Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CS 277: Data Mining
Mining Web Link Structure
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
CIS 455/555: Internet and Web Systems
HITS and PageRank; Google
March 27, 2013
© 2013 A. Haeberlen , Z. Ives
Web search before 1998
Based on information retrieval
Results were not very good
Boolean / vector model, etc.
Based purely on 'on-page' factors, i.e., the text of the page
Web doesn't have an editor to control quality
Web contains deliberately misleading information (SEO)
Great variety in types of information: Phone books, catalogs,
technical reports, slide shows, ...
Many languages, partial descriptions, jargon, ...
How to improve the results?
© 2013 A. Haeberlen , Z. Ives
Plan for today
HITS
Hubs and authorities
PageRank
NEXT
Iterative computation
Random-surfer model
Refinements: Sinks and Hogs
Google
© 2013 A. Haeberlen , Z. Ives
How Google worked in 1998
Google over the years
SEOs
Goal: Find authoritative pages
Many queries are relatively broad
Consequence: Abundance of results
"cats", "harvard", "iphone", ...
There may be thousands or even millions of pages that
contain the search term, incl. personal homepages, rants, ...
IR-type ranking isn't enough; still way too much for a
human user to digest
Need to further refine the ranking!
Idea: Look for the most authoritative pages
© 2013 A. Haeberlen , Z. Ives
But how do we tell which pages these are?
Problem: No endogenous measure of authoritativeness
Hard to tell just by looking at the page.
Need some 'off-page' factors
Idea: Use the link structure
Hyperlinks encode a considerable amount of
human judgment
What does it mean when a web page links
another web page?
Intra-domain links: Often created primarily for navigation
Inter-domain links: Confer some measure of authority
So, can we simply boost the rank of pages
with lots of inbound links?
© 2013 A. Haeberlen , Z. Ives
Relevance Popularity!
Team
Sports
“A-Team”
page
Hollywood
“Series to
Recycle” page
© 2013 A. Haeberlen , Z. Ives
Mr. T’s
page
Cheesy
TV
Shows
page
Yahoo
Directory
Wikipedia
Hubs and authorities
A
B
Hub
Authority
Idea: Give more weight to links from hub
pages that point to lots of other authorities
Mutually reinforcing relationship:
© 2013 A. Haeberlen , Z. Ives
A good hub is one that points to many good authorities
A good authority is one that is pointed to by many good hubs
HITS
R
S
Algorithm for a query Q:
1.
2.
3.
4.
Start with a root set R, e.g., the t highest-ranked pages from
the IR-style ranking for Q
For each pR, add all the pages p points to, and up to d
pages that point to p. Call the resulting set S.
Assign each page pS an authority weight xp and a hub
weight yp; initially, set all weights to be equal and sum to 1
For each pS, compute new weights xp and yp as follows:
5.
6.
Normalize the new weights such that both the sum of all the
xp and the sum of all the yp are 1
Repeat from step 4 until a fixpoint is reached
© 2013 A. Haeberlen , Z. Ives
New xp := Sum of all yq such that qp is an interdomain link
New yp := Sum of all xq such that pq is an interdomain link
If A is adjacency matrix, fixpoints are principal eigenvectors of
ATA and AAT, respectively
HITS: Hub and Authority Rankings
•
J. Kleinberg, Authorative sources in a hyperlinked environment,
Proceedings of ACM SODA Conference, 1998.
– HITS – Hypertext Induced Topic Selection
•
Every page u has two distinct measures of merit, its hub score h[u] and
its authority score a[u].
