
Finding Personally Identifying Inforamtion
... Compute a function to recover the original data distribution from the randomized values Not always secure – random noise can be filtered in certain circumstances to accurately estimate original data values ...
... Compute a function to recover the original data distribution from the randomized values Not always secure – random noise can be filtered in certain circumstances to accurately estimate original data values ...


CE417 - Data Mining Course - Fall 1386 Homework
... (5) Describe three classifications of dimensionality reduction techniques, and discuss the advantages and disadvantages of each class in each classification. (6) Imagine that we have a function Dc that accepts as input only a single numerical attribute of a dataset and converts it to a nominal attri ...
... (5) Describe three classifications of dimensionality reduction techniques, and discuss the advantages and disadvantages of each class in each classification. (6) Imagine that we have a function Dc that accepts as input only a single numerical attribute of a dataset and converts it to a nominal attri ...

WYDZIAŁ
... Emergence and evolution of knowledge discovery systems. The general schema of knowledge discovery and the data mining phase. The comparison of existing data analysis methods: i) query and reports, ii) online analytical processing and iii) data mining. Data warehouses and data marts. Data warehouse d ...
... Emergence and evolution of knowledge discovery systems. The general schema of knowledge discovery and the data mining phase. The comparison of existing data analysis methods: i) query and reports, ii) online analytical processing and iii) data mining. Data warehouses and data marts. Data warehouse d ...

Bibliography
... Emergence and evolution of knowledge discovery systems. The general schema of knowledge discovery and the data mining phase. The comparison of existing data analysis methods: i) query and reports, ii) online analytical processing and iii) data mining. Data warehouses and data marts. Data warehouse d ...
... Emergence and evolution of knowledge discovery systems. The general schema of knowledge discovery and the data mining phase. The comparison of existing data analysis methods: i) query and reports, ii) online analytical processing and iii) data mining. Data warehouses and data marts. Data warehouse d ...

WYDZIAŁ
... Emergence and evolution of knowledge discovery systems. The general schema of knowledge discovery and the data mining phase. The comparison of existing data analysis methods: i) query and reports, ii) online analytical processing and iii) data mining. Data warehouses and data marts. Data warehouse d ...
... Emergence and evolution of knowledge discovery systems. The general schema of knowledge discovery and the data mining phase. The comparison of existing data analysis methods: i) query and reports, ii) online analytical processing and iii) data mining. Data warehouses and data marts. Data warehouse d ...

slides - UCLA Computer Science
... A divide-and-conquer approach Simple algorithm, intuitive model ...
... A divide-and-conquer approach Simple algorithm, intuitive model ...

Joseph JaJa Fall 2005 Course Syllabus
... ENEE759G: Data Mining and Knowledge Discovery Instructor: Joseph JaJa Fall 2005 Course Syllabus Course Objectives: The course will cover fundamental techniques used for analyzing and classifying large scale scientific and business data. These techniques, primarily based on machine learning and stati ...
... ENEE759G: Data Mining and Knowledge Discovery Instructor: Joseph JaJa Fall 2005 Course Syllabus Course Objectives: The course will cover fundamental techniques used for analyzing and classifying large scale scientific and business data. These techniques, primarily based on machine learning and stati ...

Machine Learning Specialist
... machine learning, predictive analytics, data mining and statistics. Develop and maintain the Data Science infrastructure: Conduct preliminary data exploration and data preparation steps. Perform variable/algorithm selection, model development and validation, metrics definition and scoring/ranking. M ...
... machine learning, predictive analytics, data mining and statistics. Develop and maintain the Data Science infrastructure: Conduct preliminary data exploration and data preparation steps. Perform variable/algorithm selection, model development and validation, metrics definition and scoring/ranking. M ...


Spring 2013 Statistics 702: Data Mining Statistical Methods
... Class participation and presentation: 15% Final project: 25% Note that any regrading request on assignments or exams has to be made within one week after the paper is returned. ...
... Class participation and presentation: 15% Final project: 25% Note that any regrading request on assignments or exams has to be made within one week after the paper is returned. ...


