
Dimensional Modeling
... build times and disk space needed to create them has grown enormously, often requiring more time than is allotted and more space than the original data! ...
... build times and disk space needed to create them has grown enormously, often requiring more time than is allotted and more space than the original data! ...

Regression Discontinuity
... RD compares regression lines, not means Both RDs and REs control for selection bias Unknown variables do not determine assignment Pretests have no error IF used as the selection variable Regression lines are not affected by posttest errors ...
... RD compares regression lines, not means Both RDs and REs control for selection bias Unknown variables do not determine assignment Pretests have no error IF used as the selection variable Regression lines are not affected by posttest errors ...

International Inflation and Interest Rates
... mixture of extreme points. In particular, let X be a Polish space and the set of all p.m.'s on B(X) (equipped with the topology of weak convergence of p.m.'s). Further, let be any countable class of Borel functions from X into itself, 1 = {P : P=P-1 for all in } the set of -invariant ...
... mixture of extreme points. In particular, let X be a Polish space and the set of all p.m.'s on B(X) (equipped with the topology of weak convergence of p.m.'s). Further, let be any countable class of Borel functions from X into itself, 1 = {P : P=P-1 for all in } the set of -invariant ...

Section 2 Models in Science
... patterns, ocean currents, and carbon dioxide levels in the atmosphere. These models do not make exact predictions about future climates, but they estimate what might happen if variables change. ...
... patterns, ocean currents, and carbon dioxide levels in the atmosphere. These models do not make exact predictions about future climates, but they estimate what might happen if variables change. ...

Public Sector OR in Japan: Education, Research, and Applications
... Public sector OR in Japan Public sector segment is described by a huge amount of statistical data that are obtained by various forms of processes: surveys, sampling, and other collective means. “Reliable” data needs to be used more efficiently and effectively as we now find the need for various kin ...
... Public sector OR in Japan Public sector segment is described by a huge amount of statistical data that are obtained by various forms of processes: surveys, sampling, and other collective means. “Reliable” data needs to be used more efficiently and effectively as we now find the need for various kin ...

Lecture 6
... • Determine Optionality and Cardinality Determine the number of occurrences of one entity for a single occurrence of the related entity. • Name Relationships Name each relationship between entities • Eliminate Many-toMany Relationships Many-to-many relationships cannot be implemented into database t ...
... • Determine Optionality and Cardinality Determine the number of occurrences of one entity for a single occurrence of the related entity. • Name Relationships Name each relationship between entities • Eliminate Many-toMany Relationships Many-to-many relationships cannot be implemented into database t ...

Market Demand Sample Report
... MDM Analytics offers several ways you can take advantage of its products and services to reach your full market potential: Annual subscription to MDM Market Prospector database – For clients with ongoing research needs, we recommend the annual subscription with unlimited access to MDM Analytics mark ...
... MDM Analytics offers several ways you can take advantage of its products and services to reach your full market potential: Annual subscription to MDM Market Prospector database – For clients with ongoing research needs, we recommend the annual subscription with unlimited access to MDM Analytics mark ...

Data Mining and Official Statistics
... 1.What is Data Mining ? Data Mining is often presented as a revolution in information processing. Here are two definitions taken from the literature: U.M.Fayyad : « Data Mining is the nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data » ...
... 1.What is Data Mining ? Data Mining is often presented as a revolution in information processing. Here are two definitions taken from the literature: U.M.Fayyad : « Data Mining is the nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data » ...

International Journal on Advanced Computer Theory and
... classification in emerging trends of information technology in development, which predicts the probability that a given sample is a member of a particular class. It is based on the Bayes theorem. The Bayesian classification shows better accuracy and speed when applied to large databases. The Bayesia ...
... classification in emerging trends of information technology in development, which predicts the probability that a given sample is a member of a particular class. It is based on the Bayes theorem. The Bayesian classification shows better accuracy and speed when applied to large databases. The Bayesia ...

Chapter 1 An Introduction to Model Building
... would yield 0.52 gallons of motor fuel, then the yield would be 52%. 4. To reduce maintenance costs, data was collected on parts inventories and equipment breakdowns. Obtaining accurate data required the installation of a new data based - management system and integrated maintenance information syst ...
... would yield 0.52 gallons of motor fuel, then the yield would be 52%. 4. To reduce maintenance costs, data was collected on parts inventories and equipment breakdowns. Obtaining accurate data required the installation of a new data based - management system and integrated maintenance information syst ...

Q: What is the difference in the random effect model and the GEE
... SAS, which allows random intercepts and random slopes, or even more complicated structures. You can install gllamm directly from STATA by entering webseek gllamm into the STATA command line and following the directions. Please also see the GLLAMM website for examples and information about the comman ...
... SAS, which allows random intercepts and random slopes, or even more complicated structures. You can install gllamm directly from STATA by entering webseek gllamm into the STATA command line and following the directions. Please also see the GLLAMM website for examples and information about the comman ...

Connected Digital Experience Connected Marketing Solutions
... loops and ensuring consistent behavior and messaging across touch-points. With customers increasingly connected with each other, and influencing one another, we help connect you and your customer. ...
... loops and ensuring consistent behavior and messaging across touch-points. With customers increasingly connected with each other, and influencing one another, we help connect you and your customer. ...

