Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
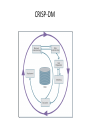
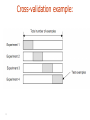
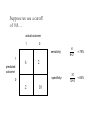
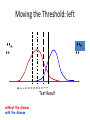
Model Evaluation CRISP-DM CRISP-DM Phases • Business Understanding – Initial phase – Focuses on: • Understanding the project objectives and requirements from a business perspective • Converting this knowledge into a data mining problem definition, and a preliminary plan designed to achieve the objectives • Data Understanding – Starts with an initial data collection – Proceeds with activities aimed at: • • • • Getting familiar with the data Identifying data quality problems Discovering first insights into the data Detecting interesting subsets to form hypotheses for hidden information CRISP-DM Phases • Data Preparation – Covers all activities to construct the final dataset (data that will be fed into the modeling tool(s)) from the initial raw data – Data preparation tasks are likely to be performed multiple times, and not in any prescribed order – Tasks include table, record, and attribute selection, as well as transformation and cleaning of data for modeling tools • Modeling – Various modeling techniques are selected and applied, and their parameters are calibrated to optimal values – Typically, there are several techniques for the same data mining problem type – Some techniques have specific requirements on the form of data, therefore, stepping back to the data preparation phase is often needed CRISP-DM Phases • Evaluation – At this stage, a model (or models) that appears to have high quality, from a data analysis perspective, has been built – Before proceeding to final deployment of the model, it is important to more thoroughly evaluate the model, and review the steps executed to construct the model, to be certain it properly achieves the business objectives – A key objective is to determine if there is some important business issue that has not been sufficiently considered – At the end of this phase, a decision on the use of the data mining results should be reached CRISP-DM Phases • Deployment – Creation of the model is generally not the end of the project – Even if the purpose of the model is to increase knowledge of the data, the knowledge gained will need to be organized and presented in a way that the customer can use it – Depending on the requirements, the deployment phase can be as simple as generating a report or as complex as implementing a repeatable data mining process – In many cases it will be the customer, not the data analyst, who will carry out the deployment steps – However, even if the analyst will not carry out the deployment effort it is important for the customer to understand up front what actions will need to be carried out in order to actually make use of the created models Evaluating Classification Systems • Two issues – What evaluation measure should we use? – How do we ensure reliability of our model? How do we ensure reliability of our model? EVALUATION How do we ensure reliability? • Heavily dependent on training Data Partitioning • Randomly partition data into training and test set • Training set – data used to train/build the model. – Estimate parameters (e.g., for a linear regression), build decision tree, build artificial network, etc. • Test set – a set of examples not used for model induction. The model’s performance is evaluated on unseen data. Aka out-of-sample data. • Generalization Error: Model error on the test data. Set of training examples Set of test examples Complexity and Generalization Score Function e.g., squared error Optimal model complexity Stest(q) Strain(q) Complexity = degrees of freedom in the model (e.g., number of variables) Holding out data • The holdout method reserves a certain amount for testing and uses the remainder for training – Usually: one third for testing, the rest for training • For “unbalanced” datasets, random samples might not be representative – Few or none instances of some classes • Stratified sample: – Make sure that each class is represented with approximately equal proportions in both subsets 12 Repeated holdout method • Holdout estimate can be made more reliable by repeating the process with different subsamples – In each iteration, a certain proportion is randomly selected for training (possibly with stratification) – The error rates on the different iterations are averaged to yield an overall error rate • This is called the repeated holdout method 13 Cross-validation • Most popular and effective type of repeated holdout is cross-validation • Cross-validation avoids overlapping test sets – First step: data is split into k subsets of equal size – Second step: each subset in turn is used for testing and the remainder for training • This is called k-fold cross-validation • Often the subsets are stratified before the crossvalidation is performed 14 Cross-validation example: 15 15 More on cross-validation • Standard data-mining method for evaluation: stratified ten-fold cross-validation • Why ten? Extensive experiments have shown that this is the best choice to get an accurate estimate • Stratification reduces the estimate’s variance • Even better: repeated stratified cross-validation – E.g. ten-fold cross-validation is repeated ten times and results are averaged (reduces the sampling variance) • Error estimate is the mean across all repetitions 16 Leave-One-Out cross-validation • Leave-One-Out: a particular form of cross-validation: – – • • • 17 Set number of folds to number of training instances I.e., for n training instances, build classifier n times Makes best use of the data Involves no random subsampling Computationally expensive, but good performance Leave-One-Out-CV and stratification • Disadvantage of Leave-One-Out-CV: stratification is not possible – • Extreme example: random dataset split equally into two classes – – – 18 It guarantees a non-stratified sample because there is only one instance in the test set! Best model predicts majority class 50% accuracy on fresh data Leave-One-Out-CV estimate is 100% error! Three way data splits • One problem with CV is since data is being used jointly to fit model and estimate error, the error could be biased downward. • If the goal is a real estimate of error (as opposed to which model is best), you may want a three way split: – Training set: examples used for learning – Validation set: used to tune parameters – Test set: never used in the model fitting process, used at the end for unbiased estimate of hold out error The Bootstrap • The Statistician Brad Efron proposed a very simple and clever idea for mechanically estimating confidence intervals: The Bootstrap • The idea is to take multiple resamples of your original dataset. • Compute the statistic of interest on each resample • you thereby estimate the distribution of this statistic! Sampling with Replacement • Draw a data point at random from the data set. • Then throw it back in • Draw a second data point. • Then throw it back in… • Keep going until we’ve got 1000 data points. • You might call this a “pseudo” data set. • This is not merely re-sorting the data. • Some of the original data points will appear more than once; others won’t appear at all. Sampling with Replacement • In fact, there is a chance of (1-1/1000)1000 ≈ 1/e ≈ .368 that any one of the original data points won’t appear at all if we sample with replacement 1000 times. any data point is included with Prob ≈ .632 • Intuitively, we treat the original sample as the “true population in the sky”. • Each resample simulates the process of taking a sample from the “true” distribution. Bootstrapping & Validation • This is interesting in its own right. • But bootstrapping also relates back to model validation. • Along the lines of cross-validation. • You can fit models on bootstrap resamples of your data. • For each resample, test the model on the ≈ .368 of the data not in your resample. • Will be biased, but corrections are available. • Get a spectrum of ROC curves. Closing Thoughts • The “cross-validation” approach has several nice features: – Relies on the data, not likelihood theory, etc. – Comports nicely with the lift curve concept. – Allows model validation that has both business & statistical meaning. – Is generic can be used to compare models generated from competing techniques… – … or even pre-existing models – Can be performed on different sub-segments of the data – Is very intuitive, easily grasped. Closing Thoughts • Bootstrapping has a family resemblance to cross- validation: – Use the data to estimate features of a statistic or a model that we previously relied on statistical theory to give us. – Classic examples of the “data mining” (in the non-pejorative sense of the term!) mindset: • Leverage modern computers to “do it yourself” rather than look up a formula in a book! • Generic tools that can be used creatively. – Can be used to estimate model bias & variance. – Can be used to estimate (simulate) distributional characteristics of very difficult statistics. – Ideal for many actuarial applications. What evaluation measure should we use? METRICS Evaluation of Classification actual outcome 1 0 – Not always the best choice • Assume 1% fraud, • model predicts no fraud • What is the accuracy? 1 a b 0 c d predicted outcome Accuracy = (a+d) / (a+b+c+d) Actual Class Predicted Class Fraud No Fraud Fraud 0 0 No Fraud 10 990 Evaluation of Classification Other options: – recall or sensitivity (how many of those that are really positive did you predict?): • a/(a+c) – precision (how many of those predicted positive really are?) • a/(a+b) actual outcome Precision and recall are always in tension 1 0 1 a b 0 c d – Increasing one tends to decrease another predicted outcome Evaluation of Classification Yet another option: – recall or sensitivity (how many of the positives did you get right?): • a/(a+c) – Specificity (how many of the negatives did you get right?) • d/(b+d) actual outcome Sensitivity and specificity have the same tension Different fields use different metrics 1 0 1 a b 0 c d predicted outcome Evaluation for a Thresholded Response • Many classification models output probabilities • These probabilities get thresholded to make a prediction. • Classification accuracy depends on the threshold – good models give low probabilities to Y=0 and high probabilities to Y=1. predicted probabilities Suppose we use a cutoff of 0.5… actual outcome 1 1 predicted outcome 0 8 3 0 9 0 Test Data