•
Recursive quantitative definitions of hub and authority scores
•
Relies on query-time processing
– To select base set Vq of links for query q constructed by
• selecting a sub-graph R from the Web (root set) relevant to the query
• selecting any node u which neighbors any r \in R via an inbound or
outbound edge (expanded set)
– To deduce hubs and authorities that exist in a sub-graph of the Web
•
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
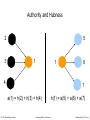
Authority and Hubness
5
2
3
1
1
4
6
7
a(1) = h(2) + h(3) + h(4)
CS 277: Data Mining Lectures
Analyzing Web Link Structure
h(1) = a(5) + a(6) + a(7)
Padhraic Smyth, UC Irvine
Authority and Hubness Convergence
• Recursive dependency:
a(v) Σ
w Є pa[v]
h(w)
h(v) Σ w Є ch[v] a(w)
• Using Linear Algebra, we can prove:
a(v) and h(v) converge
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Slides 2-13 in pdf
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
HITS Example
Find a base subgraph:
• Start with a root set R {1, 2, 3, 4}
• {1, 2, 3, 4} - nodes relevant to
the topic
• Expand the root set R to include
all the children and a fixed
number of parents of nodes in R
A new set S (base subgraph)
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
HITS Example Results
Authority
Hubness
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Authority and hubness weights
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Recap: HITS
Improves the ranking based on link structure
Based on concept of hubs and authorities
Intuition: Links confer some measure of authority
Overall ranking is a combination of IR ranking and this
Hub: Points to many good authorities
Authority: Is pointed to by many good hubs
Iterative algorithm to assign hub/authority scores
Query-specific
© 2013 A. Haeberlen , Z. Ives
No notion of 'absolute quality' of a page; ranking needs to
be computed for each new query
Plan for today
HITS
PageRank
Hubs and authorities
NEXT
Iterative computation
Random-surfer model
Refinements: Sinks and Hogs
Google
© 2013 A. Haeberlen , Z. Ives
How Google worked in 1998
Google over the years
SEOs
Google's PageRank (Brin/Page 98)
A technique for estimating page quality
Important differences to HITS:
Based on web link graph, just like HITS
Like HITS, relies on a fixpoint computation
No hubs/authorities distinction; just a single value per page
Query-independent
Results are combined with IR score
© 2013 A. Haeberlen , Z. Ives
Think of it as: TotalScore = IR score * PageRank
In practice, search engines use many other factors
(for example, Google says it uses more than 200)
PageRank: Intuition
A
G
H
How many levels
should we consider?
I
J
Shouldn't E's vote be
worth more than F's?
E
F
B
C
D
Imagine a contest for The Web's Best Page
Initially, each page has one vote
Each page votes for all the pages it has a link to
To ensure fairness, pages voting for more than one page
must split their vote equally between them
Voting proceeds in rounds; in each round, each page has the
number of votes it received in the previous round
In practice, it's a little more complicated - but not much!
© 2013 A. Haeberlen , Z. Ives
PageRank
Each page i is given a rank xi
Goal: Assign the xi such that the rank of each
page is governed by the ranks of the pages
linking to it:
1
xi x j
jBi N j
Rank of page j
Rank of page i
How do we compute
the rank values?
© 2013 A. Haeberlen , Z. Ives
Every page
j that links to i
Number of
links out
from page j
Iterative PageRank (simplified)
x
1
n
( k 1)
i
1 (k )
xj
jBi N j
Initialize all ranks to
be equal, e.g.:
Iterate until
convergence
© 2013 A. Haeberlen , Z. Ives
(0)
i
x
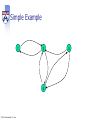
Simple Example
1
2
4
© 2013 A. Haeberlen , Z. Ives
3
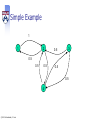
Simple Example
1
1
2
0.5
3
0.5
0.5
0.5
0.5
0.5
4
© 2013 A. Haeberlen , Z. Ives
Simple Example
1
1
2
0.5
3
0.5
0.5
0.5
0.5
Weight matrix W
0
1
0
0
0.5
0
0
0.5
0
0.5
0
0.5
0
0.5 0.5
© 2013 A. Haeberlen , Z. Ives
0
0.5
4
