
CPSC445/545 Introduction to Data Mining Spring 2008
... The file hw3_data.csv contains 1000 observations with two groups (Group 0 and Group 1) and two variables (x and y). You can load the data using the ``read.csv” command in R. 1. Plot all the data points in a 2-dimensional scatter plot. Mark Group 1 points and Group 0 points differently (e.g., one wit ...
... The file hw3_data.csv contains 1000 observations with two groups (Group 0 and Group 1) and two variables (x and y). You can load the data using the ``read.csv” command in R. 1. Plot all the data points in a 2-dimensional scatter plot. Mark Group 1 points and Group 0 points differently (e.g., one wit ...

Environmental Data Mining
... visualization. It plays an extremely important role in data mining in different scientific fields and in many practical applications. At present ML is widely used as an efficient tool in GI Sciences, rem ...
... visualization. It plays an extremely important role in data mining in different scientific fields and in many practical applications. At present ML is widely used as an efficient tool in GI Sciences, rem ...


Stat 202: Data Mining Professor: Art Owen
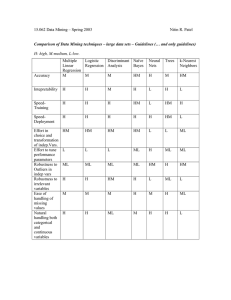
... selection of topics, such as: Association rules, Clustering, Decision Trees, Neural networks, and Nearest Neighbors. ...
... selection of topics, such as: Association rules, Clustering, Decision Trees, Neural networks, and Nearest Neighbors. ...

Selecting Data Mining and Statistical Procedures in Scientific
... All interested are welcome Abstract ...
... All interested are welcome Abstract ...

Data Mining and Machine Learning for Modeling Driving
... Automated vehicles are still in the development phase. Our team develops solutions for highly automated vehicles. These solutions are based on driver models generated by data mining and machine learning algorithms that transform massive amounts of vehicle trajectories into descriptive knowledge abou ...
... Automated vehicles are still in the development phase. Our team develops solutions for highly automated vehicles. These solutions are based on driver models generated by data mining and machine learning algorithms that transform massive amounts of vehicle trajectories into descriptive knowledge abou ...


Eidetic Design
... •…to the specific perceptual domain in which humans are experts in intuitively grasping the context, the character and the reasons of the issue at hand •I.e., visualization, audibilization, “perceptualization”, … ...
... •…to the specific perceptual domain in which humans are experts in intuitively grasping the context, the character and the reasons of the issue at hand •I.e., visualization, audibilization, “perceptualization”, … ...





13 11 Ray Lloyd
... to control and manage the inlets To control and manage the inlets we need to know at what temperature they are Squish ...
... to control and manage the inlets To control and manage the inlets we need to know at what temperature they are Squish ...



SE-516 DATA MINING UNIT-I Introduction : Challenges – Origins of
... DBSCAN Cluster evaluation on Characteristics of Data, Clusters, and Clustering Algorithms. Suggested Reading: 1. Pang-Ning Tan Michael Steinbach, Vipin kumar, “Introduction to Data Minings “,Pearson Education.2008. 2. K.P. Soman, Shyam Diwakar, V.Ajay, “Insight into Data Mining Theory and Practice , ...
... DBSCAN Cluster evaluation on Characteristics of Data, Clusters, and Clustering Algorithms. Suggested Reading: 1. Pang-Ning Tan Michael Steinbach, Vipin kumar, “Introduction to Data Minings “,Pearson Education.2008. 2. K.P. Soman, Shyam Diwakar, V.Ajay, “Insight into Data Mining Theory and Practice , ...

Visualization in hyperspace: making visual inferences for multivariate data VOTech/University of Leeds
... hierachical clustering ...
... hierachical clustering ...


Zahid Islam
... • We can protect the privacy of your data subjects both on-line and off-line. We successfully applied our data mining algorithms on • Irrigation Water Demand Prediction. • Software Defect Prediction. • Employee Behaviour Analysis. • Customer behaviour analysis such as brand switching. We can perform ...
... • We can protect the privacy of your data subjects both on-line and off-line. We successfully applied our data mining algorithms on • Irrigation Water Demand Prediction. • Software Defect Prediction. • Employee Behaviour Analysis. • Customer behaviour analysis such as brand switching. We can perform ...

algorithm
... On Algorithms • what is worth? Specialized algorithms: best performance for special problems Generic algorithms: good performance over a wide range of ...
... On Algorithms • what is worth? Specialized algorithms: best performance for special problems Generic algorithms: good performance over a wide range of ...


Open Position- Interns
... Research Intern – Microsoft’s Recommendations Team (Herzeliya) The recommendation team in Israel is a fast growing team responsible for designing and building recommendation algorithms for a wide array of Microsoft products such as Xbox Games, Xbox Movies, Groove Music, Windows Store, Windows Phone, ...
... Research Intern – Microsoft’s Recommendations Team (Herzeliya) The recommendation team in Israel is a fast growing team responsible for designing and building recommendation algorithms for a wide array of Microsoft products such as Xbox Games, Xbox Movies, Groove Music, Windows Store, Windows Phone, ...
Gene Codes introduces CodeLinker
... normalized you have numerous data analysis options, such as: ...
... normalized you have numerous data analysis options, such as: ...

Summary
... Principal Components Analysis (PCA) Find the principal directions in the data, and use them to reduce the number of dimensions of the set by representing the data in linear combinations of the principal components. Works best for multivariate data. Finds the m < d eigen-vectors of the covariance mat ...
... Principal Components Analysis (PCA) Find the principal directions in the data, and use them to reduce the number of dimensions of the set by representing the data in linear combinations of the principal components. Works best for multivariate data. Finds the m < d eigen-vectors of the covariance mat ...
Nonlinear dimensionality reduction

High-dimensional data, meaning data that requires more than two or three dimensions to represent, can be difficult to interpret. One approach to simplification is to assume that the data of interest lie on an embedded non-linear manifold within the higher-dimensional space. If the manifold is of low enough dimension, the data can be visualised in the low-dimensional space.Below is a summary of some of the important algorithms from the history of manifold learning and nonlinear dimensionality reduction (NLDR). Many of these non-linear dimensionality reduction methods are related to the linear methods listed below. Non-linear methods can be broadly classified into two groups: those that provide a mapping (either from the high-dimensional space to the low-dimensional embedding or vice versa), and those that just give a visualisation. In the context of machine learning, mapping methods may be viewed as a preliminary feature extraction step, after which pattern recognition algorithms are applied. Typically those that just give a visualisation are based on proximity data – that is, distance measurements.