統計資料採礦
... The mission of the Department of Statistics is to cultivate quality professionals with enthusiasm and global perspectives. Graduate Program Learning Goals (goals covered by this course are indicated): ...
... The mission of the Department of Statistics is to cultivate quality professionals with enthusiasm and global perspectives. Graduate Program Learning Goals (goals covered by this course are indicated): ...

ementa - Escola de Inverno
... Based on the unprecedented increase in unstructured data generation rate in various fields of human knowledge, there is a growing need, both from a scientific point of view as well as from a practical point of view, to extract useful information from these immense volume of data. Data mining is the ...
... Based on the unprecedented increase in unstructured data generation rate in various fields of human knowledge, there is a growing need, both from a scientific point of view as well as from a practical point of view, to extract useful information from these immense volume of data. Data mining is the ...

Course Description Approaches to finding the unexpected in data: data min-
... Approaches to finding the unexpected in data: data mining, pattern recognition and understanding. Emphasis is on data-centered, non-inferential statistics, for large or high-dimensional data, and topical problems. Simple graphical methods, as well as classical and computerintensive methods applied i ...
... Approaches to finding the unexpected in data: data mining, pattern recognition and understanding. Emphasis is on data-centered, non-inferential statistics, for large or high-dimensional data, and topical problems. Simple graphical methods, as well as classical and computerintensive methods applied i ...

Linear Regression Data mining by WEKA
... Data Description Cost Data for U.S. Airlines, 90 Oservations On 6 Firms For 15 Years, 1970-1984 Source: These data are a subset of a larger data set provided to the author by Professor Moshe Kim. They were originally constructed by Christensen Associates of Madison, Wisconsin. I consider following ...
... Data Description Cost Data for U.S. Airlines, 90 Oservations On 6 Firms For 15 Years, 1970-1984 Source: These data are a subset of a larger data set provided to the author by Professor Moshe Kim. They were originally constructed by Christensen Associates of Madison, Wisconsin. I consider following ...
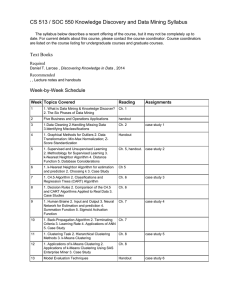
CS 513 / SOC 550 Knowledge Discovery and Data Mining Syllabus
... CS 513 / SOC 550 Knowledge Discovery and Data Mining Syllabus The syllabus below describes a recent offering of the course, but it may not be completely up to date. For current details about this course, please contact the course coordinator. Course coordinators are listed on the course listing for ...
... CS 513 / SOC 550 Knowledge Discovery and Data Mining Syllabus The syllabus below describes a recent offering of the course, but it may not be completely up to date. For current details about this course, please contact the course coordinator. Course coordinators are listed on the course listing for ...

Equivalence Classes: Another way to envision the traversal is to first
... representation on the left is called a horizontal data layout, which is adopted by many association rule mining algorithms, including Apriori. Another possibility is to store the list of transaction identifiers (TID-list) associated with each item. Such a representation is known as the vertical data ...
... representation on the left is called a horizontal data layout, which is adopted by many association rule mining algorithms, including Apriori. Another possibility is to store the list of transaction identifiers (TID-list) associated with each item. Such a representation is known as the vertical data ...

Machine Learning - Department of Computer Science and
... artificial intelligence concerned with algorithms that allow computers to learn. What this means, in most cases, is that algorithm is given a set of data and infers information about the properties of data – and that information allows it to make predictions about other data that might see in the fu ...
... artificial intelligence concerned with algorithms that allow computers to learn. What this means, in most cases, is that algorithm is given a set of data and infers information about the properties of data – and that information allows it to make predictions about other data that might see in the fu ...