6QuantiativeDataAnalysis-CentralTendency_Dispersion
... percentile rank is typically defined as the proportion of scores in a distribution that a specific score is greater than or equal to. For instance, if you received a score of 95 on a math test and this score was greater than or equal to the scores of 88% of the students taking the test, then your pe ...
... percentile rank is typically defined as the proportion of scores in a distribution that a specific score is greater than or equal to. For instance, if you received a score of 95 on a math test and this score was greater than or equal to the scores of 88% of the students taking the test, then your pe ...

For the following exercise determine the range (possible values) of
... that assigns a real number to each outcome in the sample space of a random experiment. It’s notation is denoted by an uppercase letter such as X. ...
... that assigns a real number to each outcome in the sample space of a random experiment. It’s notation is denoted by an uppercase letter such as X. ...

Data mining is a step in the KDD process consisting of particular
... Dimensionality reduction and transformation methods reduce the effective number of variables under consideration or find invariant representations for the data Smoothing (binning, clustering, regression etc.) Aggregation (use of summary operations (e.g., averaging) on data) Generalization (primitive ...
... Dimensionality reduction and transformation methods reduce the effective number of variables under consideration or find invariant representations for the data Smoothing (binning, clustering, regression etc.) Aggregation (use of summary operations (e.g., averaging) on data) Generalization (primitive ...

Taking Your Application Design to the Next Level with SQL
... 5. Enhancing an E-commerce web application with market basket analysis ...
... 5. Enhancing an E-commerce web application with market basket analysis ...

The relationship between business cycles and earnings per share
... by accounting system is the basis of future predictions. However, accounting data are not enough to conduct an accurate prediction of future data. Rather, other factors such as national economic conditions (i.e. expansion or recession) need to be addressed as well. Economic conditions may exert vari ...
... by accounting system is the basis of future predictions. However, accounting data are not enough to conduct an accurate prediction of future data. Rather, other factors such as national economic conditions (i.e. expansion or recession) need to be addressed as well. Economic conditions may exert vari ...

Statistical Learning for Resting-State fMRI: Successes and Challenges
... While data-driven methods such as ICA are often called model-free, they rely on the following simple multivariate decomposition model of the signal: Y = U V + N, where Y ∈ Rn×p are the fMRI data: n observations of images with p voxels, U ∈ Rn×k and V ∈ Rk×p are respectively k time series and k spati ...
... While data-driven methods such as ICA are often called model-free, they rely on the following simple multivariate decomposition model of the signal: Y = U V + N, where Y ∈ Rn×p are the fMRI data: n observations of images with p voxels, U ∈ Rn×k and V ∈ Rk×p are respectively k time series and k spati ...

Low Rank Language Models for Small Training Sets
... that is easier to estimate from the finite amount of training data. In the matrix case, reducing the rank of the joint probability matrix is equivalent to pushing the distributions over a vocabulary of size , , either exactly or approximately into a subspace of . More generally, a low rank tensor im ...
... that is easier to estimate from the finite amount of training data. In the matrix case, reducing the rank of the joint probability matrix is equivalent to pushing the distributions over a vocabulary of size , , either exactly or approximately into a subspace of . More generally, a low rank tensor im ...
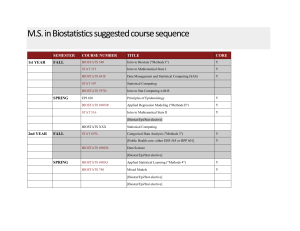
M.S. in Biostatistics suggested course sequence
... M.S. in Biostatistics suggested course sequence 1st YEAR ...
... M.S. in Biostatistics suggested course sequence 1st YEAR ...

Foundational Methodology for Data Science
... discover underlying patterns, with the goal of gaining insights. Organizations can then use these insights to take actions that ideally improve future outcomes. There are numerous rapidly evolving technologies for analyzing data and building models. In a remarkably short time, they have progressed f ...
... discover underlying patterns, with the goal of gaining insights. Organizations can then use these insights to take actions that ideally improve future outcomes. There are numerous rapidly evolving technologies for analyzing data and building models. In a remarkably short time, they have progressed f ...

13058_2014_424_MOESM2_ESM
... number of features that have at one time been added to the selected feature subset vector, V , we determine P m linear discriminants by adding each of the remaining P m to V . The feature whose addition most improves the performance of the linear classifier is added to V if its contribution to t ...
... number of features that have at one time been added to the selected feature subset vector, V , we determine P m linear discriminants by adding each of the remaining P m to V . The feature whose addition most improves the performance of the linear classifier is added to V if its contribution to t ...

Slides in ppt
... Are used extensively in the business world as predictive models Neural Nets are widely used in the financial market to model fraud in credit cards and monetary transactions ...
... Are used extensively in the business world as predictive models Neural Nets are widely used in the financial market to model fraud in credit cards and monetary transactions ...

Chapter16 11-12
... anticipates a profit of $50,000 if it gets the larger contract and a profit of $20,000 on the smaller contract. There is a 30% chance of getting the larger contract, a 60% chance of getting the smaller contract, and a 10% of getting neither contract. Assume the contracts are independently given, ...
... anticipates a profit of $50,000 if it gets the larger contract and a profit of $20,000 on the smaller contract. There is a 30% chance of getting the larger contract, a 60% chance of getting the smaller contract, and a 10% of getting neither contract. Assume the contracts are independently given, ...
