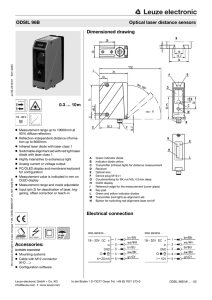
Accessories: Dimensioned drawing Electrical connection ODSIL
... most cases, the use of a floating average results in a reduction in the variance of the measurement values. To use this, select the menu setting Application -> Measure Filter -> Averaging. The number of measurement values to be taken into account can be set to a value between 1 … 99 via menu setting ...
... most cases, the use of a floating average results in a reduction in the variance of the measurement values. To use this, select the menu setting Application -> Measure Filter -> Averaging. The number of measurement values to be taken into account can be set to a value between 1 … 99 via menu setting ...

Tax Analytics Artificial Intelligence and Machine Learning
... very complex formulas – is the mainstay of tax functions. However, much more sophisticated tax analysis can be achieved with ML. This is a category of adaptive algorithms in which the output, or algorithm function, modifies itself as data is processed. By contrast, formulas in Excel do not change wh ...
... very complex formulas – is the mainstay of tax functions. However, much more sophisticated tax analysis can be achieved with ML. This is a category of adaptive algorithms in which the output, or algorithm function, modifies itself as data is processed. By contrast, formulas in Excel do not change wh ...





A Simplex Algorithm Whose Average Number of Steps Is Bounded
... It is natural to consider models with some symmetry assumptions. Very roughly, the hope is that, in a symmetric set of instances, if one is bad, then others should be good, so that the average over the set should not be bad. More specifically, suppose we have a group of symmetries and consider the e ...
... It is natural to consider models with some symmetry assumptions. Very roughly, the hope is that, in a symmetric set of instances, if one is bad, then others should be good, so that the average over the set should not be bad. More specifically, suppose we have a group of symmetries and consider the e ...


One and Done? Optimal Decisions From Very
... However, the claim that human cognition can be described as Bayesian inference does not imply that people are doing exact Bayesian inference. Exact Bayesian inference amounts to fully enumerating hypothesis spaces every time beliefs are updated with new data. In any large-scale application, this is ...
... However, the claim that human cognition can be described as Bayesian inference does not imply that people are doing exact Bayesian inference. Exact Bayesian inference amounts to fully enumerating hypothesis spaces every time beliefs are updated with new data. In any large-scale application, this is ...




Interocular transfer of simultaneous but not successive
... light. The side on which each of the colors appeared was randomly determined on each trial. A response to the green key, regardless of which side it was on, was defined as correct, while a response to the red key was defined as incorrect. In the simultaneous pattern discrimination, one of the side k ...
... light. The side on which each of the colors appeared was randomly determined on each trial. A response to the green key, regardless of which side it was on, was defined as correct, while a response to the red key was defined as incorrect. In the simultaneous pattern discrimination, one of the side k ...

Neural Networks and Its Application in Engineering
... specific problems. ANNs, like people, learn by example. According to Michael Mozer of the University of Colorado, “The neural network is structured to perform nonlinear Bayesian classification”. M aterial published as part of this publication, either on-line or in print, is copyrighted by the Inform ...
... specific problems. ANNs, like people, learn by example. According to Michael Mozer of the University of Colorado, “The neural network is structured to perform nonlinear Bayesian classification”. M aterial published as part of this publication, either on-line or in print, is copyrighted by the Inform ...

Variance and Standard Deviation - Penn Math
... The next one is the variance Var (X ) = σ 2 (X ). The square root of the variance σ is called the Standard Deviation. For continuous random variable X with probability density function f (x) defined on [A, B] we saw: ...
... The next one is the variance Var (X ) = σ 2 (X ). The square root of the variance σ is called the Standard Deviation. For continuous random variable X with probability density function f (x) defined on [A, B] we saw: ...







alexander philip dawid - Statistical Laboratory
... Genetic variation, disease prediction and causation Cambridge Statistics Initiative Geometrical methods for statistical inference and decision World of uncertainty (co-investigator) Simplicity, complexity and modelling (co-investigator) An abstract approach to expert systems Bayesian analysis in exp ...
... Genetic variation, disease prediction and causation Cambridge Statistics Initiative Geometrical methods for statistical inference and decision World of uncertainty (co-investigator) Simplicity, complexity and modelling (co-investigator) An abstract approach to expert systems Bayesian analysis in exp ...


Using Reinforcement Learning to Spider the Web Efficiently
... We represent the value function using a collection of naive Bayes text classifiers, performing the mapping by casting this regression problem as classification [Torgo and Gama, 1997]. We discretize the discounted sum of future reward values of our training data into bins, place the text in the neigh ...
... We represent the value function using a collection of naive Bayes text classifiers, performing the mapping by casting this regression problem as classification [Torgo and Gama, 1997]. We discretize the discounted sum of future reward values of our training data into bins, place the text in the neigh ...

Probability of Events
... The Addition Rule When events are not mutually exclusive, the addition rule is given by: p(A or B) = p(A) + p(B) - p(A and B) p(A and B) is the probability that both event A and event B occur simultaneously This formula can always be used as the addition rule because p(A and B) equals zero when the ...
... The Addition Rule When events are not mutually exclusive, the addition rule is given by: p(A or B) = p(A) + p(B) - p(A and B) p(A and B) is the probability that both event A and event B occur simultaneously This formula can always be used as the addition rule because p(A and B) equals zero when the ...