Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
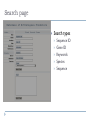
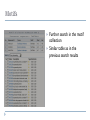
Introductory to database handling Endre Sebestyén What is a database? A database is a bunch of information It is a structured collection of information It contains basic objects, called records or entries The records contain fields, which contain defined types of data, somehow related to that record A nuclotid sequence database would contain for example all kinds of nucleotides as records, and nucleotide properties (length, name, origin, etc) as fields. What is a database? A database is searchable It is updated regularly (releases) It contains an index (table of content, catalog) New data goes in Obsolete, old data goes out It is cross referenced To other databases Why databases? The main purpose of databases is not only to collect and organize data, but to allow advanced data retrieval and analysis A database query is a method to retrieve information from the database The organization of records into fields allows us to use queries on fields Example : all mouse rna sequences between 1000-1500 bp length Databases on the internet WEBSERVERS USER DATABASE SERVER Databases on the internet Information system Query system Storage system Data Databases on the internet Information system Query system Storage system Data Book Book title Sequence Temperature Picture Video Log files of web servers etc Databases on the internet Information system Query system Storage system Data Bookshelves Boxes Text files/directories Binary files MySQL database Oracle database Types of databases Hierarchical model Tree-like structures Parent -> child One to many relations Types of databases Network model More complex than the previous Parent -> child One to many Many to one Types of databases Relational model Most widely used Fast and efficient (if the data structure is designed correctly) Databases on the internet Lists Catalogues Librarian Index files SQL language grep command Query systems for databases SQL query language Querying and modifying data Managing the database Optimize queries SELECT * FROM sequence_feature WHERE sequence_primary_id LIKE ‘%$variable%’ SORT BY sequence_primary_id LIMIT 10; Multiple operating systems Different programming languages Different storage systems (MySQL, PostgreSQL, etc) Use SQL terminal Throught programming languages Databases on the internet Library NCBI Entrez Google Lots of other general and specialized databases with search interfaces on the web Case study: the DoOP database Tries to collect and analyze the promoter regions of different genes and orthologous gene clusters http://doop.abc.hu 2 main sections: plant and chordate Chordate: v1.4 Plant: v1.5, v1.6 Integrates different kinds of data Sequence data Sequence annotation Cross-references to external databases Multiple alignments Conserved sequence regions Goal: easily accessible and searchable interface on the web Data processing MySQL tables MySQL tables MySQL table MySQL tables Data processing API for the MySQL database Application Programming Interface We want to convert the MySQL data into nice webpages MySQL query to get data: SELECT * FROM sequence_feature WHERE sequence_primary_id LIKE ‘%$variable%’ SORT BY sequence_primary_id LIMIT 10; And so on… Process the data OR with n API $data = $sequence_feature_object->get_data; Bio::DOOP API (More or less) simple representations of the sequence and other data -> modules and objects The API “hides” the MySQL queries and other stuff from us, so we can concentrate on the web pages It works well only if we have good API design with all the necessary features Bio::DOOP API modules Clusters Subsets Sequences Sequence features Motifs Other modules for managing, sorting and filtering the data Search page Search types Sequence ID Gene ID Keywords Species Sequence Search results Cluster ID Description Conserved motifs Taxonomical groups Download sequences Promoter cluster Sequences Gene annotation Sequence alignment Crossreferences Conserved regions Promoter cluster UTR region Species, size Motifs Motifs Further search in the motif collection Similar table as in the previous search results Thank you for your attention!