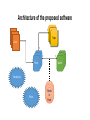
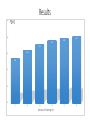
Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
"St. Petersburg National Research University of Information Technologies, Mechanics and Optics" Department of "Secure Information Technology" Identification of the authors of short messages portals on the Internet using the methods of mathematical linguistics. Specialty 05.13.19 "Methods and systems of information protection, information security" Postgraduate: Sukhoparov M.E. Supervisor: doctor of engineering science, Lebedev I.S. Purpose and objectives The goal - a study of methods to identificate users. Objectives: study and development of scientific-methodical system of identification of authorship of textual information creation of the program layout, based on the proposed approach assessment of the performance and efficiency of the developed prototyping implementation Prospective directions of research The use of naive Bayes classifier Analysis based on the N - grams Analysis based on latent Dirichlet allocation Architecture of the proposed software 1 Users Topic 1 * * * * Posts Words Vocabulary Filters Words in Posts Naive Bayes classifier Bayes theorem: 𝑃 𝑑 𝑐 𝑃(𝑐) 𝑃 𝑐𝑑 = 𝑃(𝑑) 𝑃 𝑐 𝑑 - probability that document 𝑑 belongs to the class 𝑐 ; 𝑃 𝑑 𝑐 - probability of finding document 𝑑 of any documents class 𝑐; 𝑃(𝑐) - unconditional probability of finding a document of class 𝑐 in the case of documents; 𝑃(𝑑) - unconditional probability of a document 𝑑 in the case of documents. Naive Bayes classifier Maximum a posteriori estimation: 𝑐𝑚𝑎𝑝 = argmax 𝑃 𝑑 𝑐 𝑃(𝑐) 𝑃(𝑑) 𝑐∈𝐶 𝑛 𝑃 𝑑 𝑐 ≈ 𝑃 𝜔1 𝑐 𝑃 𝜔2 𝑐 … 𝑃 𝜔𝑛 𝑐 ≈ 𝑃(𝜔𝑖 |𝑐) 𝑖 𝑛 𝑐𝑚𝑎𝑝 = argmax 𝑃(𝑐) 𝑐∈𝐶 𝑃(𝜔𝑖 |𝑐) 𝑖 Naive Bayes classifier The problem of arithmetic overflow: 𝑛 𝑐𝑚𝑎𝑝 = argmax log 𝑃(𝑐) + 𝑐∈𝐶 log 𝑃(𝜔𝑖 |𝑐) 𝑖 Estimation of parameters of the Bayes model: 𝐷𝑐 , 𝐷 •𝑃 𝑐 = where 𝐷𝑐 - number of documents belong to class 𝑐, 𝐷 total number of documents in the training set; • 𝑃 𝜔𝑖 𝑐 = 𝑊𝑖𝑐 , 𝑊 𝑖′ ∈𝑉 𝑖′ 𝑐 where 𝑊𝑖𝑐 - number of times as the i-th word appears in the documents of class 𝑐, 𝑉 - dictionary of a set of documents (a list of all unique words). Naive Bayes classifier The problem of unknown words: 𝑊𝑖𝑐 + 1 𝑊𝑖𝑐 + 1 𝑃 𝜔𝑖 𝑐 = = 𝑉 + 𝑖 ′ ∈𝑉 𝑊𝑖 ′ 𝑐 𝑖 ′ ∈𝑉 (𝑊𝑖 ′ 𝑐 +1) The final view of the formula: 𝑐𝑚𝑎𝑝 𝐷𝑐 = argmax log + 𝐷 𝑐∈𝐶 𝑛 𝑖 𝑊𝑖𝑐 + 1 log 𝑉 + 𝑖 ′ ∈𝑉 𝑊𝑖 ′ 𝑐 Naive Bayes classifier Statistics used in the classification stage: relative frequencies of the classes in the case of documents; total number of words in each document class; the relative frequencies of words within each class; dictionary size (amount of unique words in training set). 𝐷𝑐 log + 𝐷 𝑛 𝑖𝜖𝑄 𝑊𝑖𝑐 + 1 log 𝑉 + 𝐿𝑐 𝐷𝑐 - number of documents belong to class 𝑐; 𝐷 - total number of documents in the training set; 𝑉 - dictionary of a set of documents (a list of all unique words); 𝐿𝑐 - the total number of words in documents of class c in the training set; 𝑊𝑖𝑐 - number of times as the i-th word appears in the documents of class 𝑐; 𝑄 - set of words of classified document (including repeats). Results 1.00 𝑃 𝑐𝑑 0.80 0.79 0.81 0.76 0.72 0.64 0.60 0.54 0.40 0.20 0.00 75 100 125 150 Amount of training set 175 200 Conclusions The implementation of the proposed solutions will identify the authors of short message forums and blogs on the Internet at various PR - actions to combat and control the formation and manipulation of public opinion and other manifestations of astroterfing.