Suppose we use a cutoff of 0.5… actual outcome 1 0 sensitivity: 1 predicted outcome 8 = 100% 3 specificity: 0 0 8 8+0 9 9+3 = 75% 9 we want both of these to be high Suppose we use a cutoff of 0.8… actual outcome 1 0 sensitivity: 1 predicted outcome 6 = 75% 10 10+2 = 83% 2 specificity: 0 2 6 6+2 10 • Note there are 20 possible thresholds • Plotting all values of sensitivity vs. specificity gives a sense of model performance by seeing the tradeoff with different thresholds • Note if threshold = minimum actual outcome c=d=0 so sens=1; spec=0 • 0 a b c d If threshold = maximum a=b=0 so sens=0; spec=1 • 1 1 If model is perfect sens=1; spec=1 0 ROC curve plots sensitivity vs. (1-specificity) – also known as false positive rate Always goes from (0,0) to (1,1) The more area in the upper left, the better Random model is on the diagonal “Area under the curve” (AUC) is a common measure of predictive performance ROC CURVES Receiver Operating Characteristic curve • ROC curves were developed in the 1950's as a by-product of research into making sense of radio signals contaminated by noise. More recently it's become clear that they are remarkably useful in decision-making. • They are a performance graphing method. • True positive and False positive fractions are plotted as we move the dividing threshold. They look like: • ROC graphs are two-dimensional graphs in which TP rate is plotted on the Y axis and FP rate is plotted on the X axis. • An ROC graph depicts relative tradeoffs between benefits (true positives) and costs (false positives). • Figure shows an ROC graph with five classifiers labeled A through E. • A discrete classier is one that outputs only a class label. • Each discrete classier produces an (fp rate, tp rate) pair corresponding to a single point in ROC space. • Classifiers in figure are all discrete classifiers. ROC Space Several Points in ROC Space • Lower left point (0, 0) represents the strategy of never issuing a positive classification; – such a classier commits no false positive errors but also gains no true positives. • Upper right corner (1, 1) represents the opposite strategy, of unconditionally issuing positive classifications. • Point (0, 1) represents perfect classification. – D's performance is perfect as shown. • Informally, one point in ROC space is better than another if it is to the northwest of the first – tp rate is higher, fp rate is lower, or both. Specific Example Pts without the disease Pts with disease Test Result Threshold Call these patients “negative” Call these patients “positive” Test Result Some definitions ... Call these patients “negative” Call these patients “positive” True Positives Test Result without the disease with the disease Call these patients “negative” Call these patients “positive” Test Result without the disease with the disease False Positives Call these patients “negative” Call these patients “positive” True negatives Test Result without the disease with the disease Call these patients “negative” Call these patients “positive” False negatives Test Result without the disease with the disease Moving the Threshold: right ‘‘’’ ‘‘+ ’’ Test Result without the disease with the disease Moving the Threshold: left ‘‘’’ ‘‘+ ’’ Test Result without the disease with the disease ROC curve True Positive Rate (sensitivity) 100% 0% 0% False Positive Rate (1-specificity) 100% ROC curve comparison A poor test: A good test: 100% True Positive Rate True Positive Rate 100% 0% 0% 0% 100% False Positive Rate 0 % 100% False Positive Rate ROC curve extremes Best Test: Worst test: 100% True Positive Rate True Positive Rate 100% 0 % 0 % 0 % False Positive Rate 100 % The distributions don’t overlap at all 0 % False Positive Rate 100 % The distributions overlap completely How to Construct ROC Curve for one Classifier • • • • Ppos 0.99 0.98 0.7 0.6 0.43 Sort the instances according to their Ppos. Move a threshold on the sorted instances. For each threshold define a classifier with confusion matrix. Plot the TPr and FPr rates of the classfiers. True Class pos pos neg pos neg Predicted True pos neg pos 2 1 neg 1 1 Creating an ROC Curve • A classifier produces a single ROC point. • If the classifier has a “sensitivity” parameter, varying it produces a series of ROC points (confusion matrices). • Alternatively, if the classifier is produced by a learning algorithm, a series of ROC points can be generated by varying the class ratio in the training set. ROC for one Classifier Good separation between the classes, convex curve. ROC for one Classifier Reasonable separation between the classes, mostly convex. ROC for one Classifier Fairly poor separation between the classes, mostly convex. ROC for one Classifier Poor separation between the classes, large and small concavities. ROC for one Classifier Random performance. The AUC Metric • The area under ROC curve (AUC) assesses the ranking in terms of separation of the classes. • AUC estimates that randomly chosen positive instance will be ranked before randomly chosen negative instances. Comparing Models • Highest AUC wins • But pay attention to ‘Occam’s Razor’ – ‘the best theory is the smallest one that describes all the facts’ – Also known as the ‘parsimony principle’ – If two models are similar, pick the simpler one