Matrix-Vector form
Recall rj = importance of node j
rj =
Si wij ri
i,j = 1,….n
e.g., r2 = 1 r1 + 0 r2 + 0.5 r3 + 0.5 r4
= dot product of r vector with column
2 of W
Let r = n x 1 vector of importance values for the
n nodes
Let W = n x n matrix of link weights
© 2013 A. Haeberlen , Z. Ives
Eigenvector Formulation
Need to solve the importance equations for
unknown r, with known W
r = WT r
We recognize this as a standard eigenvalue
problem, i.e.,
Ar=lr
(where A =
WT)
with l = an eigenvalue = 1
and r = the eigenvector corresponding to l = 1
© 2013 A. Haeberlen , Z. Ives
Eigenvector Formulation
Need to solve for r in
(WT – l I) r = 0
Note: W is a stochastic matrix, i.e., rows are non-negative and sum to 1
Results from linear algebra tell us that:
(a) Since W is a stochastic matrix, W and WT have the same
eigenvectors/eigenvalues
(b) The largest of these eigenvalues l is always 1
(c) the vector r corresponds to the eigenvector corresponding to the largest
eigenvector of W (or WT)
© 2013 A. Haeberlen , Z. Ives
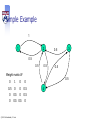
Solution for the Simple
Example
Solving for the eigenvector of W we get
r = [0.2 0.4 0.133 0.2667]
1
Results are quite intuitive, e.g., 2 is “most important”
1
2
0.5
3
0.5
W
0
0.5
1
0
0
0.5
0
0
0.5
0
0.5
0
0.5
0
0.5 0.5
© 2013 A. Haeberlen , Z. Ives
0
0.5
0.5
0.5
4
Naïve PageRank Algorithm Restated
Let
N(p) = number outgoing links from page p
B(p) = number of back-links to page p
1
PageRank ( p)
PageRank (b)
bB p N (b)
© 2013 A. Haeberlen , Z. Ives
Each page b distributes its importance to all of the
pages it points to (so we scale by 1/N(b))
Page p’s importance is increased by the importance
of its back set
In Linear Algebra formulation
Create an m x m matrix M to capture links:
M(i, j) = 1 / nj
=0
if page i is pointed to by page j
and page j has nj outgoing links
otherwise
Initialize all PageRanks to 1, multiply by M repeatedly until
all values converge:
PageRank ( p1 ' )
PageRank ( p1 )
PageRank ( p ' )
PageRank ( p )
2
2
M
...
...
PageRank
(
p
'
)
PageRank
(
p
)
m
m
© 2013 A. Haeberlen , Z. Ives
Computes principal eigenvector via power iteration
A Brief Example
Google
Amazon
g'
y’ =
a’
Yahoo
0
0
0.5 0.5
0 0.5 *
g
y
1
0.5
a
Running for multiple iterations:
g
y
a
1
1
= 1 , 0.5 ,
1
1.5
1
0.75
1.25
Total rank sums to number of pages
© 2013 A. Haeberlen , Z. Ives
,…
1
0.67
1.33
0
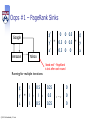
Oops #1 – PageRank Sinks
Google
Amazon
g'
y’ =
0 0 0.5
0.5 0 0.5 *
g
y
a’
0.5 0
a
Yahoo
'dead end' - PageRank
is lost after each round
Running for multiple iterations:
g
y
a
© 2013 A. Haeberlen , Z. Ives
1
0.5
= 1 ,
1 ,
1
0.5
0.25
0.5
0.25
,…,
0
0
0
0
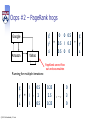
Oops #2 – PageRank hogs
g'
Google
Amazon
Yahoo
0 0 0.5
y’ = 0.5 1 0.5
a’
0.5 0 0
PageRank cannot flow
out and accumulates
Running for multiple iterations:
g
y
a
© 2013 A. Haeberlen , Z. Ives
1
0.5
= 1 ,
2 ,
1
0.5
0.25
2.5
0.25
,…,
0
3
0
*
g
y
a
Slides 14-20 in pdf
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Improved PageRank
Remove out-degree 0 nodes (or consider them to
refer back to referrer)
Add decay factor d to deal with sinks
1
PageRank ( p) (1 d ) d
PageRank (b)
bB p N (b)
Typical value: d=0.85
© 2013 A. Haeberlen , Z. Ives
Random Surfer Model
PageRank has an intuitive basis in random
walks on graphs
Imagine a random surfer, who starts on a
random page and, in each step,
with probability d, klicks on a random link on the page
with probability 1-d, jumps to a random page (bored?)
The PageRank of a page can be interpreted
as the fraction of steps the surfer spends on
the corresponding page
© 2013 A. Haeberlen , Z. Ives
Transition matrix can be interpreted as a Markov Chain
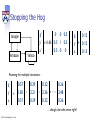
Stopping the Hog
Google
Amazon
Yahoo
g'
0 0 0.5
y’ = 0.85 0.5 1 0.5 *
a’
0.5 0 0
0.15
g
y + 0.15
0.15
a
Running for multiple iterations:
g
y
a
=
0.57
1.85 ,
0.57
0.39
2.21
0.39
0.32
0.26
,
2.36 , … , 2.48
0.32
0.26
… though does this seem right?
