Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
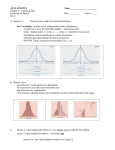
Fuzzy How to calculate the st. dev? How to calculate the range? How to calculate the variance? What is variance? √ What’s Fuzzy JANUARY 24, 2008 Responses See Meier: pages 101-102 See Meier: page. 99 See Meier: page 102, step 5 of st. dev. SPSS calculates these measurements of dispersions. See Analyze> Descriptive Statistics> Frequencies> Statistics. Variance is the sum of the squared deviations from the mean divided by the number of observations being analyzed. (Meier, page 102; 1036/5= 207.2). By itself it is a meaningless number. However, the square root (√) of the variance is the standard deviation which is used to identify if a value is close to the mean (what you would expect at random) or far from the norm, which may be significant. Examples of st. deviation? √ Examples are found on the in-class exercise of January 24th. We will complete this exercise on Feb. 1st. Also see http://psych.colorado.edu/~mcclella/java/normal/normz.html This is from the class web page titled, Playing with Standard Errors. Interpreting st. dev. once it is calculated? √ Standard deviations allow one to exam how close or far an observation is from the norm. For example let’s say the norm for LSAT scores is 1000 and the standard deviation is 100. Then the typical, run of the mill applicant will have a score of 900 to 1100. The difference between 900 and 1100 is random error. A law school that wants high performers on LSAT exams may elect to only consider applicants that are 2 standard deviations above the norm (1100 +) knowing that will discourage applications from 84% of all LSAT test takers. Could you identify terms and how can we best learn definitions such as deductive, inductive reasoning? A general rule is that large st. deviations (compared to their means) indicate less certainty about the norm while small standard deviations indicate greater certainty. Drug A has 87% effectiveness as its mean with a standard deviation or 4 but drug B has 87% effectiveness and a standard deviation of 2. FDA will prefer drug B to A. In some cases the size of the standard deviation away from the norm will determine if a drug may be sold over the counter (small standard deviation) or must be sold by prescription. There is a Glossary in Meier beginning on page 535. The other terms will be found in a college level dictionary rather than in online WORD subprograms. 1 What is the difference between valid percent and cumulative percent? These are terms used by SPSS for output from Descriptive Statistics>Frequency table. I get confuse calculating mean, median, and mode for grouped data. I am also confused about calculating standard deviations for grouped data. We will use SPSS to calculate the mean, median, mode, variance, range and standard deviation. Since the computer has no problem with large sets of numbers there is no reason to use grouped data calculations. Grouped calculations are used as a short hand by those who just don’t want to add up a column of numbers with a 1000 plus items. However, since most organization use computers the need for “grouped data” calculations has passed. Skip this discussion in Meier. When writing a good hypothesis should you attempt to try to predict? E.g. Young persons are more likely to vote? A “good” hypothesis describes the relationship between the independent and dependent variables. A good hypothesis could be: Age is an indicator of voting. As age rises voting among citizens increases A valid percent is a response divided by all responses. For example, if there are 100 responses and 10 of these responses were “1” then the valid percentage is 10% (10/100). If the next response is “2” and there are 15 (2 responses) the valid percentage is (15/100) or 15%. The cumulative percentage of both the first and the second is 25% (10+15). Cumulative percentages work ONLY with interval/ratio and ordinal data. In the first case there is no “direction” and a test of statistical significance would be 2 tailed. The outcome could go either way: rise with age or fall with age. In the second case there is direction and it is a one tailed test. The researcher is looking not only for an influence but for an influence in a particular direction. Both are ‘good’ hypotheses. I am having difficulty understanding the researcher’s hypothesis and the inferential relationship. These were the first and last questions on the purple sheet. See discussion of “hypothesis” noted above. The inferential question on the purple sheet concerned the specifics provided in the example. The example indicated that the key belief of the researcher was that as age increased opposition to gay adoptions increased. This was the inference the researcher believed the independent would have on the dependent. The general relationship in this specific example was that age influenced views on gay adoptions. 2 Jargon- or being able to decipher the different terms that are asking for the same information in different ways. The jargon is a challenge. The reason is that statistics texts are written by different disciplines that have different ways of addressing their discipline. In public administration we borrow heavily from sociology, psych, economics, political science, etc. In addition, SPSS has its own terms for concepts. I like to use SPSS terms or common English because these are the terms we use in practice. Example: Norm = typical= central tendency= mean, median and mode. See 5 questions handout for some of the linkages. Please ask in class if terms are overlapping. Still struggling with conceptual definitions versus operational. √ √ See Fuzzy chart for January 17, visit me in my office during office hours and/or set up an appointment if the office hours are not viable for you. Generally speaking conceptual definitions are found in dictionaries and operational definitions are identified by the researcher in the methodology sections that describes what variables were used and how the data was collected. E.g. Liberty conceptually means citizens setting their own rules for self government. The operational definition might be Liberty is the response of citizens to questions 106-111 on an NES survey that address participation in public affairs. Struggling with the relationship of nominal, ordinal and interval to mean, median and mode. Level Mode Median Mean Nominal * Ordinal * * Interval/Ratio * * * * indicates one can use statistic for specified level of measurement. Confused about the scale and it relationship to measurement. What scale level should be linked to what measurement? Scale is an SPSS word that means, not nominal or ordinal. In some statistics books this would be called parametric data or continuous data but SPSS abbreviates the concept by using the term “scale”. Scale should be linked—at least in theory—to interval and ratio measuring systems. Can you create a description of the standard deviation chart (normal curve) naming what each line/curve means? Try http://www.mnstate.edu/wasson/ed602lesson7.htm and scroll down to the picture of a ‘normal’ curve which is about a third of the way down the page. The title of the picture is Percentages of Cases Under Portions of the Normal Curve. Here is the curve and a definition of the lines and spaces under the curve. “0” equals the mean. However, since the measure column (last column on the right in the variable view) doesn’t control any subprogram in SPSS researchers (GSS, NES, Census) use ‘scale’ as a default and it could mean anything! 3 Click on box next to this fuzzy cell and it should reveal the curve and its values. (it make take a moment or two to load) Also try: www.ms.uky.edu/~mai/java/stat/GaltonMachine.html This web page introduces you to Gauss, the inventor of the ‘curve’. Relax and watch the curve develop. It is a great stress reducer. Please explain the tails and skewness. The picture above is a Gaussian, bell shaped curve of random events and as you can see there are two tails which are equal. The mean, median and mode are all in the same place (0). However, the model is not like the real world and the distribution may indicate lumpiness on the left and a long tail on the right. A tail on the right means the data is positively skewed and that the mean will be larger than the median. A tail on the left means the data is negatively skewed and the mean will be smaller than the median. Project requirements for LAWA Still having trouble with data interpretation and how to assign variables. Badly skewed data has policy implications. For example the US economy is in-- or is headed to-- a recession. Over the past 2 decades productivity and income has soared. However, the distribution of that wealth has gone primarily to the top 1% of all income earners in the U.S. Consequently if you look at mean change in GDP, wealth, stocks, etc. The U.S. looks like it is booming. However, if you look at the skewness of the data you see that the norm (in this case the median income of $42000) has remained virtually stagnant while only a few have reaped the benefits. This is the reason that Clinton and Bush tax cuts for the top 1 to 5% of income earners makes sense politically but not economically in terms of balancing the overall economy. I would like to meet with the LAWA team next week at a time that is viable for our 9 members. We can then discuss what each person will do in the overall project. Question is not specific. Please come to office hours and/or set up a time to clear up this confusion. 4