Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
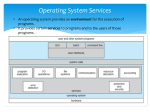
DISK SCHEDULING Overview Over the past 30 years, the increase in the speed of processors and main memory has far outstripped that of disk access, with processor and main memory speeds increasing by about two orders of magnitude compared to one order of magnitude for disk. The result is that disks are currently at least four orders of magnitude slower than main memory. This gap is expected to continue into the foreseeable future. Thus, the performance of disk storage subsystems is of vital concern, and much research has gone into schemes for improving that performance. Disk Performance Parameters When the disk drive is operating, the disk is rotating at constant speed. To read or write, the head must be positioned at desired track and at the beginning of the desired sector on the track. Track selection involves moving the head in a moveable-head system. On a moveable-head system, the time it takes to position the head at the track is known as seek time. Once the track is selected, the desired controller waits until the appropriate sector rotates to line up with the head. The time it takes for the beginning of the sector to reach the head is known as rotational delay, or rotational latency. The sum of the seek time if any and the rotational delay is the access time, the time it takes to get into position to read or write. Once the head is in position, the read or write operation is then performed as the sector moves under the head; this is the data transfer position of the operation. Seek Time o o o Seek time is the time required to move the disk arm to the required track. The seek time consists of two key components: the initial startup time and the time taken to traverse the cylinders that have to be crossed once the access arm is up to speed. The seek time can be approximate with the following formula: Ts = m * n + s Where, Ts = estimated seek time n = number of tracks traversed m = constant that depends on the disk drive s = startup time Disk Scheduling One of the responsibilities of the operating system is to use the hardware efficiently. For the disk drives, this means having a fast access time and disk bandwidth. The access time has two major components: 1. the seek time and 2. the rotational latency The disk bandwidth is the total number of bytes transferred, divided by the total time between the first request for service and the completion of the last transfer. We can improve both the access time and the bandwidth by scheduling the servicing of disk I/O requests in a good order. Whenever a process needs I/O to or from the disk, it issues a system call to the operating system. The request specifies several pieces of information: 1. 2. 3. 4. Whether this operation is input or output What the disk address for the transfer is What the memory address for the transfer is What the number of bytes to be transferred is If the desired disk drive and controller are available, the request can be serviced immediately. If the drive or controller is busy, any new requests for service will need to be placed on the queue of pending requests for that drive. First-Come First-Served Scheduling o o The simplest form of disk scheduling is, of course, FCFS. This algorithm is intrinsically fair, but it generally does not provide the fastest service. Shortest-Seek-Time-First Scheduling o o o o o o It seems reasonable to service all the requests close to the current head positions, before moving the head far away to service other requests. This assumption is the basis for the shortest-seek-time-first (SSTF) algorithm. The SSTF algorithm selects the request with the minimum seek time from the current head position. Since the seek time increases with the number of cylinders traversed by the head SSTF chooses the pending request closest to current head position. SSTF scheduling is essentially a form of SJF scheduling, and, like SJF scheduling, it may cause starvation of some requests. That request may arrive at any time. SCAN Scheduling o o o o o In the SCAN algorithm, the disk arm starts at one end of the disk, and moves toward the other end of the disk. At the other end, the direction of head movement is reversed, and servicing continues. The head continuously scans back and forth across the disk. If the request arrives in the queue just in front of the head, it will be serviced almost immediately, a request arriving just behind the head will have to wait until the arm moves to the end of the disk, reverses direction, and comes back. The SCAN algorithm is sometimes called the Elevator algorithm, since the disk arm behaves just like an elevator in a building, first servicing all the requests going up, and then reversing to service requests the other way. C-SCAN Scheduling o o o o Circular SCAN (C-SCAN) is a variant of SCAN that is designed to provide a more uniform wait time. Like SCAN, C-SCAN moves the head from one end of the disk to the other, servicing the request along the way. When the head reaches the other end, however it immediately returns to the beginning of the disk, without servicing any request on the return trip. The C-SCAN scheduling algorithm essentially treats the cylinder as