
Bile salt hydrolase in Lactobacillus plantarum
... all microbial activities contribute to host metabolism in a positive manner. For example, the bacterial putrefaction of proteins leads to the formation of potentially toxic and carcinogenic substances, such as ammonia, amines, phenols, thiols, and indols (50, 101). Another example of potentially har ...
... all microbial activities contribute to host metabolism in a positive manner. For example, the bacterial putrefaction of proteins leads to the formation of potentially toxic and carcinogenic substances, such as ammonia, amines, phenols, thiols, and indols (50, 101). Another example of potentially har ...

Digestive System
... a) results in the production of bilirubin 6) synthesis of bile salts 7) produces bile a) yellow-green, alkaline solution containing bile salts, bilirubin, cholesterol, lecithin & and a number of electrolytes b) involved with lipid catabolism & absorption ...
... a) results in the production of bilirubin 6) synthesis of bile salts 7) produces bile a) yellow-green, alkaline solution containing bile salts, bilirubin, cholesterol, lecithin & and a number of electrolytes b) involved with lipid catabolism & absorption ...

The Ileal Lipid Binding Protein Is Required for Efficient Absorption
... The ileal lipid binding protein (ilbp) is a cytoplasmic protein that binds bile acids with high affinity. However evidence demonstrating the role of this protein in bile acid transport and homeostasis is missing. We created a mouse strain lacking ilbp (Fabp62/2 mice) and assessed the impact of ilbp ...
... The ileal lipid binding protein (ilbp) is a cytoplasmic protein that binds bile acids with high affinity. However evidence demonstrating the role of this protein in bile acid transport and homeostasis is missing. We created a mouse strain lacking ilbp (Fabp62/2 mice) and assessed the impact of ilbp ...
Bilirubin
... because it is less soluble in it reacts more slowly with reagent (reaction carried out in methanol). - in this case both conjugated and unconjugated bilirubin are measured given total bilirubin. Unconjugated will calculated by subtracting direct from total and so called indirect. ...
... because it is less soluble in it reacts more slowly with reagent (reaction carried out in methanol). - in this case both conjugated and unconjugated bilirubin are measured given total bilirubin. Unconjugated will calculated by subtracting direct from total and so called indirect. ...

Chapter 40 Structure and Function of the Digestive System
... the least complete; the longitudinal layer is absent on the anterior and posterior surfaces. The glandular epithelium is discussed in the section about secretory functions of the stomach (see p. 1398). Blood is supplied to the stomach by branches of the celiac artery. The blood supply is so abundant ...
... the least complete; the longitudinal layer is absent on the anterior and posterior surfaces. The glandular epithelium is discussed in the section about secretory functions of the stomach (see p. 1398). Blood is supplied to the stomach by branches of the celiac artery. The blood supply is so abundant ...
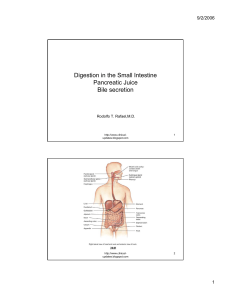
Digestion in the Small Intestine Pancreatic Juice Bile secretion
... to the amount of bile reabsorbed by the hepatocytes The synthesis and secretion of bile by the liver is ...
... to the amount of bile reabsorbed by the hepatocytes The synthesis and secretion of bile by the liver is ...

The gut microbiota and the liver. Pathophysiological and clinical
... development of many of the complications of liver disease, as well as in the progression of liver disease, per se (Fig. 1). A more fundamental role for SIBO has been proposed in both alcoholic liver disease (through the generation of acetaldehyde) [31] and NAFLD (by promoting both steatosis and infla ...
... development of many of the complications of liver disease, as well as in the progression of liver disease, per se (Fig. 1). A more fundamental role for SIBO has been proposed in both alcoholic liver disease (through the generation of acetaldehyde) [31] and NAFLD (by promoting both steatosis and infla ...

approved
... 5. At the jejunal end of the mesentery, the fat is deposited near the root and is scanty near the intestinal wall. At the ileal end of the mesentery the fat is deposited throughout so that it extends from the root to the intestinal wall. 6. Aggregations of lymphoid tissue (Peyer's patches) are prese ...
... 5. At the jejunal end of the mesentery, the fat is deposited near the root and is scanty near the intestinal wall. At the ileal end of the mesentery the fat is deposited throughout so that it extends from the root to the intestinal wall. 6. Aggregations of lymphoid tissue (Peyer's patches) are prese ...
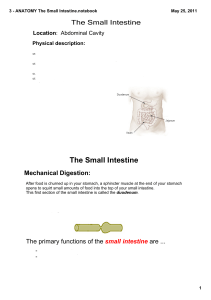
3 - ANATOMY The Small Intestine.notebook
... Pancreatic amylase is released into the small intestine to digest carbohydrates into monosacharides (single sugars) which can be absorbed into the blood stream. ...
... Pancreatic amylase is released into the small intestine to digest carbohydrates into monosacharides (single sugars) which can be absorbed into the blood stream. ...