© 2013 A. Haeberlen , Z. Ives
Search Engine Optimization (SEO)
Has become a big business
White-hat techniques
Google webmaster tools
Add meta tags to documents, etc.
Black-hat techniques
Link farms
Keyword stuffing, hidden text, meta-tag stuffing, ...
Spamdexing
Doorway pages / cloaking
© 2013 A. Haeberlen , Z. Ives
Initial solution: <a rel="nofollow" href="...">...</a>
Some people started to abuse this to improve their own rankings
Special pages just for search engines
BMW Germany and Ricoh Germany banned in February 2006
Link buying
Recap: PageRank
Estimates absolute 'quality' or 'importance' of
a given page based on inbound links
Considered relatively stable
Query-independent
Can be computed via fixpoint iteration
Can be interpreted as the fraction of time a 'random surfer'
would spend on the page
Several refinements, e.g., to deal with sinks
But vulnerable to black-hat SEO
An important factor, but not the only one
© 2013 A. Haeberlen , Z. Ives
Overall ranking is based on many factors (Google: >200)
What could be the other 200 factors?
Positive
On-page
Off-page
Negative
Links to 'bad neighborhood'
Keyword in title? URL?
Keyword in domain name? Keyword stuffing
Over-optimization
Quality of HTML code
Hidden content (text has
Page freshness
same color as background)
Rate of change
Automatic redirect/refresh
...
...
Fast increase in number of
High PageRank
Anchor text of inbound links inbound links (link buying?)
Link farming
Links from authority sites
Links from well-known sites Different pages user/spider
Content duplication
Domain expiration date
...
...
Note: This is entirely speculative!
© 2013 A. Haeberlen , Z. Ives
Source: Web Information Systems, Prof. Beat Signer, VU Brussels
Beyond PageRank
PageRank assumes a “random surfer” who
starts at any node and estimates likelihood
that the surfer will end up at a particular page
A more general notion: label propagation
© 2013 A. Haeberlen , Z. Ives
Take a set of start nodes each with a different label
Estimate, for every node, the distribution of arrivals from
each label
In essence, captures the relatedness or influence of nodes
Used in YouTube video matching, schema matching, …
Plan for today
HITS
PageRank
Hubs and authorities
Iterative computation
Random-surfer model
Refinements: Sinks and Hogs
Google
© 2013 A. Haeberlen , Z. Ives
NEXT
How Google worked in 1998
Google over the years
SEOs
Google Architecture [Brin/Page 98]
Focus was on scalability
to the size of the Web
First to really exploit
Link Analysis
Started as an academic
project @ Stanford;
became a startup
Our discussion will be
on early Google – today
they keep things secret!
© 2013 A. Haeberlen , Z. Ives
The Heart of Google Storage
“BigFile” system for storing indices,
tables
Support for 264 bytes across multiple
drives, filesystems
Manages its own file descriptors,
resources
This was the predecessor to GFS
First use: Repository
© 2013 A. Haeberlen , Z. Ives
Basically, a warehouse of every HTML page
(this is the 'cached page' entry), compressed
in zlib (faster than bzip)
Useful for doing additional processing, any
necessary rebuilds
Repository entry format:
[DocID][ECode][UrlLen][PageLen][Url][Page]
The repository is indexed (not inverted here)
Repository Index
One index for looking up documents by
DocID
Done in ISAM (think of this as a B+ Tree
without smart re-balancing)
Index points to repository entries (or to
URL entry if not crawled)
One index for mapping URL to DocID
Sorted by checksum of URL
Compute checksum of URL, then perform
binary search by checksum
Allows update by merge with another
similar file
© 2013 A. Haeberlen , Z. Ives
Why is this done?
