - 16:16, 16 May 2009
QuickObjects (section Supported Database Servers)
Framework with a built in framework for business logic and validation. … fully
supported and can be used against any of the supported databases. …
9 KB (1223 words) - 17:57, 26 November 2008
________________________-----
Gradient descent
From Wikipedia, the free encyclopedia
Jump to: navigation, search
For the analytical method called "steepest descent", see Method of steepest descent.
Gradient descent is a first-order optimization algorithm. To find a local minimum of a
function using gradient descent, one takes steps proportional to the negative of the
gradient (or the approximate gradient) of the function at the current point. If instead one
takes steps proportional to the gradient, one approaches a local maximum of that
function; the procedure is then known as gradient ascent.
Gradient descent is also known as steepest descent, or the method of steepest descent.
When known as the latter, gradient descent should not be confused with the method of
steepest descent for approximating integrals.
edit] Description
Gradient descent is based on the observation that if the real-valued function
is
defined and differentiable in a neighborhood of a point , then
decreases fastest if
one goes from in the direction of the negative gradient of F at ,
. It follows
that, if
for γ > 0 a small enough number, then
. With this observation in mind,
one starts with a guess for a local minimum of F, and considers the sequence
such that
We have
so hopefully the sequence
converges to the desired local minimum. Note that the
value of the step size γ is allowed to change at every
iteration.
This process is illustrated in the picture to the right. Here F is assumed to be defined on
the plane, and that its graph has a bowl shape. The blue curves are the contour lines, that
is, the regions on which the value of F is constant. A red arrow originating at a point
shows the direction of the negative gradient at that point. Note that the (negative)
gradient at a point is orthogonal to the contour line going through that point. We see that
gradient descent leads us to the bottom of the bowl, that is, to the point where the value of
the function F is minimal.
[edit] Examples
Gradient descent has problems with pathological functions such as the Rosenbrock
function shown here. The Rosenbrock function has a narrow curved valley which
contains the minimum. The bottom of the valley is very flat. Because of the curved flat
valley the optimization is zig-zagging slowly with small stepsizes towards the minimum.
The gradient ascent method applied to
[edit] Comments
Gradient descent works in spaces of any number of dimensions, even in infinitedimensional ones. In the latter case the search space is typically a function space, and one
calculates the Gâteaux derivative of the functional to be minimized to determine the
descent direction.
Two weaknesses of gradient descent are:
1. The algorithm can take many iterations to converge towards a local minimum, if
the curvature in different directions is very different.
2. Finding the optimal γ per step can be time-consuming. Conversely, using a fixed γ
can yield poor results. Methods based on Newton's method and inversion of the
Hessian using conjugate gradient techniques are often a better alternative.
A more powerful algorithm is given by the BFGS method which consists in calculating
on every step a matrix by which the gradient vector is multiplied to go into a "better"
direction, combined with a more sophisticated line search algorithm, to find the "best"
value of γ.
Gradient descent is in fact Euler's method for solving ordinary differential equations
applied to a gradient flow. As the goal is to find the minimum, not the flow line, the error
in finite methods is less significant.
[edit] A computational example
The gradient descent algorithm is applied to find a local minimum of the function f(x)=x43x3+2 , with derivative f'(x)=4x3-9x2. Here is an implementation in the C programming
language.
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
int main ()
{
// From calculation, we expect that the local minimum occurs at
x=9/4
// The algorithm starts at x=6
double xOld = 0;
double xNew = 6;
double eps = 0.01;
double precision =
while (fabs(xNew {
xOld = xNew;
xNew = xNew }
// step size
0.00001;
xOld) > precision)
eps*(4*xNew*xNew*xNew-9*xNew*xNew);
printf ("Local minimum occurs at %lg\n", xNew);
}
With this precision, the algorithm converges to a local minimum of 2.24996 in 70
iterations.
A more robust implementation of the algorithm would also check whether the function
value indeed decreases at every iteration and would make the step size smaller otherwise.
One can also use an adaptive step size which may make the algorithm converge faster.
Mordecai Avriel (2003). Nonlinear Programming: Analysis and Methods. Dover
Publishing. ISBN 0-486-43227-0.
