Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
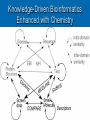
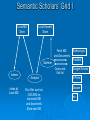
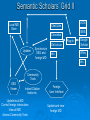
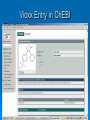
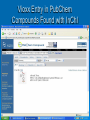
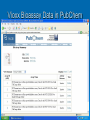
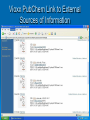
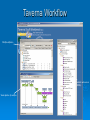
Mopping up the Flood of Data with Web Services Gary Wiggins Indiana University School of Informatics [email protected] Overview of the Talk Data Mining and Knowledge Discovery DMKD in Bioinformatics DMKD in Chemistry Public Chemistry Databases for DMKD Overview of Web Services NIH-funded Projects Underway or Planned at Indiana University Educational Opportunities at IU Data Mining and Knowledge Discovery (DMKD) Techniques began to be used around 1989 Rapid growth in the mid 1990s, with DMKD field emerging around 1995 Built on DM tools such as Machine Learning Data Mining One of the steps in Knowledge Discovery Concerned with the actual extraction of knowledge from data Efficient and scalable methods for mining interesting patterns and knowledge and discovering hidden facts contained in large databases Data Mining Techniques Efficient classification methods Clustering Outlier analysis Frequent, sequential, and structured pattern analysis Visualization and spatial/temporal analysis tools Knowledge Discovery (KD) “KD is a nontrivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns from large collections of data.” --Fayyad et al., as quoted by Cios and Kurgan The KD process involves: Understanding and preparation of the data Data Mining (DM) Verification and application of the discovered knowledge Framework for KD Process Steps range from very few, e.g., Data collection and understanding Data mining Implementation To multi-step models, e.g., Cios and Kurgan’s six-step DMKD process model Cios and Kurgan’s Six-Step DMKD Process Model Understanding the problem domain Understanding the data Preparation of the data ~50% or more of effort spent on this step Data mining Evaluation of the discovered knowledge Using the discovered knowledge General Data Mining/ Data Analysis Systems SAS Enterprise Miner SPSS Insightful S-Plus IBM DB2 Intelligent Miner Microsoft SQLServer 2005 SGI MLC++ and MineSet Tree Visualizer Inxight VizServer Trends: Major Conferences Knowledge Discovery and Data Mining (KDD) 2005 International Conference on Machine Learning (ICML) 2006 http://www.informatik.uni-trier.de/~ley/db/conf/kdd/kdd2005.html http://www.icml2006.org/icml2006/technical/accepted.html SIAM Conference on Data Mining 2006 http://www.siam.org/meetings/sdm06/proceedings.htm 12th Annual SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, August 20-23, 2006 Areas of Interest on the Research Track: Applications of data mining (biomedicine, business, e-commerce, defense) Data and result visualization Data warehousing Data mining for community generation, social network analysis and graph-structured data Foundations of data mining Interactive and online data mining KDD framework and process Mining data streams Mining high-dimensional data Mining sensor data Mining text and semi-structured data Mining multi-media data Novel data mining algorithms Privacy and data mining Robust and scalable statistical methods Pre-processing and post-processing for data mining Security issues Spatial and temporal data mining Trends in DMKD OLAP (On-Line Analytical Processing) Data warehousing Association rules High Performance DMKD systems Visualization techniques Applications of DM More recently: Database products that incorporate DM tools New developments in design and implementation of the DMKD process Information visualization products as end-user queries XML XML: the Key to DM and KD? Or simply a data exchange protocol? Allows for the description and storage of structured or semi-structured data and their relationships Can be used to exchange data in a platform-independent way BUT—only one paper at the major conferences listed earlier that dealt with XML XML helps: Standardize communication between diverse DM tools and databases (I/O procedures) Build standard data repositories sharing data between different DM tools that work on different software platforms Implement communication protocols between DM tools Provide a framework for integration of and