Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Multidimensional empirical mode decomposition wikipedia , lookup
Telecommunication wikipedia , lookup
PSTN network topology wikipedia , lookup
Packet switching wikipedia , lookup
Windows Vista networking technologies wikipedia , lookup
Cracking of wireless networks wikipedia , lookup
Serial digital interface wikipedia , lookup
Asynchronous Transfer Mode wikipedia , lookup
TCP congestion control wikipedia , lookup
Quality of service wikipedia , lookup
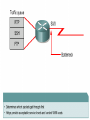
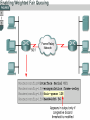
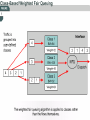
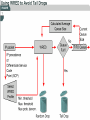
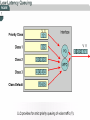
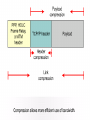
Managing Network Performance Queuing & Compression Queuing overview • A queuing policy helps network managers meet two challenges: • Providing an appropriate level of service for all users • Controlling expensive WAN costs Weighted fair queuing • Weighted fair queuing (WFQ) is a flow-based algorithm that schedules delay-sensitive traffic to the front of a queue to reduce response time, and also shares the remaining bandwidth fairly among high-bandwidth flows. • By breaking up packet trains, WFQ assures that lowvolume traffic is transferred in a timely fashion. • Weighted fair queuing gives low-volume traffic, such as Telnet sessions, priority over high-volume traffic, such as File Transfer Protocol (FTP) sessions. • Weighted fair queuing gives concurrent file transfers balanced use of link capacity. • Weighted fair queuing automatically adapts to changing network traffic conditions. Weighted fair queuing • 1. 2. 3. 4. • There are four types: Flow-based Distributed Class-based Distributed class-based Weighted fair queuing is enabled by default for physical interfaces whose bandwidth is less than or equal to T1/E1 Conversations or Flows • 1. 2. 3. 4. 5. The sorting of traffic into flows is based on packet header addressing. Common conversation discriminators are as follows: Source/destination network address Source/destination Media Access Control (MAC) address Source/destination port or socket numbers Frame Relay data-link connection identifier (DLCI) value Quality of service/type of service (QoS/ToS) value Class-based weighted fair queuing • CBWFQ extends the standard WFQ functionality to provide support for user-defined traffic classes. • By using CBWFQ, network managers can define traffic classes based on several match criteria, including protocols, access control lists (ACLs), and input interfaces. • A FIFO queue is reserved for each class, and traffic belonging to a class is directed to the queue for that class. • More than one IP flow, or “conversation", can belong to a class. • Once a class has been defined according to its match criteria, the characteristics can be assigned to the class. • To characterize a class, assign the bandwidth and maximum packet limit. • The bandwidth assigned to a class is the guaranteed bandwidth given to the class during congestion. • CBWFQ assigns a weight to each configured class instead of each flow. • This weight is proportional to the bandwidth configured for each class. Weight is equal to the interface bandwidth divided by the class bandwidth. • Therefore, a class with a higher bandwidth value will have a lower weight. CBWFQ versus flow-based WFQ • Bandwidth allocation – CBWFQ allows the administrator to specify the exact amount of bandwidth to be allocated for a specific class of traffic. • The administrator can configure up to 64 classes, and can control distribution among them. • Finer granularity and scalability – • CBWFQ allows the administrator to define what constitutes a class based on more criteria. • CBWFQ allows the use of ACL’s and protocols or input interface names to define how traffic will be classified, thereby providing finer granularity. • The administrator can configure up to 64 discrete classes in a service policy. CBWFQ and tail drops • Traffic variations such as packet bursts or flows demanding high bandwidth can cause congestion when packets arrive at an output port faster than they can be transmitted. • The router tries to handle short-term congestions by packet buffering. • This absorbs periodic bursts of excessive packets so that they can be transmitted later. • Although packet buffering has a cost of delay and jitter, packets are not dropped • For network traffic causing longer-term congestion, a router using CBWFQ or any of several other queuing methods will need to drop some packets. • A traditional strategy is tail drop. • With tail drop, a router simply discards any packet that arrives at the tail end of a queue that has completely used up its packet-holding resources. • Tail drop is the default queuing response to congestion. • Tail drop treats all traffic equally and does not differentiate between classes of service. • When using tail drop, the router drops all traffic that exceeds the queue limit. • Many TCP sessions then simultaneously go into a slow start. • This reduces the TCP window size. • Consequently, traffic temporarily slows as much as possible. • As congestion is reduced, window sizes begin to increase in response to the available bandwidth. • This activity creates a condition called global synchronization. • Global synchronization manifests when multiple TCP hosts reduce their transmission rates in response to packet dropping, and then increase their transmission rates after the congestion is reduced. • The most important point is that the waves of transmission