

An Analysis on Density Based Clustering of Multi
... A Self-Organizing Map (SOM) or self-organizing feature map (SOFM) is a neural network approach that uses competitive unsupervised learning. Learning is based on the concept that the behavior of a node should impact only those nodes and arcs near it. Weights are initially assigned randomly and adjust ...
... A Self-Organizing Map (SOM) or self-organizing feature map (SOFM) is a neural network approach that uses competitive unsupervised learning. Learning is based on the concept that the behavior of a node should impact only those nodes and arcs near it. Weights are initially assigned randomly and adjust ...


Parameter Reduction for Density-based Clustering of Large Data Sets
... the density-based clustering structure of the data. This method is used for interactive cluster analysis. • CHAMELEON has been found to be very effective in clustering convex shapes. However, the algorithm cannot handle outliers and needs parameter setting to work effectively. • TURN* is a brute for ...
... the density-based clustering structure of the data. This method is used for interactive cluster analysis. • CHAMELEON has been found to be very effective in clustering convex shapes. However, the algorithm cannot handle outliers and needs parameter setting to work effectively. • TURN* is a brute for ...
Mining massive datasets
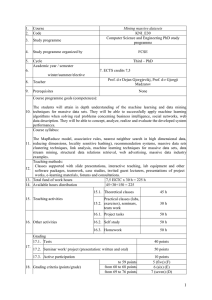
... The students will attain in depth understanding of the machine learning and data mining 10. techniques for massive data sets. They will be able to successfully apply machine learning algorithms when solving real problems concerning business intelligence, social networks, web data description. They w ...
... The students will attain in depth understanding of the machine learning and data mining 10. techniques for massive data sets. They will be able to successfully apply machine learning algorithms when solving real problems concerning business intelligence, social networks, web data description. They w ...


Comparative Analysis of EM Clustering Algorithm and Density
... Abstract:- Machine learning is type of artificial intelligence wherein computers make predictions based on data. Clustering is organizing data into clusters or groups such that they have high intra-cluster similarity and low inter cluster similarity. The two clustering algorithms considered are EM a ...
... Abstract:- Machine learning is type of artificial intelligence wherein computers make predictions based on data. Clustering is organizing data into clusters or groups such that they have high intra-cluster similarity and low inter cluster similarity. The two clustering algorithms considered are EM a ...

Association Rules
... IT462 Lab 4: Association Rules For this lab, you will implement a data mining algorithm and try it on some sample data set. Part 1 (Find the frequent itemsets): Implement the Apriori algorithm to find the frequent itemsets. This is the algorithms we discussed in class. The algorithm is described in ...
... IT462 Lab 4: Association Rules For this lab, you will implement a data mining algorithm and try it on some sample data set. Part 1 (Find the frequent itemsets): Implement the Apriori algorithm to find the frequent itemsets. This is the algorithms we discussed in class. The algorithm is described in ...


MIS2502: Final Exam Study Guide Page MIS2502: Final Exam Study
... Be able to read the output from a cluster analysis o And interpret a scatter plot of 2 dimensional data (i.e., the baseball example from the slides) Understand the difference between cohesion and separation Mean statistics – interpret root mean squared standard deviation and distance to nearest clus ...
... Be able to read the output from a cluster analysis o And interpret a scatter plot of 2 dimensional data (i.e., the baseball example from the slides) Understand the difference between cohesion and separation Mean statistics – interpret root mean squared standard deviation and distance to nearest clus ...

ALGORITHM FOR SPATIAL CLUSTERING WITH OBSTACLES
... and we emphasize what we believe are limitations which are addressed by our approach. CLARANS CLARANS (Clustering Large Applications based up on RANdomized Search) was introduced in [NG94] as the first clustering technique in spatial data mining. The algorithm takes as an input the number, k, of the ...
... and we emphasize what we believe are limitations which are addressed by our approach. CLARANS CLARANS (Clustering Large Applications based up on RANdomized Search) was introduced in [NG94] as the first clustering technique in spatial data mining. The algorithm takes as an input the number, k, of the ...

improve the performance
... Introduction to Benchmarking (II): The current situation in other imaging communities ...
... Introduction to Benchmarking (II): The current situation in other imaging communities ...


Clustering
... of k clusters, such that the sum of squared distances is minimized (where ci is the centroid or medoid of cluster Ci) ...
... of k clusters, such that the sum of squared distances is minimized (where ci is the centroid or medoid of cluster Ci) ...

Basic Clustering Concepts & Algorithms
... Hypothesis generation and testing Prediction based on groups Cluster & find characteristics/patterns for each group Finding K-nearest Neighbors Localizing search to one or a small number of clusters Outlier detection: Outliers are often viewed as those “far away” from any cluster ...
... Hypothesis generation and testing Prediction based on groups Cluster & find characteristics/patterns for each group Finding K-nearest Neighbors Localizing search to one or a small number of clusters Outlier detection: Outliers are often viewed as those “far away” from any cluster ...



Improving the orthogonal range search k -windows algorithm
... ionic micro-currents of the brain and originated at the cellular level [1]. The MEG analysis can provide information of vital importance for the monitoring of brain dynamics in both normal and pathological conditions of the Central Nervous System. The MEG signals are recorded with the use of specifi ...
... ionic micro-currents of the brain and originated at the cellular level [1]. The MEG analysis can provide information of vital importance for the monitoring of brain dynamics in both normal and pathological conditions of the Central Nervous System. The MEG signals are recorded with the use of specifi ...



ppt
... Some seeds can result in poor convergence rate, or convergence to sub-optimal clusterings Common heuristics ...
... Some seeds can result in poor convergence rate, or convergence to sub-optimal clusterings Common heuristics ...

Multi-view Subspace Clustering for High
... The data today is towards more observations and very high dimensions. Large high-dimensional data are usually sparse and contain many classes/clusters. For example, large text data in the vector space model often contains many classes of documents represented in thousands of terms. It has become a r ...
... The data today is towards more observations and very high dimensions. Large high-dimensional data are usually sparse and contain many classes/clusters. For example, large text data in the vector space model often contains many classes of documents represented in thousands of terms. It has become a r ...

New Method for Finding Initial Cluster Centroids in K
... 10K centre points. These 10K points are then given as input to the K-means algorithm and the algorithm run 10 times, each of the 10 runs initialized using the K final centroid locations from one of the 10 subset runs. The result thus obtained is initial cluster centroids for the K-means algorithm [7 ...
... 10K centre points. These 10K points are then given as input to the K-means algorithm and the algorithm run 10 times, each of the 10 runs initialized using the K final centroid locations from one of the 10 subset runs. The result thus obtained is initial cluster centroids for the K-means algorithm [7 ...


IJARCCE 12
... clustering method, which is used to identify spatial structures that may be present in the data. Experimental results indicate that, when compared with existing clustering methods, CLARANS is very efficient and effective. Fig 3: Steps of CLARANS algorithm. ...
... clustering method, which is used to identify spatial structures that may be present in the data. Experimental results indicate that, when compared with existing clustering methods, CLARANS is very efficient and effective. Fig 3: Steps of CLARANS algorithm. ...