communication between different DMKD steps Predictive Model Markup Language (PMML) and Other Tools In conjunction with XML, PMML enables the automation of sharing of discovered knowledge between different domains and tools XML-RPC SOAP (Simple Object Access Protocol) UDDI OLAP OLE DB-DM Discovery Informatics: Definition "Discovery Informatics is the study and practice of employing the full spectrum of computing and analytical science and technology to the singular pursuit of discovering new information by identifying and validating patterns in data." --William W. Agresti in 2003 Discovery Informatics Discovery and Application of Information Data Mining and Machine Learning are two aspects of Discovery Informatics. Overview of the Talk Data Mining and Knowledge Discovery DMKD DMKD in Bioinformatics in Chemistry Public Chemistry Databases for DMKD Overview of Web Services NIH-funded Projects Underway or Planned at Indiana University Educational Opportunities at IU Trends: Bioinformatics Conferences International Conference on Instelligent Systems for Molecular Biology (ISMB) 2006 Research in Computational Molecular Biology (RECOMB) 2006 http://ismb2006.cbi.cnptia.embrapa.br/papers.html http://www.informatik.unitrier.de/~ley/db/conf/recomb/recomb2006.html Pacific Symposium on Biocomputing (PSB) 2006 http://helix-web.stanford.edu/psb06/ Main Areas of Research in Bioinformatics Sequence alignment Alternative splicing Microarray analysis Functional analysis Analysis of single nucleotide polymorphisms (SNPs) Natural language text analysis DMKD Sessions at Major Bioinformatics Conferences Databases and Data Integration Text Mining and Information Extraction Semantic Webs Data Mining in Bioinformatics (Bajcsy) Data cleaning, data preprocessing, and semantic integration of heterogeneous, distributed biomedical databases Existing data mining tools for biodata analysis Development of advanced, effective, and scalable data mining methods in biodata analysis Preprocessing of Biodata Integration of multiple microarray gene experiments must resolve inconsistent labels of genes to form a coherent data store. Focus on quantitative quality metrics based on analytical and statistical data descriptors and on relationships among variables. Semantic Integration of Heterogeneous Biomedical Databases Combine multiple sources into a coherent data store Find sematically equivalent real-world entities from several biomedical sources Problems Different labels for the same concept: gene_id vs. g_id Time asynchronization: same gene analyzed at multiple development stages Approaches for Semantic Integration of Biodata Construction of integrated biodata warehouses or biodatabases Construction of a federation of heterogeneous distributed biodatabases Must build up mapping rules or semantic ambiguity resolution rules across multiple databases Existing Data Mining Tools for Biodata Analysis-I Sequence Analysis, e.g., NCBI/BLAST, ClustalW, HMMER, PHYLIP, MEME, TRANSFAC, MDScan, Vector NTI, Sequencher, MacVector Structure Prediction and Visualization, e.g., RasMol, Raster3D, Swiss-Model, Scope, MolScript, Cn3D Existing Data Mining Tools for Biodata Analysis-II Genome Analysis, CAP3, Paracel GenomeAssembler, GenomeScan, GeneMark, GenScan, X-Grail, ORF Finder, GeneBuilder Pathway Analysis e.g., and Visualization, e.g., KEGG, EcoCyc/MetaCyc, GenMapp Microarray Analysis, e.g., ScanAlyze/Cluster/TreeView, Scanalytics MicroArray Suite, Profiler, Silicon Genetics Biospecific Data Analysis Software Systems Agilent GeneSpring Spotfire Invitrogen VectorNTI Text Mining in Bioinformatics Techniques have progressed from simple recognition of terms to extraction of interaction relationships in complex sentences. Search objectives have broadened to a range of problems, e.g., Improving homology search Identifying cellular location Deriving genetic network technologies Current Work in Biomedical Text Mining (Cohen and Hersh) Text mining operates at a finer level of granularity than information retrieval and text summarization. TM examines relationships between specific kinds of information contained within and between documents. Areas of active research: Named entity recognition (genes, proteins, etc.) Text classification Synonym and abbreviation extraction Relationship extraction Hypothesis generation Integrated frameworks Systems Biology