Lexicon
The list of searchable words
(Presumably, today it’s used to
suggest alternative words as well)
The “root” of the inverted index
As of 1998, 14 million “words”
Kept in memory (was 256MB)
Two parts:
© 2013 A. Haeberlen , Z. Ives
Hash table of pointers to words and the
“barrels” (partitions) they fall into
List of words (null-separated)
Indices – Inverted and “Forward”
Inverted index divided into
“barrels” (partitions by range)
Indexed by the lexicon; for
each DocID, consists of a Hit
List of entries in the document
Two barrels: short (anchor and
title); full (all text)
Forward index uses the same
barrels
Indexed by DocID, then a list
of WordIDs in this barrel and
this document, then Hit Lists
corresponding to the WordIDs
Lexicon: 293 MB
WordID
ndocs
WordID
ndocs
WordID
ndocs
Inverted Barrels: 41 GB
DocID: 27
nhits: 8
hit hit hit hit
DocID: 27
nhits: 8
hit hit hit
DocID: 27
nhits: 8
hit hit hit hit
DocID: 27
nhits: 8
hit hit
forward barrels: total 43 GB
DocID WordID: 24
nhits: 8
hit hit hit
WordID: 24
nhits: 8
hit hit
NULL
hit hit hit
DocID WordID: 24
nhits: 8
hit
WordID: 24
nhits: 8
hit hit
WordID: 24
nhits: 8
hit hit hit
NULL
hit
original tables from
http://www.cs.huji.ac.il/~sdbi/2000/google/index.htm
© 2013 A. Haeberlen , Z. Ives
Hit Lists (Not Mafia-Related)
Used in inverted and forward indices
Goal was to minimize the size – the bulk of
data is in hit entries
Plain
For 1998 version, made it down to 2 bytes per hit (though
that’s likely climbed since then):
cap 1
font: 3
position: 12
vs.
Fancy
cap 1
font: 7
Anchor
cap 1
font: 7 type: 4
© 2013 A. Haeberlen , Z. Ives
type: 4
position: 8
special-cased to:
hash: 4
pos: 4
Google’s Distributed Crawler
Single URL Server – the coordinator
Crawlers had 300 open connections apiece
A queue that farms out URLs to crawler nodes
Implemented in Python!
Each needs own DNS cache – DNS lookup is major
bottleneck, as we have seen
Based on asynchronous I/O
Many caveats in building a “friendly” crawler
(remember robot exclusion protocol?)
© 2013 A. Haeberlen , Z. Ives
Theory vs. practice
Expect the unexpected
They accidentally crawled an online game
Huge array of possible errors: Typos in HTML tags,
non-ASCII characters, kBs of zeroes in the middle of a tag,
HTML tags nested hundreds deep, ...
Social issues
Lots of email and phone calls, since most people had not
seen a crawler before:
"Wow, you looked at a lot of pages from my web site. How did you like it?"
"This page is copy-righted and should not be indexed"
...
Typical of new services deployed "in the wild"
© 2013 A. Haeberlen , Z. Ives
We had similar experiences with our ePOST system and our
measurement study of broadband networks
Google’s Search Algorithm
1.
2.
3.
4.
5.
Parse the query
Convert words into wordIDs
Seek to start of doclist in the short barrel for every word
Scan through the doclists until there is a document that
matches all of the search terms
Compute the rank of that document
6.
7.
8.
© 2013 A. Haeberlen , Z. Ives
IR score: Dot product of count weights and type weights
Final rank: IR score combined with PageRank
If we’re at the end of the short barrels, start at the doclists
of the full barrel, unless we have enough
If not at the end of any doclist, goto step 4
Sort the documents by rank; return the top K
Ranking in Google
Considers many types of information:
Position, font size, capitalization
Anchor text
PageRank
Count of occurrences (basically, TF) in a way that tapers off
(Not clear if they did IDF at the time?)
Multi-word queries consider proximity as well
© 2013 A. Haeberlen , Z. Ives
How?
Google’s Resources
In 1998:
24M web pages
About 55GB data w/o repository
About 110GB with repository
Lexicon 293MB
Worked quite well with low-end PC
In 2007: > 27 billion pages, >1.2B queries/day:
Don’t attempt to include all barrels on every machine!
© 2013 A. Haeberlen , Z. Ives
e.g., 5+TB repository on special servers separate from index
servers
Many special-purpose indexing services (e.g., images)
Much greater distribution of data (~500K PCs?),
huge net BW
Advertising needs to be tied in (>1M advertisers in 2007)
Google over the years
August 2001: Search algorithm revamped
February 2003: Local connectivity analysis
Index updated incrementally, rather than in big batches
June 2005: Personalized results
More weight to links from experts' sites. Google's first patent.