Bile Acids - Biocrates
... Bile Acids & Cancer Bile acids have been implicated in cancer since the 1940s. In this context the role of some bile acids came to be regarded as cancer promoters rather than carcinogens. Here the composition of the bile acids might play an important role. Different bile acids show concentration dep ...
... Bile Acids & Cancer Bile acids have been implicated in cancer since the 1940s. In this context the role of some bile acids came to be regarded as cancer promoters rather than carcinogens. Here the composition of the bile acids might play an important role. Different bile acids show concentration dep ...


Medical Terminology
... Splen/ectomy: Excision of the spleen Splen/o/megaly: Enlargement of the spleen Splen/o/ptosis: Prolapse of the spleen Splen/o/pexy: Surgical fixation of the spleen Splen/o/pathy: Any disease of the spleen Splen/o/rrhaphy: Suture of the spleen Splen/o/rrhagia: hemorrhage from the spleen Splen/algia: ...
... Splen/ectomy: Excision of the spleen Splen/o/megaly: Enlargement of the spleen Splen/o/ptosis: Prolapse of the spleen Splen/o/pexy: Surgical fixation of the spleen Splen/o/pathy: Any disease of the spleen Splen/o/rrhaphy: Suture of the spleen Splen/o/rrhagia: hemorrhage from the spleen Splen/algia: ...

Radiological anatomy of the liver
... The largest organ in the body is the liver with a mean weight of 1.2- 1.5kg, which constitutes about 25% of the adult body weight (Kenichi and Kunio, 1997). The anatomical position of the liver is a key to fulfilling its functions as it controls the release into the systemic circulation of all absor ...
... The largest organ in the body is the liver with a mean weight of 1.2- 1.5kg, which constitutes about 25% of the adult body weight (Kenichi and Kunio, 1997). The anatomical position of the liver is a key to fulfilling its functions as it controls the release into the systemic circulation of all absor ...

Organ Combining Form
... Splen/ectomy: Excision of the spleen Splen/o/megaly : Enlargement of the spleen Splen/o/ptosis: Prolapse of the spleen Splen/o/pexy: Surgical fixation of the spleen Splen/o/pathy: Any disease of the spleen Splen/o/rrhaphy: Suture of the spleen Splen/o/rrhagia: hemorrhage from the spleen Splen/algia: ...
... Splen/ectomy: Excision of the spleen Splen/o/megaly : Enlargement of the spleen Splen/o/ptosis: Prolapse of the spleen Splen/o/pexy: Surgical fixation of the spleen Splen/o/pathy: Any disease of the spleen Splen/o/rrhaphy: Suture of the spleen Splen/o/rrhagia: hemorrhage from the spleen Splen/algia: ...
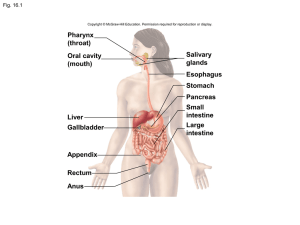
Chapter 01 FlexArt
... 1 A wave of smooth muscle relaxation moves ahead of the bolus, allowing the digestive tract to expand. ...
... 1 A wave of smooth muscle relaxation moves ahead of the bolus, allowing the digestive tract to expand. ...


Lesson 9 Readings
... fatty food the body releases bile into the common bile duct which joins with the pancreatic duct just before the entrance to the duodenum. The duodenum thus receives a mixture of bile and pancreatic juices. Bile has a detergent-like effect on fats in the duodenum. It breaks apart large fat globules ...
... fatty food the body releases bile into the common bile duct which joins with the pancreatic duct just before the entrance to the duodenum. The duodenum thus receives a mixture of bile and pancreatic juices. Bile has a detergent-like effect on fats in the duodenum. It breaks apart large fat globules ...
Digestive system
... Functions of the digestive system • Digestion-mechanical and chemical breakdown of material • Motility-movement of material from the oral cavity to the anus-swallowing / peristalsis • Secretion-exocrine release of enzymes into the lumen of the digestive tract for chemical digestion • Absorption-mov ...
... Functions of the digestive system • Digestion-mechanical and chemical breakdown of material • Motility-movement of material from the oral cavity to the anus-swallowing / peristalsis • Secretion-exocrine release of enzymes into the lumen of the digestive tract for chemical digestion • Absorption-mov ...