Jan A. Snyman (2005). Practical Mathematical Optimization: An Introduction to
Basic Optimization Theory and Classical and New Gradient-Based Algorithms.
Springer Publishing. ISBN 0-387-24348-8
________________________
Backpropagation
From Wikipedia, the free encyclopedia
(Redirected from Back propagation)
Jump to: navigation, search
This article is about the computer algorithm. For the biological process, see Neural
backpropagation.
Backpropagation, or propagation of error, is a common method of teaching artificial
neural networks how to perform a given task. It was first described by Paul Werbos in
1974, but it wasn't until 1986, through the work of David E. Rumelhart, Geoffrey E.
Hinton and Ronald J. Williams, that it gained recognition, and it led to a “renaissance” in
the field of artificial neural network research.
It is a supervised learning method, and is an implementation of the Delta rule. It requires
a teacher that knows, or can calculate, the desired output for any given input. It is most
useful for feed-forward networks (networks that have no feedback, or simply, that have
no connections that loop). The term is an abbreviation for "backwards propagation of
errors". Backpropagation requires that the activation function used by the artificial
neurons (or "nodes") is differentiable.
[edit] Summary
Summary of the backpropagation technique:
1. Present a training sample to the neural network.
2. Compare the network's output to the desired output from that sample. Calculate
the error in each output neuron.
3. For each neuron, calculate what the output should have been, and a scaling factor,
how much lower or higher the output must be adjusted to match the desired output.
This is the local error.
4. Adjust the weights of each neuron to lower the local error.
5. Assign "blame" for the local error to neurons at the previous level, giving greater
responsibility to neurons connected by stronger weights.
6. Repeat from step 3 on the neurons at the previous level, using each one's "blame"
as its error.
[edit] Algorithm
Actual algorithm for a 3-layer network (only one hidden layer):
Initialize the weights in the network (often randomly)
Do
For each example e in the training set
O = neural-net-output(network, e) ; forward pass
T = teacher output for e
Calculate error (T - O) at the output units
Compute delta_wi for all weights from hidden layer to
output layer ; backward pass
Compute delta_wi for all weights from input layer to
hidden layer ; backward pass continued
Update the weights in the network
Until all examples classified correctly or stopping criterion
satisfied
Return the network
As the algorithm's name implies, the errors (and therefore the learning) propagate
backwards from the output nodes to the inner nodes. So technically speaking,
backpropagation is used to calculate the gradient of the error of the network with respect
to the network's modifiable weights. This gradient is almost always then used in a simple
stochastic gradient descent algorithm to find weights that minimize the error. Often the
term "backpropagation" is used in a more general sense, to refer to the entire procedure
encompassing both the calculation of the gradient and its use in stochastic gradient
descent. Backpropagation usually allows quick convergence on satisfactory local minima
for error in the kind of networks to which it is suited.
It is important to note that backpropagation networks are necessarily multilayer
perceptrons (usually with one input, one hidden, and one output layer). In order for the
hidden layer to serve any useful function, multilayer networks must have non-linear
activation functions for the multiple layers: a multilayer network using only linear
activiation functions is equivalent to some single layer, linear network. Non-linear
activation functions that are commonly used include the logistic function, the softmax
function, and the gaussian function.
The backpropagation algorithm for calculating a gradient has been rediscovered a number
of times, and is a special case of a more general technique called automatic
differentiation in the reverse accumulation mode.
It is also closely related to the Gauss–Newton algorithm, and is also part of continuing
research in neural backpropagation.
_____________________________
Naive Bayes classifier
From Wikipedia, the free encyclopedia
(Redirected from Naive bayes)
Jump to: navigation, search
This article includes a list of references or external links, but its sources remain
unclear because it has insufficient inline citations. Please help to improve this
article by introducing more precise citations where appropriate. (May 2009)
A naive Bayes classifier is a term in Bayesian statistics dealing with a simple
probabilistic classifier based on applying Bayes' theorem with strong (naive)
independence assumptions. A more descriptive term for the underlying probability model
would be "independent feature model".
In simple terms, a naive Bayes classifier assumes that the presence (or absence) of a
particular feature of a class is unrelated to the presence (or absence) of any other feature.
