

A Neural Model of Rule Generation in Inductive Reasoning
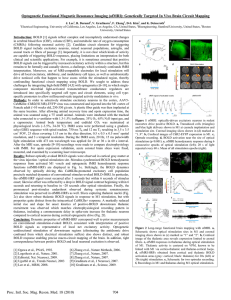
... top with one blank cell, and the eight possible answers for that blank cell are given below. In order to solve this matrix, the subject needs to generate three rules: (a) the number of triangles increases by one across the row, (b) the orientation of the triangles is constant across the row, (c) eac ...
... top with one blank cell, and the eight possible answers for that blank cell are given below. In order to solve this matrix, the subject needs to generate three rules: (a) the number of triangles increases by one across the row, (b) the orientation of the triangles is constant across the row, (c) eac ...

Rich Probabilistic Models for Genomic Data
... L P( X m | Gm ) P(Gm ) P( X f | G f ) P(G f ) P( X o | Go ) P(Go | Gm , G f ) Gm G f Go1 ...
... L P( X m | Gm ) P(Gm ) P( X f | G f ) P(G f ) P( X o | Go ) P(Go | Gm , G f ) Gm G f Go1 ...

77
... computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis. The standard SVM takes a set of input data and predicts, for each given input, which of two possible classes the input is a member of, which ma ...
... computer science for a set of related supervised learning methods that analyze data and recognize patterns, used for classification and regression analysis. The standard SVM takes a set of input data and predicts, for each given input, which of two possible classes the input is a member of, which ma ...

Transfer Learning of Latin and Greek Characters in
... sets. Its is very apparent from Figure 4.1 that these are the weights used to classify the Greek letter. Each separate square in Figure 4.1 and 4.2 corresponds to a weight matrix of the connections of the 576 (24 × 24) input neurons to each of the 36 hidden neurons. A lighter colour means a stronger ...
... sets. Its is very apparent from Figure 4.1 that these are the weights used to classify the Greek letter. Each separate square in Figure 4.1 and 4.2 corresponds to a weight matrix of the connections of the 576 (24 × 24) input neurons to each of the 36 hidden neurons. A lighter colour means a stronger ...

Quiz Answers
... a) The neuron would fire no matter what. b) The neuron would tally up the mere number of excitatory inputs versus that of the inhibitory inputs. (eg. 6 versus 4) c) The neuron would stay at rest due to confusion. d) The neuron would integrate the information based upon the summed depolarization that ...
... a) The neuron would fire no matter what. b) The neuron would tally up the mere number of excitatory inputs versus that of the inhibitory inputs. (eg. 6 versus 4) c) The neuron would stay at rest due to confusion. d) The neuron would integrate the information based upon the summed depolarization that ...

THE NATURE OF MODELING by Jeff Rothenberg Chapter for "AI
... conditions of the model itself) that can lead to a given result. This is analogous to the use of if−then rules in the backward direction (i.e., "backward chaining") or to mathematical optimization techniques. There are also definitive questions that ask whether certain states, conditions, or actions ...
... conditions of the model itself) that can lead to a given result. This is analogous to the use of if−then rules in the backward direction (i.e., "backward chaining") or to mathematical optimization techniques. There are also definitive questions that ask whether certain states, conditions, or actions ...


The human brain has on average 100 billion neurons, to each
... represented in this model includes the neuronal populations of the cortex and the thalamus (see across). Why these in particular? It seems quite obvious why the cerebral cortex should be included. Not only does it comprise the greatest volume of the brain, but it is the structure that lies closest t ...
... represented in this model includes the neuronal populations of the cortex and the thalamus (see across). Why these in particular? It seems quite obvious why the cerebral cortex should be included. Not only does it comprise the greatest volume of the brain, but it is the structure that lies closest t ...



Neuron File
... synapses onto other neurons as it goes. Many neurons fit the foregoing schema in every respect, but there are also exceptions to most parts of it. There are no neurons that lack a soma, but there are neurons that lack dendrites, and others that lack an axon. Furthermore, in addition to the typical a ...
... synapses onto other neurons as it goes. Many neurons fit the foregoing schema in every respect, but there are also exceptions to most parts of it. There are no neurons that lack a soma, but there are neurons that lack dendrites, and others that lack an axon. Furthermore, in addition to the typical a ...

S013513518
... Cleveland Heart Diseases dataset. Further we have enhanced Sensitivity, Specificity and Accuracy of MLP, using Dagging approach. MLP with Dagging approach had showed good results and attained accuracy of 84.58%. So more applications would bring out the efficiency of this model over other models when ...
... Cleveland Heart Diseases dataset. Further we have enhanced Sensitivity, Specificity and Accuracy of MLP, using Dagging approach. MLP with Dagging approach had showed good results and attained accuracy of 84.58%. So more applications would bring out the efficiency of this model over other models when ...

REASONING ANd dECISION - Université Paul Sabatier
... logic, or appears as an interval of possible numerical values of an ill-known quantity, or even as a set of attributes that does not allow for the precise description of an object. To understand such situations, we need another probabilistic concept, so-called subjectivistism, where a probability do ...
... logic, or appears as an interval of possible numerical values of an ill-known quantity, or even as a set of attributes that does not allow for the precise description of an object. To understand such situations, we need another probabilistic concept, so-called subjectivistism, where a probability do ...


Pointing the way toward target selection
... interest and then allowing the visual system to select a target within this region. Recurrent networks can perform a number of other computations of relevance to sensory processing. For example, if the recurrent connections are strong enough, a particular hill of activity can be maintained even afte ...
... interest and then allowing the visual system to select a target within this region. Recurrent networks can perform a number of other computations of relevance to sensory processing. For example, if the recurrent connections are strong enough, a particular hill of activity can be maintained even afte ...



Document
... many connecting weights, and hence complex models. Without sufficient data to support training, overcomplex models are prone to overfitting. Unfortunately, in many bioinformatic problems, huge data sets can be simply unavailable. Even when they are available, analysing them is often very computation ...
... many connecting weights, and hence complex models. Without sufficient data to support training, overcomplex models are prone to overfitting. Unfortunately, in many bioinformatic problems, huge data sets can be simply unavailable. Even when they are available, analysing them is often very computation ...

Towards a robotic model of the mirror neuron system
... All units have trainable thresholds (biases) that are updated in a similar way as weights (being fed with a constant input 1). IV. ...
... All units have trainable thresholds (biases) that are updated in a similar way as weights (being fed with a constant input 1). IV. ...

PDF
... – Learning algorithm is given the correct value of the function for particular inputs Æ training examples – An example is a pair (x, f(x)), where x is the input and f(x) is the output of the function applied to x. ...
... – Learning algorithm is given the correct value of the function for particular inputs Æ training examples – An example is a pair (x, f(x)), where x is the input and f(x) is the output of the function applied to x. ...


