



EM Algorithm
... respect to Q (theta fixed) and then maximizing F with respect to theta (Q fixed). ...
... respect to Q (theta fixed) and then maximizing F with respect to theta (Q fixed). ...




Fabio D`Andrea LMD – 4e étage “dans les serres” 01 44 32 22 31
... shows that the Voronoi cells depend significantly on the metric used. ...
... shows that the Voronoi cells depend significantly on the metric used. ...
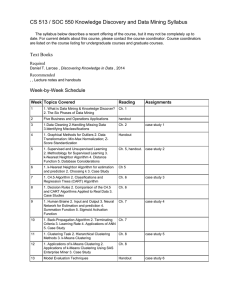
CS 513 / SOC 550 Knowledge Discovery and Data Mining Syllabus
... Summation Function 5. Sigmoid Activation Function ...
... Summation Function 5. Sigmoid Activation Function ...

Clustering in Data Mining ( Phuong Tran)
... Some elements may be close according to one distance measure and further away according to another. Select a good distance measure is an important step in clustering. ...
... Some elements may be close according to one distance measure and further away according to another. Select a good distance measure is an important step in clustering. ...



Data Mining Lab
... 2. Pre-process a given dataset based on the following: a. Attribute Selection b. Handling Missing Values c. Discretization d. Eliminating Outliers 3. Create a dataset in ARFF (Attribute-Relation File Format) for any given dataset and perform Market-Basket Analysis. 4. Generate Association Rules usin ...
... 2. Pre-process a given dataset based on the following: a. Attribute Selection b. Handling Missing Values c. Discretization d. Eliminating Outliers 3. Create a dataset in ARFF (Attribute-Relation File Format) for any given dataset and perform Market-Basket Analysis. 4. Generate Association Rules usin ...


Clustering
... Select initial centroids at random. Assign each object to the cluster with the nearest centroid. Compute each centroid as the mean of the objects assigned to it. Repeat previous 2 steps until no change. ...
... Select initial centroids at random. Assign each object to the cluster with the nearest centroid. Compute each centroid as the mean of the objects assigned to it. Repeat previous 2 steps until no change. ...

A New Gravitational Clustering Algorithm
... Many clustering techniques rely on the assumption that a data set follows a certain distribution and is free of noise Given noise, several techniques (k-means, fuzzy k-means) based on a least squares estimate are spoiled Most clustering algorithms require the number of clusters to be specified The a ...
... Many clustering techniques rely on the assumption that a data set follows a certain distribution and is free of noise Given noise, several techniques (k-means, fuzzy k-means) based on a least squares estimate are spoiled Most clustering algorithms require the number of clusters to be specified The a ...

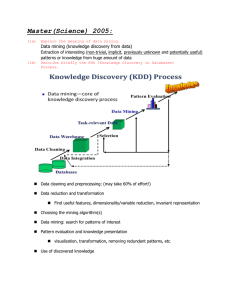
The goal of data mining is to extract knowledge, dependencies and
... networks with the backpropagation algorithm, RBF networks, Kohonens maps and some modifications of LVQ method. There are also described some clustering methods like hierarchical clustering, QT clustering, kmeans method and its fuzzy modification. The work also includes data pre-processing techniques ...
... networks with the backpropagation algorithm, RBF networks, Kohonens maps and some modifications of LVQ method. There are also described some clustering methods like hierarchical clustering, QT clustering, kmeans method and its fuzzy modification. The work also includes data pre-processing techniques ...

Introduction to Clustering
... Cluster is a collection of data objects that are similar to one another within the same cluster and are dissimilar to the objects in other cluster. Cluster: a collection of data objects o ...
... Cluster is a collection of data objects that are similar to one another within the same cluster and are dissimilar to the objects in other cluster. Cluster: a collection of data objects o ...



Cluster1
... gender, age, product, etc.) into numeric values so can be treated as points in space • If two points are close in geometric sense then they represent similar data in the database ...
... gender, age, product, etc.) into numeric values so can be treated as points in space • If two points are close in geometric sense then they represent similar data in the database ...

Modified K-Means for Better Initial Cluster Centres
... ISSN 2320–088X IJCSMC, Vol. 2, Issue. 7, July 2013, pg.219 – 223 RESEARCH ARTICLE ...
... ISSN 2320–088X IJCSMC, Vol. 2, Issue. 7, July 2013, pg.219 – 223 RESEARCH ARTICLE ...


INFS 6510 – Competitive Intelligence Systems
... 1. How do association rules differ from traditional production rules? How are they the same? ...
... 1. How do association rules differ from traditional production rules? How are they the same? ...