a circular list that wraps around from the final cylinder to the first one. LOOK Scheduling o o o o o Notice that, as we described them, both SCAN and C-SCAN move the disk arm across the full width of the disk. In practice, neither algorithm is implemented this way. More commonly, the arm goes only as far as the final request in each direction. Then, it reverses direction immediately, without first going all the way to the end of the disk. These versions of SCAN and C-SCAN are called LOOK and CLOOK, because they look for a request before continuing to move in a given direction. Selection of a Disk-Scheduling Algorithm o o o o o o o o o o o o o o o Given so many disk-scheduling algorithms, how do we choose the best one? SSTF is common and has a natural appeal. SCAN and C-SCAN perform better for systems that place a heavy load on the disk, because they are less likely to have the starvation problem. For any particular list of requests, it is possible to define an optimal order of retrieval, but the computation needed to find an optimal schedule may not justify the savings over SSTF or SCAN. With any scheduling algorithm, however, performance depends heavily on the number and types of requests. For instance, suppose that the queue usually has just one outstanding request. Then, all scheduling algorithms are forced to behave the same, because they have only one choice for where to move the disk head. They all behave like FCFS scheduling. Note that the requests for disk service can be greatly influenced by the file-allocation method. A program reading a contiguously allocated file will generate several requests that are close together on the disk, resulting in limited head movement. A linked or indexed file, on the other hand, may include blocks that are widely scattered on the disk, resulting in greater head movement. The location of directories and index blocks also is important. Since every file must be opened to be used, and opening a file requires searching the directory structure, the directories will be accessed frequently. Suppose a directory entry is on the first cylinder and a file’s data are on the final cylinder. In this case, the disk head has to move the entire width of the disk. o o o o o o o o o o o o o o If the directory entry were on the middle cylinder, the head has to move at most one-half the width. Caching the directories and index blocks in main memory can also help to reduce the disk-arm movement, particularly for read requests. Because of these complexities, the disk-scheduling algorithm should be written as a separate module of the operating system, so that it can be replaced with a different algorithm if necessary. Either SSTF or LOOK is a reasonable choice for the default algorithm. Note that the scheduling algorithms described earlier consider only the seek distances. For modern disks, the rotational latency can be nearly as large as the average seek time. But it is difficult for the operating system to schedule for improved rotational latency because modern disks do not disclose the physical location of logical blocks. Disk manufacturers have been helping with this problem by implementing disk-scheduling algorithms in the controller hardware built into the disk drive. If the operating system sends a batch of requests to the controller, the controller can queue them and then schedule them to improve both the seek time and the rotational latency. If I/O performance were the only consideration, the operating system would gladly turn over the responsibility of disk scheduling to the disk hardware. In practice, however, the operating system may have other constraints on the service order for requests. For instance, demand paging may take priority over application I/O, and writes are more urgent than reads if the cache is running out of free pages. Also, it may be desirable to guarantee the order of a set of disk writes to make the file system robust in the face of system crashes; consider what could happen if the operating system allocated a disk page to a file, and the application wrote data into that page before the operating system had a chance to flush the modified inode and free-space list back to disk. To accommodate such requirements, an operating system may choose to do its own disk scheduling, and to “spoon-feed” the requests to the disk controller, one by one. Disk Management The operating system is responsible for several other aspects of disk management, too like disk initialization, booting from disk, and bad-block recovery. Disk Formatting o o o o o o o o o o o o o o o o o o o A new magnetic disk is a blank slate: It is just platters of a magnetic recording material. Before a disk can store data, it must be divided into sectors that the disk controller can read and write. This process is called low-level formatting, or physical formatting. Low-level formatting fills the disk with a special data structure for each sector. The data structure for a sector typically consists of a header, a data area (usually 512 bytes in size), and a trailer. The header and trailer contain information used by the disk controller, such as a sector number and an error-correcting code (ECC). When the controller writes a sector of data during normal I/O, the