known as global synchronization will result in significant link under-utilization Weighted Random Early Detect (WRED) • WRED monitors the average queue depth in the router and determines when to begin packet drops based on the queue depth. • When the average queue depth crosses the user-specified minimum threshold, • WRED begins to drop both TCP and UDP packets with a certain probability. • If the average queue depth ever crosses the user-specified maximum threshold, then WRED reverts to tail drop, and all incoming packets might be dropped. • The idea behind using WRED is to maintain the queue depth at a level somewhere between the minimum and maximum thresholds, and to implement different drop policies for different classes of traffic. Low Latency Queuing (LLQ) • The Low Latency Queuing (LLQ) feature provides strict priority queuing for class-based weighted fair queuing (CBWFQ), reducing jitter in voice conversations. • Configured by the priority command, strict priority queuing gives delay-sensitive data, such as voice, preferential treatment over other traffic. • With this feature, delay-sensitive data is sent first, before packets in other queues are treated. • LLQ is also referred to as priority queuing/classbased weighted fair queuing (PQ/CBWFQ) because it is a combination of the two techniques. Queuing comparison • Flow-based WFQ differs from priority and custom queuing in several ways. • On serial interfaces, WFQ is enabled by default, and the user must enable priority and custom queuing. • WFQ does not use queue lists to determine the preferred traffic on a serial interface. • Instead, the fair queue algorithm dynamically sorts traffic into messages that are part of a conversation. • The messages are queued for low-volume conversations, usually interactive traffic. • The messages are given priority over high-volume, bandwidth-intensive conversations, such as file transfers. • When multiple file transfers occur, the transfers are given comparable bandwidth. • Class-based weighted fair queuing allows network managers to customize fair queuing behavior so that user-defined classes of traffic receive guaranteed bandwidth during times of congestion. • More than one flow, or conversation, can belong to a user-defined class. • Low latency queuing (LLQ) adds strict priority queuing to CBWFQ operation. • LLQ allows a user to specify a priority class, which will be served before any of the other classes of traffic. However, the priority queuing (PQ) with LLQ will not starve the other classes because the PQ is policed whether or not there is congestion. Data Compression • Data compression works by identifying patterns in a stream of data, and choosing a more efficient method of representing the same information. • Essentially, an algorithm is applied to the data to remove as much redundancy as possible. • The efficiency and effectiveness of a compression scheme is measured by its compression ratio, the ratio of the size of uncompressed data to compressed data. • A compression ratio of 2:1 (relatively common) means that the compressed data is half the size of the original data. Link compression • Link compression, which is sometimes referred to as per-interface compression, involves compressing both the header and payload sections of a data stream. • Unlike header compression, link compression is protocol independent. • Uses two types of algorithm: Predictor • Predicts the next sequence of characters in the data stream by using an index to look up a sequence in a compression dictionary. • It then examines the next sequence in the data stream to see if it matches. • If so, that sequence replaces the looked-up sequence in a maintained dictionary. • If not, the algorithm locates the next character sequence in the index and the process begins again. • The index updates itself by hashing a few of the most recent character sequences from the input stream. STAC • Developed by STAC Electronics, STAC is a Lempel-Ziv (LZ) compression algorithm. • It searches the input data stream for redundant strings and replaces them with a token, which is shorter than the original redundant data string. • If the data flow moves across a point-topoint connection, use link compression. • In a link compression environment, the complete packet is compressed and the switching information in the header is not available for WAN switching networks. • Therefore, the best applications for link compression are point-to-point environments with a limited hop path. • Typical examples are leased lines or ISDN. Payload compression • When using payload compression, the header is left unchanged and packets can be switched through a WAN packet network. • Payload compression is appropriate for virtual network services such as Frame Relay, and Asynchronous Transfer Mode (ATM). • It uses the STAC compression method TCP/IP header compression • TCP/IP header compression subscribes to the Van Jacobson Algorithm defined in RFC 1144. • TCP/IP header compression lowers the overhead generated by the disproportionately large TCP/IP headers as they are transmitted across the WAN. • TCP/IP header compression is protocol-specific and only compresses the TCP/IP header. • The Layer 2 header is still intact and a packet with a compressed TCP/IP header can still travel across a WAN link. MPPC • The Microsoft Point-To-Point Compression (MPPC) protocol allows Cisco routers to exchange compressed data with Microsoft clients. • MPPC uses an LZ-based compression mechanism. • Use MPPC when exchanging data with a host using MPPC across a WAN link.