
Density-Based Spatial Clustering
... under Density-based spatial clustering. A. DBSCAN (Density-Based Spatial Clustering of Application with Noise) DBSCAN [4] is a density-based clustering algorithm which is designed to discover clusters and noise of spatial objects in spatial database. It is necessary to know the parameters ε and MinP ...
... under Density-based spatial clustering. A. DBSCAN (Density-Based Spatial Clustering of Application with Noise) DBSCAN [4] is a density-based clustering algorithm which is designed to discover clusters and noise of spatial objects in spatial database. It is necessary to know the parameters ε and MinP ...

Full Paper (PDF 376832 bytes). - Vanderbilt University School of
... Both classification and clustering schemes require data objects to be defined in terms of a predefined set of features. Features represent properties of the object that are relevant to the problem solving task. For example, if we wish to classify automobiles by speed and power, body weight, body sha ...
... Both classification and clustering schemes require data objects to be defined in terms of a predefined set of features. Features represent properties of the object that are relevant to the problem solving task. For example, if we wish to classify automobiles by speed and power, body weight, body sha ...

JMIS2015 - Lingnan University
... strategies such as SMOTE<> [8]. With more balanced training data between the classes, the classification tool may have sufficiently more opportunities to learn the model structures and
improve classification accuracy.
Alternatively, decision support sy ...
... strategies such as SMOTE<



C2P: Clustering based on Closest Pairs
... queries and the R∗ -tree index structure are used to focus only on related portions of the database. DBSCAN [EKSX96] is a density-based clustering algorithm for spatial databases. DBSCAN is based on parameters that are difficult to determine, whereas DBCLASS [XEKS98] does not present this requirement ...
... queries and the R∗ -tree index structure are used to focus only on related portions of the database. DBSCAN [EKSX96] is a density-based clustering algorithm for spatial databases. DBSCAN is based on parameters that are difficult to determine, whereas DBCLASS [XEKS98] does not present this requirement ...

Contents
... in the general data set overall). Therefore, a test set is used, made up of test tuples and their associated class labels. These tuples are randomly selected from the general data set. They are independent of the training tuples, meaning that they are not used to construct the classifier. The accura ...
... in the general data set overall). Therefore, a test set is used, made up of test tuples and their associated class labels. These tuples are randomly selected from the general data set. They are independent of the training tuples, meaning that they are not used to construct the classifier. The accura ...

Spatio-temporal clustering
... Geo-referenced variables. When it is possible to observe the evolution in time of some phenomena in a fixed location, we have what is usually called a geo-referenced variable, i.e., the time-changing value of some observed property. In particular, the basic settings might allow only to remember the m ...
... Geo-referenced variables. When it is possible to observe the evolution in time of some phenomena in a fixed location, we have what is usually called a geo-referenced variable, i.e., the time-changing value of some observed property. In particular, the basic settings might allow only to remember the m ...
part_3
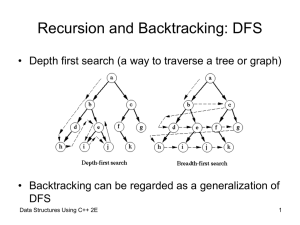
... Puzzle (cont’d.) • Backtracking algorithm – Find problem solutions by constructing partial solutions – Ensures partial solution does not violate requirements – Extends partial solution toward completion – If partial solution does not lead to a solution (dead end) • Algorithm backs up • Removes most ...
... Puzzle (cont’d.) • Backtracking algorithm – Find problem solutions by constructing partial solutions – Ensures partial solution does not violate requirements – Extends partial solution toward completion – If partial solution does not lead to a solution (dead end) • Algorithm backs up • Removes most ...





clustering large-scale data based on modified affinity propagation
... process of finding the parameters is very time consuming because each change of any parameter will require re-running the algorithm. KAP [20] was developed to address AP drawback. KAP is able to generate K clusters according to what a user specifies by adding one constraint in the message passing pr ...
... process of finding the parameters is very time consuming because each change of any parameter will require re-running the algorithm. KAP [20] was developed to address AP drawback. KAP is able to generate K clusters according to what a user specifies by adding one constraint in the message passing pr ...

Mining the FIRST Astronomical Survey Imola K. Fodor and Chandrika Kamath
... – find the largest (in abs value) coefficient V j , p , and discard the corresponding original variable X j – repeat the procedure w/ the second-to-last PC, and iterate until only 20 variables remain Call these PCA features ...
... – find the largest (in abs value) coefficient V j , p , and discard the corresponding original variable X j – repeat the procedure w/ the second-to-last PC, and iterate until only 20 variables remain Call these PCA features ...




Outlier Detection - SFU computing science
... • If only some labeled outliers are available, a small number of labeled outliers many not cover the possible outliers well – To improve the quality of outlier detection, one can get help from models for normal objects learned from unsupervised methods Jian Pei: CMPT 741/459 Data Mining -- Outlier ...
... • If only some labeled outliers are available, a small number of labeled outliers many not cover the possible outliers well – To improve the quality of outlier detection, one can get help from models for normal objects learned from unsupervised methods Jian Pei: CMPT 741/459 Data Mining -- Outlier ...

Feature Selection: A Practitioner View
... LASSO, LARS, 1-norm support vector etc. Wrapper Approach: In this method, the feature selection is approached considering the data mining algorithm as a black box. All possible combinations of the feature sets are used and tested exhaustively for the target data mining algorithm and it typically use ...
... LASSO, LARS, 1-norm support vector etc. Wrapper Approach: In this method, the feature selection is approached considering the data mining algorithm as a black box. All possible combinations of the feature sets are used and tested exhaustively for the target data mining algorithm and it typically use ...


Generalizing Self-Organizing Map for Categorical Data
... projected data preserves the topological relationship of the original data; therefore, this ordered grid can be used as a convenient visualization surface for showing various features of the training data, for example, cluster structures [3]. Since it was originally proposed, the SOM has had many ap ...
... projected data preserves the topological relationship of the original data; therefore, this ordered grid can be used as a convenient visualization surface for showing various features of the training data, for example, cluster structures [3]. Since it was originally proposed, the SOM has had many ap ...


Review Paper on Clustering and Validation Techniques
... For example, readability is an important aspect in the performance of multi-document summarization. In future work, we will consider new soft cluster algorithm to more improve the efficiency of clustering. Cluster Analysis is a process of grouping the objects, called as a cluster/s, which consists o ...
... For example, readability is an important aspect in the performance of multi-document summarization. In future work, we will consider new soft cluster algorithm to more improve the efficiency of clustering. Cluster Analysis is a process of grouping the objects, called as a cluster/s, which consists o ...

K-nearest neighbors algorithm

In pattern recognition, the k-Nearest Neighbors algorithm (or k-NN for short) is a non-parametric method used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression: In k-NN classification, the output is a class membership. An object is classified by a majority vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor. In k-NN regression, the output is the property value for the object. This value is the average of the values of its k nearest neighbors.k-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally and all computation is deferred until classification. The k-NN algorithm is among the simplest of all machine learning algorithms.Both for classification and regression, it can be useful to assign weight to the contributions of the neighbors, so that the nearer neighbors contribute more to the average than the more distant ones. For example, a common weighting scheme consists in giving each neighbor a weight of 1/d, where d is the distance to the neighbor.The neighbors are taken from a set of objects for which the class (for k-NN classification) or the object property value (for k-NN regression) is known. This can be thought of as the training set for the algorithm, though no explicit training step is required.A shortcoming of the k-NN algorithm is that it is sensitive to the local structure of the data. The algorithm has nothing to do with and is not to be confused with k-means, another popular machine learning technique.