Requires a shift in focus from genes and proteins to the system’s structure and dynamics Four key properties: System structures System dynamics Control method Design method Systems Biology Markup Language (SBML) and CellML iSpecies.org Overview of the Talk Data Mining and Knowledge Discovery DMKD in Bioinformatics DMKD Public in Chemistry Chemistry Databases for DMKD Overview of Web Services NIH-funded Projects Underway or Planned at Indiana University Educational Opportunities at IU Data Mining in Chemistry “Modern experimentation (whether “classical” or high-throughput) should be based on the productive interplay of statistical techniques (design-ofexperiments), molecular modeling as well as cheminformatics.” --Ulrich S. Schubert Session on “Integration of Informatics and Knowledge Management Informatics”* Integration of Informatics at the Systems Level and at the Data Level Chris L. Waller, Ph.D., Director, World Wide Chemistry Informatics, Pfizer Global Research & Development Integrated Knowledge Management at Bayer HealthCare: Pharmacophore Informatics William J. Scott, Ph.D., Team Leader, Department for Chemistry Research, Bayer Pharmaceuticals Corporation Building a Knowledge Enabled Organization Cory R. Brouwer, Ph.D., Associate Director, Knowledge Management Informatics, Pfizer Global Research & Development Knowledge Management: Building a Knowledge Enabled Organization Victor Lobanov, Ph.D., Principal Scientist, MDI, Johnson & Johnson Pharmaceutical R&D *10th Annual Cheminformatics Conference, May 23-16, 2006, Philadelphia Impact of HTS and Combinatorial Chemistry Research Most the pharmaceutical industry medical research catalyst research More impact in: recently: polymer and materials research. Diversity of Data Mining in Chemistry On 5/7/2006 there were 4072 references to either “datamining” or “data mining” in Chemical Abstracts. 3416 different index terms were assigned to those records. 2772 used 1-5 times (81%) 298 used 6-10 times (9%) 103 used 11-15 times (3%) 71 used 16-20 times (2%) 38 used 21-25 times (1%) 24 used 26-30 times (1%) 110 for 31-480 times (3%) Most frequent co-term: “bioinformatics” with 480 hits or 12% of the occurrences 90% 80% 70% 60% 50% Series1 40% 30% 20% 10% 0% 1-5 6-10 11-15 16-20 21-25 25-30 31-480 SFS graph Components of the Semantic Web for Chemistry XML – eXtensible Markup Language RDF – Resource Description Framework RSS – Rich Site Summary Dublin Core – allows metadata-based newsfeeds OWL – for ontologies BPEL4WS – for workflow and web services Murray-Rust et al. Org. Biomol. Chem. 2004, 2, 31923203. Chemical Markup Language (CML) Much of the semantics in a chemical article can be supported by CML Molecules Structures Reactions and reaction schemes Spectra (including annotations) Physicochemical data XML dictionaries and lexicons provide linguistic and semantic support for markup Will lead to quicker authoring and higher quality of embedded structures and data through machine validation Key Factors in the Success of the Chemical Semantic Web Institutional Repositories: services deployed and supported at an institutional level to offer dissemination management, stewardship, and where appropriate, longterm preservation of both the intellectual work created by an institutional community and the records of the intellectual and cultural life of the institutional community Open Access Movement Knowledge-Driven Bioinformatics Enhanced with Chemistry Text Mining (Banville) “In the pharmaceutical field, it is ideally the marriage of biological and chemical information that needs to be the ultimate focus of text data mining applications.” Problems: Lack of universal publication standards for identifying each unique chemical entity Selective indexing policies of A&I services Need to understand how chemical structures link to biological processes OSCAR3 Service Open Java source application under development by Peter Murray-Rust group at Cambridge (Not published yet) Extracts chemical information from either a paragraph of experimental data or a full paper (e.g. melting points, infra-red and NMR data, and mass spectral information) Produces an XML instance highlighting the chemical information with an Extensible Stylesheet Language (XSL) file At IU, we are attaching SOAP input/output engine for a web service based on OSCAR3. OSCAR at Work in the Future