ECC is updated with a value calculated from all the bytes in the data area. When the sector is read, the ECC is recalculated and is compared with the stored value. If the stored and calculated numbers are different, this mismatch indicates that the data area of the sector has become corrupted and that the disk sector may be bad. The ECC is an error-correcting code because it contains enough information that if only 1 or 2 bits of data have been corrupted, the controller can identify which bits have changed, and can calculate what their correct values should be. The ECC processing is done automatically by the controller whenever a sector is read or written. Most hard disks are low-level formatted at the factory as a part of the manufacturing process. This formatting enables the manufacturer to test the disk, and to initialize the mapping from logical block numbers to detect-free sectors on the disk. For many hard disks, when the disk controller is instructed to lowlevel format the disk, it can also be told how many bytes of data space to leave between the header and trailer of all sectors. It is usually possible to choose among a few sizes, such as 256, 512, and 1024 bytes. Formatting a disk with a larger sector size means that fewer sectors can fit on each track, but that also means fewer headers and trailers are written on each track, and thus increases the space available for user data. Some operating systems can handle only a sector size of 512 bytes. To use a disk to hold files, the operating system still needs to record its own data structures on the disk. It does in two steps. o o o o o o o o o o o The first step is to partition the disk into one or more groups of cylinders. The operating system can treat each partition as though the latter were a separate disk. For instance, one partition can hold a copy of the operating system’s executable code, while another holds user files. After partitioning, the second step is called logical formatting, or “making a file system.” In this step, the operating system stores the initial file-system data structures onto the disk. The data structures may include maps of free and allocated space (a FAT or inodes) and an initial empty directory. Some operating systems give special programs the ability to use a disk partition as a large sequential array of logical blocks, without any filesystem data structures. This array is sometimes called raw I/O. For example, some database systems prefer raw I/O because it enables them to control the exact disk location where each database record is stored. Raw I/O bypasses all the file-system services, such as the buffer cache, prefetching, space allocation, file names, and directories. We can make some applications more efficient by implementing their own special-purpose storage services on a raw partition, but most applications perform better when they use the regular file-system services. Boot Block o o o o o o o o For a computer to start running - for instance, when it is powered up or rebooted - it needs to have an initial program to run. This initial bootstrap program tends to be simple. It initializes all aspects of the system, from CPU registers to device controllers and the contents of main memory, and then starts the operating system. To do its job, it finds the operating-system kernel on disk, loads that kernel into memory, and jumps to an initial address to begin the operating-system execution. For most computers, the bootstrap is stored in read-only memory (ROM). This location is convenient, because ROM needs no initialization, and is at a fixed location that the processor can start executing when powered up or reset. And, since ROM is read only, it cannot be infected by a computer virus. The problem is that changing this bootstrap code requires changing the ROM hardware chips. o o o o o o o For this reason, most systems store a tiny bootstrap loader program in the boot ROM, whose only job is to bring in a full bootstrap program from disk. The full bootstrap program can be changed easily: A new version is simply written onto the disk. The full bootstrap program is stored in a partition called the boot blocks, at a fixed location on the disk. A disk that has a boot partition is called a boot disk or system disk. The code in the boot ROM instructs the disk controller to read the boot blocks into memory (no device drivers are loaded at this point), and then starts executing that code. The full bootstrap program is more sophisticated than the bootstrap loader in the boot ROM, and is able to load the entire operating system from a nonfixed location on disk, and to start the operating system running. Even so, the full bootstrap code may be small. Bad Blocks o o o o o o o o o o o o o o Because disks have moving parts and small tolerances (recall that the disk head flies just above the disk surface), they are prone to failure. Sometimes, the failure is complete, and the disk needs to be replaced, and its contents restored from backup media to the new disk. More frequently, one or more sectors become defective. Most disks even come from the factory with bad blocks. Depending on the disk and controller in use, these blocks are handled in a variety of ways. On simple disks, such as