
Descriptive Statistics and Exploratory Data Analysis
... trial etc. It is important to find out why an observation is missing. This is best done by asking ‘people in the field’. In particular, there is a world of difference between observations lost through random event, and situations where missing observations are created deliberately. Further the proba ...
... trial etc. It is important to find out why an observation is missing. This is best done by asking ‘people in the field’. In particular, there is a world of difference between observations lost through random event, and situations where missing observations are created deliberately. Further the proba ...










File - Elisha Kostka
... value is determined by taking the maximum of the spots showing on either of the two dice thrown. For example, if a 3 and a 5 were thrown, then X would take the value of Maximum(3,5) = 5. The range of values that X can assume are the positive integers 1,2,3,4,5,6. ...
... value is determined by taking the maximum of the spots showing on either of the two dice thrown. For example, if a 3 and a 5 were thrown, then X would take the value of Maximum(3,5) = 5. The range of values that X can assume are the positive integers 1,2,3,4,5,6. ...

STT 315 Pathak - Exam 1 - Practice Exam Solutions
... 13. B – There are no outliers Outlier – A data point that is not consistent with the majority of the data You can identify outliers in a histogram by looking for gaps in the data. Gaps in a histogram represent areas of a distribution where there are no recorded values. If there is a gap in a his ...
... 13. B – There are no outliers Outlier – A data point that is not consistent with the majority of the data You can identify outliers in a histogram by looking for gaps in the data. Gaps in a histogram represent areas of a distribution where there are no recorded values. If there is a gap in a his ...




Multi-Conditional Learning: Generative/Discriminative Training for
... a globally normalized product of local functions. In our experiments here we shall use the harmonium’s factorization structure to define an MRF and we will then define sets of marginal conditionals distributions of some observed variables given others that are of particular interest so as to form ou ...
... a globally normalized product of local functions. In our experiments here we shall use the harmonium’s factorization structure to define an MRF and we will then define sets of marginal conditionals distributions of some observed variables given others that are of particular interest so as to form ou ...


ing of accuracy for timely decisions, and social issues (privacy, discrimina-
... of transactions for acceptable users. Jake Ryan, Meng-Jang Lin, and Risto Miikulainen (all of University of Texas) train backpropagation neural networks to recognize the typical commands of a computer user. An anomaly is signaled if the neural network does not classify the new commands as the actual ...
... of transactions for acceptable users. Jake Ryan, Meng-Jang Lin, and Risto Miikulainen (all of University of Texas) train backpropagation neural networks to recognize the typical commands of a computer user. An anomaly is signaled if the neural network does not classify the new commands as the actual ...


PROBABILITY TOPICS: HOMEWORK
... II. How should the <20,000 and the 100,000+ intervals be handled? Why? d. Find the 40th and 80th percentiles EXERCISE 5 Following are the published weights (in pounds) of all of the team members of the San Francisco 49ers from a previous year (Source: San Jose Mercury News). ...
... II. How should the <20,000 and the 100,000+ intervals be handled? Why? d. Find the 40th and 80th percentiles EXERCISE 5 Following are the published weights (in pounds) of all of the team members of the San Francisco 49ers from a previous year (Source: San Jose Mercury News). ...
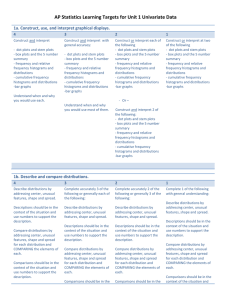
AP Statistics Learning Targets for Unit 1 Univariate Data
... Given two x-values on a normal curve and a mean and a standard deviation determine the percentage of data between those values. Given a percentage of data in an area (either above or below an x-value) on a normal curve, determine the x-value that bounds that area. Given a percentage of data between ...
... Given two x-values on a normal curve and a mean and a standard deviation determine the percentage of data between those values. Given a percentage of data in an area (either above or below an x-value) on a normal curve, determine the x-value that bounds that area. Given a percentage of data between ...


CS607_Current_Subjective
... How does neural network resemble the human brain? Answer:- (Page 187) It resembles the brain in two respects • Knowledge is acquired by the network through a learning process (called training) • Interneuron connection strengths known as synaptic weights are used to store the knowledge Elaborate the ...
... How does neural network resemble the human brain? Answer:- (Page 187) It resembles the brain in two respects • Knowledge is acquired by the network through a learning process (called training) • Interneuron connection strengths known as synaptic weights are used to store the knowledge Elaborate the ...


Time series

A time series is a sequence of data points, typically consisting of successive measurements made over a time interval. Examples of time series are ocean tides, counts of sunspots, and the daily closing value of the Dow Jones Industrial Average. Time series are very frequently plotted via line charts. Time series are used in statistics, signal processing, pattern recognition, econometrics, mathematical finance, weather forecasting, intelligent transport and trajectory forecasting, earthquake prediction, electroencephalography, control engineering, astronomy, communications engineering, and largely in any domain of applied science and engineering which involves temporal measurements.Time series analysis comprises methods for analyzing time series data in order to extract meaningful statistics and other characteristics of the data. Time series forecasting is the use of a model to predict future values based on previously observed values. While regression analysis is often employed in such a way as to test theories that the current values of one or more independent time series affect the current value of another time series, this type of analysis of time series is not called ""time series analysis"", which focuses on comparing values of a single time series or multiple dependent time series at different points in time.Time series data have a natural temporal ordering. This makes time series analysis distinct from cross-sectional studies, in which there is no natural ordering of the observations (e.g. explaining people's wages by reference to their respective education levels, where the individuals' data could be entered in any order). Time series analysis is also distinct from spatial data analysis where the observations typically relate to geographical locations (e.g. accounting for house prices by the location as well as the intrinsic characteristics of the houses). A stochastic model for a time series will generally reflect the fact that observations close together in time will be more closely related than observations further apart. In addition, time series models will often make use of the natural one-way ordering of time so that values for a given period will be expressed as deriving in some way from past values, rather than from future values (see time reversibility.)Time series analysis can be applied to real-valued, continuous data, discrete numeric data, or discrete symbolic data (i.e. sequences of characters, such as letters and words in the English language.).