Semantic Scholars’ Grid I Local MD Store Local Harvest Store Fetch MD and Documents PubMed Gatherer Indexer Index all Local MD Query and Get list Analyzer Run filter such as OSCAR2 on harvested MD and documents Store new MD Science.gov Google Scholar e-Prints Dspace etc. Semantic Scholars’ Grid II Local MD Store ACM CiteULike IEEE Connotea Del.icio.us Google Scholar etc. Wiley Plug-in Updater Synchronize SSG and foreign MD etc. Community Tools SSG Viewer Instant Citation Index etc. Update local MD Control foreign interactions View all MD’ Access Community Tools Foreign User Interface Update and view foreign MD Chemical Datamining Software SureChem CLiDE http://surechem.reeltwo.com/ Recognizes structures, reactions, and text http://www.simbiosys.ca/clide/ OSCAR “OSCAR1” to check experimental data • http://www.ch.cam.ac.uk/magnus/checker.html • http://www.rsc.org/Publishing/ReSourCe/AuthorGuidelines/AuthoringTools/E xperimentalDataChecker/ CSR (Chemical Structure Reconstruction) http://www.scai.fraunhofer.de/uploads/media/MZ-ERCIM05_04.pdf MDL DocSearch—combines MDL’s Isentris platform and EMC’s Documentum Overview of the Talk Data Mining and Knowledge Discovery DMKD in Bioinformatics DMKD in Chemistry Public Chemistry Databases for DMKD Overview of Web Services NIH-funded Projects Underway or Planned at Indiana University Educational Opportunities at IU ChemDB http://cdb.ics.uci.edu/CHEM/Web/ ChEBI, Chemical Entities of Biological Interest Dictionary of molecular entities focused on small chemical compounds Features an ontological classification, showing the relationships between molecular entities or classes of entities and their parents and/or children Vioxx Entry in ChEBI The IUPAC International Chemical Identifier (InChI) Open source, non-proprietary, public-domain identifier for chemicals String of characters that uniquely represent a molecular substance Independent of the way the chemical structure is drawn Enables reliable structure recognition and easy linking of diverse data compilations Accepts as input MOLfiles (or SDfiles) and CML files Download the program to your computer at: http://www.iupac.org/inchi/license.html Generation of InChI for Vioxx with wInChI Vioxx Entry in PubChem Compounds Found with InChI Vioxx Bioassay Data in PubChem Vioxx PubChem Link to External Sources of Information PubChem Link to Elsevier MDL DiscoveryGate www.discoverygate.com provides access to integrated scientific content from databases, journal articles, patent publications and reference works information providers include Elsevier, ThomsonDerwent, FIZ CHEMIE, the U.S. FDA, Prous Science and Thieme MDL Compound Index (the master list of substances included in DiscoveryGate data sources) now exceeds 14 million unique chemical structures with the addition of 5 million chemical structures from the PubChem database. The Elsevier MDL/NIH Link via PubChem and DiscoveryGate Cross-indexes PubChem to the Compound Index hosted on Elsevier MDL’s DiscoveryGate platform MDL added 5 million structures from PubChem to their index, resulting in over 14 million unique chemical structures Links go both ways Can move from biological data in PubChem to bioactivity, chemical sourcing, synthetic methodology, and EHS data in DiscoveryGate sources Elsevier MDL’s xPharm Comprehensive set of records linking: Agents (compounds) (2300) Targets (600) Disorders (450) Principles that govern their interactions (180) Answers questions such as: • What targets are associated with control of blood pressure? • What adverse effects are associated with monoamine oxidase inhibitors? Web Guide for Essential Cheminformatics Resources http://www.chembiogrid.org http://www.indiana.edu/~cheminfo/cicc/ ChemBioGrid Chemical Databases Overview of the Talk Data Mining and Knowledge Discovery DMKD in Bioinformatics DMKD in Chemistry Public Chemistry Databases for DMKD Overview of Web Services NIH-funded Projects Underway or Planned at Indiana University Educational Opportunities at IU Web Services Overview What are “Web Services”? A distributed invocation system built on Grid computing • Independent of platform and programming language • Built on existing Web standards A service oriented architecture with • Interfaces based on Internet protocols • Messages in XML (except for binary data attachments) Web Services for Chemistry: Problems Performance