Summer 2003: Fritz
Incorporate additional ranking criteria more easily
Users can let Google mine their own search behavior
December 2005: Engine update
© 2013 A. Haeberlen , Z. Ives
Allows for more comprehensive web crawling
Source: http://www.wired.com/magazine/2010/02/ff_google_algorithm/all/1
Google over the years
May 2007: Universal search
December 2009: Real-time search
New indexing system; "50 percent fresher results"
February 2011: Major change to algorithm
Display results from Twitter & blogs as they are posted
August 2010: Caffeine
Users can get links to any medium (images, news, books,
maps, etc) on the same results page
The "Panda update" (revised since; Panda 3.3 in Feb 2012)
"designed to reduce the rankings of low-quality sites"
Algorithm is still updated frequently
© 2013 A. Haeberlen , Z. Ives
Source: http://www.wired.com/magazine/2010/02/ff_google_algorithm/all/1
Social Networks
•
Social networks = graphs
– V = set of “actors” (e.g., students in a class)
– E = set of interactions (e.g., collaborations)
– Typically small graphs, e.g., |V| = 10 or 50
– Long history of social network analysis (e.g. at UCI)
– Quantitative data analysis techniques that can automatically extract
“structure” or information from graphs
• E.g., who is the most important “actor” in a network?
• E.g., are there clusters in the network?
– Comprehensive reference:
• S. Wasserman and K. Faust, Social Network Analysis, Cambridge University
Press, 1994.
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Node Importance in Social Networks
• General idea is that some nodes are more important than others in
terms of the structure of the graph
• In a directed graph, “in-degree” may be a useful indicator of
importance
– e.g., for a citation network among authors (or papers)
• in-degree is the number of citations => “importance”
• However:
– “in-degree” is only a first-order measure in that it implicitly
assumes that all edges are of equal importance
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Recursive Notions of Node Importance
• wij = weight of link from node i to node j
– assume
Sj wij
= 1 and weights are non-negative
– e.g., default choice: wij = 1/outdegree(i)
• more outlinks => less importance attached to each
•
Define rj = importance of node j in a directed graph
rj =
•
Si wij ri
i,j = 1,….n
Importance of a node is a weighted sum of the importance of nodes that
point to it
– Makes intuitive sense
– Leads to a set of recursive linear equations
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
PageRank Algorithm: Applying this idea to the Web
1. Crawl the Web to get nodes (pages) and links (hyperlinks)
[highly non-trivial problem!]
2. Weights from each page = 1/(# of outlinks)
3. Solve for the eigenvector r (for l = 1) of the weight matrix
Computational Problem:
– Solving an eigenvector equation scales as O(n3)
– For the entire Web graph n > 10 billion (!!)
– So direct solution is not feasible
Can use the power method (iterative)
r
(k+1)
= WT r
(k)
for k=1,2,…..
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Power Method for solving for r
r
(k+1)
= WT r
(k)
Define a suitable starting vector r (1)
e.g., all entries 1/n, or all entries = indegree(node)/|E|, etc
Each iteration is matrix-vector multiplication =>O(n2)
- problematic?
no: since W is highly sparse (Web pages have limited
outdegree), each iteration is effectively O(n)
For sparse W, the iterations typically converge quite quickly:
- rate of convergence depends on the “spectral gap”
-> how quickly does error(k) = (l2/ l1)k go to 0 as a function of k ?
-> if |l2| is close to 1 (= l1) then convergence is slow
- empirically: Web graph with 300 million pages
-> 50 iterations to convergence (Brin and Page, 1998)
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Basic Principles of Markov Chains
Discrete-time finite-state first-order Markov chain, K states
Transition matrix A = K x K matrix
– Entry aij = P( statet = j | statet-1 = i),
– Rows sum to 1 (since
i, j = 1, … K
Sj P( statet = j | statet-1 = i) = 1)
– Note that P(state | ..) only depends on statet-1
P0 = initial state probability = P(state0 = i),
CS 277: Data Mining Lectures
Analyzing Web Link Structure
i = 1, …K
Padhraic Smyth, UC Irvine
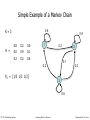
Simple Example of a Markov Chain
K=3
A =
0.8
0.8
0.2
0.0
0.0
0.9
0.1
0.2
0.2
0.6
1
0.9
0.2
2
0.1
0.2
P0 = [1/3 1/3 1/3]
0.2
3
0.6
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Steady-State (Equilibrium) Distribution for a Markov Chain
Irreducibility:
– A Markov chain is irreducible if there is a directed path from any
node to any other node
Steady-state distribution p for an irreducible Markov chain*:
pi = probability that in the long run, chain is in state I
The p’s are solutions to p = At p
Note that this is exactly the same as our earlier recursive equations for
node importance in a graph!