GI EMBRYOLOGY OVERVIEW Primordial gut is closed at 4th week
... Left one third to one half of the transverse colon, the descending and sigmoid colon, the rectum, and the superior part of the anal canal o Epithelium of urinary bladder and most of the urethra They are all supplied by INFERIOR MESENTERIC ARTERY, the artery of the hindgut The junction between the se ...
... Left one third to one half of the transverse colon, the descending and sigmoid colon, the rectum, and the superior part of the anal canal o Epithelium of urinary bladder and most of the urethra They are all supplied by INFERIOR MESENTERIC ARTERY, the artery of the hindgut The junction between the se ...
Gastrointestinal System Terminology - Key
... accumulation of fluid in the peritoneal cavity congenital absence or closure of a normal opening abnormal slowness in eating a neurotic disorder characterized by binge eating, followed by vomiting or induced diarrhea a state of ill health, wasting, or malnutrition chronic disease of the liver an ong ...
... accumulation of fluid in the peritoneal cavity congenital absence or closure of a normal opening abnormal slowness in eating a neurotic disorder characterized by binge eating, followed by vomiting or induced diarrhea a state of ill health, wasting, or malnutrition chronic disease of the liver an ong ...


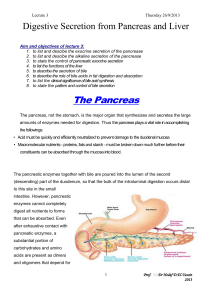
The Pancreas
... The liver is the largest gland in the body and performs an astonishingly large number of tasks that impact all body systems. One consequence of this complexity is that hepatic disease has widespread effects on virtually all other organ systems. The three fundamental roles of the liver are: 1. Vascul ...
... The liver is the largest gland in the body and performs an astonishingly large number of tasks that impact all body systems. One consequence of this complexity is that hepatic disease has widespread effects on virtually all other organ systems. The three fundamental roles of the liver are: 1. Vascul ...
Pancreatic secretion
... can be autocatalytically activated by trypsin that has already been formed from previously secreted trypsinogen. Chymotrypsinogen is activated by trypsin to form chymotrypsin, and procarboxypolypeptidase is activated in a similar manner. It is important that the proteolytic enzymes of the pancreatic ...
... can be autocatalytically activated by trypsin that has already been formed from previously secreted trypsinogen. Chymotrypsinogen is activated by trypsin to form chymotrypsin, and procarboxypolypeptidase is activated in a similar manner. It is important that the proteolytic enzymes of the pancreatic ...

Digestion - Sinoe Medical Association
... Death has been known to occur in cases where defecation causes the blood pressure to rise enough to cause the rupture of an aneurysm or to dislodge blood clots Also, in release of the Valsalva maneuver blood pressure falls, this coupled often with standing up quickly to leave the toilet results in a ...
... Death has been known to occur in cases where defecation causes the blood pressure to rise enough to cause the rupture of an aneurysm or to dislodge blood clots Also, in release of the Valsalva maneuver blood pressure falls, this coupled often with standing up quickly to leave the toilet results in a ...
Cholangiocarcinoma

Cholangiocarcinoma is a form of cancer that is composed of mutated epithelial cells (or cells showing characteristics of epithelial differentiation) that originate in the bile ducts which drain bile from the liver into the small intestine. Other biliary tract cancers include pancreatic cancer, gallbladder cancer, and cancer of the ampulla of Vater.Cholangiocarcinoma is a relatively rare neoplasm that is classified as an adenocarcinoma (a cancer that forms glands or secretes significant amounts of mucins). It has an annual incidence rate of 1–2 cases per 100,000 in the Western world, but rates of cholangiocarcinoma have been rising worldwide over the past several decades.Prominent signs and symptoms of cholangiocarcinoma include abnormal liver function tests, abdominal pain, jaundice, and weight loss. Other symptoms such as generalized itching, fever, and changes in color of stool or urine may also occur. The disease is diagnosed through a combination of blood tests, imaging, endoscopy, and sometimes surgical exploration, with confirmation obtained after a pathologist examines cells from the tumor under a microscope. Known risk factors for cholangiocarcinoma include primary sclerosing cholangitis (an inflammatory disease of the bile ducts), congenital liver malformations, infection with the parasitic liver flukes Opisthorchis viverrini or Clonorchis sinensis, and exposure to Thorotrast (thorium dioxide), a chemical formerly used in medical imaging. However, most patients with cholangiocarcinoma have no identifiable specific risk factors.Cholangiocarcinoma is considered to be an incurable and rapidly lethal malignancy unless both the primary tumor and any metastases can be fully resected (removed surgically). No potentially curative treatment yet exists except surgery, but most patients have advanced stage disease at presentation and are inoperable at the time of diagnosis. Patients with cholangiocarcinoma are generally managed - though never cured - with chemotherapy, radiation therapy, and other palliative care measures. These are also used as adjuvant therapies (i.e. post-surgically) in cases where resection has apparently been successful (or nearly so).