H 566 Data Mining Syllabus
... Provide clear and concise interpretations and written and oral presentations of an analysis of a high-dimensional data set arising in a biological, medical, or public health application using at least one modern technique. Course Content: This course is designed as a survey of and introduction to hi ...
... Provide clear and concise interpretations and written and oral presentations of an analysis of a high-dimensional data set arising in a biological, medical, or public health application using at least one modern technique. Course Content: This course is designed as a survey of and introduction to hi ...

CAP 4770 Introdution Data Mining and Machine Intelligence
... Reference materials: Research papers which will be distributed in the class Specific course information: Catalog description: This course deals with the principles of data mining. Topics include machine learning methods, knowledge discovery and representation, clustering, classification and predicti ...
... Reference materials: Research papers which will be distributed in the class Specific course information: Catalog description: This course deals with the principles of data mining. Topics include machine learning methods, knowledge discovery and representation, clustering, classification and predicti ...

Adithya_ParallelCoordinatePresentation
... • Understanding data of more than 3 dimensions • Reduction techniques might be applied • Backdrop of these might be the user want to still analyze the data based on original attributes instead of transformed or reduced attributes. ...
... • Understanding data of more than 3 dimensions • Reduction techniques might be applied • Backdrop of these might be the user want to still analyze the data based on original attributes instead of transformed or reduced attributes. ...

College of Health and Human Sciences Department of Public Health
... Provide clear and concise interpretations and written and oral presentations of an analysis of a high-dimensional data set arising in a biological, medical, or public health application using at least one modern technique. Course Content: This course is designed as a survey of and introduction to hi ...
... Provide clear and concise interpretations and written and oral presentations of an analysis of a high-dimensional data set arising in a biological, medical, or public health application using at least one modern technique. Course Content: This course is designed as a survey of and introduction to hi ...

University of Sydney Fall 2013 Discipline of Business
... you a zero for the relevant part of the grade unless there is a well documented medical excuse, in which case the weight of the missing part is spread over the remaining parts. Students must notify instructor about religious observances at the beginning of the semester so that they can be accommodat ...
... you a zero for the relevant part of the grade unless there is a well documented medical excuse, in which case the weight of the missing part is spread over the remaining parts. Students must notify instructor about religious observances at the beginning of the semester so that they can be accommodat ...

Contents
... Titus Winters, Christian Shelton, Tom Payne, and Guobiao Mei An Educational Data Mining Tool to Browse Tutor-Student Interactions: Time Will Tell! / 15 Jack Mostow, Joseph Beck, Hao Cen, Andrew Cuneo, Evandro Gouvea, and Cecily Heiner A Data Collection Framework for Capturing ITS Data Based on an Ag ...
... Titus Winters, Christian Shelton, Tom Payne, and Guobiao Mei An Educational Data Mining Tool to Browse Tutor-Student Interactions: Time Will Tell! / 15 Jack Mostow, Joseph Beck, Hao Cen, Andrew Cuneo, Evandro Gouvea, and Cecily Heiner A Data Collection Framework for Capturing ITS Data Based on an Ag ...
Nonlinear dimensionality reduction

High-dimensional data, meaning data that requires more than two or three dimensions to represent, can be difficult to interpret. One approach to simplification is to assume that the data of interest lie on an embedded non-linear manifold within the higher-dimensional space. If the manifold is of low enough dimension, the data can be visualised in the low-dimensional space.Below is a summary of some of the important algorithms from the history of manifold learning and nonlinear dimensionality reduction (NLDR). Many of these non-linear dimensionality reduction methods are related to the linear methods listed below. Non-linear methods can be broadly classified into two groups: those that provide a mapping (either from the high-dimensional space to the low-dimensional embedding or vice versa), and those that just give a visualisation. In the context of machine learning, mapping methods may be viewed as a preliminary feature extraction step, after which pattern recognition algorithms are applied. Typically those that just give a visualisation are based on proximity data – that is, distance measurements.