and scalability Proprietary data Competition from high-performance desktop applications -- Geoff Hutchison, it’s a puzzle blog, 2005-01-05 ALSO: Lack of a substantial body of trustworthy Open Access databases Non-standard chemical data formats (over 40 in regular use and requiring normalization to one another) DM Internet Toolbox Architecture Overview of the Talk Data Mining and Knowledge Discovery DMKD in Bioinformatics DMKD in Chemistry Public Chemistry Databases for DMKD Overview of Web Services NIH-funded Projects Underway or Planned at Indiana University Educational Opportunities at IU Indiana University Planned Projects: http://www.chembiogrid.org Design of a Grid-based distributed data architecture Development of tools for HTS data analysis and virtual screening Database for quantum mechanical simulation data Chemical prototype projects Novel routes to enzymatic reaction mechanisms Mechanism-based drug design Data-inquiry-based development of new methods in natural product synthesis Web Services for Chemistry at IU Purpose Technologies Interaction Layer Interactive software for creative access and exploitation of information by humans Microsoft .NET Smart Clients, portlets, Java applets, email and browser clients, visualization technologies Aggregation Layer Workflows and data schemas customized for particular domains, applications and users BPEL, Taverna and other workflow modeling tools, aggregate web services Web service layer Comprehensive data and computation provision including storage, calculation, semantics and meta-data exposed as web services Apache web services, SOAP wrappers, WSDL, UDDI, XML, Microsoft .NET NCI Developmental Therapeutics Program (DTP) Downloadable data: In vitro 60 cell line results in vitro anti-HIV results Yeast assay 200,000+ chemical structures molecular targets microarray data Or search the database at: • http://dtp.nci.nih.gov/docs/dtp_search.html IU Database of NIH DTP Data Contains over 200,000 chemical structures tested in 60 cellular assays from different human tumor cell lines Also includes microarray assay profiles for the untreated cell lines (~14,000 datapoints) A local PostgreSQL database containing the data that is exposed as a web service Using workflows and complex SQL queries, we can do advanced data mining that exploits the chemical, biological and genomic information for particular audiences (chemists, biologists, etc) Mining the NIH DTP database 60 cell lines ~200,000 compounds Cell lines can be clustered based on gene expression similarity Compounds can be clustered based on similarity of profile across cell lines, or by chemical structure fingerprint similarity Use of Taverna at IU A protein implicated in tumor growth is supplied to the docking program (in this case HSP90 taken from the PDB 1Y4 complex) The workflow employs our local NIH DTP database service to search 200,000 compounds tested in human tumor cellular assays for similar structures to the ligand. Client portlets are used to browse these structures Once docking is complete, the user visualizes the high-scoring docked structures in a portlet using the JMOL applet. Similar structures are filtered for drugability, and are automatically passed to the OpenEye FRED docking program for docking into the target protein. A 2D structure is supplied for input into the similarity search (in this case, the extracted bound ligand from the PDB IY4 complex) Correlation of docking results and “biological fingerprints” across the human tumor cell lines can help identify potential mechanisms of action of DTP compounds Taverna Workflow Workflow definition Available web services (WSDL) Visual depiction of workflow Taverna in Action CGL Contributions to CICC Build Web/Grid services for connecting Third party tool evaluation Data sources Applications (simulation, data mining, data assimilation, imaging, etc). Computing resources Information services. Workflow (Taverna) Grid tools: Globus and Condor (for interacting with TeraGrid) Building standards-based Web portal environments. OGCE grid portal project JSR 168 Java standards. This activity will begin in earnest over the summer. Digital Chemistry (BCI) Clustering Service Methods Service Method Description Input Output makebitsGenerate Generate fingerprints SMIstring from a SMILES structure Fingerprint string divkmGenerate Cluster fingerprints