For example, a fruit may be considered to be an apple if it is red, round, and about 4" in
diameter. Even though these features depend on the existence of the other features, a
naive Bayes classifier considers all of these properties to independently contribute to the
probability that this fruit is an apple.
Depending on the precise nature of the probability model, naive Bayes classifiers can be
trained very efficiently in a supervised learning setting. In many practical applications,
parameter estimation for naive Bayes models uses the method of maximum likelihood; in
other words, one can work with the naive Bayes model without believing in Bayesian
probability or using any Bayesian methods.
In spite of their naive design and apparently over-simplified assumptions, naive Bayes
classifiers often work much better in many complex real-world situations than one might
expect. Recently, careful analysis of the Bayesian classification problem has shown that
there are some theoretical reasons for the apparently unreasonable efficacy of naive
Bayes classifiers. [1] An advantage of the naive Bayes classifier is that it requires a small
amount of training data to estimate the parameters (means and variances of the variables)
necessary for classification. Because independent variables are assumed, only the
variances of the variables for each class need to be determined and not the entire
covariance matrix.
[edit] The naive Bayes probabilistic model
Abstractly, the probability model for a classifier is a conditional model
over a dependent class variable C with a small number of outcomes or classes,
conditional on several feature variables F1 through Fn. The problem is that if the number
of features n is large or when a feature can take on a large number of values, then basing
such a model on probability tables is infeasible. We therefore reformulate the model to
make it more tractable.
Using Bayes' theorem, we write
In plain English the above equation can be written as
In practice we are only interested in the numerator of that fraction, since the denominator
does not depend on C and the values of the features Fi are given, so that the denominator
is effectively constant. The numerator is equivalent to the joint probability model
which can be rewritten as follows, using repeated applications of the definition of
conditional probability:
and so forth. Now the "naive" conditional independence assumptions come into play:
assume that each feature Fi is conditionally independent of every other feature Fj for
. This means that
and so the joint model can be expressed as
This means that under the above independence assumptions, the conditional distribution
over the class variable C can be expressed like this:
where Z is a scaling factor dependent only on
, i.e., a constant if the values
of the feature variables are known.
Models of this form are much more manageable, since they factor into a so-called class
prior p(C) and independent probability distributions
. If there are k classes and
if a model for p(Fi) can be expressed in terms of r parameters, then the corresponding
naive Bayes model has (k − 1) + n r k parameters. In practice, often k = 2 (binary
classification) and r = 1 (Bernoulli variables as features) are common, and so the total
number of parameters of the naive Bayes model is 2n + 1, where n is the number of
binary features used for prediction.
[edit] Parameter estimation
All model parameters (i.e., class priors and feature probability distributions) can be
approximated with relative frequencies from the training set. These are maximum
likelihood estimates of the probabilities. Non-discrete features need to be discretized first.
Discretization can be unsupervised (ad-hoc selection of bins) or supervised (binning
guided by information in training data).
If a given class and feature value never occur together in the training set then the
frequency-based probability estimate will be zero. This is problematic since it will wipe
out all information in the other probabilities when they are multiplied. It is therefore often
desirable to incorporate a small-sample correction in all probability estimates such that no
probability is ever set to be exactly zero.
[edit] Constructing a classifier from the probability model
The discussion so far has derived the independent feature model, that is, the naive Bayes
probability model. The naive Bayes classifier combines this model with a decision rule.
One common rule is to pick the hypothesis that is most probable; this is known as the
maximum a posteriori or MAP decision rule. The corresponding classifier is the function
classify defined as follows:
[edit] Discussion
One should notice that the independence assumption may lead to some unexpected results
in the calculation of the posterior probability. In some circumstances, when there is a
dependency between observations, the value computed above may be greater than one
thereby contradicting the second axiom of probability which requires all probability
values to be less than or equal to one.
Despite the fact that the far-reaching independence assumptions are often inaccurate, the
naive Bayes classifier has several properties that make it surprisingly useful in practice.
In particular, the decoupling of the class conditional feature distributions means that each
distribution can be independently estimated as a one dimensional distribution. This in
turn helps to alleviate problems stemming from the curse of dimensionality, such as the
need for data sets that scale exponentially with the number of features. Like all
probabilistic classifiers under the MAP decision rule, it arrives at the correct
classification as long as the correct class is more probable than any other class; hence
class probabilities do not have to be estimated very well. In other words, the overall
classifier is robust enough to ignore serious deficiencies in its underlying naive
probability model. Other reasons for the observed success of the naive Bayes classifier
are discussed in the literature cited below.