*Note: technically, for a meaningful solution to exist for p, A must be both irreducible and aperiodic
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Markov Chain Interpretation of PageRank
•
W is a stochastic matrix (rows sum to 1) by definition
– can interpret W as defining the transition probabilities in a Markov chain
– wij = probability of transitioning from node i to node j
•
Markov chain interpretation:
r = WT r
-> these are the solutions of the steady-state probabilities for a Markov chain
page importance steady-state Markov probabilities eigenvector
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
The Random Surfer Interpretation
•
Recall that for the Web model, we set wij = 1/outdegree(i)
•
Thus, in using W for computing importance of Web pages, this is equivalent
to a model where:
– We have a random surfer who surfs the Web for an infinitely long time
– At each page the surfer randomly selects an outlink to the next page
– “importance” of a page = fraction of visits the surfer makes to
that page
– this is intuitive: pages that have better connectivity will be visited more
often
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Potential Problems
1
2
3
Page 1 is a “sink” (no outlink)
Pages 3 and 4 are also “sinks” (no outlink from the system)
4
Markov chain theory tells us that no steady-state solution exists
- depending on where you start you will end up at 1 or {3, 4}
Markov chain is “reducible”
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Making the Web Graph Irreducible
•
One simple solution to our problem is to modify the Markov chain:
– With probability a the random surfer jumps to any random page in the
system (with probability of 1/n, conditioned on such a jump)
– With probability 1-a the random surfer selects an outlink (randomly
from the set of available outlinks)
•
The resulting transition graph is fully connected => Markov system is
irreducible => steady-state solutions exist
•
Typically a is chosen to be between 0.1 and 0.2 in practice
•
But now the graph is dense!
However, power iterations can be written as:
r (k+1) = (1- a) WT r (k) + (a/n) 1T
– Complexity is still O(n) per iteration for sparse W
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
The PageRank Algorithm
•
S. Brin and L. Page, The anatomy of a large-scale hypertextual search
engine, in Proceedings of the 7th WWW Conference, 1998.
•
PageRank = the method on the previous slide, applied to the entire Web
graph
– Crawl the Web
• Store both connectivity and content
– Calculate (off-line) the “pagerank” r for each Web page using the power
iteration method
•
How can this be used to answer Web queries:
– Terms in the search query are used to limit the set of pages of possible
interest
– Pages are then ordered for the user via precomputed pageranks
– The Google search engine combines r with text-based measures
– This was the first demonstration that link information could be used for
content-based search on the Web
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Link Manipulation
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Conclusions
• PageRank algorithm was the first algorithm for link-based search
– Many extensions and improvements since then
• See papers on class Web page
– Same idea used in social networks for determining importance
• Real-world search involves many other aspects besides PageRank
– E.g., use of logistic regression for ranking
• Learns how to predict relevance of page (represented by bag of
words) relative to a query, using historical click data
• See paper by Joachims on class Web page
• Additional slides (optional)
– HITS algorithm, Kleinberg, 1998
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
PageRank: Limitations
•
“rich get richer” syndrome
– not as “democratic” as originally (nobly) claimed
• certainly not 1 vote per “WWW citizen”
– also: crawling frequency tends to be based on pagerank
– for detailed grumblings, see www.google-watch.org, etc.
•
not query-sensitive
– random walk same regardless of query topic
• whereas real random surfer has some topic interests
• non-uniform jumping vector needed
– would enable personalization (but requires faster eigenvector convergence)
– Topic of ongoing research
•
ad hoc mix of PageRank & keyword match score
• done in two steps for efficiency, not quality motivations
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
HITS vs PageRank: Stability
• e.g. [Ng & Zheng & Jordan, IJCAI-01 & SIGIR-01]
• HITS can be very sensitive to change in small fraction of
nodes/edges in link structure
• PageRank much more stable, due to random jumps
• propose HITS as bidirectional random walk
– with probability d, randomly (p=1/n) jump to a node
– with probability d-1:
• odd timestep: take random outlink from current node
• even timestep: go backward on random inlink of node
– this HITS variant seems much more stable as d increased
– issue: tuning d (d=1 most stable but useless for ranking)
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine
Stability of HITS vs PageRank (5 trials)
HITS
randomly
deleted 30%
of papers
PageRank
CS 277: Data Mining Lectures
Analyzing Web Link Structure
Padhraic Smyth, UC Irvine