with Divkmeans SCNstring Clustered Hierarchy smile2dkm Makebits + divkm SMIstring optclusGenerate Generate the best levels DKMstring Best partition in a hierarchy cluster level rnnclusGenerate Extract individual cluster partitions Clustered Hierarchy DKMstring Indiv. cluster partitions smile2ClusterPartiti Generate a new SMILES SMIstring oned structure w/ extra col. New SMILES structure Local Web Service Methods for WWMM of PMR’s Group Services Descriptions Input Output InChIGoogle Search an InChI inchiBasic structure through Google type Search result in HTML format InChIServer Generate InChI version format An InChI structure OBServer Transform a chemical format to another using Open Babel format inputData outputData options Converted chemical structure string CMLRSSSer Generate CMLRSS feed ver from CML data mol, title Converted description CMLRSS feed link, source of CML data More Services VOTables and related services. General purpose service for manipulating tabular data. Comes with third party tools for parsing, manipulating, displaying data. Includes import tools. Using this as an intermediary for data exchange between data bases. Draw2d Uses CDK tools to create 2d images from SDF formatted data. Common Substructure Another CDK service that can be used to calculate the common substructure between two molecules. Other CDK Services See http://www.chembiogrid.org/wiki/index.php/Web_Se rvices_Infrastructure. Based on Dr. Rajarshi Guha’s services. ToxTree An in silico toxicology prediction suite Based on the CDK toolkit Built on CML Released as OpenSource under the GPL Standalone PC software User Manual: http://ecb.jrc.it/DOCUMENTS/QSAR/TOX TREE/toxTree_user_manual.pdf ToxTree Service An open Java source application by Nina Jeliazkova Estimates toxic hazard by applying a decision tree approach. Encodes the Cramer scheme (Cramer G. M., R. A. Ford, R. L. Hall, Estimation of Toxic Hazard - A Decision Tree Approach, J. Cosmet. Toxicol., Vol.16, pp. 255-276, Pergamon Press, 1978) Could be applied to datasets from various compatible file types. We are converting this GUI application to a text-based web service Overview of the Talk Data Mining and Knowledge Discovery DMKD in Bioinformatics DMKD in Chemistry Public Chemistry Databases for DMKD Overview of Web Services NIH-funded Projects Underway or Planned at Indiana University Educational Opportunities at IU Chemoinformatics Education at IU School of Informatics degree programs BS, MS, PhD Programs offered at both the Indianapolis (IUPUI) and Bloomington (IUB) campuses Other Educational Activities Graduate Certificate Program in Chemical Informatics (4 courses by Distance Education) I571 Chemical Information Technology (3 cr.) I572 Computational Chemistry and Molecular Modeling (3 cr.) I573 Programming Techniques for Chemical and Life Science Informatics (3 cr.) I553 Independent Study in Chemical Informatics (3 cr.) I571 as CIC Courseshare offering w. Michigan Experiments with teleconferencing as a distance education tool PhD in Informatics Began in August 2005 Tracks: bioinformatics; chemical informatics; health informatics; human-computer interaction design; social and organizational informatics Under development: complex systems, networks, modeling and simulation; cybersecurity; discovery and application of information; logical and mathematical foundations; music informatics Graduate Enrollment: Chemo-, Laboratory, Bio-, Health Informatics MS Chem Lab Bio Health IUB 3 0 38 0 IUPUI 6 15 34 36 TOTAL 9 15 72 36 PhD Chem Lab Bio Health IUB 1 0 3 0 IUPUI 1 0 4 3 TOTAL 2 0 7 3 Software/DBs Used in the Program Company ArrgusLab Digital Chemistry Cambridge Cryst Data Ctr CambridgeSoft Chemical Abstracts Service Chemaxon Daylight Chemical Info System FIZ Karlsruhe IO-Informatics MDLCrossFire OpenEye Sage Informatics Serena Software Spotfire STN International Wavefunction Products and/or (Target Area) (Molecular modeling) Toolkit (Clustering) Cambridge Structrual DB & GOLD ChemDraw Ultra SciFinder Scholar Marvin (and other software) Toolkit Inorganic Crystal Structure DB Sentient Beilstein and Gmelin Toolkit (and other software) ChemTK PCMODEL DecisionSite STN Express with Discover (Anal Ed) Spartan Closing quote “The future of chemistry depends on the automated analysis of chemical knowledge, combining disparate data sources in a single resource, . . . which