some disks with IDE controllers, bad blocks are handled manually. For instance, the MS-DOS format command does a logical format, and, as a part of the process, scans the disk to find bad blocks. If format finds a bad block, it writes a special value into the corresponding FAT entry to tell the allocation routines not to use that block. If blocks go bad during normal operation, a special program (such as chkdsk) must be run manually to search for the bad blocks and to lock them as before. Data that resided on the bad blocks usually are lost. More sophisticated disks, such as the SCSI disks used in high-end PCs and most workstations, are smarter about bad-block recovery. The controller maintains a list of bad blocks on the disk. The list is initialized during the low-level format at the factory, and is updated over the life of the disk. Low-level formatting also sets aside spare sectors not visible to the operating system. o o o The controller can be told to replace each bad sector logically with one of the spare sectors. This scheme is known as sector sparing or forwarding. A typical bad-sector transaction might be as follows: The operating system tries to read logical block 87. The controller calculates the ECC and finds that the sector is bad. It reports this finding to the operating system. o o o o o o o o o o The next time that the system is rebooted, a special command is run to tell the SCSI controller to replace the bad sector with a spare. After that, whenever the system requests logical block 87, the request is translated into the replacement sector’s address by the controller. Note that such a redirection by the controller could invalidate any optimization by the operating system’s disk-scheduling algorithm! For this reason, most disks are formatted to provide a few spare sectors in each cylinder, and a spare cylinder as well. When a bad block is remapped, the controller uses a spare sector from the same cylinder, if possible. As an alternative to sector sparing, some controllers can be instructed to replace a bad block by sector slipping. For instance, suppose that logical block 17 becomes defective, and the first available spare follows sector 202. Then, sector slipping would remap all the sectors from sector 17 to 202, moving them all down one spot. That is, sector 202 would be copied into the spare, then sector 201 into 202, and then 200 into 201, and so on, until sector 18 is copied into sector 19. Slipping the sectors in this way frees up the space of sector 18, so sector 17 can be mapped to it. The replacement of a bad block generally is not a totally automatic process, because the data in the bad block usually are lost. Thus, whatever file was using that block must be repaired (for instance, by restoration from a backup tape), and that requires manual intervention. Stable-Storage Implementation By definition, information residing in stable storage is never lost. To implement such storage, we need to replicate the needed information on multiple storage devices with independent failure modes. We need to coordinate the writing of updates in a way that guarantees that a failure during an update does not leave all the copies in a damaged state, and that, when we are recovering from a failure, we can force all copies to a consistent and correct value, even if there is another failure during the recovery. A disk write results in one of the three outcomes: 1. Successful Completion The data were written correctly on disk. 2. Partial Failure A failure occurred in the midst of transfer, so only some of the sectors were written with the new data, and the sector being written during the failure may have been corrupted. 3. Total Failure The failure occurred before the disk write started, so the previous data values on the disk remain intact. We require that, whenever a failure occurs during writing of a block, the system detects it and invokes a recovery procedure to restore the block to a consistent state. To do that, the system must maintain two physical blocks for each logical block. An output operation is executed as follows: 1. Write the information onto the first physical block. 2. When the first write completes successfully, write the same information onto the second physical block. 3. Declare the operation complete only after the second write completes successfully. During recovery from a failure, each pair of physical blocks is examined. If both are the same and no detectable error exists, then no further action is necessary. If one block contains a detectable error, then we replace its contents with the value of the other block. If both blocks contain no detectable error, but they differ in content, then we replace the content of the first block with the value of the second. This recovery procedure ensures that a write to stable storage either succeeds completely or results in no change. We can extend this procedure easily to allow the use of an arbitrarily large number of copies of each block of stable storage. Although a large number of copies further reduces the probability of a failure, it is usually reasonable to simulate stable storage with only two copies. The data in stable storage are guaranteed to be safe unless a failure destroys all the copies.