[edit] Example: document classification
Here is a worked example of naive Bayesian classification to the document classification
problem. Consider the problem of classifying documents by their content, for example
into spam and non-spam E-mails. Imagine that documents are drawn from a number of
classes of documents which can be modelled as sets of words where the (independent)
probability that the i-th word of a given document occurs in a document from class C can
be written as
(For this treatment, we simplify things further by assuming that words are randomly
distributed in the document - that is, words are not dependent on the length of the
document, position within the document with relation to other words, or other documentcontext.)
Then the probability of a given document D, given a class C, is
The question that we desire to answer is: "what is the probability that a given document
D belongs to a given class C?" In other words, what is
Now by definition
?
and
Bayes' theorem manipulates these into a statement of probability in terms of likelihood.
Assume for the moment that there are only two mutually exclusive classes, S and ¬S (e.g.
spam and not spam), such that every element (email) is in either one or the other;
and
Using the Bayesian result above, we can write:
Dividing one by the other gives:
Which can be re-factored as:
Thus, the probability ratio p(S | D) / p(¬S | D) can be expressed in terms of a series of
likelihood ratios. The actual probability p(S | D) can be easily computed from log (p(S |
D) / p(¬S | D)) based on the observation that p(S | D) + p(¬S | D) = 1.
Taking the logarithm of all these ratios, we have:
(This technique of "log-likelihood ratios" is a common technique in statistics. In the case
of two mutually exclusive alternatives (such as this example), the conversion of a loglikelihood ratio to a probability takes the form of a sigmoid curve: see logit for details.)
Finally, the document can be classified as follows. It is spam if
(i.e. that
), otherwise it is not spam.
______________________
In statistics, the likelihood function (often simply the likelihood) is a function of the
parameters of a statistical model that plays a key role in statistical inference. In nontechnical usage, "likelihood" is a synonym for "probability", but throughout this article
only the technical definition is used. Informally, if "probability" allows us to predict
unknown outcomes based on known parameters, then "likelihood" allows us to estimate
unknown parameters based on known outcomes.
In a sense, likelihood works backwards from probability: given parameter B, we use the
conditional probability P(A|B) to reason about outcome A, and given outcome A, we use
the likelihood function L(B|A) to reason about parameter B. This mode of reasoning is
formalized in Bayes' theorem:
A likelihood function is a conditional probability function considered as a function of its
second argument with its first argument held fixed, thus:
and also any other function proportional to such a function. That is, the likelihood
function for B is the equivalence class of functions
for any constant of proportionality α > 0. The numerical value L(b | A) alone is
immaterial; all that matters are likelihood ratios of the form
which are invariant with respect to the constant of proportionality.
A. W. F. Edwards defined support as the natural logarithm of the likelihood ratio, and
the support function as the natural logarithm of the likelihood function.[1] There is
potential for confusion with the mathematical meaning of 'support', however, and this
terminology is not widely used outside Edwards' main applied field of phylogenetics.
For more about making inferences via likelihood functions, see also the method of
maximum likelihood, and likelihood-ratio testing.
_________________________________
Entropy is a concept applied across physics, information theory, mathematics and other
branches of science and engineering. The following definition is shared across all these
fields:
where S is the conventional symbol for entropy. The sum runs over all microstates
consistent with the given macrostate and is the probability of the ith microstate. The
constant of proportionality k depends on what units are chosen to measure S. When SI
units are chosen, we have k = kB = Boltzmann's constant = 1.38066×10−23 J K−1. If units
of bits are chosen, then k = 1/ln(2) so that
.
Entropy is central to the second law of thermodynamics. The second law in conjunction
with the fundamental thermodynamic relation places limits on a system's ability to do
useful work.[3][4]
The second law can also be used to predict whether a physical process will proceed
spontaneously. Spontaneous changes in isolated systems occur with an increase in
entropy.
The word "entropy" is derived from the Greek εντροπία "a turning towards" (εν- "in" +
τροπή "a turning").[5]