can be analysed using computational techniques to assess and build on these data.” Townsend et al. Org. Biomol. Chem. 2004, 2, 3299. We all need help when overloaded! Bibliography Agresti, William W. “Discovery informatics.” Communications of the ACM 2003, 46(8), 25-28. Banville, Debra L. “Mining chemical structural information from the drug literature.” Drug Discovery Today January 2006, 11(1/2), 35-42. Bajcsy, Peter; Han, Jiawei; Liu, Lei; Yang, Jiong. "Survey of bio-data analysis from a data mining perspective." Chapter 2 in: Wang, Jason T. L.; Zaki, Mohammed J.; Toivonen, Hannu T. T.; Shasha, Dennis (eds.), Data Mining in Bioinformatics. London, Springer Verlag, 2005, pp.9-39. Banville, Debra L. “Mining chemical structural information from the drug literature.” Drug Discovery Today, 2006, 11(1/2), 35-42. Cios, Krzysztof J.; Kurgan, Lukasz A. “Trends in data mining and knowledge discovery.” Chapter 1 in: Pal, N.R.; Jain, L.C.; Teodoresku, N. (eds.), Knowledge Discovery in Advanced Information Systems. N.Y., Springer Verlag, 2002, pp. 1-26. Cohen, Aaron M.; Hersh, W.illiam R. "A survey of current work in biomedical text mining." Briefings in Bioinformatics March 2005, 6(1), 57-71. Bibliography Corbett, Peter T.; Murray-Rust, Peter; Day, Nick E.; Townsend, Joe A.; Rzepa, Henry S. “Chemistry publications in CML.” Abstracts of Papers, 231st ACS National Meeting, Atlanta, GA, United States, March 26-30, 2006, CINF-055. Fayyad, U.M.; Piatesky-Shapiro, G.; Smyth, P.; Uthurusamy, R. Advances in Knowledge Discovery and Data Mining. AAAi/MIT Press, 1996. (quoted by Cios and Kurgan) Gardner, Stephen P. “Ontologies and semantic data integration.” Drug Discovery Today 2005 10(14), 1001-1007. Guha, R.; Howard, M.T.; Hutchison, G.R.; Murray-Rust, P.; Rzepa, H.; Steinbeck, C; Wegner, J.; Willighagen, E.L. “The Blue Obelisk—Interoperability in chemical informatics.” Journal of Chemical Information and Modeling 2006 Web Release Date: 22-Feb-2006; DOI: 10.1021/ci050400b Holliday, Gemma L.; Murray-Rust, Peter; Rzepa, Henry S. “Chemical Markup, XML, and the World Wide Web. 6. CMLReact, an XML Vocabulary for Chemical Reactions.” Journal of Chemical Information and Modeling 2006, 46(1), 145-157. Jónsdóttir, S.O.; Jorgensen, F.S.; Brunak, S. “Prediction methods and databases within chemoinformatics: emphasis on drugs and drug candidates.” Bioinformatics 2005 May 15; 21(10): 2145-60. Bibliography Karthikeyan, M.; Krishnan, S.; Pankey, Anil Kumar. “Harvesting chemical information from the Internet using a distributed approach: ChemXtreme.” Journal of Chemical Information and Modeling.” DOI: 10.1021/ci050329. Krallinger, Martin; Alonso-Allende Erhardt, Ramon; Valencia, Alfonso. “Text-mining approaches in molecular biology and biomedicine.” Drug Discovery Today 2005, 10(6), 439-445. Scherf Uwe, Ross Douglas T., Waltham Mark, Smith Lawrence H., Lee Jae K., Tanabe Lorraine, Kohn Kurt W., Reinhold William C., Myers Timothy G., Andrews Darren T., Scudiero Dominic A., Eisen Michael B., Sausville Edward A., Pommier Yves, Botstein David, Brown Patrick O., Weinstein John N. “A gene expression database for the molecular pharmacology of cancer.” Nature Genetics 2000, 24, 236244. Schubert, Ulrich S. "Materials informatics: from data to knowledge towards integrated escience approaches." QSAR & Combinatorial Science 2005, 24(1), 5. (NB: Entire issue is devoted to this topic.) SIAM International Conference on Data Mining (5th: 2005: Newport Beach, CA) Data Mining; Proceedings. Kargupta, Hillol et al., eds. SIAM, 2005. Torr-Brown, Sheryl. “Advances in knowledge management for pharmaceutical research and development.” Current Opinion in Drug Discovery & Development 2005, 8(3), 316-322. Web 2.0 Social Software: allows group interactions Enables groups to form and organize themselves Examples • • • • • • • • Wikis Blogs RSS (now found on chemistry.org) Podcasting/Coursecasting Webcasting/Webinars Flickr Jybe FURL FURL (Frame Uniform Resource Locater) For archiving and sharing of web pages Furler can capture the pages for a discussion group Tracks useful pages for a discussion http://www.furl.net/home.jsp Jybe (Join Your Browser with Everyone) Collaboration and communication in real time with IE and Firefox Screen-sharing AND editing Privacy protected: must be invited Upload documents to convert to html http://www.jybe.com